基于移动激光扫描的行道树靶标实时检测
2023-02-09薛玉玺李秋洁
薛玉玺,李秋洁
(南京林业大学机械电子工程学院,南京 210037)
行道树资源是我国重要的生态资源,是城市中一道靓丽的风景线,也是城市生态系统重要的一部分。在城市的行道树养护工作中,病虫害防治具有十分重要的意义。常规的病虫害防治手段是对行道树喷洒农药,但是这种方式会造成药液的大量浪费,同时会污染空气,从而对城市生态环境造成破坏并影响人群的身体健康。由于常规施药存在的各种问题,有学者提出了对靶施药的概念,即通过传感器先探明靶标的位置和大小等信息,然后针对该靶标进行喷雾,这种方法目前已经在果园场景成功实现,有效地解决了药液流失问题[1-2]。
对靶施药技术的关键在于靶标的快速准确检测。针对城市复杂环境下的行道树检测,学者对于不同类型的数据提出了各种检测方法。针对图像数据主要使用深度学习方法,针对点云数据的检测方法则更加多样化,例如高程阈值分类法、投影点密度法、扫描线信息分类、特征空间聚类以及机器学习等[3-4]。这些方法有效地解决了城市背景复杂情况下行道树难以检测的问题[5]。相较于处理复杂的图像数据,点云数据更受学者的青睐。林木植被的点云获取于激光雷达(light detection and ranging,LiDAR)传感器[6]。LiDAR传感器性能优越,性价比高。基于LiDAR采集得到的点云包含了行道树检测所需要的各种信息,因而目前在林木植被的目标检测和对靶喷雾领域,基于点云的各项技术已经广泛应用[7-8]。
目前基于移动激光扫描(mobile laser scanning,MLS)系统的行道树检测方法可以划分为区域检测和逐点检测两种。区域检测方法包括高程阈值分类法、投影点密度法、扫描线信息分类和特征空间聚类,这类方法都是通过一块区域内点的整体信息对这些点整体分类。例如特征空间聚类就是将整个点云空间划分为二维格网或三维体素,然后通过聚类或区域生长等方法逐步筛除非行道树点云[9-10]。区域检测方法的缺陷是这些方法的阈值等参数都是人为设置以针对不同目标的不同特征,导致其识别精度不高,泛化能力差,且区域检测无法实现点云的在线检测。