三维场景分割中多模态数据融合的2D-3D耦合网络*
2023-01-30李晓霞
李晓霞,陈 强
(广东第二师范学院计算机学院,广东 广州 510303)
0 引言
场景分割,是计算机图像处理的关键任务之一。由于场景遮挡和光照变化等因素的影响,对于复杂的场景,仅仅使用RGB 彩色图像很难达到很高的分割精度。随着三维传感器技术的发展,三维数据逐渐应用在计算机图像处理领域。将二维数据和三维数据融合可以弥补各自的不足,使分割结果具有较高的精度和鲁棒性。但是,多种模式的数据融合面临着许多的技术挑战,比如点云数据和图像数据处理手段上差异巨大,直接将点云数据和图像数据融合就不能很好地利用图像数据提供的高分辨率信息。因此如何有效地融合RGB 二维数据和三维数据成为了三维场景分割的关键。
近些年,大量关于语义分割的研究中开始应用多模态融合技术。多模态融合技术将来自不同传感器的数据进行多级特征融合,通过此方法可以提高三维场景的分割精度。文献[1,2]将深度图像作为附加通道,采用类似于RGB 语义分割的方法实现RGBD 语义分割。文献[3]在RedNet网络中设计了RGB 输入和深度输入两种神经网络分支,并在采样之前将其合并。然而,这些工作仅为颜色和深度通道建立了卷积神经网络模型,并将两者简单拼接在一起,由全卷积神经网络输出结果。这种架构忽略了颜色通道和深度通道之间存在较强相关性的事实,从而丢失了图像的语义信息。
为了充分利用三维几何信息和RGB 图像信息,本文提出了一种基于多模态数据融合的2D-3D 耦合网络。此网络可以有效地利用空间和外观信息从而较好地理解真实场景的语义信息。相比于之前那些更加关注不同模态数据的方法,本文采用平行的网络架构分别处理图像数据和点云数据,并提取全局信息辅助两种模态信息融合,从而提高了场景分割性能。
1 相关研究工作
近年来许多研究提出在场景中直接处理三维点云数据。点云数据主要包含结构特征,提供的信息有限。比如对于表面形状变化不大的物体,仅凭形状数据很难区分。如若将RGB 图像与点云融合,可以充分利用颜色信息和几何信息,使模型具有更强的鲁棒性。文献[4]介绍了一种用于RGB-D 分割的双流网络,首先分别从RGB 和深度图像中提取特征,然后使用变换网络学习不同的模态特征。同样地,FuseNet网络基于SegNet 网络建立的两个分支同时从深度和RGB 图片提取特征[5],然后将他们融合在一起。还有一些方法先将二维图片信息映射到三维空间,然后与点云数据融合后再进行特征提取[6]。
