基于主题关系的中文短文本图模型实体消歧*
2023-02-08马瑛超张晓滨
马瑛超,张晓滨
(西安工程大学计算机科学学院,陕西 西安 710048)
1 引言
随着互联网的不断发展,海量信息蜂拥而至,如何通过信息检索来获取有用信息逐渐成为人们关注的重点。但是,在信息检索的过程中,由于同一实体经常会有多层含义(即在不同语境中同一实体表达的含义可能会不同),因此常常会得到很多同名但并非相关的实体内容。实体消歧(Named Entity Disambiguation)技术的出现为解决这一问题提供了有效途径。近年来中文知识图谱的构建为人工智能的发展带来了新的机遇,作为命名实体识别的后续任务,实体链接和消歧任务也是知识图谱构建和补全的重要一环。知识图谱技术的发展对实体消歧工作也提出了更高的要求。
实体消歧是指将文档中识别出的实体指称链向特定知识库中某个目标实体的过程,其对应着自然语言中的一词多义[1],即实体消歧要解决的是同名实体存在的一词多义问题。例如“巨人希曼:希曼要去水晶山,一路速度飞快,这速度太惊人了”一句中的“巨人希曼”,消歧系统希望该实体指称映射到的目标实体应该是动画片《宇宙的巨人希曼》的主角,而不是一个作品或者其他的实体对象。但有些时候,即使是人类也可能因为缺乏知识或存在误解而无法消除某些实体对象的歧义[2]。实体消歧作为自然语言处理的一项基础任务,能有效根据上下文信息消除一词多义,在该领域起着重要的作用,已经成为知识库构建、信息检索、机器翻译以及话题发现与追踪等方向的重要支撑技术[3]。
针对短文本的实体消歧工作,本文提出了一种基于实体主题关系的中文短文本图模型消歧方法。该方法使用以BERT(Bidirectional Encoder Representation from Transformers)[4]为基础的语义匹配模型进行匹配度判断,并将知识库主题关联信息作为节点关系构建图模型;然后对图进行搜索并按照搜索的结果确定链接结果;此外,还采用TextRank算法对知识库实体描述信息进行信息增强,提高了主题模型相似度的准确率,增加了方法的可靠性。
2 背景
实体消歧工作旨在确定知识库与待消歧实体之间的链接关系,需要借助知识库中的实体描述信息。按照建模所依赖的特征信息,实体消歧工作可分为基于实体描述文本的消歧方法、基于实体类别的消歧方法和基于实体关系的消歧方法。
