基于改进K-means算法的指标阈值告警方法研究
2023-01-11唐海荣韩少聪
许 健,王 琪,唐海荣,韩少聪,张 弛,陈 梁,倪 洋
(南京南瑞信息通信科技有限公司,南京 211106)
0 引言
电网企业信息化运维系统在日益复杂的运维活动中扮演着重要角色,提升了信息运维工作水平和工作效率。其组件化的中台设计可以有效降低系统耦合,提高基础服务可复用性。被管IT资源可按以下分类:主机、数据库、中间件、网络、安全、存储、虚拟化、服务、应用、机房环境等。各类资源下具有不同的指标,指标是对资源性能的数据描述或状态描述。运维人员在监测某些指标的异常状态时首先需要配置相应的阈值规则,当采集的指标数据不在阈值范围内则判定为区间越界,需要及时产生告警并通知给运维人员。
面对大量复杂多样的指标,运维人员手动录入阈值规则往往依托经验,一定程度上影响着告警准确性,并且重复劳动增加了运维负担。当业务需求变化时,运维人员需要重新编辑之前的阈值规则,维护成本较高,阈值规则的灵活性较差。针对这些痛点,本文转变静态阈值的配置思路,引入简单高效的K-means聚类分析方法,充分利用指标历史数据分析产生各时段动态阈值的区间上下限,降低人工参与度,提高阈值告警规则配置的灵活性和告警的准确性。传统K-means算法聚类数和中心点的选取缺乏明确标准定义[1],改进随机选取问题来优化算法聚类效果。
1 指标阈值告警
1.1 采集监测层次关系
电网企业信息化运维系统监测的资源指标数据由采集控制组件提供。采集控制组件基于各类采集插件,实现支持多级复杂主、子资源结构关系的安全设备、存储设备、网络设备、数据库、虚拟化及大数据部分类型的组件数据采集。资源监测组件基于微服务架构接口规范为上层应用提供主机、数据库、中间件、网络设备、安全设备、存储设备及云平台等资源的状态监测数据、性能数据及告警数据服务。采集监测的层次关系如图1所示。
图1中的异常告警及通知依赖于运维人员配置的指标阈值,实时采集的指标值存储到消息总线上,两者进行阈值规则匹配。比如CPU使用率大于95%时则产生告警等级为严重的告警,并对告警信息进行通知分发。

图1 采集监测层次关系
1.2 传统阈值告警配置流程
电网企业信息化运维系统在日常运维中需要由人工来录入指标的阈值告警规则,配置过程中需要进行较多的页面交互,主要流程如下:
(1)在系统菜单中进入告警策略管理页面,在主资源类型下新增相应的告警策略,主资源类型包括服务器类、数据库类、中间件类、网络设备、链路、安全设备、云平台等。
(2)点击告警策略中的触发条件蓝色数字下钻到该策略的资源与指标关联列表页面。主资源下包含许多子资源,不同主子资源又包含丰富的指标。
(3)点击需要监测的指标中的触发规则蓝色数字下钻到该指标的触发规则配置页面。配置阈值告警规则,填写阈值上下限、持续时间、告警级别等表单信息,确认保存。
从整个流程来看,面对丰富的监测指标,一是交互多重复工作量大,二是对运维人员的经验有一定要求。且当业务需求变化时,还需回到原表单处重新编辑阈值告警规则,维护成本较高,欠缺灵活性。
1.3 聚类分析指标阈值告警
聚类分析属于无监督学习,常见的分类主要有基于层次的聚类算法、基于划分的聚类算法、基于密度的聚类算法、基于网络的聚类算法和基于模型的聚类算法[2]。
针对上节提到的问题,转变静态阈值的配置思路,从运维现场每五分钟采集一次指标数据来看,有丰富的指标历史数据可供使用,便可聚类分析出各时段指标的动态阈值上下限,降低人工参与度,提高阈值告警规则配置的灵活性和告警的准确性。