逐点检测如机器学习方法则是以点云的每一个点为处理单元,确定一个以检测点为中心,大小固定的邻域,然后提取设计好的局部特征,用这些特征训练一个二分类器以实现点云逐点检测的目标[5,11]。这种对于原始点云的检测方法常采用四叉树、八叉树和k-D树建立点云数据索引,但是该方法无法满足在线检测的要求[12-14]。后有学者提出采用格网索引的方式对点云进行处理,虽然这种方法能够实现点云在线检测,但依旧无法实现实时检测[15]。
针对逐点检测方法无法满足实时性要求的问题,本研究基于MLS的逐点检测算法,使用随机森林分类器[16],通过特征筛选和改进邻域搜索算法从而提高逐点检测的速度,在保证点云分类器性能平稳的情况下达到行道树点云实时检测的目的。
1 材料与方法
方法包括MLS点云数据采集、立方体邻域搜索、点云局部特征提取、RF分类器检测4个步骤。首先,对MLS采集到的行道树点云数据进行人工标注;然后使用立方体邻域对每个点进行局部特征提取;接着训练得到RF分类器,随后将特征按照贡献度高低进行排序,特征按照贡献度从低到高逐个剔除,直至保留满足行道树检测准确性和实时性要求的特征,使用筛选好的特征对分类器进行再训练得到最终的RF分类器。
1.1 MLS点云数据采集
本研究使用的MLS点云数据采集系统如图1所示,由1台遥控小车、1个二维LiDAR和1台笔记本电脑组成。小车沿着人行道做匀速直线运动,其上搭载的LiDAR将采集到的数据输送到电脑里,电脑将每一束激光的前3次回波距离r1、r2、r3和回波强度I1、I2、I3保存。

图1 MLS系统Fig.1 MLS system
以小车上的LiDAR初始位置为坐标原点建立一个三维空间坐标系,小车的运动方向为x轴,垂直小车向上的方向为z轴,垂直x轴和z轴纵深向树的方向为y轴(图2)。小车沿着x轴方向运动,其上的LiDAR(UTM-30LX)沿着y轴方向自上而下扫描,扫描范围为270°,角分辨率为0.25°,故而每条扫描线(即每帧)有1 081个激光点,1条扫描线为1帧。扫描从135°开始到-135°结束,最大扫描距离为60 m。
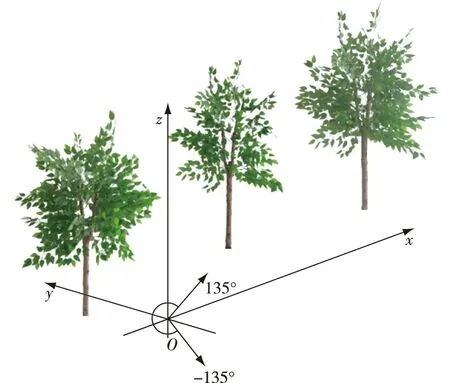