随着深度学习和预训练模型[5,6]的发展,基于实体描述文本的消歧方法取得了优秀的成绩。He等人[7]提出了一种基于深度神经网络(Deep Neural Networks)的方法来进行实体消歧,通过深度神经网络自主学习实体和上下文的特征表示,端到端地进行实体消歧,避免了人工设计特征,在公开实体链接数据集上取得了优异的消歧结果。Francis-Landau等人[8]提出使用卷积神经网络(Convolutional Neural Networks)进行消歧,通过捕获实体指称上下文和目标实体上下文的语义信息,并利用多个粒度的卷积来比较两者之间的语义相似度。Phong等人[9]提出将实体消歧问题转化为文本语义匹配问题,将待消歧文本和所有候选实体一一配对,通过计算匹配程度确定消歧结果。该方法在诸多预训练模型的帮助下在实体消歧工作中取得了优异的成绩,但利用描述文本的语义特征进行消歧的模型仅考虑了待消歧实体与候选实体之间的匹配程度,而忽略了同一文本中多个待消歧实体间的一致性关系。上述方法都是基于实体描述文本进行的消歧工作。
Raiman等人[10]提出了针对实体类别进行建模的方法DeepType,该方法将实体消歧任务看做对同名实体类型的判定,其最大的难点在于如何构建类别系统,在待消歧实体的候选实体之间类别差距不大的情况下,如何能够给出有区分度的类别判定。
基于实体关系的消歧方法实质上是考虑多实体之间的全局最优,通常有基于搜索算法的消歧模型[11](如基于随机游走算法的消歧模型)和基于图理论的消歧模型(如基于密度子图的方法)[12,13]。由于多实体消歧基于知识库中实体与实体之间的关系,因此需要知识库的信息包含完整的三元组信息,即实体-关系-实体的信息表述。但是,在实际的消歧环境中知识库往往并不包含实体关系的描述或实体关系的描述不完整。针对这一问题,王瑞等人[14]提出了基于主题词向量和主题模型的多实体消歧模型,该模型通过构建主题词关系对待消歧文本和实体描述、实体与实体之间进行主题建模,并利用主题相似度得到最终的消歧结果,这在一定程度上解决了在知识库缺乏关系信息的情况下进行多实体消歧的问题。但在短文本的环境中,将待消歧文本和实体描述的主题关系作为消歧的判定依据很难得到理想的效果。
随着微博、评论等短文本信息的不断增多,知识提取工作的重心在一定程度上转移到了短文本上。而短文本由于包含信息较少、语言不规范等原因为自然语言处理带来了新的挑战。在实体消歧过程中,单实体消歧模型在短文本中的效果并不是很理想。同时,由于网络实体的更新速度快,网络用语多等原因,短文本环境中很难构建出包含完整链接关系的知识库,使用实体关系的消歧方法也很难取得很好的效果。
3 中文短文本图模型实体消歧方法
针对中文短文本上下文特征不足以及知识库中很难直接建立实体间关系的问题,本文提出了一种基于主题关系的中文短文本图模型实体消歧方法。该方法首先使用由TextRank算法[15]提取出的关键词作为语料库进行主题推断,然后使用主题推断的结果与语义匹配模型给出的评分相结合构建消歧网络图,最终通过搜索排序确定最终的消歧结果。短文本实体消歧方法的模型结构如图1所示,语义匹配模块用于计算待消歧文本与候选实体的匹配分数,主题推断模块用于得到同一文本下的多个实体间的主题相关度。以匹配分数与主题相关度作为图节点与边的权值构建图模型,通过融合消歧得到最优的消歧组合。