2 改进K-means算法
2.1 确定最佳聚类数的方法
2.1.1 手肘法
手肘法通过样本聚类总误差平方和SSE这一指标来表示样本的聚合程度,其值越小表示类间样本越紧凑。SSE的计算公式为
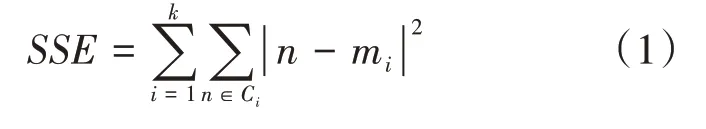
其中,Ci表示第i个类,n表示Ci中的样本点,mi是Ci中所有样本的均值。每个类的聚合程度会随着聚类数k的增大而逐渐提高,样本划分越来越精细,误差平方和SSE也会逐渐变小。在聚类初期,k小于真实聚类数,k的增大会迅速增加每个类的聚合程度,SSE的下降幅度也会很大;而当k到达真实聚类数时,再增大k时样本聚合程度改变不会很大,SSE的下降幅度随着k值的继续增大而趋于平缓,即SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。然而,SSE加和的方式会使得某些分类效果较差的类计算所得的类间误差平方和被聚类效果较好的类间误差平方和中和[3],本文进一步结合统计学中的Gap Statistic方法来确定最佳聚类数。
2.1.2 Gap Statistic法
Gap Statistic的主要思想是计算每一类里各样本两两之间欧式距离的平方和,并将其与构建的参考零均值均匀分布所得的聚类结果相比较,从而确定数据集的最佳聚类数目。当聚类数k为最优值时,Gap Statistic这个统计量达到最大值,也意味着此时的聚类结果与零均值均匀分布产生的数据的聚类结果差别最大。算法流程分为以下三步:
第1步:改变聚类数量k从1到kmax,计算不同k值对应的类内偏离和wk,计算公式为
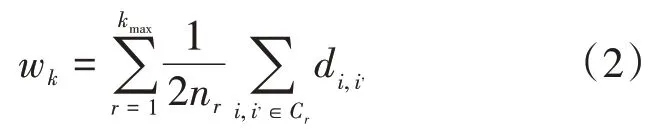
其中Cr表示聚类得到的第r类,nr表示样本个数,表示该类中所有样本两两之间的距离和。
第2步:构建B个参考零均值均匀分布数据,改变聚类数量k从1到kmax,计算不同k值对应的类内偏离和wkb,b=1,2,…,B,k=1, 2, …,kmax。
第3步:对前两步的类内偏离和取对数处理,二者比较后的差值作为Gap(k),计算公式为
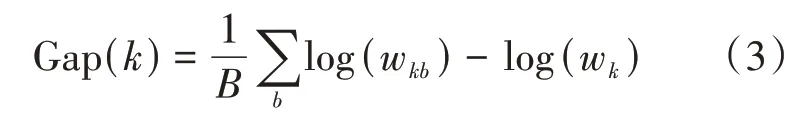
2.2 确定初始聚类中心点的方法
传统K-means算法在开始运行时初始聚类中心的选取是随机的[4],对聚类结果的影响较大。为了避免聚类中心陷入局部最优解,仿生智能优化算法的出现提高了K-means算法的全局搜索能力,比较流行的算法有萤火虫算法、森林优化算法、遗传算法等[5]。本文采用变步长萤火虫算法的最优解作为初始聚类中心点。
2.2.1 萤火虫算法
萤火虫算法是一种基于群体的随机搜索算法[6]。把空间各点看成萤火虫,利用发光弱的萤火虫受发光强的萤火虫吸引的特点进行位置迭代,从而完成寻优过程。寻优过程和萤火虫的相对亮度和相互吸引度有关。相对亮度用式(4)表示,相互吸引度用式(5)表示:
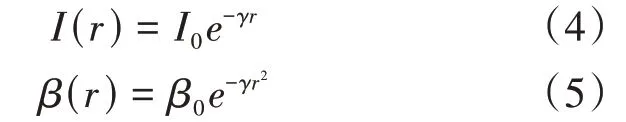
式(4)、式(5)中的γ为光吸收因子,一般情况下γ∈ [0.01,100][7],r为两只萤火虫间的欧式距离,I0表示r为0时的亮度,β0表示r为0时的吸引度,也即最大吸引度。发光越亮代表其位置越好,最亮萤火虫即代表函数的最优解。发光越亮的萤火虫对周围萤火虫的吸引度越高,同时与距离成反比,距离越大吸引度越小,若发光亮度一样,则萤火虫做随机运动进行位置更新,假设Xj比Xi吸引度高,Xi位置更新计算公式为