图2 三维坐标Fig.2 Three-dimensional coordinate schematic
本研究所用的点云数据为一段230 m的校园人行道。笔者通过搭载在小车上的LiDAR以U型路径扫描获得。两侧数据一侧为23 300帧,另一侧为21 800帧,共计45 100帧。点云中第i帧内第j个测量点P(i,j)的三维坐标由下式计算:
(1)
式中:i为该点在点云中的帧序号;v为车速;Δt为LiDAR的扫描周期;r1(i,j)为第i帧内第j个测量点P(i,j)的第一次回波的距离。
其中θ(j)的计算方法为:
θ(j)=jΔθ+θ0
(2)
式中:Δθ为LiDAR的角度分辨率;θ0为第i条扫描线的起始扫描角度。
1.2 基于格网索引的立方体邻域搜索
逐点检测的方法需要用到每个点的局部特征,因而每个点都需要搜索邻域。邻域搜索的计算速度和准确性直接影响检测结果的计算速度和准确性。在点云特征提取的过程中常用的邻域有k近邻和球形邻域两种[17-18]。在计算每一个点的k近邻时都需要遍历点云中所有点,而所使用的点云包含了上千万个点,这就导致了k邻域搜索的计算量非常大,进而降低了特征提取的速度。点云内部的密度有大有小,因而难以选择合适的k值,k值选择过大,会导致模型的欠拟合;k值选择过小,会导致模型的过拟合。综上所述,k近邻方法并不适用于行道树的实时检测。球形邻域的方法虽然适合点云的特征提取,但其无法满足行道树的实时检测。
本研究提出采用立方体邻域的方法来提取点云的局部特征。在立方体边长和球体直径相同的情况下,立方体邻域包含的点比球域更多,这意味着同样的特征,使用立方体邻域提取与球域相比包含的信息更多(图3)。点云内部点分布不均,使用球域提取的特征在空间各个方向上表现为各向同性;相比之下,使用立方体邻域提取的特征在空间上表现为各向异性,各向异性的特征对于点云中各个物体的边缘检测十分有利,因而立方体邻域比球域更适用于行道树检测。
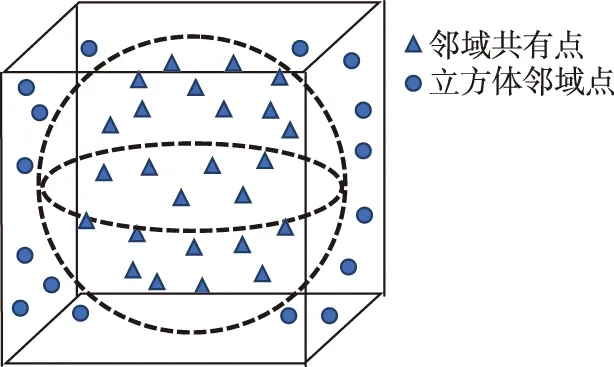
图3 立方体邻域与球域Fig.3 Diagram of cubic neighborhood and spherical neighborhood
