基于CWHC-AM的实体及关系联合抽取方法
2023-01-18李宏宇段利国候晨蕾姚龙飞
李宏宇,段利国,2,候晨蕾,姚龙飞
(1. 太原理工大学 信息与计算机学院,山西 太原 030024;2. 山西师范大学现代文理学院 转改筹备处,山西 临汾 041000)
0 引言
信息抽取可以快速地从非结构化文本中抽取出特定的信息,便于将海量内容自动分类、提取和重构。关系抽取则是信息抽取的子任务,其目的是从非结构化文本中得到三元组形式的知识,将知识表示为(h,r,t),其中,h和t表示头实体和尾实体,r表示h和t之间的关系[1]。例如,在下面的句子S1中,抽取的三元组是(韩信,朝代,西汉)。该任务需要对文本进行全面理解,才能准确抽取出实体及其关系。
S1: 粮仓祖师: 西汉韩信。
关系抽取早期采用流水线(pipeline)的方法,实体抽取和关系抽取分别处理,即先进行命名实体识别(named entity recognition,NER),然后进行关系分类(relation classification,RC)。这种方法容易造成误差传播,并且也忽略了两个子任务之间的内在联系和依赖关系,影响抽取结果。为了解决这些问题,联合抽取的方法被提出,通过实体识别和关系分类联合模型,同时抽取实体和关系,获得了更好的性能。然而,之前的工作忽略了重叠三元组的问题。如图1所示,如果句子中的同一实体对具有多种关系,则属于EntityPairOverlap(EPO)类;如果某一个实体与其他实体构成多种关系,那么就属于SingleEntityOverlap(SEO)类。
Zeng等人[2]是最先考虑重叠三元组问题的团队之一,他们引入了不同重叠模式的类别,并提出一个带有复制机制的序列到序列模型。Fu等人[3]提出一种基于图卷积网络的方法来研究关系重叠问题。虽然这些方法可以有效缓解重叠实体关系无法抽取的问题,但由于没有充分利用实体与关系之间的联系,导致抽取的结果通常是不完整和不准确的。除此之外,很多信息实际上是无法用三元组描述的,如获奖类型的数据需要考虑时间、地点、奖项等信息,然而大多数现有的方法不能有效地处理多元关系[4]。
针对上述问题,本文提出一种基于字、词混合编码和注意力机制(CWHC-AM)的实体及关系联合抽取模型,使用指针网络标注方案,将实体及关系联合抽取问题转化为序列标注问题,根据标注结果抽取三元组信息,提高模型抽取三元组的性能。
本文主要贡献有以下几点:
(1) 提出了一种基于字、词混合编码和注意力机制的实体及关系联合抽取模型,充分利用两个子任务之间的联系。
(2) 采用多层指针网络标注方案,解决重叠三元组问题。针对EPO现象,每一层是一个关系类别对应的指针网络;针对SEO现象,对于每个头实体,反复对其应用相同的尾实体及关系解码。
(3) 针对多元关系问题,使用分解算法将多元关系问题转化成多个二元关系问题进行抽取。
(4) 训练过程中在Embedding层添加扰动生成对抗样本,使神经网络适应这种改变,从而提高模型的鲁棒性。
本文在2020百度语言与智能技术竞赛中提供的关系抽取数据集DuIE 2.0上进行实验,实验结果表明,本文的模型能够更加有效地抽取三元组。此外,与先提取后分类的方法相比,本文的方法不再在第一步提取所有实体,只识别可能参与目标三元组的头实体,从而减轻了冗余实体对的影响。
1 相关工作
关系抽取早期大多采用流水线模型,首先进行命名实体识别,抽取句子中所有的实体;然后进行关系分类,抽取实体间可能存在的关系。流水线方法主要存在以下几个问题: ①将命名实体识别和关系分类分开处理,忽视了两个子任务之间的联系; ②因实体识别不准确,容易产生错误传播; ③不存在关系的实体产生的冗余信息导致错误率提升,影响模型的性能。
目前主流的方法是实体及关系联合抽取。传统的联合抽取模型[5-6]依赖于NLP工具进行特征提取。随着深度学习的不断发展,Gupta等人[7]提出一种多任务递归神经网络(TF-MTRNN)模型,将实体识别和关系分类任务简化为表格填充问题。Zheng等人[8]提出基于神经网络的端到端模型来联合抽取实体和关系。这些方法能够较好地避免传统流水线方法存在的问题,但是关系重叠问题和多元关系没有过多考虑。
2018年,Bekoulis等人[9]提出同时进行实体识别和关系抽取的神经网络模型,不需要人工或工具提取特征,并且用CRF在实体识别层建模,将关系抽取视为多头选择问题,为每一个实体识别潜在的多种关系。2019年,Fu等人[3]提出了一种基于图卷积网络的方法,将文本建模为关系图来研究关系重叠问题。Li等人[10]提出了一种新的关系抽取范式,运用机器阅读理解(MRC)模型,将关系抽取任务转换为多轮问答任务。Dai等人[11]提出PA-LSTM算法,根据每个查询词的位置同时标记实体和关系标签,并取得较好的性能。Yu等人[12]提出一种基于新的分解策略的统一序列标记框架。2020年,Yuan 等人[13]运用注意力机制来学习特定关系的句子表示。即使这些方法提取SEO三元组取得较好的效果,但提取EPO三元组的性能并不佳。
Wei等人[14]提出一种新的级联二进制标记框架,该框架首先识别句子中所有可能的头实体,然后识别每个头实体对应的尾实体和关系。但该方法仅将头实体表示简单地与句子向量相加,忽略了头实体和其他词之间的细粒度语义联系。
目前的多元关系抽取方法大多是针对开放领域的。Gamallo等人[15]针对英语、西班牙语等语种,通过人工制定的规则和依存分析技术完成关系抽取任务。李颖等人[16]基于依存分析的方法,提出面向中文开放领域文本的多元实体关系抽取模型N-COIE,该模型首先对中文文本进行词性标注和依存关系标注,然后按照规则识别基本的名词短语,抽取候选实体关系多元组,最后通过过滤的方法扩充关系库。这些方法受规则的准确性和覆盖面以及依存分析工具的正确率影响较大。
Goodfellow等人[17]在图像识别中加入对抗训练样本以增强模型的鲁棒性。本文借鉴这种方法,在Embedding层添加扰动生成对抗样本,改善模型的鲁棒性。
2 CWHC-AM实体及关系联合抽取方法
本节中,首先介绍多元关系分解策略,然后介绍指针网络标注方案,最后介绍CWHC-AM实体及关系联合抽取模型。
2.1 多元关系分解策略
分析数据集可知,二元关系只有一个尾实体,多元关系的尾实体是一个由多个实体构成的结构体,如表1所示。在多元关系中,value槽位及对应的值是不可或缺的,其他槽位[inWork,onDate,period,inArea]均可缺省。为了后面分解算法的便捷,将缺省的槽位值用“none”表示。

