基于蚁群参数优化的LightGBM辐射源个体识别*
2023-02-08顾楚梅曹建军王保卫徐雨芯
顾楚梅,曹建军,王保卫,徐雨芯
(1.国防科技大学第六十三研究所,江苏 南京 210007;2.南京信息工程大学计算机学院网络空间安全学院,江苏 南京 210044)
1 引言
无线通信领域中,辐射源发出的信号不仅包含了所需的信号信息还承载了辐射源内部器件的固有硬件信息,通过提取这部分信息特征来识别不同辐射源个体的过程称为辐射源个体识别SEI(Specific Emitter Identification)[1]。SEI一般由3个步骤组成:对接收到的原始辐射源信号进行预处理;从预处理后的信号中提取辐射源物理层本质细微特征,即射频指纹RFF(Radio Frequency Fingerprint)特征;使用分类器识别信号,以确定发射此信号的辐射源个体[2]。由于射频指纹的可测性、唯一性和不可篡改性,SEI被广泛应用于军事通信、情报侦察、电子对抗、无线网络安全和设备诊断等军用和民用领域[3]。但是,辐射源信号数据量大、提取到的射频指纹特征维数高等问题增加了辐射源个体分类识别的难度,如何在降低特征维数的同时提高辐射源个体识别正确率是一个至关重要的问题。
通常使用特征选择FS(Feature Selection)方法来解决上述问题。特征选择旨在根据某种评价标准从原始特征空间中消除不相关和冗余特征,选出高相关性特征组成特征子集,以获得比使用所有特征更好的性能[4]。特征选择方法通常分为3类:过滤式、封装式和嵌入式。过滤式方法通过评估每一特征的鉴别能力过滤掉鉴别能力差的特征。该方法运算时间短、独立于学习算法且具有高泛化性,但依赖具体的度量标准。典型的过滤式特征选择方法有方差分析、互信息和卡方检验等[5]。封装式方法由搜索策略和学习算法组成,将特征选择封装到学习算法中,通过学习算法的预测结果进行评估,并使用搜索策略调整特征子集。该方法所选择的特征子集性能高且考虑了特征间的相互关系,但计算复杂度高。典型的封装式方法有递归特征消除等[6]。嵌入式方法将特征选择嵌入到学习算法中,学习算法结束的同时也得到了特征的重要性值。该方法效率较高、特征分辨力好,但依赖于指定学习算法。典型的嵌入式方法有:基于惩罚项的方法,例如Lasso等;基于树模型的方法,包括决策树DT(Decision Tree)、随机森林RF(Random Forest)、梯度提升决策树GBDT(Gradient Boosting Decision Tree)、极端梯度提升XGBoost(eXtreme Gradient Boosting)和轻量级梯度提升LightGBM(Light Gradient Boosting Machine)等[7]。
嵌入式特征选择方法解决了过滤式方法结果中冗余度较高及封装式方法计算复杂度较大等问题,逐渐成为了特征选择的研究热点。文献[8]为改进现有的网络入侵检测多分类方法,提出了一种融合RF和GBDT的入侵检测模型,首先使用GBDT对特征进行重要性排序,并使用递归特征消除法进行特征选择,然后使用RF进行特征变换,分类器选用GBDT,最后验证了该方法的优越性。文献[9]提出了一种基于XGBoost和RF特征选择的堆叠模型,计算XGBoost模型和RF模型特征重要性值的调和平均数,并将得到的调和平均数作为新的重要性值进行特征选择。相比于XGBoost和RF等特征选择方法,该模型的F1值有所提升。