融合交互注意力和参数自适应的商品会话推荐
2023-01-18李智强王志宏
郑 楠,过 弋,2,3,李智强,王志宏
(1. 华东理工大学 信息科学与工程学院,上海 200237;2. 大数据流通与交易技术国家工程实验室 商业智能与可视化技术研究中心,上海 200436; 3. 上海大数据与互联网受众工程技术研究中心,上海 200072)
0 引言
随着互联网的快速发展和移动设备的普及,用户往往面临海量信息,特别是在选购商品时,难以快速地发现自身实际需要的商品,从而引发信息过载问题[1]。因此推荐系统应运而生,既可以为用户推荐所需要或感兴趣的商品,又可以为商品提供者提高曝光率,提高交易率。传统的推荐算法通常依赖于对用户的自身特性和历史交互商品特征的分析,在现实应用中需要较长时间周期,表现不佳。同时用户对隐私更加注重,常常匿名访问网站,或只是在有购买行为时才提醒用户登录,导致用户的浏览信息采集缺失,或登录的用户只有短期的交互信息,以致用户的浏览信息采集较少。在以上情况下,传统的推荐算法如协同过滤等常表现不佳。会话是将匿名用户的交互序列按照时间顺序切分成指定长度的相对较短的序列,如图1中的会话序列。基于会话的商品推荐算法旨在通过对指定时间内的匿名用户的行为序列研究来预测用户下一个交互的商品[2],既能够学习用户的短期兴趣,又能够保留用户交互的时间顺序信息,以此学习商品之间的顺序依赖,从而引起广泛的关注。
近年来,图神经网络的提出和广泛应用使基于图神经网络的推荐算法研究成为研究的热点。但大多集中于会话图的构建学习。如SR-GNN[3]对用户的偏好学习只集中于当前会话,忽略了其他会话相关物品的转移关系学习。如GCE-GNN[4]虽考虑到其他会话的学习,但只强调全局图对会话图的指导,忽视了会话图对全局图的指导作用,并将两者表征采用固定权重融合,对全局图和局部会话图各自学习到的物品表征之间的强相关信息的提取和融合研究缺乏。
针对以上问题,本文提出了一种融合交互注意力机制和改进参数自适应策略的图神经网络推荐模型,简称InterAtt-GNN。主要创新点如下:
(1) 引入交互注意力机制来同时利用全局图对会话图的指导和会话图对全局图的指导,分别对会话图和全局图学习的物品表征进行强相关信息提取。
(2) 通过改进参数自适应策略对原有的会话图和全局图物品表征学习两者权重并用于信息提取后的表征融合。
(3) 本文在公开数据集Tmall上进行实验。结果表明,InterAtt-GNN算法相比于对比的其他推荐算法在准确率和MRR指标上分别提升了1.82%~3.01%和0.43%~0.50%。
1 相关工作
随着深度学习的快速发展和注意力机制的优越表现,目前已有许多基于循环神经网络和引入注意力机制的会话推荐算法研究。总结来看,在基于会话的推荐系统研究领域中,目前优越的模型大多基于循环神经网络、注意力机制和图神经网络。
1.1 基于循环神经网络的会话推荐算法
基于会话的推荐算法研究本质上是对序列化推荐算法的研究,其大多都假设序列中的交互行为是有顺序依赖的。而RNN在捕捉序列的顺序依赖方面具有强大优势。目前基于RNN的推荐算法研究大多基于长短时记忆(LSTM)[5]和门循环控制单元(GRU)[6]的循环神经网络,用于捕捉会话行为序列的长期依赖关系。HIDASI等人[7]将整个会话作为行为序列,利用RNN的变体GRU对其建模。BOGINA等人[8]将用户停留时间结合到RNN模型,提升在Yoochoose数据集上的准确率。但基于RNN的推荐算法在应用中存在以下不足:(1)由于RNN的强假设前提是序列中任何相邻项都是高度相关的,与现实中交互序列的生成情景不符,很容易生成错误的相关性从而引入噪声; (2)忽略了用户交互行为的复杂协作依赖关系。
1.2 基于注意力机制的会话推荐算法
深度学习在描述序列数据方面的极强表现力使得深度学习的模型在推荐系统中取得显著成功。尤其是将注意力机制引入神经网络中,用于提取序列中相对重要的行为信息。Wang等人[9]提出基于自注意力机制的SASRec模型,结合RNN和马尔科夫链模型的优势,既可以捕捉长期的语义信息,还可以基于尽可能少的行为进行预测。陈海涵等人[10]从基于注意力机制的DNN、CNN、RNN、GNN推荐四个方面分析,分别阐明进展和不足,并指出多特征交互是未来研究的要点。随着注意力机制融合进推荐系统的发展,阿里先后提出融合 Attention机制的深度学习模型 DIN[11]和 DIEN[12],能够根据候选商品的不同调整不同特征的权重,并且将注意力机制作用于深度神经网络。考虑到用户的每个会话的兴趣是相近的,会话间的兴趣差别较大,Feng等提出DSIN[13]模型,考虑和用户的会话关系结合,相对之前模型进一步提升。但是,上述注意力机制都是基于序列自身的物品学习注意力权重,缺少对会话间和会话内物品表征学习的注意力。
1.3 基于图神经网络的会话推荐算法
随着图神经网络的高速发展,将图神经网络引入推荐算法的研究成为目前推荐系统研究的热点。图神经网络相较于以往的深度学习神经网络学习能够考虑到用户交互行为序列的复杂交互关系,从而捕捉序列中被忽略的复杂的用户-商品之间的交互转换。考虑到商品间的复杂的转移关系,SR-GNN[3]模型提出用GNN的方法来提取用户的短期兴趣,性能相对以往的方法有较大提升。但只关注会话内的商品交互。随之,GCE-GNN[4]模型被提出,构建局部会话图获取用户基于会话的短期兴趣,用所有序列构建的全局交互图获得用户基于会话间的长期兴趣,相较于单会话学习有较大提升,但对于全局图和会话图学习到的物品嵌入只是通过简单的sum-pooling结合,忽视了两者之间的强相关关系。南宁等人[14]用物品注意图和协同关联图学习物品表征并使用双层注意力获取节点表征,获得性能提升,但缺少图表征之间的学习。也有将图神经网络与传统方法结合,如矩阵分解[15],尽管取得一定效果,但对于会话间的学习不足。
2 模型结构
针对上述问题,本文引入交互注意力机制学习两者之间的强相关关系,提出InterAtt-GNN模型,其整体流程如图1所示。
该模型由以下几个部分组成:商品表征学习层、交互注意力层、融合层、序列表征层和输出层。