表1 多元关系示例
多元关系抽取是关系抽取研究的热点和难点,目前通过深度学习实现多元关系抽取的研究尚不多见,利用深度学习模型进行三元组抽取已经取得了较好的效果,为了在本文提出的模型中同时实现二元关系和多元关系的抽取,使用分解算法将多元关系分解为多个二元关系。同时,为探究最合适的分解策略,本文提出3种方案: 方案1,将尾实体[inWork,onDate,period,inArea]的槽位值补充到头实体上;方案2,将尾实体[inWork,onDate,period,inArea]的槽位值补充到value槽位值中;方案3,将前面两种方案融合起来,实现信息的补充。三种方案的具体示例如表2所示。

表2 多元关系分解方案具体示例
表2示例的分解结果如表3所示。分析表3可知,方案1和方案2在某些句子中无法做到信息等价转化。方案1在例句1的分解结果中,无法将奖项和对应作品匹配;方案2无法处理例句2中两个复杂三元组都出现“戏曲类一等奖”的情况。只有方案3才能实现复杂三元组与多个简单三元组之间的信息等价转换。因此本文提出的分解算法是基于方案3实现的,算法描述如下:

算法1 多元关系分解算法输入: spo = (entityhead,relation,[entity1,…,entity5])表示包含多元关系类别的元组;输出: spolist = {spo1,spo2,…,spok}表示分解后的三元组集合。 1.spolist = {(entityhead,relation,entity1)}2.(r: e) ∈ {(inWork: entity2),(onDate: entity3),(period: entity4),(inArea: entity5)}3.for 1 to 4: 4. i f e != none:5. add (entityhead,relation-r,entity1),(en-tity1,r,e) to spolist