Luca Caltagirone 等[7]将三维数据映射到RGB 图像平面并将其融合后提出了一种不同时期的融合策略。Dai 等[8]先从RGB 图像中提取了二维特征,再将他们投射回三维体素。在这些方法中,虽然RGB 数据和点云数据可以用相似的格式表达,就像(R,G,B)和(X,Y,Z),但他们具有不同的内在属性,表示了不同特征空间中的信息。这些方法不能充分利用RGB 图像数据中丰富的外观特征信息,导致提取的特征细节不够充分,缺乏系统的特征融合。在大多数情况下,RGB 相机比三维传感器具有更高的空间分辨率。在二维数据升级为三维数据之前,通过从高分辨率的图像提取信息可以显著提高融合算法的性能。
2 本文方法
本节介绍一种基于输入的RGB 图像和点云数据预测语义分割的新方法。虽然点云和RGB 图像具有相似的输入格式,但是处理方法却非常不同的。点云数据是不规则的、无序的,而RGB 图像则是规则的,有序的。如何有效地从两种不同格式的数据中提取有用特征是非常关键的。本文提出了一个多模态数据融合的2D-3D 耦合网络,有效地利用空间信息和外观信息,更好地理解真实场景的三维信息。
本文设计了一个异构双流式结构,如图1所示,给出了网络的总体框架。网络主要包含三大部分:①二维分支,用来提取图像特征;②三维分支,从原始的点云数据中提取特征信息;③特征融合,整合前两个输出的结果,预测最终结果。此结构简单、高效,充分利用了两种数据源各自的优点,并且在数据处理上不会引起偏差。
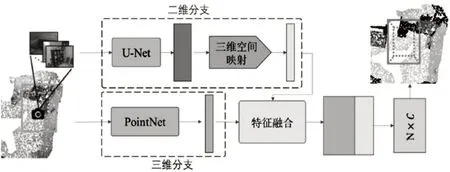
图1 本文方法整体结构图
2.1 轻量级RGB特征提取路径
与现有方法中直接将二维图像和三维点云数据融合不同,本文采用并行的双分支结构来处理二维和三维数据,可帮助网络更加充分的利用不同空间内的数据信息。二维分支的功能是提取二维图像的特征。通常,二维图像相机具有更高的空间分辨率,因此对其进行独立特征提取可以获得更详细的信息。本文采用U-Net 模型对RGB 图像特征进行提取,因为UNet 简单快速并有利于网络对模型进行端到端的联合训练。设输入图像为I∈RH×W×3,其中H和W分别表示图像的高度和宽度,图像的通道数为3。通过U-Net提取到的图像特征如下:
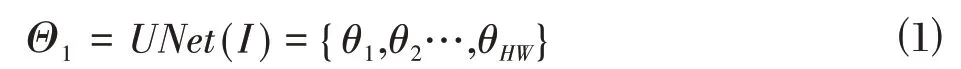
其中,Θ1∈RH×W×C,C代表了图像特征的维度。