图1 InterAtt-GNN算法整体图
2.1 商品表征层
商品表征层包括会话商品表征学习模块和全局商品表征学习模块,会话商品表征学习模块基于会话图学习商品在当前会话图中的表征,全局商品表征学习模块首先根据当前商品在全部会话中交互商品构建商品的全局图,从中学习商品基于全局图的表征。
会话图如图1所示,对于所有的商品V={v1,v2,…,vn},每个匿名会话序列定义为S={v1,v2,…,vm},m为会话序列长度,通过拟合会话序列中邻近的商品对构成会话图,令SessionGraph=(Vs,Εs),其中,Vs⊆V,是会话中的商品序列,Es={(vi,vj)|i,j∈{1,…,m}}是商品序列中商品之间边的集合。构建的会话图是有序无权有向图,通过计算当前会话序列中每个商品对之间的内积和非线性转换得到注意力权值αij,加权得到商品会话图表征Li,具体步骤如式(1)所示。而全局图则定义一个ε邻域集合Nvi,包含在所有会话序列中与节点i距离小于ε的节点。将节点之间的共现次数作为两两节点之间的权重wij,并考虑到计算复杂度选取权重top-K的邻居节点重构加权无向图。为学习不同邻居的具体作用,通过函数π(vi,vj)学习不同邻居节点之间的权重,通过聚合函数agg聚合上一个hop的节点表示和邻居节点表示得到当前hop的邻居节点表示,通过两次聚合得到最终邻居节点表示。邻居节点与节点表示拼接后通过激活函数prelu最终得到全局会话表征Gi。
在全局图和有向图的构造及各自的商品表征学习上,本文沿用GCE-GNN中的构造方法,分别用SessionGraphLearning和GlobalGraphLearning表示,如式(1)所示。