文献[10]提出了一种基于XGBoost和RF相结合的物联网入侵检测方法,使用XGBoost对特征进行重要性评分并选出最优特征组成特征子集,使用改进的RF算法进行分类,该模型能有效进行特征选择并合理分类。文献[11]针对从传感器中提取的特征数较多导致在学习过程中可能出现的过拟合问题,使用LightGBM特征选择方法来减少特征集的维数,实验结果表明LightGBM方法可以产生比现有Boosting算法更好的结果。文献[12]设计了一种基于LightGBM的特征选择方法来加快入侵检测系统的训练和测试,根据特征重要性值对特征进行排序,依次选取前h(h∈N*)个特征重要性值大的特征查验训练精度直到不再改善,根据实验结果选取了前12个特征重要性值大的特征构成最优特征子集并输入到分类器中,不仅有效缩减了特征维度还优化了精度。
上述几种基于树的嵌入式特征选择方法在各自研究背景和数据集上均能得到较优的特征子集。在辐射源个体识别领域,为进一步提高分类识别的正确率和运算效率,本文提出了一种基于蚁群参数优化的LightGBM辐射源个体识别方法ACO-LightGBM(Ant Colony Optimization_Light Gradient Boosting Machine)。该方法结合了提升小波包变换、蚁群算法、LightGBM方法和特征选择思想,主要过程如下:
(1) 选取12个统计特征参数和标准化相对能量,结合提升小波包分解与重构方法提取特征并构建特征参数体系。
(2) 使用蚁群ACO(Ant Colony Optimization)算法优化LightGBM参数,包括最小叶子节点数据量(χ)、决策树的数量(δ)、学习率(ε)、L1正则化项的权重(γ)、L2正则化项的权重(λ)和最小叶子节点样本权重和(η)。参数的取值将影响特征选择和最终的分类结果。
(3) 使用优化后的LightGBM获得每个特征重要性值并进行排序,使用序列后向搜索策略进行特征选择,比较搜索过程中各个特征子集的分类正确率,最后得到最优特征子集。
(4) 采用不同信噪比下的电台数据集,对比GBDT、XGBoost和LightGBM特征选择方法,综合考虑分类正确率和特征个数等评估指标,实验结果表明本文所提方法性能更优。
2 LightGBM模型描述
针对GBDT方法在处理大数据或高维特征时效率低和扩展性差的问题,研究人员对GBDT算法进行优化,提出了LightGBM。LightGBM中的直方图(Histogram)、基于梯度的单侧采样GOSS(Gradient-based One-Side Sampling)等算法的提出解决了上述问题[13],且提供了度量标准来衡量模型中特征的重要性。
2.1 直方图算法构建决策树
每个样本信息包含了样本的特征取值、一阶梯度值和二阶梯度值。直方图算法将连续的浮点特征值离散化为k个整数,即将数据划分为k个区域,每个区域构成一个bin,并构造一个宽度为k的直方图,如图1所示,每个bin中所包含的信息为样本个数、一阶梯度之和及二阶梯度之和。离散化后的值作为索引在直方图中累积统计量,遍历一次数据后,直方图累积了所有需要的统计量;然后将每一个bin对应的直方图作为分裂点计算分裂增益,候选分裂点个数为bin个数减1,遍历寻找最优分裂点。直方图算法优化了GBDT等算法按照样本不同取值进行分裂的方法,需要遍历的分裂点个数更少,且使用整数代替原始数据的浮点值,减少了计算量和内存消耗[14]。

Figure 1 Construction process of histogram图1 直方图构建过程
