基于多任务标签一致性机制的中文命名实体识别
2023-02-04吕书宁徐金安陈钰枫张玉洁
吕书宁,刘 健,徐金安,陈钰枫,张玉洁
(北京交通大学 计算机与信息技术学院,北京 100044)
0 引言
命名实体识别(Named Entity Recognition, NER)要求从自由文本中识别出属于特定类别的片段,最早由第六届语义理解会议(Message Understanding Conference,MUC-6)提出,定义了地点、机构、人物等实体类别。自MUC-6以来,人们对命名实体识别的兴趣不断增加,各种学术研究(如CoNLL03[1]、ACE[2]、IREX[3]、TREC EntityTrack[4]等)都致力于此。从隐马尔可夫模型(HMM)[5]、支持向量机(SVMs)[6]和条件随机场(CRFs)[7]到近些年流行的深度学习神经网络[8-10],都为命名实体识别任务在通用类领域的应用,以及各种垂直特定领域的深入推广打下了坚实的基础。
实体边界识别的准确度直接影响了命名实体识别的最终效果[11]。相较于英文命名实体识别,中文命名实体的边界识别效果并不理想,这导致目前中文命名实体识别任务效果不佳。为了解决上述问题,现有一些方法提出利用多任务学习将分词信息融入到命名实体识别任务中,在一定程度上提升了识别效果[9,12]。然而,现有方法中仍然存在两个主要问题:
(1) 相比起分词信息,词性信息能为命名实体识别提供更具判别性的特征。例如,研究表明命名实体大多都是名词词性[13]。然而,现有的方法只考虑了融入分词信息,很少考虑词性信息对命名实体识别任务的影响。
(2) 受标注成本、环境影响,目前同时具备命名实体、分词、词性信息三种标注资源的数据集非常有限,本文意在关注更通用的设定。现有的多任务学习方法针对不同任务的数据集分开进行学习,在这种模式下,无法学习重要的标签一致性信息。例如,命名实体的开始边界也应该对应分词标签的开始边界。
针对上述问题,本文提出一种新的基于多任务学习模式的中文命名实体识别方法: 在融入分词信息的基础上进一步融入词性信息,实现三种任务的联合信息共享;提出标签一致性训练机制,在训练过程中考虑不同标签之间的一致性关系,即实体标签的边界与分词和词性标签边界的对齐关系,指导模型更好地学习多任务表示,改善中文命名实体识别效果。在方法层面,我们的模型主要包含三个模块: ①NER数据集预标注模块,以现有的NER数据集为基础,融入与原始数据相一致的分词、词性标签,用于指导后续多任务一致性学习。②多任务共享学习模块,为命名实体识别任务、中文分词(Chinese Word Segment,CWS)任务与词性标注(Part-of-Speech Tagging,POS)任务构建共享的网络结构,把多个任务的数据表示嵌入到同一个语义空间中,达到多任务联合学习的目的。③联合训练模块,在训练过程中考虑不同任务的解码结果是否一致,实现一致性训练。
为了验证本文方法的有效性,我们分别在新闻和社交媒体两个领域的中文命名实体识别数据集上进行实验,并且考虑了标注数据较为充足的全样本和标注数据较为缺乏的小样本两种环境的实验设置。实验结果表明: ①全样本实验中,相较于基线模型,本文方法可以提升10.28%的F1值,与现有方法相比提升0.76%以上。②小样本实验中,新闻领域模拟小样本数据集取得了F1值为92.98%的实验结果,高于基线系统11.17%,高于现有方法3.05%以上;社交媒体领域真实低资源小样本数据集中F1值达到61.33%,高于基线系统8.84%,与现有方法相比提升2.54%以上。综上所述,本文的主要贡献包括:
(1) 提出一种新的中文命名实体识别多任务学习框架,在命名实体识别模型中融合分词和词性信息,实现多任务联合训练,增强中文命名实体识别效果。
(2) 提出基于标签一致性机制的多任务学习模式,可以捕获不同任务解码结果的一致性关系,增强边界信息学习,优化学习多任务表示。
(3) 在新闻和社交媒体两个领域中验证了本文方法的有效性。同时,实验结果表明,在标注资源匮乏的小样本数据集中本文方法效果更为显著,改善了中文命名实体识别任务可利用已标注数据集资源稀缺、样本量不充足等现状。
1 相关工作
1.1 命名实体识别
现有的命名实体识别方法大致可分为基于统计特征的方法和基于深度学习的方法。在基于统计特征的命名实体识别方法中,Bikel等[5]提出了第一个名为IdentiFinder的基于隐式马尔科夫模型(HMM)的命名实体识别系统,用于识别和分类名称、日期、时间表达式和数字数量。Szarvas等[14]利用C4.5决策树和AdaBoost.M1学习算法开发了多语言命名实体识别系统,通过不同的特征子集训练几个独立的决策树分类器,再通过多数投票方案组合它们的决策。Bikel等[15]运用最大熵理论提出了最大熵命名实体(MENE),MENE能够利用非常多样化的知识来源来做标记决策,取得了很好的效果。近年来,基于深度学习的命名实体识别模型占据了主导地位并取得了先进的成果。与基于特征的方法相比,深度学习方法有助于自动学习更多隐藏的特征信息。深度学习方法多采用字符级别的输入,Ma等[16]利用卷积神经网络(CNN)提取单词的字符级表示,然后将字符表示向量与词向量融合送入循环神经网络(RNN)上下文编码器提取实体。Kuru等[17]提出的CharNER,是一种与语言无关的字符级表示,将句子视为字符序列,并利用长短时记忆网络(LSTM)进行表示的提取。目前,基于深度学习的命名实体识别已成为主流方法。
1.2 基于多任务学习的命名实体识别
现有研究已经开始探索命名实体识别任务与其他任务的关联,并提出基于多任务学习的方法。Collobert等[18]训练了一个Window/Sentence方法网络来共同执行NER、POS、组块分析(Chunk)和语义角色标注(SRL)任务。这种多任务机制让训练算法发现并学习对所有任务都感兴趣的有用的内部表示。Rei[19]发现,通过在训练过程中加入无监督语言建模目标,可实现序列标注模型性能的改进。Lin等[20]提出了一种基于低资源的多语种多任务架构,可有效转移不同类型的知识改善主模型。除了考虑命名实体识别连同其他序列标注任务,多任务学习框架还可以应用到联合提取实体和关系[21]上,或将命名实体识别模型分为实体切分和实体类别预测[22],进一步提升效果。
1.3 中文命名实体识别
现有的中文命名实体识别方法包括基于字的命名实体识别、基于词的命名实体识别、基于字词联合的命名实体识别。Li等[23]通过字级别和词级别统计方法的对比,证明基于字符的命名实体识别方法一般有更好的表现。Huang等[24]利用双向长短时记忆网络(BiLSTM)提取特征,将拼写、上下文、词嵌入和地名词典四种类型的特征融于命名实体识别任务。Lu等[25]在基于神经网络的命名实体识别模型中采用基于字的命名实体识别方案。Zhang等[26]提出的Lattice LSTM网络结构效果较好,其将传统的LSTM单元改进为网格LSTM,在字模型的基础上显性利用词与词序信息,避免了分词错误传递的问题。Zhou等[27]将中文命名实体识别视为一项联合识别和分类任务。Wang等[22]提出了一种适用于中文命名实体识别的门控卷积神经网络(GCNN)模型。在多任务学习方面,Wang等[12]通过将分词和命名实体识别联合学习来融合分词信息。Peng等[28]与He等[29]在字级别的命名实体识别方案中又融入了词的信息,将分词信息作为Soft Feature来增强识别效果。Peng等[9]提出了基于分词任务和中文命名实体识别任务联合训练的模型。
然而,现有的中文命名实体识别方法一般只考虑了单纯将中文命名实体识别与中文分词两种任务相结合,并且没有在学习过程中考虑标签的一致性信息,这可能只会得到次优的结果。针对以上问题,本文提出一种新的针对中文命名实体识别的多任务学习框架,融入分词及词性等词汇信息,同时考虑多任务解码一致性的信息,实现更为有效的多任务学习过程。
2 方法
图1展示了本文方法的框架,主要包含以下三个部分,下面将对每一模块进行具体介绍。
(1) NER数据集预标注模块
利用现有的NER数据集进行预标注处理,通过数据预标注融入额外的与原始数据具有一致性的分词、词性标签,在数据层面实现一定程度的信息共享,用于指导后续多任务一致性学习。
(2) 多任务共享学习模块
基于多任务学习的命名实体识别方法的共享学习模块,由共享表示层及序列解码层构成。多种任务在本模块共享参数与网络结构学习特征,实现多任务学习训练的信息交互共享。
(3) 联合训练模块
在基于多任务学习的联合训练中,融入基于标签一致性机制的训练方法,增强基于多任务学习的命名实体识别方法的识别效果。
2.1 NER数据集预标注模块
现有的多任务命名实体识别方法针对不同任务的数据集分别进行学习,不利于学习标签一致性信息。本文首先设置NER数据集预标注模块,在原有的NER数据中融入额外的与命名实体标签相一致的分词、词性标签,便于模型学习标签一致性信息。具体的流程如图2所示。