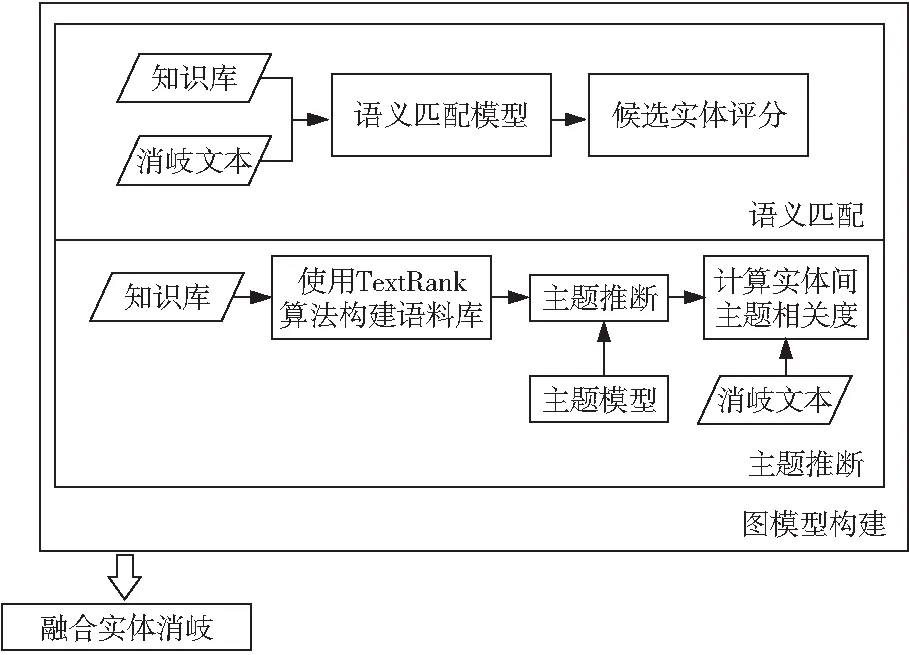
Figure 1 Structure of entity disambiguation usingChinese short text graph model based on topic relations图1 基于主题关系的中文短文本图模型实体消歧模型结构图
3.1 主题推断
本文将潜在狄利克雷分布LDA(Latent Dirichlet Allocation)主题模型[16]与TextRank关键词提取算法相结合对候选实体的描述文本进行主题推断,并根据主题推断的结果进行主题相关度计算。LDA属于机器学习中的生成模型,其根据词的特征分布生成文章的主题分布,本质上是多层级的贝叶斯概率图模型[17]。但在实体消歧中,由于多数同名实体都具有相似的实体描述,因此直接使用实体描述文本作为语料进行主题推断的效果并不理想。为突出同名实体描述信息之间的差异性,在构建语料库时,本文选择了TextRank关键词提取算法对实体的描述信息进行信息增强,使用增强后的关键词作为语料库进行主题推断。
TextRank算法是以PageRank算法为蓝本,针对自然语言处理任务的特点进行修改而形成的一种基于图模型的排序算法[18]。为考虑相邻词之间的语义关系,TextRank算法将关键词提取转化到图模型中进行处理。该算法将文本视作句子的集合T={S1,S2,…,Sn},每个句子又视为单词的集合Si={N1,N2,…,Nm},构建图G=(V,E),其中V为单词集合,E为词之间重要性关系集合,边权值具体表现为重要性评分。重要性评分计算如式(1)所示:
score(Ni)=(1-d)+
(1)
其中,In(Ni)是指向节点Ni的节点集合;Out(Nj)是节点Nj指向的节点组成的集合;d为阻尼系数,根据实际情况对阻尼系数进行赋值,通常取0.85。
根据重要性评分设定阈值H。选择重要性评分排序后前H项为最终结果。在实体消歧中进行关键词提取时重点保留了定语性质的名词和其他实体的指称。
3.2 基于BERT的语义匹配模型
为准确计算候选实体与待消歧实体之间的语义相似度评分,本文将待消歧文本中的所有候选实体与待消歧文本一一拼接,构建了一个二分类模型。采用的模型设计结构是参考经典的match架构改进而来的。以BERT作为模型的输入,取CLS位置的向量以表示待消歧文本与知识库描述信息的全局差异。为保留针对待消歧实体的局部信息,本文通过记录实体出现的开始位置begin和结束位置end,将编码后对应位置向量的拼接结果作为实体的局部特征Entity。将得到的CLS位置的向量与实体位置的向量进行拼接,通过Sigmoid为激活函数的全连接层进行分类。其中增加Dropout层的目的是为了防止模型过拟合,Dropout层的参数设置为0.15。基于BERT的语义匹配模型结构如图2所示,其中N表示句子中的字符长度。