表3 多元关系分解示例
2.2 指针网络标注方案
首先考虑头实体标注。该任务需要确定头实体的开始和结束位置,采用指针网络标注方案,在标签序列中用1表示头实体的开始位置,2表示头实体的结束位置,文本中其他字符统一标记为0。尾实体及关系抽取采用多层指针网络进行标注,每一层对应一个关系,假设有r种不同的关系类别就会生成r层指针网络,每层又分为两个标注序列。与给定头实体具有某种关系层的第一个序列标注尾实体的开始位置为1,第二个序列标注尾实体的结束位置为1,其他关系层均标注为0。
图2举例说明了本文的标注方案。输入句子包含三元组(“俞敏洪”,“创始人”,“新东方”),创始人是预定义的关系类别,每个字都根据实体和关系信息被标注相应的标签。头实体“俞敏洪”的第一个字符“俞”标注为1,最后一个字符“洪”标注为2。在尾实体及关系抽取中,与关系“创始人”对应的指针网络层的第一个序列中“新”的位置和第二个序列中“方”的位置均标记为1。

图2 指针标注方案
2.3 CWHC-AM模型介绍
模型整体结构如图3所示,模型包括三个部分,分别是编码层、头实体抽取模块和尾实体及关系抽取模块。
2.3.1 编码层
Devlin等人[18]于2018年10月提出BERT模型,在多个NLP任务中都取得了不错的效果。Liu等人[19]于2019年提出RoBERTa 模型,RoBERTa 模型在BERT模型的基础上增加了训练数据和训练批次,删除了结构预测(NSP)任务,引入了动态掩蔽,获得了更好的效果。
BERT中的分词器Tokenizer自带的tokenize方法会自动去掉空格,这可能会导致分词之后的句子与原来句子长度不相等,给序列标注任务带来困难,为了解决这个问题,本文将句子中的空格去除。
编码层的输入是句子序列,由于标注方案的选择,同时为了避免标注出现错误,选择以字为基本单位进行输入,但由于汉语单字存在着歧义性,加入词层面信息可以消解部分歧义[20]。因此本文采用字向量与词向量混合编码的方法,如图4所示。
图4中某个词语w由c1,c2,c3三个字组成,首先采用RoBERTa语言模型提取文本特征生成字向量序列,维度是768,然后使用pyhanlp将句子序列分词,根据词向量表检索得到词语w的词向量,维度是256,然后将字向量与该字所在词的词向量进行拼接得到该字的最终向量。因此,经过编码层的表示可以表示为E=[e1,e2…,en]。相关计算如式(1)~式(3)所示。

图3 模型结构

图4 字向量与词向量混合编码
其中,ew∈dw,ei∈dh+dw,dw为词向量的维度,dh为字向量的维度,表示词语w中第i个字的字向量,ew表示该字所在词的词向量。
2.3.2 头实体抽取模块
本模块的目标是抽取句子中所包含关系的头实体。通过对编码层产生的最终表示E进行解码来识别头实体。更具体地说,通过softmax多标签分类器为每个位置分配标签(0/1/2)来识别头实体的开始和结束位置,如式(4)所示。
P(yi,t)=softmax(WhE+bh)
(4)
其中,P(yi,t)∈n×3,表示输入序列中的第i个位置为标签t的概率,t∈{0,1,2},1表示头实体的开始位置,2表示头实体的结束位置。Wh和bh分别表示softmax函数的权重矩阵和偏置项。
最终,得到位置i具有的标签,如式(5)所示。
(5)

(6)
2.3.3 尾实体及关系抽取模块
(1) 注意力层
在关系抽取任务中,实体包含的语义信息和句子中的每个词与实体间的距离信息都是不能忽视的。因此,将编码层的输出向量E与相对位置向量拼接,再通过注意力层进一步捕获头实体与句子的关系。头实体表示定义如式(7)、式(8)所示。
其中,ph_start,ph_end是相对位置编码向量,分别代表句子中某个字ci与头实体h的开始位置和结束位置的距离。将实体的开始位置和结束位置之间的平均向量表示eh作为头实体h的表示向量,其中estart和eend分别表示头实体h的开始和结束位置向量。