图2 NER数据集预标注流程图
2.2 多任务共享学习模块
在预标注的基础上,我们构造多任务共享学习模块,针对不同任务联合进行学习。多任务共享学习模块包括共享表示层与序列解码层两个部分。在以下叙述中,将输入序列记为A={a1,a2,…,an},其中,an表示序列A的第n个字。A表示一条预标注NER数据集D的输入,或者原始分词数据集NCWS或原始词性标注数据集NPOS的输入。
2.2.1 共享表示层
BERT层传统的静态词向量通常无法表征一词多义,本文选用基于BERT[30]的预训练语言模型进行特征学习,以表示上下文相关语义。对于输入序列A={a1,a2,…,an},将序列统一处理为: 开始token为特殊分类嵌入符“[CLS]”,结束为特殊分隔符“[SEP]”的形式进行编码。BERT采用多头自注意力(Self-Attention)机制来学习每个字与其他字的依赖关系和上下文语义,然后通过前馈神经网络对Attention计算后的输入进行多个不同线性变换对的投影变换,最终得到序列的全局信息,如式(1)~式(3)所示。
(1)
MultiHead(Q,K,V)=Concat(head1,…,headn)WO
(2)
(3)
经过BERT层编码计算,我们将A转换为M={m1,m2,…,mn}。
BiGRU层在BERT层基础上,我们增加双向门控循环单元(BiGRU)层[31],进一步学习多任务之间的共享信息。我们将BERT层的输出序列M作为BiGRU层的输入,对于时刻t的输入,计算如式(4)~式(7)所示。