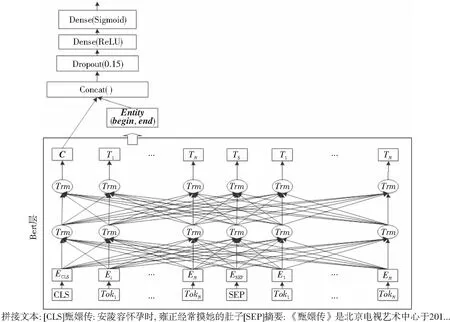
Figure 2 Structure of semantic matching model based on BERT图2 基于BERT的语义匹配模型结构图
如图2所示,对于“甄嬛传:安陵容怀孕时,雍正经常摸她的肚子”这一输入文本,首先将实体“甄嬛传”与知识库中所匹配的描述信息一一配对,模型训练中正样本为待消歧文本与其正确链接对象的描述文本的拼接,负样本为与非正确链接对象的拼接。正样本与负样本的比例为1∶3。最终通过训练好的模型预测待消歧文本与其所有候选实体的描述文本的匹配程度,得到待消歧实体与其候选实体的匹配分数。
3.3 融合实体消歧
本文针对短文本的待消歧实体集合构建图,以待消歧实体为节点,以语义匹配模型给出的评分作为节点的值,以实体与实体的主题相关度作为边的权值。主题相关度topicRela的计算方法如式(2)所示:
(2)
其中,Ta和Tb分别为候选实体a和b的主题推断结果。
消歧结果由语义匹配评分matchi与最大权值和maxWeight(i)构成,计算方法如式(3)所示:
(3)
其中,α为语义匹配评分在消歧结果中的线性权重,i表示第i个候选实体,e为待处理文本中待消歧实体的个数,最大权和maxWeight(i)是以节点i为起点的所有全连接子图的节点和边权值和的最大值。
为降低时间复杂度,本文仅选取语义匹配评分排序前3的节点加入图中。构造的结果如图3所示,其中加粗的子图为最优的消歧组合。
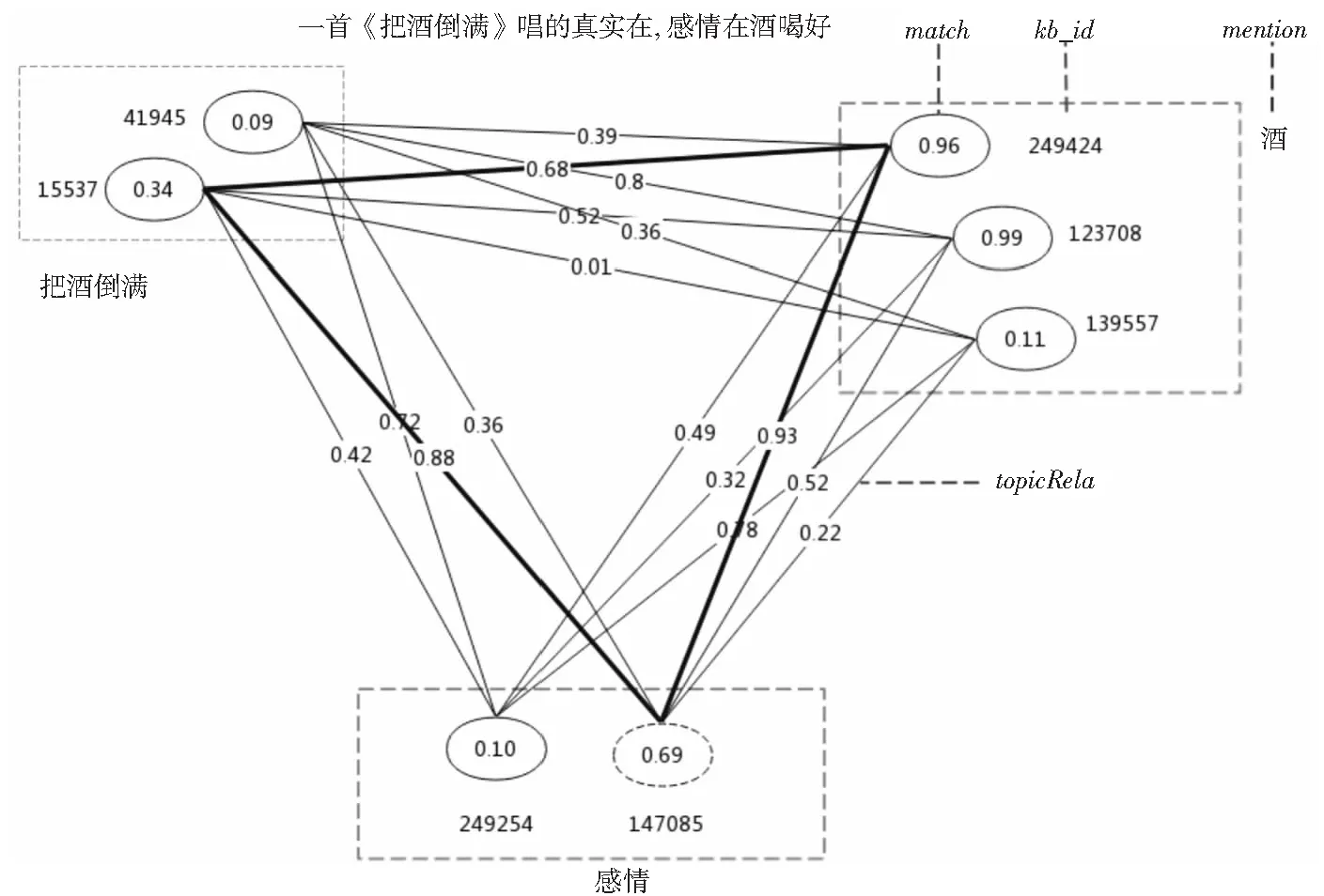
Figure 3 Relationship diagram of candidate entity 图3 候选实体关系图
计算节点与边权值最大的节点组合需要对图进行遍历计算。本文将所有候选实体按待消歧实体构成节点集合作为融合消歧的输入,并计算所有全连接子图的节点和边的权重和。算法伪代码如算法1所示:
算法1实体关系图权值和计算
Input:NodeByGroup,n。/*NodeByGroup:An entity to be detected is a set of nodes in a group;e:number of entities to be detected in a text*/
Output:Weights。/*A path-weight table that contains all of the subgraphs:*/