为了加快邻域搜索的速度,本研究采用二维格网的点云索引方式来缩小邻域搜索范围。这种方式下,邻域搜索范围缩小到以待测点为中心的附近几帧内的部分点云。假设P(i,j)为待测点,邻域边长为R,则邻域搜索的帧数范围为(i-Δi)到(i+Δi),且单独的一帧内,搜索的激光束范围为(j-Δj)到(j+Δj)。Δi和Δj的计算方式为:
(3)
式中,Δα为Δθ对应的弧度。邻域搜索范围确定以后,采用式(4)搜索立方体邻域,与式(5)中的球域搜索相比,立方体邻域的计算更简单。
(4)
式中:(x,y,z)为立方体邻域点坐标;(x0,y0,z0)为立方体中心点坐标。
{(x,y,z)|(x-x0)2+(y-y0)2+(z-z0)2≤R2}
(5)
式中:(x,y,z)为球域点坐标;(x0,y0,z0)为球域中心点坐标。
1.3 点云特征向量构建
本研究从宽度、深度、高度、次数、强度、维度和密度几个方面构建了一个局部特征向量。在邻域搜索完成后,计算邻域内点云的局部特征并组成特征向量。所用的局部特征见表1。
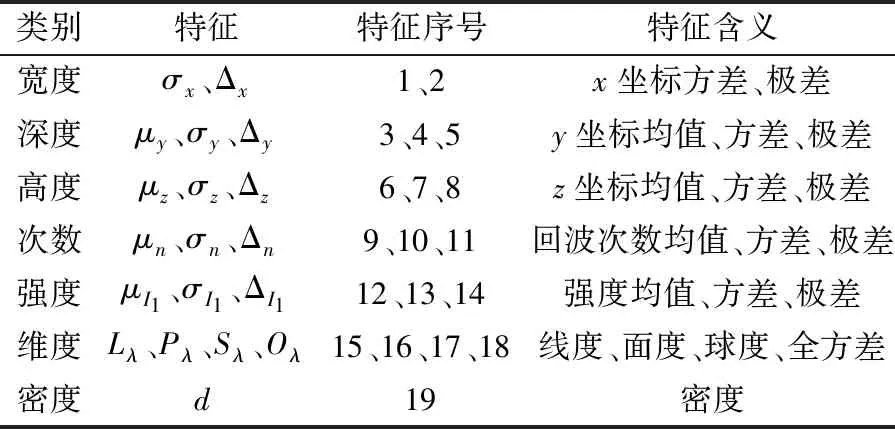
表1 点云局部特征Table 1 Point cloud local features
宽度和深度类特征能够区分行道树与建筑物、行人、电线杆等。高度类特征能够区分行道树与较高的建筑物以及低矮的车辆等。由于树冠特殊的内部结构,故而回波次数和密度类特征能够区分行道树与地面和其他的实心物体。不同物体对于LiDAR激光的反射率都是不同的,所以强度特征也能够有效区分行道树与其他物体,维度类特征能够区分行道树与人行道上各种规则的物体。
1.4 基于RF的特征选择与融合
本研究所采用的算法是机器学习中的有监督算法——RF算法。这种算法是由Leo Breiman提出的,其算法结构如图4所示,由多个决策树组合得到。在RF模型生成的过程中,每一个决策树模型的训练都是单独的,这样能够有效降低决策树之间的关联性,从而减少模型的过拟合情况。本研究所用决策树的组合方式为投票法,这种方法主要应用于分类问题,在决策树投票过程中即使有个别决策树模型预测出错,最终也是以票数最高的类别为最终结果。