2.2.2 序列解码层

其中,y是预测的标签序列,T是模型参数。针对不同任务,分别以式(9)~式(11)为三个优化目标:
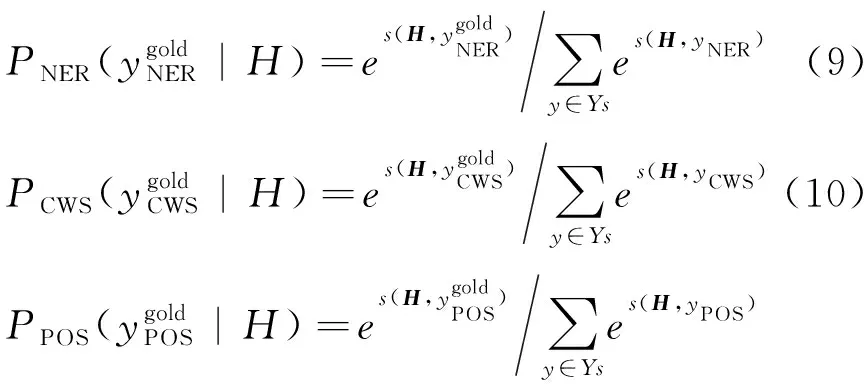
(11)
使用pNER(yi|xi),pCWS(yi|xi),pPOS(yi|xi)表示不同解码模块将xi标注为yi的概率。
2.3 联合训练模块
在多任务学习基础上,本文提出基于标签一致性的模型训练机制,考虑不同任务的解码标签是否一致。具体而言,我们定义了损失函数如式(7)所示。其中,LNER、LCWS、LPOS分别为命名实体识别任务、分词任务和词性标注任务的损失函数,分别以各自任务的标准(Ground-truth)标签计算损失。
L=w1*LNER+w2*LCWS+
w3*LPOS+w4*LNERconsistency
(12)
LNERconsistency=
(13)