1.Weights←null;/*To hold the sum of nodes andweights*/
2.First←NodeByGroup[0];/*Visit the first set of nodes*/
3.Weights←First;
4.fori=1 toedo
TempWeiths←null;/*Save the weight of the node after adding the new node*/
5.foreachnode∈NodeByGroup[i]do
6.forweight∈Weightsdo
TempWeights←ComputeWeight(node,weight);
7.endfor
8.endfor
9.Weights=TempVisited;
10.endfor
returnWeights;
对所有节点进行遍历计算可以得到包含候选实体的全部全连接子图与权值和。对包含某候选实体的全连接子图按权值和进行排序,即可得到包含该实体的最大权值和与其对应的全连接子图。
根据得到的最大权值和单消歧实体的评分计算所有候选实体的link值,并将待消歧实体的所有候选实体的link值进行排序,选取结果最大的作为消歧结果。当link值小于0.5时,则判定为NIL实体,即知识库中没有与待消歧实体相匹配的结果。
4 实验与结果分析
本节将通过实验验证基于主题关系的中文短文本图模型实体消歧方法的可行性。
4.1 数据集
本文实验采用 CCKS2020(2020全国知识图谱与语义计算大会)短文本实体链接任务所提供的语料集和知识库。语料集中每条数据包含一条文本和该文本中包含的实体指称,以及各个实体指称在给定知识库中对应的目标实体。知识库中包含每个实体的别名、实体类别和实体描述信息。
语料集由训练集和验证集组成,其中训练集包括7万条短文本标注数据,验证集包括 1万条短文本标注数据。数据集主要来自于真实的互联网网页标题数据,短文本平均长度为21.73个中文字符,覆盖了不同领域的实体,包括人物、电影、电视、小说、软件、组织机构和事件等。本次研究只针对语料集中的非NIL实体进行处理。
4.2 实验环境与参数设置
本文实验所用的系统环境配置为:CPU使用英特尔Core i7-10750H @ 2.60 GHz六核,GPU使用NVIDIA GeForce RTX 2060,操作系统为Windows10。
本文实验使用的语义匹配模型为BERTBASE,学习率前3轮为1e-6,第4轮为1e-7,最大序列长度为512,训练batch_size设置为4。
4.3 评价标准
