基于复合尺度与多粒度联合特征的行人重识别
2022-12-30程俣博雷景生
程俣博,雷景生
(上海电力大学 计算机科学与技术学院,上海 201300)
0 引 言
行人重识别属于行人检索方向的子问题,主要研究在由不同摄像头的监控区域下、不同时段拍摄的行人图像库中,检索到与目标人物为同一类的行人图像[1]。近些年来,深度学习方法逐渐取代传统的方法。
在特征表示方面,大部分算法通过利用不同的深度学习网络提取特征,然后进行度量学习计算相似度,目前主流算法主要有利用特征金字塔[2](DPFL)、多尺度模型[3](MuDeep)、3D空间语义模型[4](SAN)等模型提取特征,当遇到遮挡或者光照的干扰时,全局特征的判别能力减弱,因此渐渐开始局部特征的研究。常见的局部特征提取思想包括人体姿态导向模型[5](PDC)、属性学习模型[6](APR)、结构化表征学习[7](PSRL)、特征切块模型[8](PCB)和多分支模型[9](MGN)等,提取不同粒度下的具有表征能力的深度特征。同时,随着注意力机制的提出与发展,很多专家学者将注意力模型[10-12]用在了行人重识别实验上,并取得了良好的识别效果。
考虑到只采用端到端的方式会割裂尺度与粒度间的关系,造成信息的丢失。本文采用ResNet50[13]作为基础骨干网络,提出一种不同尺度与不同粒度信息相结合的算法策略,设计出多分支网络,对基础网络的最后三层卷积输出做不同尺度的提取,兼顾不同层的信息,且骨干网络的最后输出切分为不同粒度,分别提取具有表征能力的特征,然后利用全局池化、卷积归一等操作,对不同粒度信息进行更加深度的特征提取,增强网络对多粒度表征信息的识别能力。
1 行人重识别方法研究
1.1 行人重识别网络架构
本文所提出的行人重识别架构主要由3个部分组成,分别是基础骨干网络(backbone)、复合尺度模块(composite scale module)和多粒度模块(multi granularity module)。
如图1所示。Backbone为ResNet50网络,提取到行人特征后,复合尺度模块和多粒度模块共同进行深度特征提取融合。复合尺度模块由3个分支组成,分别为P0、P1、P2分支,分别从网络不同深度提取行人特征。多粒度模块由P3、P4分支组成,分别提取不同粒度下的行人显著特征,作为全局特征的补充。最后将复合尺度模块与多粒度模块的特征融合,形成最终用于身份识别预测的特征。
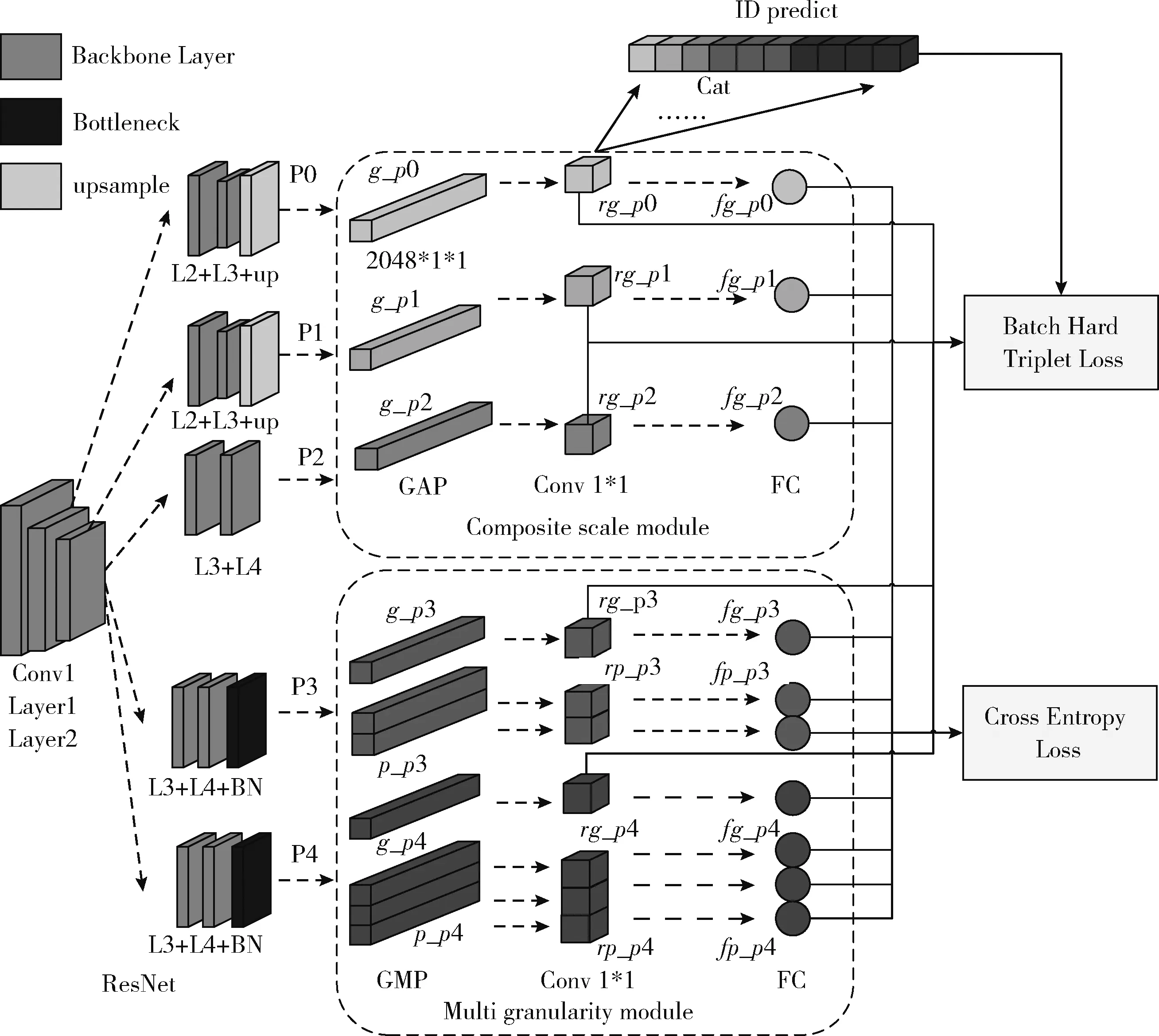
图1 行人重识别总体架构
为了深度提取更多行人特征,本文的基础网络采用ResNet50网络的前5层,即Conv1至Layer4,复合尺度模块的分支P0,联合Layer1、Layer2和上采样层输出特征,提取低层网络的特征,作为高层特征的补充,然后通过GAP(global average pooling)将特征降为2048×1×1大小,然后经过1×1卷积、批量归一化、全连接等操作,得到最终的特征表示fg_p0。分支P1与分支P2与P0类似,不同的是,分支P1特征来自于Layer2、Layer3和上采样层,分支P2特征来自于Layer3和Layer4,实现了不同尺度的特征提取。