在直方图基础上,LightGBM使用了带有最大深度限制的按叶子生长(leaf-wise)策略代替GBDT中按层生长(level-wise)的决策树生长策略。2种生长策略的对比如图2所示。level-wise策略通过分裂每一层的叶子节点来构建树,不加区分地处理同一层叶子将消耗大量资源来分裂信息增益较低的节点。而leaf-wise策略从当前所有叶子节点中找到分裂增益最大的叶子进行分裂。相比于传统方法,leaf-wise在分裂次数相同的情况下不仅避免了大量计算还降低了误差。为避免leaf-wise方法生长出深度较大的决策树而引起过拟合问题,通过增加最大深度限制进行约束[15]。
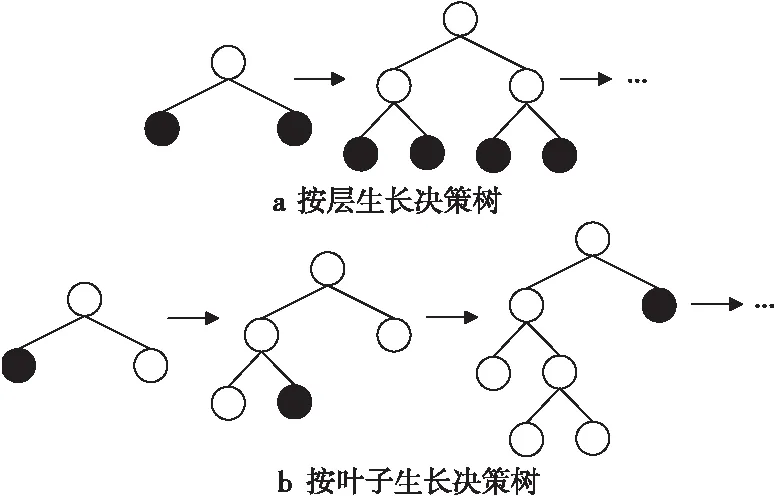
Figure 2 Comparison of decision tree growth strategies图2 决策树生长策略对比
LightGBM中的决策树基于给定的训练数据集通过多次迭代进行构建,在每一次迭代中使用损失函数的一阶和二阶梯度信息计算当前树的残差并根据残差值来拟合一棵新树加入到当前迭代树中。迭代树是由Z轮迭代生成的Z棵决策树叠加而成[16]。
2.2 GOSS算法
GOSS算法的主要思想是排除权重较小的数据,用权重大的数据计算信息增益。GBDT中每个数据虽然没有原始数据权重,但都有不同的梯度值。根据信息增益的定义可知,梯度较小的数据在计算增益时发挥的作用较小,故可以剔除这些数据而留下梯度较大的数据,但剔除数据通常会改变数据集的分布。
使用决策树来学习一个从输入空间Xc到梯度空间G的映射函数,数据集{x1,x2,…,xi,…,xn}的数据个数为n,xi是空间Xc中维度为c的向量。每一次梯度提升迭代中,在当前模型中损失函数负梯度输出的值表示为{g1,g2,…,gi,…,gn}。GOSS算法首先将数据按照梯度的绝对值从大到小进行排序,然后保留前a个梯度绝对值较大的数据记为特征子集A,从剩余小梯度数据中随机选取b个记为特征子集B,在集合A∪B上计算特征j在分裂点d的信息增益Vj(d)[17],如式(1)所示:
(1)
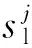
2.3 特征重要性
LightGBM提供了2个度量标准来衡量模型中特征的重要性:split—每个特征在所有决策树中被分割的总次数;gain—特征在所有决策树中作为分裂点所得到的信息增益。一个特征在所有决策树中被分裂的次数越多或得到的信息增益值越大,此特征就越重要,对预测结果的影响越大[18]。
对于特征j,决策树选择最优分裂点dj*=arg maxdVj(d)并计算得到最大信息增益Vj(dj*),然后在点dj*处将数据分成左右孩子节点。特征j在单棵决策树中节点d的重要性计算如式(2)所示:
IMPim=wd·ΔV
(2)
其中,wd表示节点d的数据量与总数据量的比值,ΔV表示节点d分裂后左右叶子节点相比分裂前原节点的信息增益值。将每棵决策树中特征j的重要性相加得到特征j基于模型LightGBM的特征重要性评分,评分越高,该特征对预测结果越有效[19]。
3 基于提升小波包变换的特征提取
特征提取是辐射源个体识别的关键步骤,提取到的特征直接影响到特征选择和分类器的性能。原始辐射源信号数据量往往很大,辐射源个体识别的关键不在于使用所有数据对辐射源进行描述,而在于使用其中有效特征来识别辐射源个体。特征提取旨在通过变换提取到有效的识别特征,使原始信号从高维数据空间转化到低维特征空间[20]。