本文实体消歧模型的评价指标选用精确率P、召回率R及F1值(F1-score)。给定输入文本集Q,对于Q中的每条输入文本q,假设q中有E个实体指称,即Mq={m1,m2,m3,…,mE}。则实体消歧模型的评价指标定义如式(4)所示:
(4)
其中,每个实体指称链接到知识库的实体编号为Eq={e1,e2,e3,…},实体消歧模型输出的链接结果为E′q={e′1,e′2,e′3,…}。
4.4 实验过程
4.4.1 主题数实验
由于主题数的设置直接影响主题推断的结果,进而影响消歧的结果,因此本文根据知识库所构造的主题模型,分别选择K=1,10,20,30,40,50,60,70,80作为主题数进行困惑度实验。根据困惑度指标所选取的主题数能够很好地对主题模型进行检测。在以F1值为实验结果评价指标的实验中,主题数设置为70时效果最优,但考虑到主题推测的实际意义,最终选取困惑度作为衡量主题数的标准。困惑度可以理解为对于一篇文章,所训练出来的模型对文章属于哪个主题有多不确定,这个不确定程度就是困惑度。困惑度越低,说明聚类的效果越好。一个主题模型的困惑度的计算方法如式(5)所示:
(5)
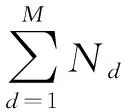

Figure 4 Experiment of number of topics-perplexity图4 主题数-困惑度实验
由图4可知,在K值为60时主题模型的困惑度最低,说明此时主题模型的推断效果最优。
4.4.2 关键词个数实验
TextRank算法构建了用于计算实体间主题相关度的语料库,为验证其中主题词个数H的选取对于消歧结果的影响,本文分别选取主题词个数为[1,15]进行实验,评测标准为F1值。实验结果如图5所示。
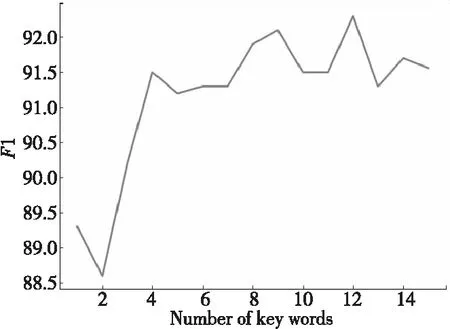
Figure 5 Experiment of number of keywords-F1 图5 关键词个数-F1实验
根据实验结果,本文以关键词个数为12作为最终的TextRank算法关键词抽取算法的阈值H的值。
4.4.3α取值实验
本节对式(3)语义匹配评分中线性权重α的取值进行实验。使用F1值作为判别标准,α取值分别为0,0.1,0.2,0.3,0.4和0.5时的实验结果如图6所示。
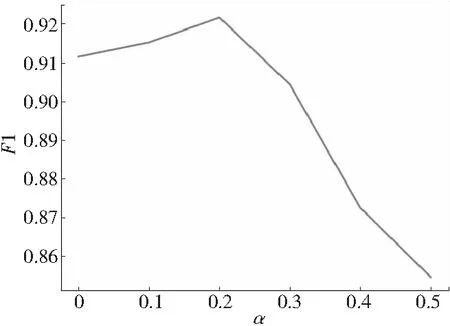
Figure 6 Experiment of different values of α图6 α取值实验
根据实验结果,本文选择0.2作为α的取值。即通过搜索算法得出的权值和maxMatch与语义匹配评分以2∶8的方式得出最终的链接评分。
4.5 实验结果
4.5.1 模型对比实验
为了验证本文所提模型的有效性,本文同时使用TextRNN[19]、TextRCNN[20]及基于BERT的DeepMatch模型在同一数据集上进行实体消歧,实验结果如表1所示。