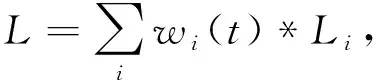
其中,wi(t)代表了每个任务i的权重,Ln(t-1)、rn(t-1)分别代表了任务n在第t-1步时的Loss和训练速度,r越小表示任务训练得越快,其中rn(t-1)∈(0,+∞),N代表任务的数量,T是一个常数,T=1时,w等同于softmax的结果,T足够大时,w趋近1,则各个任务的Loss权重相同。在训练过程的每次迭代中,从给定的任务数据集中抽取一批训练实例,同时训练NER、CWS、POS三个任务来更新参数。
3 实验设置
3.1 数据集和评价指标
为了评估本文方法的有效性,我们在两个领域的命名实体识别数据集上进行了实验,包括Journalism(新闻领域人民日报标注数据集)和Social media(社交媒体领域微博标注数据集),均将其整合成由人名PER、地名LOC、组织机构名ORG三种实体类型标注的形式。分词任务使用的是北大计算语言所制作的1998年《人民日报》标注语料库,词性标注使用的是网络文库语料。表1、表2给出的是各个数据集的详细信息。

表1 命名实体识别数据集

表2 分词及词性标注数据集
本文选用的是BIO标注体系,在测试过程中,只有当一个实体的边界和实体的类型完全正确时,才能判断该实体预测正确。本文采用召回率R、精确率P和F1值来评判模型的性能。各评价指标的计算方法如式(16)~式(18)所示。
(16)
(17)
(18)
3.2 模型实现
本文采用BERT-Base模型。BERT-Base模型共12层,隐层为768维,采用12头模式,共110 M个参数。将BiGRU的隐藏层设为100。在模型训练方面,采用Adam优化器[33]对损失函数进行优化,将Drpout值设为0.1[34]。我们为不同任务设定了不同的学习率,如表3所示。

表3 学习率参数设置
4 实验结果
为验证本文方法的有效性,分别在Journalism(新闻)和Social media(社交媒体)两个领域的中文命名实体识别数据集上进行实验,并设置了标注数据较为充足的全样本和标注数据较为缺乏的小样本两种实验环境。
4.1 全样本实验
在新闻领域的全样本实验中,与以下方法进行对比: 单任务学习方法: ①GRU-CRF,该方法联合GRU和CRF进行命名实体识别。②BiGRU,该方法使用双向GRU网络,捕获过去和将来两个方向的信息进行命名实体识别。③BiGRU-CRF,该方法结合BiGRU和CRF进行命名实体识别。④BERT-CRF,该方法结合预训练语言模型BERT与条件随机场CRF进行命名实体识别。⑤BERT-BiGRU-CRF,该方法结合预训练语言模型,BiGRU和CRF进行命名实体识别。⑥Collobert等[18]的方法采用前馈神经网络,结合预处理和词缀特征进行命名实体识别。⑦Lample等[8]的方法创新性地将BiLSTM与CNN模型结合进行命名实体识别。⑧Shen等[35]的方法将深度学习与主动学习相结合进行命名实体识别。多任务学习方法: ①Wang等[12]的方法在联合训练中融合分词信息进行命名实体识别。②Peng等[9]的方法基于分词和中文命名实体识别联合训练进行命名实体识别。我们将本文提出的基于标签一致性机制的多任务学习方法记为Multi-task(Label consistency)。实验结果如表4所示。