辐射源个体识别中特征提取的方法通常有双谱法、提升小波包分析法、Wigner-Ville和经验模态分解法等[21]。基于提升小波包分析法有较好的时频分辨能力和较高的运算效率,本文采用此方法,通过其分解与重构可以获得更多特征信息,扩大了有效识别特征集合[22]。
本文选取了12个统计特征参数:均值、平均幅值、方根幅值、标准差、有效值、峰-峰值,波形指标、脉冲指标、峰值指标、偏斜度、峭度和峪度指标,并使用标准化相对能量。依据统计特征参数和标准化相对能量,结合提升小波包分解与重构,给出了特征参数体系。对于辐射源发出的信号,首先使用先序分解后序搜索算法[23]对数据进行最优基分解,得到最佳小波包树;然后,通过分解与重构将最佳小波包树调整为一棵两层的满二叉树,满二叉树的叶子节点分别记作(2,0),(2,1),(2,2)和(2,3),计算4个频带内系数的统计特征值和标准化相对能量;接着,分别对每一频带内系数进行单支重构,并分别提取相应的统计特征;最后,对原信号重构并提取重构原信号的统计特征。
将重构原信号的12个统计特征参数(标号为1~12)、小波包分解的第2层4个节点系数的各12个统计特征参数(标号为13~60)、4个单支重构信号的12个统计特征参数(标号为61~108)及小波包分解的第2层4个节点系数的标准化相对能量(标号为109~112),共112个特征依次编号。为全面描述辐射源信号信息,在幅值信号、I路信号和Q路信号上分别提取这112个特征并构建特征集set={vi|vi=v1,v2,…,vn},n=336。
4 LightGBM参数优化和特征选择
为提升辐射源个体识别的正确率,可以对LightGBM的参数进行优化,并使用LightGBM算法获取特征重要性值进而进行特征选择,以达到提高算法正确率和运算效率的目的。
辐射源个体识别问题的本质为分类问题。分类器的参数设置和特征子集的选择会直接影响到最终的分类性能,故使用分类器的分类正确率和所选子集中的特征个数作为目标函数。为提升辐射源个体识别正确率和运算效率,根据目标函数,所求问题可以描述为:(1)LightGBM的6个参数为:最小叶子节点数据量(χ)、决策树的数量(δ)、学习率(ε)、L1正则化项的权重(γ)、L2正则化项的权重(λ)和最小叶子节点样本权重和(η),各参数在给定取值范围内取值;(2)从原始特征集合中选择基数为q的一个特征子集subsetq;(3)将各参数取值和特征子集subsetq输入分类器,得到的分类正确率A最大且特征个数q最小。具体数学模型如式(3)~式(5)所示:
maxA(χ;δ;ε;γ;λ;η;subsetq)
(3)
minq
(4)
s.t.|subsetq|=q,1≤q≤n
(5)
其中,A为分类正确率,计算公式如式(6)所示:
(6)
数据输入测试集前,已知正类(Positive)数据和负类(Negative)数据,模型预测的数据也分为正负2类。可以得出4个指标:样本真实类别为正类,模型识别结果也为正类TP(True Positive);样本真实类别为正类,但模型识别结果为负类FN(False Negative);样本真实类别为负类,但模型识别结果为正类FP(False Positive);样本真实类别为负类,模型识别结果也为负类TN(True Negative)。
5 求解模型的算法设计
基于蚁群参数优化的LightGBM辐射源个体识别方法框架如图3所示。首先,对原始辐射源信号使用提升小波包进行特征提取,并使用Z-score标准化对得到的特征数据集进行处理,采用蚁群算法优化LightGBM的6个参数;然后,根据优化后的LightGBM计算得到每个特征的重要性值,在此基础上使用序列后向搜索策略进行特征选择,得到最优特征子集;最后,将最优特征子集输入到分类器中识别辐射源个体。