不同于传统方法中的将3D 点云数据转换成体素或映射为二维视图,本文直接使用无序的点云作为三维点云分支的输入,避免了数据转换造成的信息丢失。对于输入的点集x∈RN×3,N代表了点的数量。在三维点云分支中,为了提高模型的适用性,减少数据旋转、转换和其他更改的影响,本文采用PointNet中的T-Net网络使数据与原点坐标对齐。
2.2 特征融合
多模式特征学习的目标是在不同模式之间以可控的方式传递和融合特征,使不同模式的信息相互补充,从而有效地提高方法的性能。为了整合二维和三维空间的特征,首先基于投影原理和相机内外部参数建立RGB 特征空间到3D 特征空间的映射。设为原始图像特征,θk∈为映射后的图像特征,其中,NI≤H×W是采样像素数。预测输入点云是进行语义识别和分割的必要步骤,因此建立了输入点云相应的RGB 特征。对于点云中的一点i,在θk域内可找到n个相邻点来提取新特征为:

首先,将RGB特征与点云特征点对点融合后,得到:

其中,θP为通过三维分支提取的特征,θF∈,C1和C2分别表示二维空间和三维空间的特征向量维度,Γ()表示串联操作。
接着,从二维分支和三维分支中提取的全局特征为
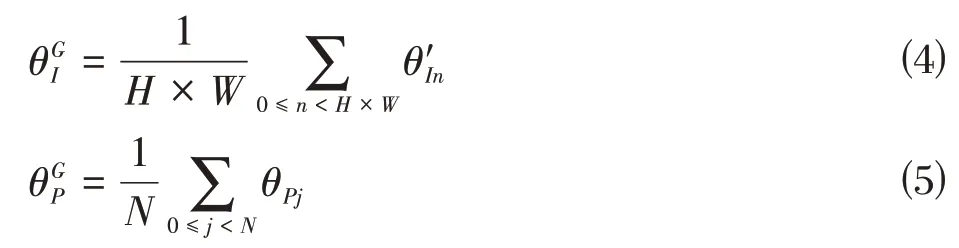
最后,将融合后的特征进行1×1 的卷积操作,以提高局部和全局特征的融合性并对不相关的噪声信息进行过滤。对于融合后的特征,采用MLP层来预测语义标签。MLP 层的通道数为512、128 和C,其中C是最终为点云中的每个点输出语义标签的数量。
3 实验与分析
3.1 数据集
本文的主要任务是基于三维点云数据和RGB 图片数据进行语义理解。因此,需要在数据采集过程中获取摄像头的参数。本文使用目前在2D和3D语义分割最具挑战性的室内场景数据集——Scannet 数据集[9]。该数据集主要基于办公和居住场所,包含1513个室内扫描场景数据,其中的1201 个场景用于训练,312 个用于测试。当训练过程中整个场景的标记点超过30%时,就从场景中随机选取一个与地面平行的1.5m×1.5m区域,从该区域随机采集8192点作为一个训练或者测试的输入样本。与此同时,为了增加训练样本数可将整个区域沿着Z轴进行随机旋转。
3.2 具体实现步骤
⑴训练过程
在训练过程中采用Adam 优化算法。初始学习速率设置为10-3,批大小设置为6。本文提出的模型基于Python 3.6 和PyTorch 0.4.1 实现,以端到端的方式进行训练,并利用带权重的交叉熵损失解决样本类别不均衡的问题。