表4 中文命名实体识别全样本实验结果 (单位: %)
从表4可以看出,本文基于标签一致性机制的多任务学习方法Multi-task(Label consistency)获得92.28%的F1值,显著优于其他模型及方法。相比基线模型BERT-CRF、BiGRU-CRF、GRU-CRF、BiGRU分别提升2.44%、7.91%、8.27%、10.28%的F1值;相比BERT-BiGRU-CRF框架下的单任务训练,提升1.06%的F1值;与同样融入词信息的Collobertd等[18]的方法相比F1值提升4.23%;与Lample等[8]的混合模型方法相比F1值提升2.2%;与将深度学习和主动学习相结合Shen等[35]的方法相比F1值提升1.47%;与Wang[12]等和Peng等[9]的联合训练方法相比F1值有0.99%和0.76%的提升。可见,本文方法基于标签一致性机制在数据集阶段即强调实体边界的对齐和词汇信息的增强,以及在多任务学习中进一步共享编码、网络结构与参数来进行中文命名实体识别的有效性。
4.2 小样本实验
考虑到多任务学习可能更适用于标注样本稀缺的环境,我们进行小样本实验,实验结果如表5所示。

表5 中文命名实体识别小样本实验结果F1值 (单位: %)

续表
小样本实验设计如下:
(1) 模拟环境: 在新闻领域人民日报数据集中仅取原数据集20%的数据作为训练集,验证模型效果。
(2) 真实环境: 选用样本语句数仅有新闻领域5%的社交媒体领域微博数据集验证本文方法的有效性。主要对比方法包括: ①Peng等[28]基于中文命名实体识别进行嵌入式联合训练。②He等[29]提出基于BiLSTM神经网络的半监督学习模型,将转移概率和深度学习相结合。③Zhang等[26]重建了12个神经序列标记模型,研究构建有效和高效的神经序列标记系统。
本文方法在低资源小样本的环境设置下提升效果显著: ①在新闻领域的模拟环境中,本文方法可达到92.98%的F1值,相比BERT-BiGRU-CRF模型单任务与Peng等[28]的多任务方法的F1值分别提升了3.05%、3.71%。同时,高于Multi-task(Label consistency)全样本实验0.70%。②在社交媒体领域的真实环境中,相较于现有方法具有显著提升。其中,与Zhang等[26]、Peng等[28]、He等[29]相比分别提高2.54%、5.28%、6.51%的F1值。以上实验结果表明本文提出的基于多任务学习的命名实体识别方法对标注资源匮乏的情况具有更加显著的效果。
4.3 讨论
4.3.1 不同多任务共享方法
在本文选择的模型框架的基础上,我们进一步对比不同的多任务学习训练模式的影响。本文进行了三种多任务共享方法的实验:①基于联合损失函数的多任务学习Multi-task(Joint loss),三种任务使用不同数据集,只进行联合损失的计算,按动态权重共同作用实现模型的优化。②基于参数共享的多任务学习Multi-task(Parameter sharing),在联合损失的基础上,三种任务共享BiGRU层及一个线性层,三种任务增加网络结构与参数的共享,使信息交互共享更加全面充分。③基于标签一致性机制的多任务学习Multi-task(Label consistency),基于本文数据预标注模块进行的多任务共享学习,在数据集阶段即实现实体边界的对齐,以及词汇信息的增强,再进一步共享编码、网络结构与参数,最后结合标签一致性机制计算联合损失。实验结果如表6所示。