Figure 3 Framework of specific emitter identification of LightGBM based on ant colony parameters optimization图3 基于蚁群参数优化的LightGBM辐射源个体识别框架图
5.1 蚁群算法优化LightGBM参数
为提升辐射源个体识别的正确率,需要对LightGBM的一些参数进行优化。由于蚁群算法具有信息正反馈、采用并行分布式计算和鲁棒性较强等优点,本文采用ACO算法优化LightGBM的6个参数。
ACO基于蚂蚁觅食行为,设置多只蚂蚁分头并行进行搜索,是一种群智能优化算法。每只蚂蚁会在行进的路径上释放信息素,信息素量与解的质量成正比。蚂蚁路径的选择依据信息素浓度大小(初始信息素浓度相同)和启发式信息,采用随机局部搜索策略,使当前最优解上的信息素浓度较大,后续蚂蚁选择该解的概率也较大。通过禁忌表来控制合法解,所有蚂蚁搜索完一次即迭代一次,每迭代一次需更新信息素,舍弃原蚂蚁,新蚂蚁进行新一轮迭代[24]。
以辐射源个体识别最大分类正确率作为参数优化的目标,引用文献[23]中基于图的蚂蚁系统算法求解,根据优化参数问题构造有向图,如图4所示。

Figure 4 Construction digraph of parameters optimization图4 参数优化问题构造图的有向图
图4中,需要优化的参数个数为6,包括2个离散型参数(最小叶子节点数据量(χ)和决策树的数量(δ))和4个连续型参数(学习率(ε)、L1正则化项的权重(γ)、L2正则化项的权重(λ)和最小叶子节点样本权重和(η)),共设置7个节点,各参数搜索空间大小为n(n=1001),其中参数χ和参数δ的取值为x1,x2∈{x|1≤x≤1001,x∈Z},参数ε的取值为x3∈{x|0.001≤x≤1.001},参数γ和参数λ的取值为x4,x5∈{x|0.00≤x≤10.00},参数η的取值为x6∈{x|0.01≤x≤10.01},x3取小数千分位,x4、x5和x6取小数百分位。有向图的边表示参数的备选取值,路径映射为一个求得的参数组合。eu1表示参数最小叶子节点数据量(χ)的备选取值集中第u(1≤u≤n)个取值。在节点d1处人为设定蚂蚁总数K,每只蚂蚁根据有向图边上的信息素量和启发式信息随机独立地向下一节点移动,构造可行解,直到所有蚂蚁均完成一次行走过程,一次迭代结束,迭代结束后按照一定规则对信息素进行更新。
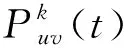
(7)
其中,K表示蚂蚁总数量,k=1,2,…,K;τuv(t)为t(t=1,2,…)时刻边euv上的信息素浓度值;α表示信息素的相对重要程度;ηu为启发式因子,表示选择第u个元素的期望程度;β表示启发式因子的相对重要程度,LightGBM参数优化问题中设定选择每个候选值的期望程度相同,故暂不考虑ηu,设置β=0;tabuk为蚂蚁k的禁忌表,记录蚂蚁走过的边。
信息素量随迭代次数动态变化。当一次迭代完成后,按照一定规则对信息素进行更新,如式(8)所示:
τuv(t)=(1-ρ)τuv(t-1)+Qφ′(tabut)
(8)
其中,ρ(0<ρ<1)为信息素挥发系数;tabut为t时刻选择的参数路径;φ′(tabut)为要进行信息素增强路径的目标函数值,为信息素增量公式;Q为常数,用于调节信息素增量的大小。