(2) 特征融合层
将注意力层的输出向量Eh与头实体的表示向量相加,得到新的句子表示E3。为了捕获句子更为丰富的语义信息,将句子表示E与句子表示E3进行拼接,有助于对句子的充分理解,同时也避免丢失句子的关键信息。计算如式(12)、式(13)所示。
(3) Bi-LSTM层
在获得句子多层次信息的基础上,需要进一步获取基于上下文语义的编码表示,但RNN存在着梯度爆炸或者梯度消失的问题,从而限制了网络学习长期依赖的问题,而LSTM是非常优秀的RNN变体,通过门控单元解决长期依赖问题。
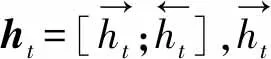
本模型中BiLSTM的输入是式(13)中的E4,送入到BiLSTM,得到包含双向的语义依赖的表示H。其中,H∈n×2dh,dh为隐含层维度。
(4) 解码层
使用两个sigmoid分类器分别计算句子中尾实体的开始位置和结束位置的概率。详细操作如式(14)、式(15)所示。

尾实体及关系抽取模块优化以下似然函数,以识别头实体所对应的尾实体和关系。
(16)

2.3.4 联合损失函数
模型的联合损失由头实体抽取模块的损失函数L1、尾实体及关系抽取模块的损失函数L2组成,具体如式(17)所示。
Ljoint=L1+L2
(17)
采用随机梯度下降法训练模型,优化式(17)使头实体、尾实体和关系的抽取能够相互影响。
2.3.5 对抗训练
模型训练过程中,通过增加对抗训练提高模型鲁棒性。对抗训练首先要生成对抗样本,本文通过在Embedding参数矩阵上加一个扰动radv来生成对抗样本,如式(18)所示。
(18)
由于上式在深度神经网络中实现困难,本文采用Goodfellow[17]提出的一种线性近似方法计算radv,如式(19)、式(20)所示。
其中,ε是超参数的小边界范数,与Yasunaga等人[21]相同,设置如式(21)所示。
(21)
其中,d是Embedding的维度。结合原来的样本和对抗样本,来进行训练,最终的损失函数,如式(22)所示。
Ljoint(w;θ)+Ljoint(w+radv;θ)
(22)
3 实验
3.1 数据集与评价指标
本文选择2020百度语言与智能技术竞赛中的关系抽取任务数据集DuIE 2.0进行实验。数据集的关系集合中定义了48个关系,其中包含43个二元关系和5个多元关系。数据集中的句子来自百度百科、信息流资讯以及贴吧,其中百度贴吧中的句子偏向口语化和非正式性,增加了抽取难度。训练集17万条,验证集2万条,由于评测主办方只公开了训练集和验证集,没有公开测试集,所以本文将原来的验证集作为测试集,将原来的训练集按照近似9∶1划分为新的训练集和验证集。
根据不同的重叠模式关系原则,将句子分为三类,即Normal、SEO和EPO,具体例子如图1所示。表4描述了数据集的统计情况,从表4可以看出,整个数据集有37%的关系是重叠关系。

表4 数据集重叠情况统计
本文后续和其他模型进行实验对比,将精确率P、召回率R和F1值作为实验的评价指标。具体如式(23)~式(25)所示。
其中,s为测试集中句子个数。
3.2 模型参数设置
本文的词向量字典使用的是由苏剑林开源的通过Word2Vec训练好的词向量,即V∈|V|×d,其中,|V|表示词向量的个数|V|=1 056 283,d为词向量的维度d=256。BiLSTM的隐含层维度设置为300,在模型训练的过程中,词向量保持不变,字向量会不断学习更新,模型采用Adam作为优化器,学习率设置为10-5,batch-size设置为16。
3.3 实验结果及分析
为了验证本文提出模型的效果,选择了以下模型进行对比实验:
(1)Pipeline: 本文搭建了流水线模型,通过BERT-BiLSTM-CRF模型进行命名实体识别,获得实体对,然后应用Zhou等人[22]的方法来识别实体间关系,该方法提出一个基于注意力机制的长短时记忆神经网络模型来获取一个句子中最重要的信息。
(2)BERT: 谷歌公开的预训练模型,此模型作为基线模型。
(3)BERT-Gather: 该方法在BERT方法的基础上,引入头实体的语义信息。
(4)BERT-wwm-Gather: BERT-wwm为Cui等人以全词掩盖技术进行预训练的模型[23]。
(5)RoBERTa-wwm-ext-Gather: 中文RoBERTa-wwm-ext预训练模型是由哈工大讯飞联合实验室结合中文全词掩盖技术以及RoBERTa模型发布。
(6)BERT-Gather-BiLSTM: 该方法在BERT-Gather的基础上,加入BiLSTM进一步提取特征。
(7)BERT-Gather-LSTM: 为增加对比性,使用LSTM提取特征。
(8)ERINE: 官方提供的基线模型,提出一种结构化的标记策略来直接微调ERNIE预训练模型。
(9)DGCNN: 是苏剑林提出的一种基于DGCNN和概率图的信息抽取模型。
(10)Etl-Span-BERT: 是由Yu等人[16]提出的,在此基础上使用BERT预训练模型,该方法采用基于span的标记方案将联合抽取任务转化为多个序列标记问题的模型。
(11)CasRel: 是Wei等人[14]提出的一种级联式解码实体及关系抽取方法。
(12)TPLinker: 是Wang等人[24]提出的一种统一的联合抽取标注框架,可实现单阶段联合抽取。
(13)BSLRel: 是张龙辉等人[25]提出的一种基于神经网络的端到端的关系三元组抽取模型,该模型经过数据增强、模型融合和答案后处理之后,在线上评测中最终排名第5。
(14)OurModel: 本文提出的模型,采用RoBERTa作为预训练模型,编码层采用字向量与词向量混合编码的方式,直接将编码层的输出进行解码,得到头实体,在抽取尾实体和关系时,引入头实体的位置信息,并利用注意力机制学习头实体和句子序列的联系,再通过BiLSTM进一步提取特征,解码得到尾实体和关系。
对上述的方法进行了实验,具体结果如表5所示。