其中α为步长因子,rand()为[-0.5,0.5]区间范围内的随机扰动[8]。
算法流程如下:
第1步:初始化算法参数:萤火虫数量、光吸收因子、最大吸引度、步长因子和最大迭代次数;
第2步:计算初始位置处的萤火虫目标函数值作为各自的最大荧光亮度;
第3步:计算萤火虫群的相对亮度和相互吸引度,根据相对亮度判断萤火虫移动方向,更新位置;
第4步:根据更新后的位置,重新计算相对亮度;
第5步:当满足最大迭代次数则输出最优个体值,否则返回第3步继续下一次寻优。
2.2.2 变步长萤火虫算法
随着迭代次数的增加,萤火虫群会在最优值附近聚集[9]。此时萤火虫个体与最优值之间的距离已经非常小,在个体向最优值趋近的过程中,很可能会出现萤火虫移动的距离大于个体与最优值间距的情况,而导致个体更新自己位置时跳过了最优值,出现震荡,将会导致最优值发现率降低,影响算法的收敛精度和速度。为了尽量避免由上述原因造成的收敛较慢情况,潘晓英等[10]采用自适应移动步长代替原有固定步长,通过萤火虫种群的聚合程度令步长变化呈减小的趋势,自适应移动步长计算公式为

其中α,为萤火虫每一代的自适应步长因子,D(Ci)t+1为萤火虫种群移动后的类间距离和。本文借鉴了该思想,在算法开始时,将初始步长设定为相对较大值,而后随着迭代次数增加设定一个判定条件:当迭代次数达到最大迭代次数的一半时,用式(8)替代固定步长α,使其逐渐减小趋于0,第t次的步长因子为

其中e为自然常数,则萤火虫算法将在开始时具有较好的全局寻优能力,迅速定位在接近全局最优解的区域,而后期也具有良好的局部搜索能力,能精确得到全局最优解。
2.3 改进K-means算法总结
聚类数和初始聚类中心点的选取对算法的结果有重要的影响。针对手肘法可能出现“肘点”不明确问题,进一步结合Gap Statistic确定出最佳聚类数;针对萤火虫算法随着迭代次数增加可能会在最优值附近出现震荡的问题,改变步长因子来提高萤火虫算法的全局寻优和局部搜索能力,将最优值作为K-means聚类算法的初始中心点。改进后的K-means算法流程如图2所示。
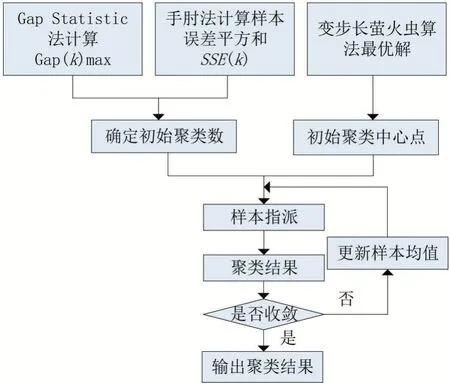
图2 改进K-means算法流程图
3 实验分析
3.1 实验环境搭建
为验证改进K-means算法的指标阈值告警方法,在电网企业某省公司信息化运维系统测试环境中进行数据测试。采集由五台物理机组成,操作系统为centos7.5,配置为32核CPU,64 G内存,500 G硬盘。其中两台部署weblogic集群及jar包库,三台部署采集后台服务。信息化运维系统采集控制组件和资源监测组件进行容器化部署。
3.2 实验流程
第1步:对样本个数为n的指标数据进行缺失值处理,缺失值采用该指标当天的平均值填充。
第2步:利用二分查找,计算[1,∛n]范围内不同k值下误差平方和以及类内偏离和。
第3步:绘制出误差平方和随k值增加的变化趋势,记录误差平方和减少趋势不再明显时的k1值。
第4步:计算样本在均匀分布推断下的平均类内偏离和。
第5步:计算样本类内偏离和与平均类内偏离和的log差作为Gap Statistic。
第6步:绘制出Gap Statistic随k值增加的变化趋势Gap(k)函数,记录Gap(k)max时的k2值。
第7步:比较第2步和第5步中的k值,如果两者相等则将此k值作为样本聚类个数,如果不等则k1不断递增1,取Gap(k1)最大时的k1作为样本聚类个数。