表6 不同多任务共享方法测试结果F1值 (单位: %)
从表6可以看出,基于联合损失函数的多任务学习Multi-task(Joint loss)中全样本与真实小样本的F1值比其单任务分别提升0.68%、1.98%。基于参数共享的多任务学习Multi-task(Parameter sharing)中全样本及两种小样本比其单任务F1值分别提升0.84%、0.05%、3.09%,且均高于Multi-task(Joint loss)方法。本文基于标签一致性机制的多任务学习Multi-task(Label consistency),在全样本及两种小样本中分别比其单任务提升1.06%、3.05%、3.83%,比上述两种共享方法F1值涨幅更大,提升效果更显著。综上可见,多任务学习共享信息越充分,越能获得更好的表示学习及性能优势。训练效率也是评估的重要指标,基于本文方法的多任务学习模式,共同处理三种任务,共享编码特征及网络结构,大大减少训练参数量,且样本量越小效果越明显,训练速度越快,从而增加资源利用率。
4.3.2 分割实验
基于真实环境低资源小样本微博数据集,进行了分割实验,具体方法设置如下: ①Single-task,基于BERT-BiGRU-CRF框架的命名实体识别单任务实验。②No POS,在本文方法之中去掉词性信息模块,仅保留实体识别与分词模块。③No Label consistency,遵循本文方法,但在损失的计算中不加入标签一致性损失LNER_consistency参与调整网络。④Multi-task(Label consistency),完整的本文方法。实验结果如表7所示。从表7可以看出,本文方法中不加入标签一致性损失或词性信息模块相较于完整方法F1值均有下降,分别为0.71%和2.38%,验证了融合词性信息模块与标签一致性损失对命名实体识别结果提升的有效性。

表7 分割实验结果F1值 (单位: %)
4.3.3 辅助任务
最后,我们验证该方法是否可以在提高主任务中文命名实体识别结果的同时,也改善分词与词性标注两个辅助任务的效果。实验结果如表8所示,其中包括单任务实验以及基于联合损失函数的多任务学习Multi-task(Joint loss)、基于参数共享的多任务学习Multi-task(Parameter sharing)、基于标签一致性机制的多任务学习Multi-task(Label consistency)三种不同共享方式的多任务实验。

表8 多任务学习测试结果F1值 (单位: %)
从表8可以看出,与单任务相比,Multi-task(Joint loss)为分词和词性标注两个辅助任务带来了0.64%和3%的F1值提升。Multi-task(Parameter sharing)方法下分词与词性标注的结果分别提升F1值0.78%和5.67%。Multi-task(Label consistency)方法下,词性标注结果的F1值提升11.74%。
Joint loss方法虽然能够使用相似任务来提高命名实体识别的准确率,但是这种方案得到的辅助信息较少。Parameter sharing方法是对Joint loss方法学习方式的改进方案,其中增加了网络结构的共享参数,使网络中的部分参数得以进行信息共享,从而让系统能更多地学习到相似任务中的辅助信息,但是在训练的过程中很容易受到一些噪声的干扰。而Label consistency方法在模型训练中融入了边界信息,强调了实体边界的对齐以及词汇信息的增强,故而取得了较好的效果。
从多任务学习共享信息的程度上看,三种方法是逐步递进的,分别从不同层次对被共享任务做出增强信息共享效果的贡献。不同程度的信息共享适用于不同任务,分词和词性标注作为基础任务在低程度的信息共享方式中即可实现有效提升,命名实体识别作为进一步的任务,在越高程度的信息共享中效果提升越显著。
5 结束语
针对中文命名实体识别任务,本文提出了一种新的基于多任务学习模式的中文命名实体识别方法,同时将分词和词性标注信息融入到命名实体识别任务中,实现多任务联合训练。同时,提出标签一致性机制,学习命名实体识别、中文分词和词性标注任务的解码相关性,进一步提升效果。在全样本和小样本环境中的实验结果表明了本文方法的有效性。后续将要研究如何在本文方法中融入更多潜在的词汇信息,深度结合小样本学习的优势,应用到更多资源匮乏的领域进行研究,进一步提高中文命名实体识别的性能。