表5 实验结果对比 (单位: %)
通过表5实验结果可以发现,联合抽取方法优于流水线方法,并且Our Model的F1值优于其他所有模型,相比基线BERT模型提升了6.79%,说明了本文方法的有效性。从BERT与BERT-Gather的对比可以看出,在抽取尾实体及关系的时候引入头实体的语义信息对三元组抽取有很大作用。在BERT-Gather、BERT-Gather-LSTM和BERT-Gather-BiLSTM的对比中,可以看出LSTM的加入是有必要的,可以学习到更多语义信息,并且BiLSTM优于LSTM。从表中还可看出,RoBERTa预训练模型比BERT、BERT-wmm模型效果更好。
此外,还与在实体及关系联合抽取任务中取得较好结果的模型进行了对比。与CasRel和TPLinker相比,Our ModelF1分别提升了4.23%和8.41%。CasRel仅将头实体表示简单地与句子向量相加,而本文模型通过深层次的网络提取特征,对于中文实体及关系抽取有更好的效果;TPLinker通过链接3种类型的Span矩阵来抽取实体关系三元组,在NYT数据集中表现出较好的性能,而在DuIE 2.0数据集上表现不佳。通过分析两个数据集发现,在NYT数据集中句子长度大于50的只有17.3%,在DuIE 2.0数据集中却占有57.9%。对于一个较长的句子,Span矩阵中可能存在许多无效的Span,出现矩阵稀疏问题,从而影响模型的学习。与BSLRel相比,本文模型的F1提升了3.01%。实验结果表明,本文方法在DuIE 2.0数据集表现出更好的性能。
为了评估本文模型每部分的贡献,进行了消融实验,对比结果如表6所示,可以看到,分别去掉对抗训练、字词混合编码、相对位置向量、注意力机制和BiLSTM模型F1值都会下降,说明每一部分的加入都对模型性能的提升有所贡献,充分验证了本文模型的有效性。使用注意力机制可以充分学习到头实体与句子序列的相关性;字向量和词向量的混合编码方式可以捕获更丰富的语义信息;引入头实体的相对位置信息可以使句子序列考虑到更多的头实体语义信息;加入BiLSTM能更好地学习到长序列的信息;对抗训练可以提高模型的鲁棒性。

表6 消融实验的F1结果对比 (单位: %)
图5为5种模型在各种二元关系类别上F1值的对比。分析可知,在二元关系中总部地点、主角、人口数量、朝代、出品公司这五个关系类型抽取效果较差,而对官方语言、号和邮政编码3类关系的抽取效果较好。同时可以看出本文模型性能比较稳定。
通过对含有总部地点或者主角关系的文本进行分析,发现这些句子的关系界限不是很清晰,所以可能导致抽取结果欠佳。而对于出品公司以及朝代进行分析,发现这两个方面的句子中存在实体别名问题,因此可能导致抽取结果存在偏差。通过对人口数量方面的抽取结果进行分析,发现大部分的错误都是因为在识别尾实体的位置时采用就近原则造成的,例如,尾实体应该是“3.6万人”,但识别成“3.6万”。