(1)
其中,i∈S(为表述方便,用i代替上文的vi),hi∈d,d为表征维度。L={L1,L2,…,Lm},L∈m×d,Li∈d表示基于会话图学习到的商品表征集合,同理G={G1,G2,…,Gn},G∈n×d,n表示数据集中商品的总数。
基于会话图的学习SessionGraphLearning的展开如式(2)所示。

(2)
其中,f表示激活函数LeakyRelu,⊙表征点乘操作,aij表示边的关系权重由模型训练得到,hvi表示商品i的embedding表征。基于全局图的学习GlobalGraphLearning的展开如式(3)所示。

(3)
q、Wg1和Wg2是训练得到的超参数。hs是当前会话序列中商品的平均表示,代表当前会话表征。hNvi为节点vi的邻居节点聚合表征,k取2。
2.2 交互注意力层
针对全局图和会话图的商品表征学习融合,在考虑到实际应用场景中全局图和会话图均存在相互指导的潜在影响,本文创新性提出交互注意力机制,通过全局图和会话之间的交叉指导提取两者关于当前会话的强相关信息。
对于全局商品表征学习层学习到的表征Gi和会话商品表征层学习到的表征Li,交叉注意力同时进行全局对会话的指导学习和会话对全局的指导学习,具体流程如图2的交互注意力层所示。
全局图对会话图的指导学习方面,为强化两者的强相关特征,弱化弱相关特征,本文采用点乘的方式进一步提取两者相关的强相关信息。如式(4)所示。

(4)
考虑到模型的运行速度和减少模型计算的参数量,本文将商品i的会话表征和全局表征分别切分成li,1,li,2和gi,1,gi,2,li,1,li,2,gi,1,gi,2∈d/2。 类似于自注意力机制,商品的最终局部特征表征G2Latti可以通过全局图和会话图的强相关信息提取后的两段会话表征d)和原始商品会话表征Li的线性组合得到。具体操作如式(5)所示。
其中,⊙表征点乘操作。同样,会话图指导全局图的学习过程如式(6)所示,得到商品的最终全局特征表征L2Gatti。

(6)
2.3 融合层
通过2.2节可以得到: ①全局图指导会话图中商品i的会话图表征提取G2Latti; ②会话图指导全局图中商品i的全局表征提取L2Gatti;对于这两种表征结合,常用参数自适应的融合机制[16-17]来动态地为两者分配权重,主要思想是在同一条数据下会话图表征越重要,全局图表征相应地越不重要,如式(7)所示。

图2 交互注意力层和融合层展开图

(7)

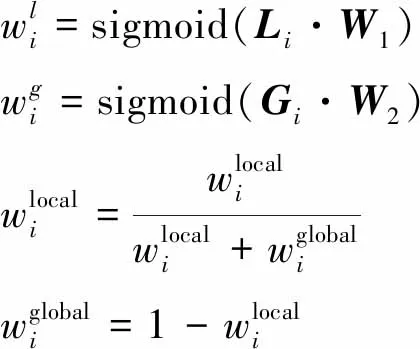
(8)

2.4 序列表征层
考虑到节点位置信息的重要性,本文在每个节点的表征序列中融入位置表征pm-i+1,并与表征序列拼接,通过注意力网络层和改进参数自适应的商品表征加权融合得到最终的会话序列表征S,如式(11)所示。

(11)

2.5 输出层
将2.4节得到的会话表征S和初始嵌入H通过Softmax层预测下一次交互的商品的概率值,如式(12)所示。

(12)
其中,H是初始嵌入矩阵
3 实验与分析
3.1 数据集
在数据集上,本文选用IJCAI-15比赛的Tmall数据集,包含了2015年某段时间内的天猫在线购物平台上匿名用户的购物日志。实验数据集描述如表1所示。