为了通过空间注意力机制捕捉到网络多通道之间的关系,避免细微特征的遗漏,多粒度模块的分支P3由Layer3、Layer4和Bottleneck层组成,通过GAP和GMP(global max pooling)将提取后的特征分为大小为2048×1×1的g_p3和大小为2048×2×1的p_p3,然后经过1×1卷积、批量归一化、全连接等操作,得到最终的特征表示fg_p3和fg_p0。分支P4的特征信息与分支P3相同,区别在于GAP和GMP后分为2048×1×1大小的g_p4和2048×3×1的p_p4。在conv1×1卷积后,将rg_p0至rg_p4所有特征连接起来,用于用户ID预测,同时利用批次难样本三元组损失[14](batch hard triplet loss)和交叉熵损失函数(cross entropy loss)对全局特征和细粒度特征进行联合训练,使得各个分支联合学习,提高网络泛化能力。
1.2 复合尺度模块
复合尺度模型[15]是指对输入图像的不同深度层次的采样,通常多尺度下的粒度包含的特征信息也会不一样,一般而言,在细粒度特征图谱中能看到更多的显著细节,在粗粒度采样中能看到特征的趋势性。特征金字塔通过利用一组不同分辨率图像提取特征,每个层级都能提取到不同尺度特征表示,且特征表示的语义信息较多。
复合尺度模块从ResNet50网络的不同深度进行多次采样,其中包括Layer2层、Layer3层以及Layer4层,然后将不同尺度的特征分别进行粗粒度提取和细粒度划分或其它等操作,最后将通过不同尺度的特征信息融合,实现网络对信息的最大化利用。由表1可以看出,不同分支的输入大小不同,由于卷积核和感受野的大小不同,会形成尺度不同的特征图,在复合尺度模块通过上采样层将维度统一为2018×H×W,后再进行其它操作。

表1 网络不同分支参数
1.3 多粒度模块
在提取行人特征时,可以分为粗粒度全局特征和细粒度局部特征[9],粗粒度模块可以捕获行人的全局特征,通过身上最显著的特征信息,可以区分不同行人的身份。但是在复杂的场景中,仅利用粗粒度信息是很难达到行人重识别的目的,在粗粒度层面,很多细粒度的特征被忽略,因此,为了更深度全面地挖掘行人的特征,一些研究者通过将人体语义进行分割对齐,计算语义之间的距离,从而判断语义的类间相似性。分块策略又名软分割策略,是指通过全局池化的方法将特征图横向分为几个模块,PCB模型通过将人体特征横向切割成6部分,HPM[16](horizontal pyramid matching)模型将特征图横向分为8个部分,本文利用软分割策略,由表1可知,将行人特征图片分为一级粗粒度、二级粒度和三级粒度,粗粒度特征与细粒度特征相结合,更全面地挖掘信息并保留表征力强的特征。多粒度模块如图2所示。