图5 二元关系的F1值对比结果
图6为5种模型在5种多元关系类别上F1值的对比。分析图6可知,多元关系的抽取效果整体较差。对于多元关系的三元组,必须所有的实体和关系都精确匹配才认为抽取正确,因此可能导致多元关系的抽取效果不太好。

图6 多元关系的F1值对比结果
3.4 对不同句子类型分析
为了验证模型处理重叠问题的能力,在测试集上进行了进一步的实验。主要对F1值进行对比,结果如图7所示。参与比较的模型均有能力处理重叠三元组,本文模型在Normal、SEO和EPO均优于其它模型。

图7 各个重叠类别的F1值对比结果
为了分析句子长度对模型性能的影响,本文将句子长度划分为5个子类,每个子类的长度分别是<12,12~49,50~99,100~199和≥200,图8描述测试集中每个子类中句子的数量,进一步对比在不同模型下不同句子长度的抽取效果,如图9所示。

图8 测试集统计
由图9可知,性能的整体趋势随着句子长度的增加,F1值在降低。TPLinker在句子长度≥200时,F1值急剧下降,因为句子越长Span矩阵越容易出现矩阵稀疏问题,从而影响模型的学习。人工分析数据集发现,较长的句子,句子结构复杂,准确获取其语义信息困难,导致关系抽取的准确率和召回率均有所降低。较短的句子结构简单,语义表达准确,实体和关系简洁明了,因此抽取的效果要好一些。由此得到启发,写文章时尽量使用简洁明了的短句,少使用晦涩难懂的长句。

图9 各个句子长度类别的F1值对比结果
除此之外,本文根据句子包含的关系三元组的个数,将数据集中的句子分为4个集合,分别包含有1,2,3-5或>=6个三元组,统计结果和对比实验结果如图10所示。

图10 各个三元组数量的对比结果
可以看出,所有模型在集合1上的效果是最好的,在一句话中所有三元组的数量下,本文模型都优于其他模型,因此本文模型能更有效地抽取句子中多个三元组,并且性能较稳定。
3.5 三元组抽取实例分析
本文对不同模型的抽取结果进行了对比,然后通过两个例句来说明BiLSTM和注意力机制加入是必要的,如表7所示。

表7 输出结果示例
观察分析表7中的例句以及抽取结果:
从例句1的抽取结果可以看出,只有BERT模型识别错误,本文模型与BERT-Gather-BiLSTM均正确且全面地抽取出三元组。可能是因为“王妍之”和“君桃”两个实体之间的距离较远,导致BERT模型没有抽取出三元组,因此说明通过BiLSTM能够使模型学习到长序列的信息。
通过例句2的抽取结果发现,BERT与BERT-Gather-BiLSTM均存在着没有抽取到的三元组,而本文模型由于加入注意力机制,对文本语义把握更充分,可以更准确地抽取出全部的三元组。
通过上述实验结果来看,本模型可以有效地抽取三元组,但通过对抽取结果进一步分析,发现也存在一些问题,具体例子如表8所示。例句3中的实体“17717”和“一起去游戏”存在着实体别名问题,由于这个原因导致了抽取结果存在着偏差。例句4中给出的尾实体是“北京市”,而本模型抽取的尾实体是“北京”,其主要原因是在识别尾实体的结束位置时,“京”和“市”的概率都超过了阈值,但根据就近原则将结束位置定位到“京”,因此造成了抽取错误。

表8 输出结果示例
4 结论与展望
本文首先针对多元关系任务,将其分解为多个二元关系进行抽取,然后提出一种基于字、词混合编码和注意力机制(CWHC-AM)的实体及关系联合抽取模型,使用指针网络标注方案,解决重叠三元组问题。该模型将实体及关系联合抽取任务分解为两个相互关联的子任务,前一个子任务是识别所有可能涉及目标关系的头实体,后一个子任务是为每个提取的头实体识别相应的尾实体和关系。
虽然本文在DuIE 2.0数据集上取得较好的结果,但是在对于个别关系类别方面的F1值可以做进一步的提升工作。未来工作中,对所提方法以及模型进行改进,提升模型的性能。由于模型采用就近匹配原则所导致的抽取错误,可考虑使用预测的开始位置概率和结束位置概率之积的排序来产生尾实体,从而提高模型抽取性能。此外,探索更好的多元关系抽取方法也是将来的研究工作之一。