表1 实验数据集
3.2 实验设置
本文的实验采用PyTorch框架开发,具体实验环境设置如表2所示。

表2 实验环境
3.3 参数设置
InterAtt-GNN模型的详细参数设置如表3所示。

表3 实验参数
3.4 实验结果分析
3.4.1 评估指标
本文采用P@N和MRR@N指标用于评估比较模型。
P@N(准确率)常被用作预测准确性的衡量标准,代表预测前N项中被正确推荐的商品的比例,具体计算方法如式(14)所示。本文选择广泛使用的P@10和P@20衡量预测准确性。选取预测中前N个预测值作为候选集,其中rel(i)={0,1}为模型预测商品候选集中是否存在目标值,存在则取值1,n为样本总数。
MRR@N(平均倒数排名)则是考虑推荐商品的排名顺序的评价指标,用来衡量推荐算法得到的top-K商品集的优劣。该评价指标于第一个正确推荐商品的顺序有关,第一个正确推荐商品越靠前则评分越高,计算方法如式(15)所示。ki为用户感兴趣的商品在推荐列表中的排名。
3.4.2 基准算法
为验证本文模型的有效性,分别选用具有代表性的9个基线模型作为对比实验。
•POP:推荐训练集中出现频率top-N的物品。
•Item-KNN[18]:基于当前会话的物品和其他会话的商品之间的余弦相似性来推荐物品。
•FPMC[19]:是一种结合矩阵分解和马尔科夫链的序列预测方法。
•GRU4Rec[7]:使用基于循环神经网络的方法为基于会话的推荐建模用户序列。
•NARM[20]:使用具有注意力机制的循环神经网络方法来捕捉用户的主要意图和序列行为信息。
•SR-GNN[3]:通过构建会话图并输入门控机制增强的GNN层来获得物品表征,从而计算物品关于会话级别的表征。
•CSRM[21]:利用记忆网络来研究最新m个会话,来获取当前会话的意图。
•F-GNN[21]:通过构建加权注意力的图神经网络来学习物品的嵌入表征。
•GCE-GNN[4]:通过引入全局图来学习物品的相关表征,将其与基于会话图学习的物品表征进行相加融合得到物品表征。
3.4.3 实验结果
本文将InterAtt-GNN模型与其他基准模型在数据集Tmall上在准确率和MRR两个指标上进行对比,实验结果如表4所示,其中每一列的最佳评分均加粗显示。