ACO算法优化LightGBM参数流程图如图5所示。在ACO算法优化LightGBM参数的过程中,首先初始化ACO的参数:蚂蚁k和蚂蚁总数量K、当前迭代次数Nc和迭代总次数N、初始信息素浓度τuv(0)、信息素相对重要程度α、信息素挥发系数ρ(0<ρ<1)、信息素强度常数Q,并设定LightGBM各个参数的取值范围,其中使用离散化来处理连续型参数。依据路径选择概率公式(式(7))构建某个可行解,并根据目标函数来判断当前解是否为最优解,若是最优值则替换原参数值,若不是则保留原参数值。所有蚂蚁搜索完即迭代一次后更新信息素值(式(8))并记录当前迭代的最优解。算法终止条件为达到设定的迭代次数,算法终止后输出迭代过程中保留的最优参数组合和最大分类正确率。
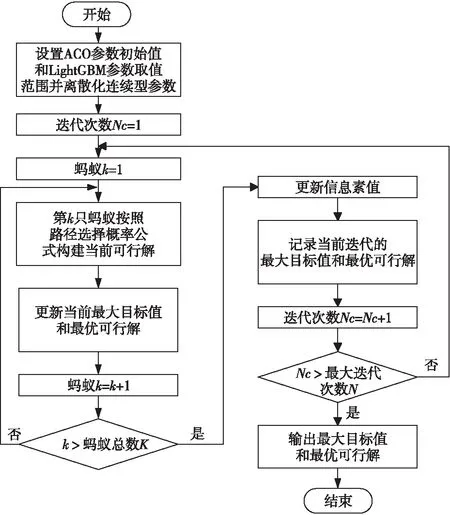
Figure 5 Flow chat of using ACO to optimize the parameters of LightGBM图5 ACO优化LightGBM参数流程图
5.2 特征选择
采用LightGBM构建迭代树的过程来计算样本的特征重要性值,并使用序列后向搜索策略[25]进行特征选择,把分类正确率最高且特征个数最小的特征子集作为特征选择的结果。
此处特征选择问题可以分为2个阶段:评估特征和搜索特征子集。评估特征时,构造迭代树模型并利用树结构对每个特征进行评价。具体过程为:首先使用直方图算法构建决策树;然后,根据一阶梯度值和二阶梯度值来确定分割点,每次都选取具有最大信息增益的特征进行分割,并在每层分裂时使用贪心方法选取最佳分割点。一个特征可能被分割多次,特征被分割的次数越多,整棵树的信息增益就越多,在特征选择过程中优先考虑选取这些特征。在搜索特征子集阶段,首先将评估特征阶段得到的重要性值进行排序;然后采用基于LightGBM特征重要性值的序列后向搜索策略进行特征选择,即对于按照重要性排序后的特征全集,每次剔除一个重要性最低的特征得到一个特征子集,综合考虑基于该特征子集的分类正确率和子集中特征的个数来确定最优特征子集。
6 实验与结果分析
6.1 数据准备
实验在1台i7-4770 3.40 GHz 4核处理器、24 GB内存的电脑上运行,开发环境为Python 3.8。
实验数据来源于2个相同型号的电台辐射源,采集环境为无噪声环境,2个电台发出的信号在10种不同的采集状态下获得,10种采集状态下的信号具体参数如表1所示。

Table 1 Signal parameters
原始数据在无噪声环境中采集得到。为验证所提方法在噪声数据上的效果,添加高斯白噪声将信噪比分别调整为10 dB和5 dB,并分别进行特征提取得到相应特征集合set10dB={vi|vi=v1,v2,…,vn}和set5dB={vi|vi=v1,v2,…,vn},n=336。
6.2 特征值标准化
为统一数据样本的数量级、增加可比性及加快算法的收敛速度,对特征值进行Z-score标准化处理[26],如式(9)所示:
(9)

Z-score标准化将数据转换到某个范围,且不会改变原始数据的排列顺序。标准化后,不同数量级的特征在数值上进行了统一,寻优过程更为平缓,更容易正确地收敛到最优解。
6.3 基于LightGBM重要性度量的特征选择
对于无噪声特征集合setoriginal={vi|vi=v1,v2,…,vn},n=336,根据式(1)和式(2)计算每个特征的重要性值,图6绘制出了前20个最重要特征的特征标号-特征重要性值柱状图[27]。