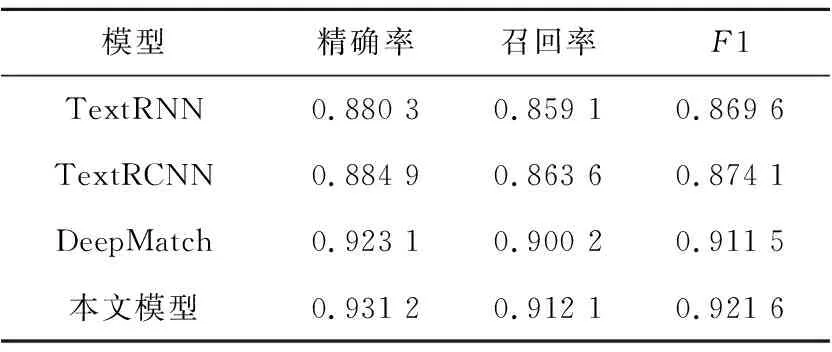
Table 1 Comparison of experimental results
由表1可以看出,使用经典的句子语义建模方法TextRNN和TextRCNN进行实体消歧的效果相对于引入预训练模型的方法,无论是准确率、召回率还是F1值都有所不足。由于引入了BERT预训练模型,模型能够充分地提取实体上下文特征,其结果优于传统方法的。本文在以BERT为基础的语义匹配方法上,结合主题模型对待消歧实体的主题一致性进行判断,弥补了短文本中上下文特征不足的缺陷。实验结果表明,本文方法在准确率、召回率和F1值上相较于传统方法与DeepMatch方法的都有所提升,由此可见以主题相关度为关系构建消歧网络的多实体消歧方法是有效的。
4.5.2 消融实验
为验证模型中匹配分数和主题关系对消岐任务的贡献,本节对模型的匹配部分和主题关系分别进行实验,模型分别命名为Match和Topic,在Match模型中本文将实体间的主题相关度全部设定为1。在Topic模型中将候选实体与待消岐文本的匹配分数全设为1。实验结果如表2所示。
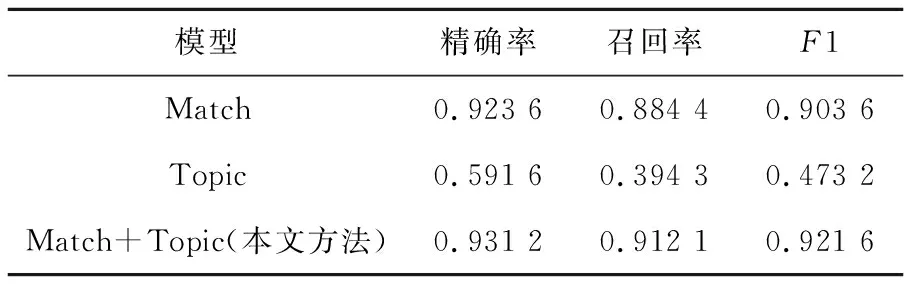
Table 2 Results of ablation experiments
由表2可以看出,在短文本环境中仅使用匹配模型进行消岐的效果并没有达到最优,但匹配分数相对于主题相关度依旧能为消岐任务带来更多的帮助。主题相关度能够帮助模型在全局范围内进行主题一致性计算,能够帮助模型在多实体间进行全局最优的选择,但在整体的消岐结构中依据上下文计算出的匹配分数显然具有更重要的地位。
本文也尝试了使用主题相似度在待消歧文本与候选实体之间建立关系,但在如“一分钟了解唐多令·芦叶满汀洲”的文本中,待消歧实体仅有“唐多令·芦叶满汀洲”,在进行主题推断后,待消歧文本与知识库中的实体对象描述信息仅具有相同的实体名,而无其他对主题推断有帮助的词汇出现,因此在对多个实体进行判断时,主题一致性很难作为链接的判别依据。而在短文本环境中这样的情况很多,因此仅使用主题关系作为构建消歧模型的依据在短文本环境中是不够的。
4.5.3 NIL实体消岐分析
本节针对NIL类别实体的消岐效果进行了实验。为了验证加入NIL实体对本文所提方法的影响,设置了2组实验,其中一组全部使用非NIL数据,另一组使用包括NIL实体的全部数据。最终每个类别的F1评分如表3所示。

Table 3 Results of disambiguation experiments of adding NIL entities and no NIL entities