表4 实验结果
从表4可以看出,在所有评分指标上,本文提出的模型InterAtt-GNN均具有最佳性能,充分证明了该模型的有效性和优越性。在传统基准模型的实验中,POP算法的各项指标评分最高只有1.67%,都远远低于其他基准模型,因为POP仅仅推荐top-N候选集,并没有进一步从候选集中进行筛选;而Item-KNN模型相较于POP准确率提升了4.98%~7.15%,但仍低于FRMR模型,这归因于Item-KNN模型虽然从候选集中进一步筛选,但只考虑序列物品对之间的余弦相似性而忽略了会话序列中的时间顺序;FRMC则应用一阶马尔科夫链来学习交互物品序列的时间依赖信息,性能相较于Item-KNN模型准确率提升大约6个百分点。总结来看,传统模型的实验演进过程表明在会话序列中用户与物品的交互行为顺序的重要性。
神经网络应用在推荐系统领域的主要应用方法包括GRU4Rec模型,NARM模型和CSRM模型。考虑到用户物品交互顺序的重要性,GRU4Rec模型将循环神经网络引入到推荐系统模型中,利用门控循环单元(GRU)模型来学习物品之间的长期依赖。在与传统模型的比较中,GRU4Rec模型的评分指标虽然低于FRMC模型3~6个百分点,但FRMC模型相较于GRU4Rec模型引入矩阵分解对用户的偏好进行分析; NARM模型提出在RNN的基础上引入注意力机制,对用户的意图进行学习,准确率提升大约10个百分点;CSRM模型的实验效果在神经网络模型中效果最佳,两个指标可以分别达到29.46%和13.96%,比之其他模型,CSRM模型考虑到会话之间的影响,在当前会话的学习中引入其他会话的协作信息。
考虑到以往的传统方法和基于神经网络的方法都只考虑到会话中物品对的交互顺序而忽略物品之间的复杂转换关系,现今热门的推荐算法大多将图神经网络应用到会话推荐系统领域。SR-GNN模型通过构建会话图利用图神经网络对会话中的物品表征进行学习,指标最高达到27.57%和10.39%;F-GNN模型则进一步引入加权图注意力层对物品获取图中加权定向边的信息;GCE-GNN模型添加对物品的全局图表征学习,增强对跨会话中物品之间交互信息的学习。SR-GNN和F-GNN模型在性能上虽略低于CSRM模型,但相较于其他模型都有极大的提升,显示出了图神经网络在推荐领域的优越性。GCE-GNN模型同时考虑会话内和会话间的物品的表征学习,准确率和MRR指标均到基线模型中的最优效果32.49%和15.21%,在模型效果上明显优于其他所有基准模型。受到CSRM模型和GCE-GNN模型关于其他会话商品之间的协作信息的考虑和NARM模型对注意力机制的引入,本文提出的模型同时考虑两种注意力机制:全局对会话的注意力学习和会话对全局的注意力学习。如此,既引入注意力机制,又考虑到会话级别的商品依赖信息的学习,模型的效果达到目前最优值,相较于GCE-GNN在准确率和MRR指标上最高可提升3%和0.5%。
3.4.4 消融实验
在这一节,本文通过对会话图和全局图学习到的物品表征进行分析并设计消融实验来验证交互注意力和参数自适应的有效性。
其中,表5分析会话图和全局图学习到表征及已有热门的结合方式的效果;表6则设计消融实验对本文模型进行分析:G2L、L2G、G2L+L2G(Interactive Attention)、G2L+L2G+PS(Interactive Attention + Parameter Self-adaptation),其中G代表全局图,L表征会话图,L2G表征会话图指导全局图学习,G2L表征全局图指导会话图学习,SP表示Sum-pooling,PS表征参数自适应,PSI表示改进的参数自适应。

表5 模型分析结果

表6 消融实验结果
从上表可以看出,只使用全局图对物品的表征学习得到的预测效果远远低于只使用会话图对商品表征学习的效果,这是因为商品在会话图中的表征学习更贴近用户的当前意图。为了更好地将两者结合,尝试Sum-pooling、参数自适应、改进参数自适应方法,可以看出改进参数自适应相对于原有的参数自适应算法确有提升。从整体可以看出其性能不如只有会话图的商品表征学习,这显示只是利用已有的融合方法对两者组合效果反而降低,说明在组合的过程中存在着信息的丢失或信息的冗余,鉴于该问题,本文再引入交互注意力机制对两者之间的强相关信息进行学习。
对模型进行消融实验发现,全局图对会话图的指导学习和会话图对全局图的指导学习具有同样的效力,这显示了以往忽视的会话图对全局图的指导学习的重要性和以往参数自适应的权重学习缺陷。此外,同时考虑两者模型的性能可以进一步提升,这证明了本文提出的交互注意力机制确实在提取强相关信息上具有有效性。而通过引入改进参数自适应对学习到的两个表征加权融合之后,实验评分指标相对提高,这显示了全局图和会话图学习到的物品表征信息存在差异,通过改进的参数自适应策略可以更好地将两者结合。
4 结论与展望
本文提出了一种融合交互注意力机制和参数自适应策略的基于图神经网络的会话推荐算法InterAtt-GNN,该算法通过引入交互注意力机制对全局图和会话图学习到的物品表征进行强相关信息提取,并利用改进参数自适应策略对两者加权融合以得到最终的物品表征用于预测推荐。在Tmall数据集上的实验结果表明了InterAtt-GNN的有效性;此外,本文提出的InterAtt-GNN模型在关于全局图和会话图的物品表征融合学习时只尝试了改进的参数自适应策略,并且关于会话图和局部图的学习未详细展开研究,未来需要进一步扩展研究。