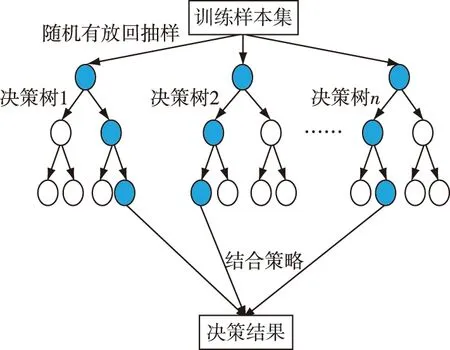
图4 RF模型结构Fig.4 RF model structure diagram
在建立决策树的过程中随机抽样生成训练子集时,剩下的预测集又称之为袋外数据。特征选择基于特征贡献度的大小,特征贡献度的计算步骤如下:
1)对于T棵决策树中的第i棵,将其预测袋外数据的误差记为e1i;
2)随机对每棵决策树的袋外数据所有样本的特征F添加随机噪声,然后再次计算预测误差记为e2i;
3)则特征F的重要性就可以量化为
(6)
得到特征贡献度之后按照从小到大的顺序依次剔除特征,每次剔除特征之后重新计算RF模型的性能指标,直到模型性能满足要求之后保存模型。
2 行道树靶标检测试验
2.1 试验平台和数据
2.1.1 试验平台
试验设备为搭载Windows 10 64位操作系统的计算机,运行内存64 GB,CPU为Intel(R) Core(TM) i9-12900K,单核频率为3.90 GHz,GPU为NVIDIA GeForce RTX 3090 Ti。使用MATLAB R2020a设计程序。
2.1.2 试验数据
使用CloudCompare为230 m人行道两侧树木点云数据打上标签,将其分为“树冠”和“其他”两类。数据集可视化结果如图5所示,其中蓝色为其他物体,红色为行道树树冠。绿色方框中为训练集,其他为测试集,其中训练集为道路两侧各一段包含尽可能多种类物体的点云。训练集和测试集具体信息如表2所示。
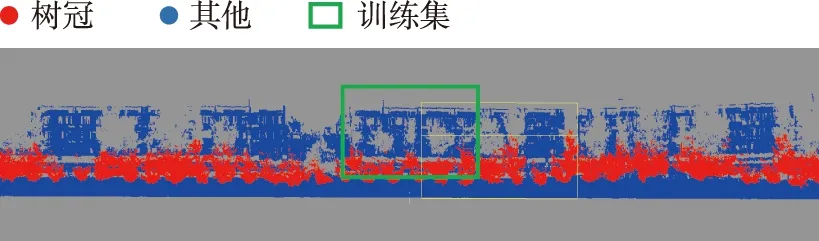
图5 数据集可视化Fig.5 Data set visualization
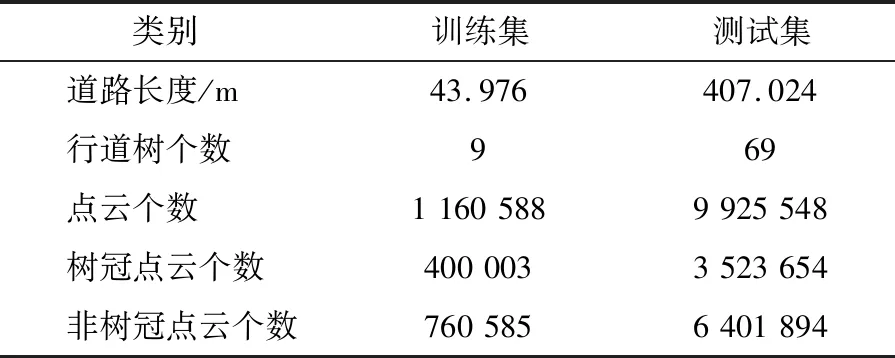
表2 数据集划分Table 2 Data set division
2.2 邻域搜索算法性能测试