图2 多粒度模块
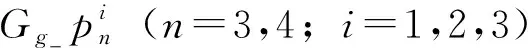
1.4 损失函数
目前交叉熵损失函数和三元组损失函数广泛的应用于分类问题和度量学习中,在深度reID领域中,交叉熵损失函数和三元组损失函数常应用于基于特征学习和度量学习的模型方法中。在全局特征提取过程中,使用交叉熵损失函数训练网络,而在基于细粒度的部分特征网络中,为了避免因为背景干扰和遮挡导致等原因的粒度不对齐问题,使用交叉熵损失函数,从而更好地拟合网络模型并且避免无意义的训练过程。交叉熵损失函数如式(1)所示
(1)
式中:C为类别数目,Wk表示行人重识别网络W的第k行参数,fi是第i个样本的特征表示,yi是第i个样本的所属类别,b为矩阵的偏移项。
三元组损失函数常应用于度量学习,在深度行人重识别任务中,三元组损失函数能解决“类间相似、类内差异”的问题,但是存在着收敛速度慢,容易过拟合的问题,因此针对这种情况,使用批次难样本三元组损失函数TriHard既能够保留三元组损失函数的特性,也能够从多个维度约束网络,提高效率,达到良好的训练效果。
批次难样本三元组损失函数的数学表达式为

(2)
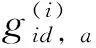
最终的损失函数是由以上两者中损失函数进行组合,表达式为
LTotal=λ1LSoftmax+λ2LTriHard
(3)
式中:λ1和λ2分别为交叉熵损失函数和批次难样本损失函数系数。
2 实验结果与分析
2.1 实验环境
本文实验所采用的硬件平台和软件环境如下,操作系统为Ubuntu 18.04,CPU为Intel®CoreTMi5-7500 Processor,GPU为NVIDIA TITAN XP-16 GB,深度学习框架为Pytorch 1.2,Python版本为3.6.8。用于训练和测试的输入图像大小为384×128,基本数据增强方法包括随机擦除、Dropout等,优化器是Adam,在训练过程中,P=8,K=16,BatchSize为128,迭代次数为1000,在训练期间采用Warmup策略,并且采取端到端的训练方式。模型的主要评估指标包括Rank@k(k=1,3,5,10) 和mAP(mean average precision)。
2.2 实验数据集
本文实验分别采取了在目前行人重识别领域的3个主流公开数据库上进行模型实验的有效性验证,分别是Market-1501数据集、DukeMTMC-reID数据集和CUHK03-detected数据集。
Market-1501数据集[17]由6个摄像头拍摄,共含1501位行人、32 668个行人矩阵框,其中训练集有751人,12 936张行人图像;测试集有750人,9732张行人图像,以及3368张查询图像。