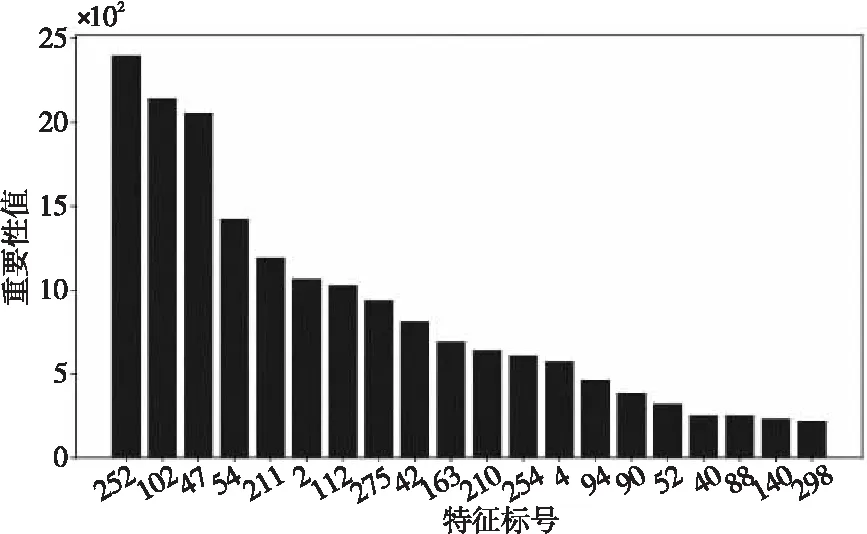
Figure 6 Ranking of features according their importance图6 特征重要性排序
为获得最优特征子集,将计算得到的特征重要性值从小到大进行排序,并使用序列后向搜索策略进行特征选择。每次将重要性值最低的特征删除得到相应的特征子集,并计算基于该特征子集的分类正确率,综合考虑该分类正确率和特征子集的大小选出最优特征子集。特征选择的结果如表2所示。

Table 2 Results of feature selection
表2中,当特征重要性值为0时,表示将所有特征输入到分类器的分类正确率为98.0%;剔除重要性低的特征可以有效提高分类性能,当选择前28个重要性值大的特征,并将这28个特征组成的特征子集输入到分类器中时得到最高正确率98.8%。由此可见:高维特征集中包含的不相关或冗余特征会影响模型性能,使用特征选择方法不仅提高了辐射源个体识别的分类正确率,同时特征维数的减少也提高了运算效率。
6.4 蚁群算法优化LightGBM参数
为提高辐射源个体识别的分类正确率,使用蚁群算法来优化LightGBM参数。待优化的参数信息如表3所示。

Table 3 Parameters of LightGBM to be optimized
首先初始化蚁群算法的参数:蚂蚁总数量K=100,迭代总次数N=100,初始信息素浓度τuv(0)=1,信息素相对重要程度α=1,信息素挥发系数ρ=0.8,信息素强度常数Q=1。基于噪声信号数据集,利用蚁群算法对LightGBM模型参数进行优化后,辐射源个体识别正确率随蚁群算法迭代次数的变化趋势如图7所示。

Figure 7 Curve of accuracy of SEI changing with the iteration times of ACO图7 辐射源个体识别正确率随ACO迭代次数变化曲线
从图7可以看出,利用ACO优化后的LightGBM模型可以获得比未优化模型(98.0%)更高的分类正确率。随着迭代次数的增加,分类正确率逐渐增加,在迭代次数为80时达到收敛,此时搜索到LightGBM模型的最优参数组合,最高分类正确率为98.9%。采用ACO优化后得到的LightGBM参数取值如表3所示。
6.5 特征选择方法对比分析
对比方法使用基于树模型的嵌入式特征选择方法:GBDT、XGBoost和LightGBM。GBDT是集成算法Boosting的一种,每次训练的目的是找到一个能够减少拟合残差的函数,在获得训练结果的同时可以得到每个特征的重要性值;XGBoost是GBDT的改进方法,具有速度快和支持自定义损失函数等优点;LightGBM是GBDT的改进方法,在不降低预测正确率的同时,大大加快了预测速度并降低了内存消耗。
使用上述3种对比方法与本文方法ACO_LightGBM在无噪声信号数据集上进行特征选择,各方法所得的分类正确率与特征子集中特征个数q(特征个数最大取值为336,该值较大,故还取q=21,41,61,81,101,121,141,161,181,201,221,241,261,281,301,321进行实验验证)的关系如图8所示。
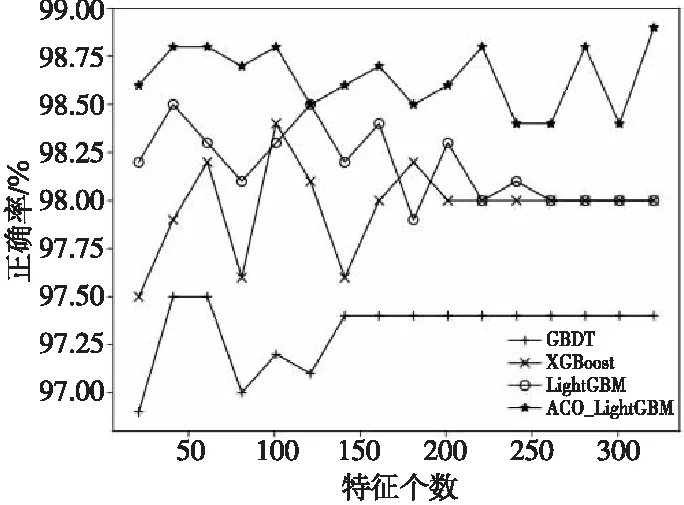