考虑到需要识别的行道树的树冠大小问题,本试验所用的立方体邻域边长R范围设置为0.6~2.0 m,与之对比的球域直径等于立方体邻域的边长。立方体邻域和球域提取19个特征需要的时间见图6。从图6可以看出,本研究所用的立方体邻域特征提取速度明显优于球域。邻域边长从0.6 m到2 m,立方体邻域特征提取平均时间为3 380.98 s,球域特征提取平均时间为3 835.62 s,本研究方法特征提取时间缩短了11.85%。
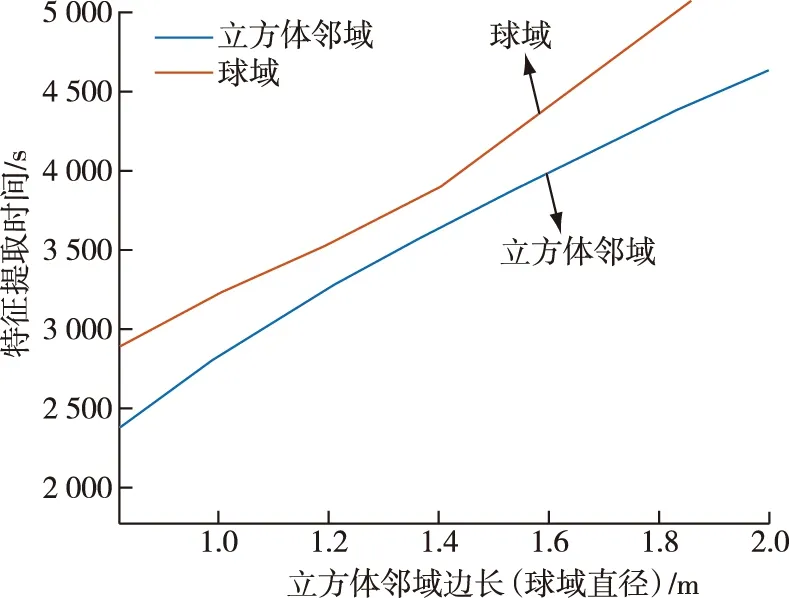
图6 特征提取时间变化Fig.6 Variation of feature extraction time
2.3 特征选择试验
设置立方体邻域边长R=1 m,表1中的19个特征的贡献度如图7所示。按照特征贡献度从低到高每次剔除1个特征,然后重新训练模型,并在训练集和测试集上预测。本试验使用精确率(Pr)、召回率(Re)和F1分数(F1)作为评估RF模型的性能指标。指标计算如式(7)、(8)和(9)所示。Pr表示模型预测为树冠点中真正树冠点的占比;Re表示所有的树冠点中预测为树冠点的占比;F1则是越高越好。
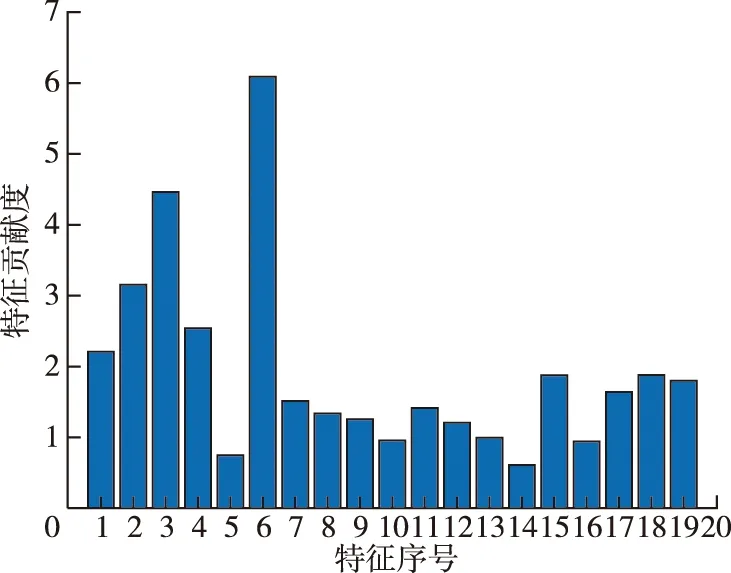
图7 特征贡献度直方图Fig.7 Histogram of feature contribution
(7)
(8)
(9)
式中:TP为预测为树冠且真为树冠的点数;FP为预测为树冠但不是树冠的点数;FN为预测不是树冠但真为树冠的点数。
统计特征筛选过程中RF模型在训练集和测试集上的Pr、Re和F1,数据如表3所示。考虑到RF模型的泛化性能,设置特征数量阈值为5,当特征筛选到剩下5个之后,停止筛选。可以看到,随着特征数量的不断减少,RF模型的各项性能指标虽然略有波动但基本保持平稳:测试集Pr最大波动0.33%,Re最大波动0.67%,F1最大波动0.34%;训练集Pr最大波动0.03%,Re最大波动0.01%,F1最大波动0.02%。
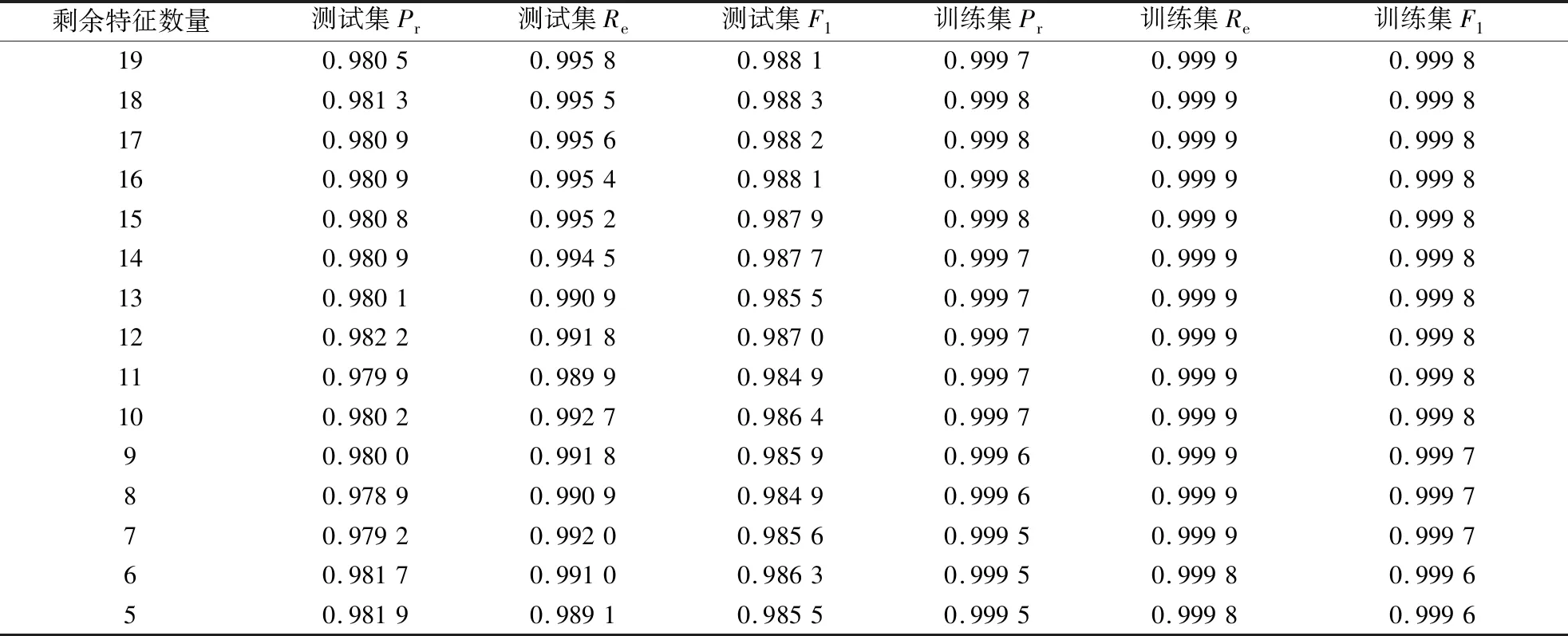
表3 点云局部特征对比Table 3 Comparison of local features of point clouds