⑵评价指标
本文采用总体准确度(OA)和平均交并比(mIoU)评价所提出模型的性能。在进行语义分割中,OA表示每一类预测正确数量的占比,IoU 表示目标类的分割域和真实路面语义类的交集率,平均IoU 级可以测量整个数据集中所有语义类的交并比。准确度和交并比可表示为:

其中,变量TP,FP,TN,FN分别表示检测对的正样本、检测错的正样本,检测对的负样本、检测错的负样本。
3.3 结果
表1 给出了ScanNet 数据集中的模型采用不同方法计算得到的性能对比。由表1 可知,本文所提出方法的mIoU 值在大多数类别上要优于基于点云的方法和基于数据融合的方法。这验证了将二维图像特征升级到三维空间进行融合的有效性,对于椅子、桌子之类的具有平面特征的物体,效果更加明显。采用本文方法可达到较好性能的原因在于:①本文模型直接使用三维点云数据,消除了数据转化过程中存在的量化误差;②本文在特征融合过程中利用了全局特征;③在进行特征提取时,平行分支保留了两种数据原有的维度。图2给出了可视化结果,可以看出,该方法对大多数语义类都有很好的分割效果,比如沙发、门、地面、桌子、椅子等。
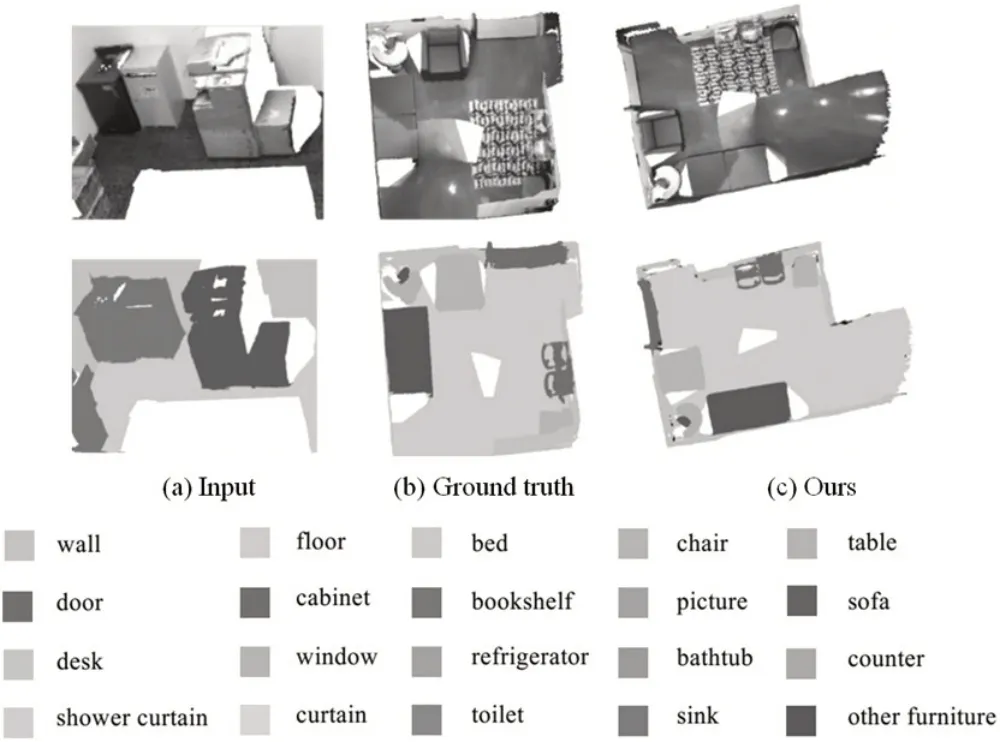
图2 ScanNet数据集可视化结果
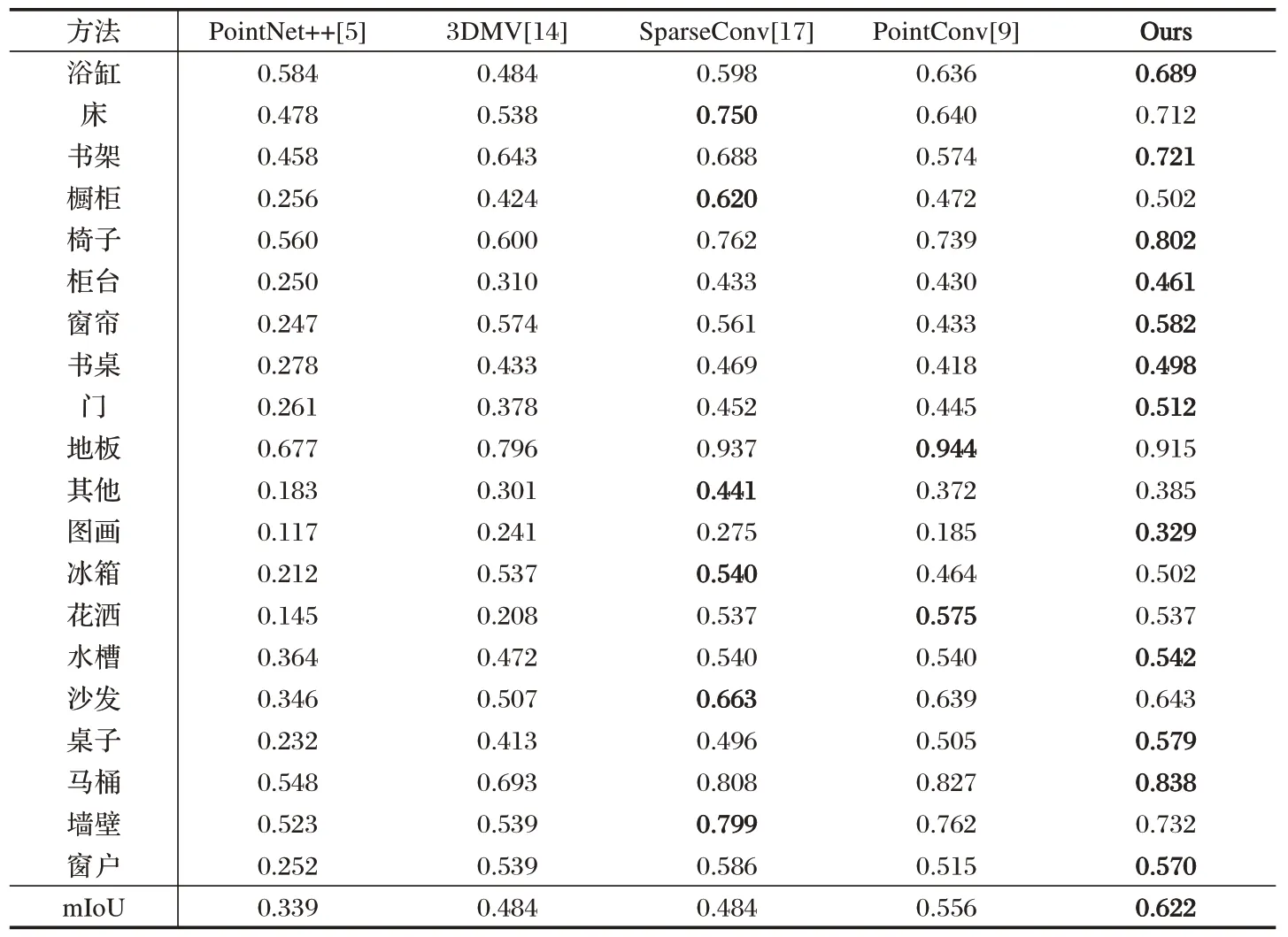
表1 ScanNet数据集中不同模型间的性能对比情况
4 结论
由于点云数据不受环境光的影响,使机器能够较好地感知周围信息,被广泛应用于各种智能系统中。但是点云数据中包含的信息极其有限,其中的几何信息不能将复杂场景完全表达,而RGB 图像中包含的颜色和纹理信息可以对点云信息进行补偿。为了能充分利用两种类型的数据来提高算法的性能,本文提出了一个端到端的3D 的语义理解网络,将点云和RGB图像联合输入,用以预测三维场景中的稠密语义标签。首先,提出了一种平行的异步结构分布处理图像特征和点云特征,保留了数据的原始特征。然后,采用密集特征融合和全局特征融合相结合的方式,建立特征融合网络,利用多模态数据实现场景语义分割。本文提出的方法能够对特征进行密集融合,有效地利用了整个场景中的二维图像特征、几何结构和全局先验信息。实验结果表明,本文方法具有较好的精度,在ScanNet数据集的mIoU值达到了0.622。