Figure 8 Accuracy comparison of classification using different feature selection methods图8 特征选择分类正确率对比
从图8可以看出,当特征个数q相同时,相比于GBDT、XGBoost和LightGBM,使用ACO_LightGBM特征选择方法选出的特征子集输入到分类器中可以得到最高正确率,使用GBDT方法得到的正确率最低。这说明使用ACO_LightGBM方法选出的特征子集更能表示电台的本质特性,从而能区分2个电台,进而分析电台的危险等级,在现代数字化信息战场取得优势。随着特征个数q的增加,使用各特征选择方法的分类正确率总体上呈现先增后减或先增后趋于平缓的趋势,这也满足了特征选择的目标,即在剔除不相关和冗余特征的同时提高分类正确率。
在3个数据集setoriginal、set10dB和set5dB上分别进行蚁群算法优化LightGBM参数和特征选择等实验,并分别使用对比方法和本文ACO_LightGBM方法得到最优特征子集,实验结果如表4所示。
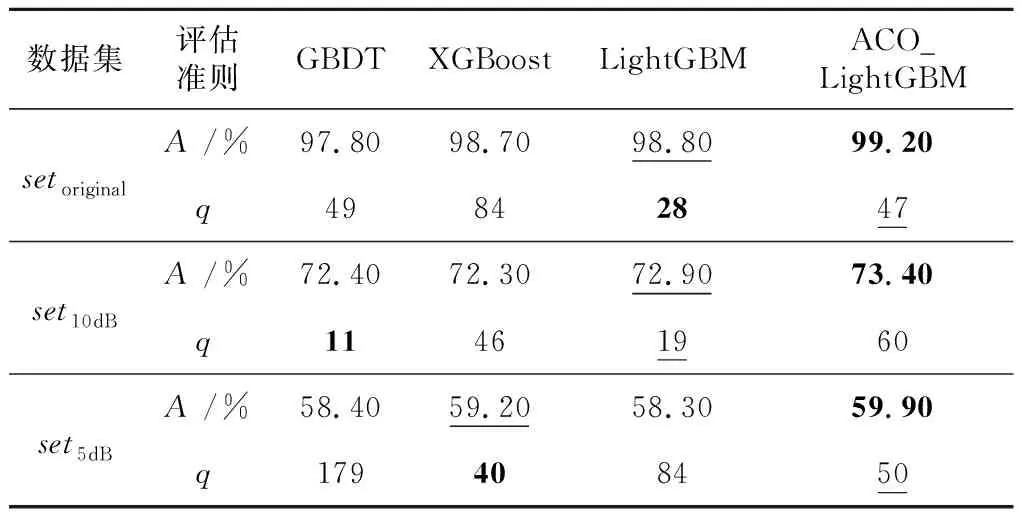
Table 4 Performance comparison of classification using different feature selection methods
表4中,加粗值为最优值,下划线值为次优值。可以看出,ACO_LightGBM方法所得的最优特征子集的分类正确率在3个数据集上均优于对比方法的,最优特征子集的特征个数也为一个相对较小的值。对于数据集setoriginal,ACO_LightGBM方法得到的分类正确率相比于GBDT、XGBoost和LightGBM方法的分别提高了1.40%,0.50%和0.40%,特征个数为次优值;对于数据集set10dB,ACO_LightGBM方法得到的分类正确率分别提高了1.00%,1.10%和0.50%,但特征个数最多;对于数据集set5dB,ACO_LightGBM方法得到的分类正确率分别提高了1.50%,0.70%和1.60%,特征个数为次优值。结合图8和表4可知,当特征个数q取4种方法的最优值时,ACO_LightGBM方法得到的分类正确率仍最大,综合考虑分类正确率和特征个数,ACO_LightGBM方法的性能最优。
7 结束语
为提升辐射源个体识别的正确率和运算效率,提出了一种基于蚁群参数优化的LightGBM辐射源个体识别方法,该方法有以下2点贡献。
(1) 使用提升小波包变换提取特征并对特征值进行标准化,以最大分类正确率和最小特征子集规模为目标函数,建立了使用LightGBM参数优化和特征选择的数学模型。
(2) 使用蚁群算法,基于参数优化问题的构造图,采用路径选择概率公式进行路径搜索,利用信息素更新公式,求解了LightGBM参数优化问题;使用基于LightGBM特征重要性值的序列后向搜索策略求解了特征选择问题。
实验结果表明,相比于GBDT、XGBoost和LightGBM方法,本文提出的基于蚁群参数优化的LightGBM辐射源个体识别方法选出的特征子集分类正确率最高,同时特征个数也相对较少,为提高辐射源个体识别正确率和运算效率提供了新思路。
未来的工作主要包括:在嵌入式特征选择方法的基础上,如何在保证分类正确率的同时进一步缩减特征子集规模;为进一步提升辐射源个体识别的正确率,考虑其他特征选择方法,如封装式方法和混合式方法等;对比信号数据集在不同分类器上得到的分类结果,以确定最适合信号数据集的分类器。