特征筛选完成后,最终留下σx、Δx、μy、σy和μz5个特征。使用球域提取19个特征和使用立方体邻域提取5个特征的时间见表4。从表4可知,针对同样的数据本研究方法节省了2 107.20 s,特征提取加快了65.40%。本研究方法特征提取时间为24.72 ms/帧,而LiDAR每帧数据的采集时间为25 ms,所以本研究方法满足检测实时性要求。保留下来的特征表明,行道树相比其他物体最具鉴别力的地方还是在于其特殊的位置和结构。在复杂的城市环境下,行道树的位置特殊,其周围没有其他大型相似物体,故而根据树冠的位置以及树冠的大小即可较为准确地从大量点云中检测出行道树。

表4 特征提取时间对比Table 4 Feature extraction time comparison
2.4 RF算法超参数调整试验
相比其他监督算法,RF算法的优点是训练速度快,生成决策树的训练样本之间相互独立,模型泛化能力好且容易实现。影响RF算法速度的一个重要参数就是决策树的数量,理论上,决策树的数量越大,RF模型的分类效果越好,相应的RF算法的计算量越大,计算时间越长。
决策树数量在1~50情况下RF算法袋外误差的变化见图8,决策树数量在1~50的情况下RF模型训练和预测时间变化见图9。从图8、9可以看出,随着决策树数量的增长,袋外误差越来越小,当数量达到13之后误差曲线趋于0并梯度保持平稳。RF模型的训练时间和模型在训练集与测试集上的预测时间随着决策树数量的增长而增长,故而最终RF模型的决策树数量确定为13。
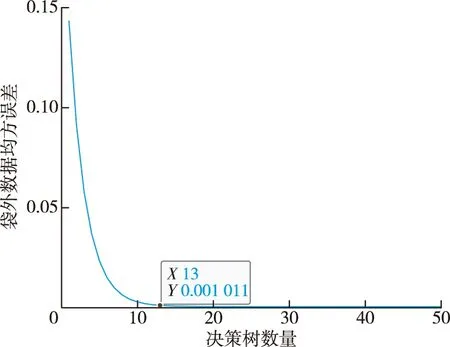
图8 袋外数据均方误差变化曲线Fig.8 Variation curve of mean square errors of out-of-bag data
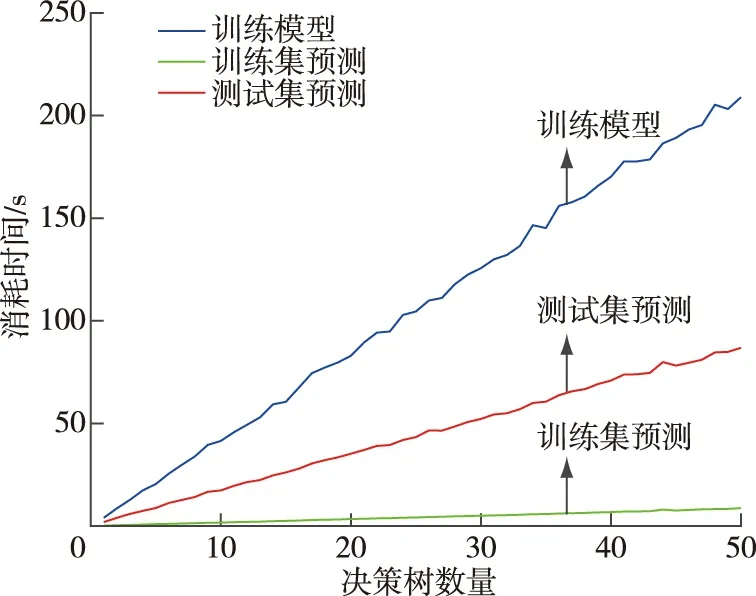
图9 RF模型训练及预测时间曲线Fig.9 RF model training and prediction time curves
2.5 检测算法对比试验