第8步:设定变步长萤火虫算法参数:综合考虑精度和计算开销,设定萤火虫数量为,光吸收因子为0.5,最大吸引度为1,最大迭代次数为200,初始步长因子设定为0.95,当迭代次数达到100时,按式(9)减少步长因子,迭代直到收敛到最优解作为初始聚类中心点。
第9步:由第7步得到的最佳聚类数和第8步得到的初始聚类中心点进行K-means聚类分析,绘制结果。
3.3 结果分析
实验指标数据选取CPU使用率,采样周期为5分钟,按天计,一天可采集24*60/5=288个CPU使用率数值,连续四周的工作日共计288*5*4=5760个样本。检查样本数据中是否存在缺失项,若存在则采用该天的CPU使用率平均值填充缺失值。在anaconda3环境中启动Jupyter Notebook后运行了python代码,绘制出实验流程第3步中的误差平方和随k值增加的变化趋势,如图3所示,第6步中的Gap Statistic随k值增加的变化趋势如图4所示。

图3 误差平方和随k值增加的变化趋势
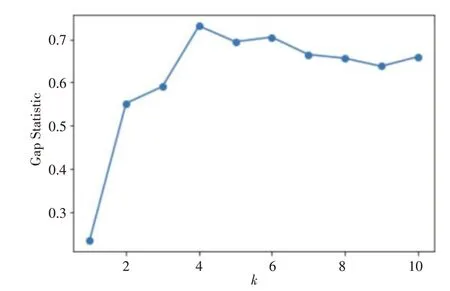
图4 Gap Statistic随k值增加的变化趋势
由图3、图4可知,“肘点”的k值为4,Gap Statistic取最大值时的k值为4,故本次实验的最佳聚类数为4,由实验流程第8步求得的初始聚类中心点进行K-means聚类分析,结果如图5所示,横轴表示时间,进行归一化处理后,范围为0~23,单位为h,指代一天24小时;纵轴表示CPU使用率,范围为0~100,单位为%。

图5 CPU使用率聚类模拟实验
从聚类结果来看,整个图形近似呈现正态分布的特征,即业务活跃时段如早晨8点到下午5点,有着较高的网站访问量、程序计算以及数据库读写等操作,CPU使用率活动在20%~90%之间;而非业务活跃时段如非工作时段和夜间,网站访问量降低后,机器的压力也随之减少,CPU使用率基本在20%以下。从时间段划分来看,上午10点到下午4点之间,CPU使用率有较大概率大于60%,为了留有一定的富余量应对业务高峰,此时应将告警的阈值适当降低,例如大于80%则产生告警级别为警告的告警。综上所述,通过改进后的K-means算法能够聚类分析出各时段的动态阈值,由后台微服务动态调整并与消息总线上采集的指标进行阈值规则匹配。电网企业某省公司现场运维运用新算法后,产生了更加精确的告警,降低了运维人员维护的工作量。
4 结语
电网企业信息化运维系统由人工配置指标阈值告警欠缺灵活性且重复工作量大,针对这一痛点,采用简单高效的K-means聚类算法对指标历史数据按时间进行划分并由后台微服务调整各时段的动态阈值。聚类数的设定和初始聚类中心点的选取对聚类结果有很大影响。针对手肘法可能出现“肘点”不明确问题,进一步结合GapStatistic确定出最佳聚类数;针对萤火虫算法随着迭代次数增加可能会在最优值附近震荡问题,改变步长因子来提高萤火虫算法的全局寻优和局部搜索能力,将最优值作为K-means聚类算法的初始中心点。通过电网企业某省公司信息化运维系统测试环境采集的CPU使用率历史数据进行聚类分析实验,结合业务特性分析了不同时段CPU使用率的阈值情况,实验结果表明改进的K-means算法能有效分析出指标不同时段的阈值情况,从而可由后台微服务调整动态阈值,减轻运维人员在系统中配置大量的指标阈值告警规则,降低了系统的运维成本,进一步提升了告警的准确性。