由表3可以看出,在加入NIL实体数据后模型效果有细微的提升,原因在于在候选实体生成阶段,一部分的NIL实体按照非NIL实体的消岐流程进行计算,最终评分小于0.5的情况被判定为NIL实体;另一部分NIL实体在知识库中无法匹配到候选实体,被直接判定为NIL实体,这一部分实体在全部NIL实体中占有近58%的比例。在不继续对该类实体进行类别判定的情况下,这类实体在一定程度上会使得最终的评分更高。
4.5.4 错误分析与总结
为分析本文方法的不足,对数据中16个类别的实体进行单独实验,实验结果如表4所示。
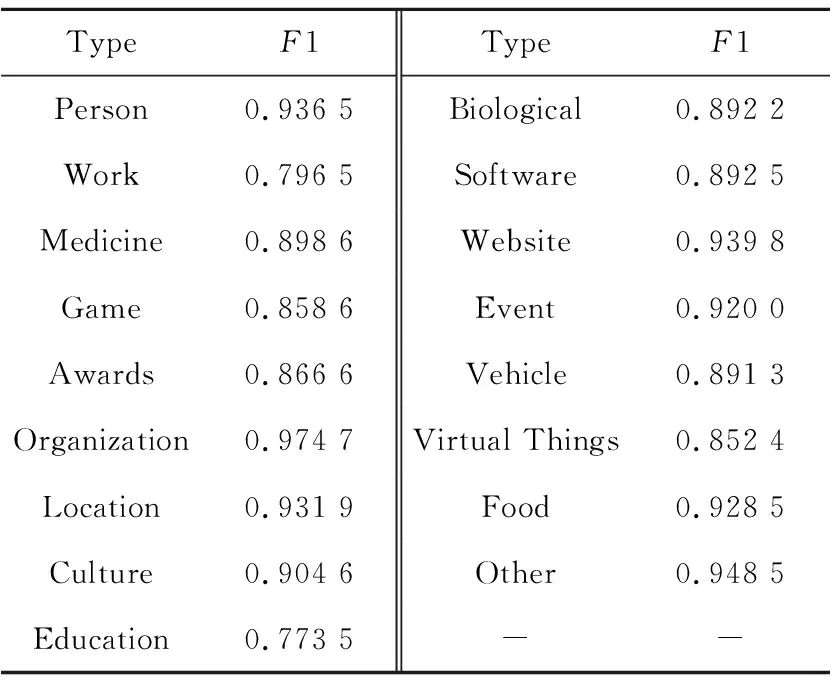
Table 4 Disambiguation results of different types of entities
由表4可以看出,本文所提出的基于主题关系的中文短文本图模型实体消歧方法对大多数类别的实体消岐都是有效的,但部分类别的实体(如Work类实体)消岐效果稍差。为找到其中原因,对Work类别中的样本进行具体分析。如图7所示,文本中出现的实体《我心飞翔》所对应的候选实体中出现了多个同类型的实体。本文所提出的方法无论从主题关系还是上下文特征都无法对这类样本进行很好的区分。但实际情况下,《我心飞翔》在没有明确指代的情况下,广为周知的是孙悦演唱的版本。但是,若要对这类实体进行有效的消岐,除语义特征外还需要考虑实体流行度等特征,因此本文方法难以对这类实体进行有效消岐。

Figure 7 Entity instance of Work class 图7 Work类实体实例
根据实验结果可以看出,本文方法虽然对部分类别的实体消岐效果不理想,但该方法相对于传统方法在短文本环境中仍具有优秀的表现。本文方法适用于知识库信息不完善的短文本实体消岐,通过主题关系与匹配评分相结合构建图模型进行消岐的方法,在知识库无法给出实体关系的情况下,能够对短文本中的实体进行主题一致性计算,从而减少短文本上下文信息不足所带来的误判。
5 结束语
本文提出了基于实体主题关系的中文短文本图模型消歧方法,其优点在于使用主题模型对知识库的实体信息进行主题推断时,通过考虑同文本中其他实体与待消歧实体的主题一致性,避免了短文本消歧中上下文特征不足所带来的误判;同时使用TextRank关键词提取算法对知识库信息进行增强,降低了同名实体中非主题词所带来的影响;结合基于BERT的语义匹配模型所得出的结果构建候选实体的关系图;通过搜索排序寻找出最优的实体组合。实验结果表明,本文方法是有效的,通过考虑候选实体间的主题一致性可以有效地解决短文本环境中上下文特征不足的问题。在下一步工作中,尝试将更多同一语料的消歧实体的共同特征引入方法,以提升短文本实体消歧的效果。