设置立方体邻域边长为1 m,对比了本研究算法和文献[15]中的算法。文献中的算法采用球形邻域,直径为立方体邻域边长,所用特征共20个,具体为表1中的19个特征加上x坐标的均值μx,文献所用监督学习算法为基于决策树的Boosting算法。两种检测算法的结果见表5。从表5可以看出,两种算法检测结果相差无几,但是本研究算法检测时间远远小于文献算法,这说明本研究算法在检测速度上远快于文献中的行道树检测算法。

表5 检测算法性能对比Table 5 Detection algorithm performance comparison
2.6 点云采样对检测性能影响试验
LiDAR的点云密度对邻域搜索和特征提取的速度影响较大,因而为了加快点云的检测速度有时会对点云进行采样处理。为了验证本研究方法对采样后点云的识别效果,对测试集采取抽帧处理。RF分类器在不同采样间隔下生成的测试集上的识别性能见表6,可以看到虽然随着采样间隔不断增加点云密度不断下降,但是测试集Pr最高下降0.20%,Re最高上升0.11%,F1最高下降0.11%,证明本研究方法对不同密度点云可有效识别。点云密度对本研究方法影响较小是因为该算法最终是依靠树冠的位置和结构来检测行道树点云,而采样对点云的上述信息影响很小。
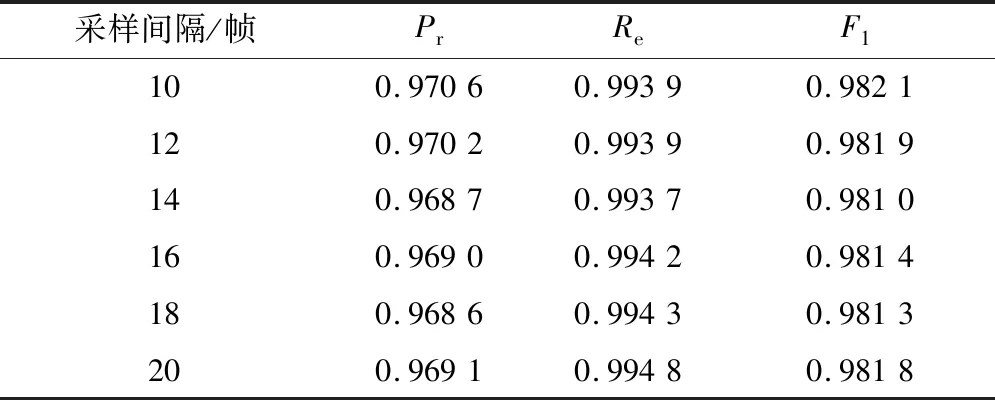
表6 不同采样间隔识别效果对比Table 6 Different sampling interval recognition effect comparison
3 结 论
针对复杂城市环境下行道树靶标实时检测问题,笔者研究一种基于MLS的行道树靶标点云逐点检测方法,通过改进特征提取邻域以及进行特征筛选最终实现了行道树靶标实时检测。在特征提取过程中本研究使用立方体邻域替代球域,在邻域边长取0.6~2.0 m的范围下,立方体邻域相比球域特征提取的平均时间缩短了11.85%。本研究针对宽度、深度、高度、维度、密度、次数和强度7类点云局部特征进行了特征贡献度排序,并按照从低到高的顺序依次剔除,最终保留了σx、Δx、μy、σy和μz5个特征,在RF分类器性能保持平稳的前提下提取特征的时间缩短了65.40%。点云采样试验表明,最终得到的分类器具有良好的鲁棒性,能够有效抵抗点云密度对行道树靶标检测的干扰。