DukeMTMC-reID数据集[18]由8个摄像头拍摄,共含1812位行人,36 411张行人矩阵图片,其中训练集有702人,116 522张图像;测试集有702人,117 661张图像。
CUHK03-detected数据集[19]是在中国香港大学校园采集的大型数据集,由10个摄像头共同拍摄,覆盖多个时段。其中,训练集767个行人,7365张行人图片;测试集700个行人,5223张图片;1400张查询图片,剩下的11 188张行人图片作为Gallery图库。
2.3 评价指标
行人重识别研究普遍利用平均精确均值(mAP)和首中准确率(Rank@1)两种评价指标反应网络的精准度。
平均精确均值可以反映模型在收到Query请求后,返回的正确检索结果在返回列表中的排名,可以全面衡量行人重识别模型的性能,如式(4)所示
(4)
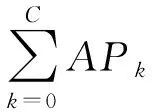
Rank@n表示模型返回列表中n张图片中属于目标类别的概率,首中准确率(Rank@1)表示查询结果中排名第一的图像为目标类别的概率。
2.4 实验结果与结果仿真
2.4.1 实验结果
本次实验主要在3大主流数据集CUHK03-detected、DukeMTMC-reID 和Market-1501上进行实验测试,图3为模型在3大数据集上的结果。其中关于损失函数,出于“首先确定行人的身份问题,再进行细节的确认和特征辨别”的思想考虑,因此实验环境中损失函数的参数设置为λ1=1和λ2=2。
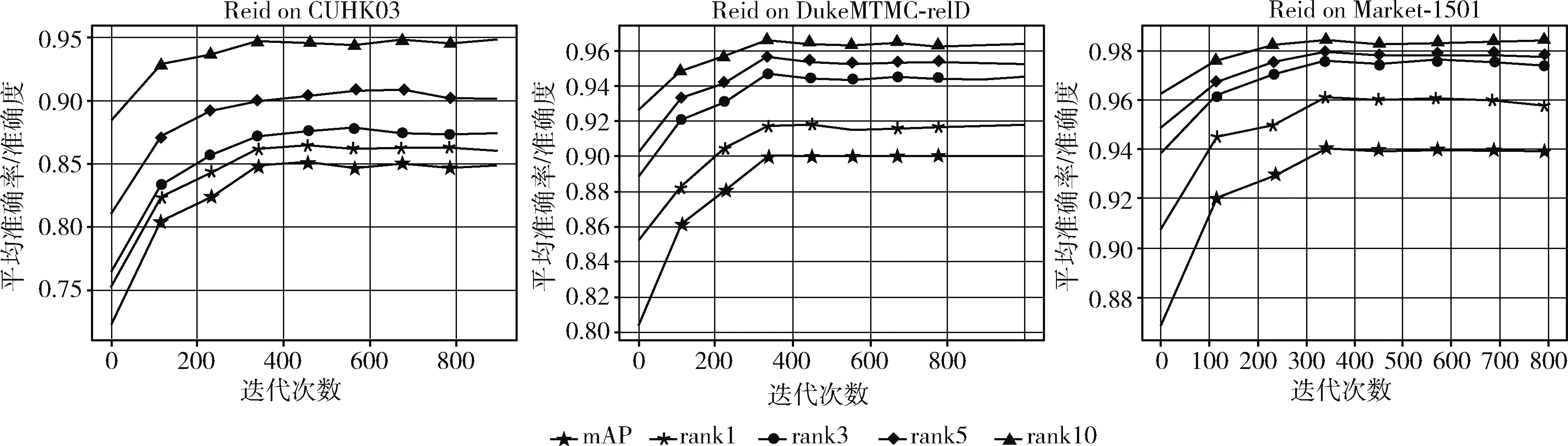
图3 算法在数据集上的性能表现
实验结果由图3可以发现,在CUHK03-detected数据集上,Rank@1=85.24%,Rank@3=87.57%,Rank@5=90.36%,Rank@10=94.57%,平均准确率mAP=86.48%。在DukeMTMC-reID数据集上,Rank@1=91.89%,Rank@3=94.48%,Rank@5=95.20%,Rank@10=96.36%,平均准确率mAP=90.11%。在Market-1501数据集上,Rank@1=96.21%,Rank@3=97.60%,Rank@5=97.86%,Rank@10=98.53%,平均准确率mAP=94.12%。
2.4.2 消融实验
本算法模型主要分为3个部分,即多尺度模型、多粒度模型和联合部分,为了探讨不同部分对于算法模型识别率的影响,实验分别对多尺度模型和多粒度模型存在的必要性做了验证,结果见表2~表4。其中,RK表示re-ranking技巧,是指基于k阶导数编码的方式,计算出行人图像特征的杰卡德距离,然后将图片的马氏距离与杰卡德距离加权求和得到最终的结果,对需要识别测试的图库中的图片进行重新排序,从而提升性能指标。
由表2~表4实验结果可以发现,与基础网络ResNet50相比,复合尺度模块、多粒度模块以及联合特征对行人重识别的效果有所提升。
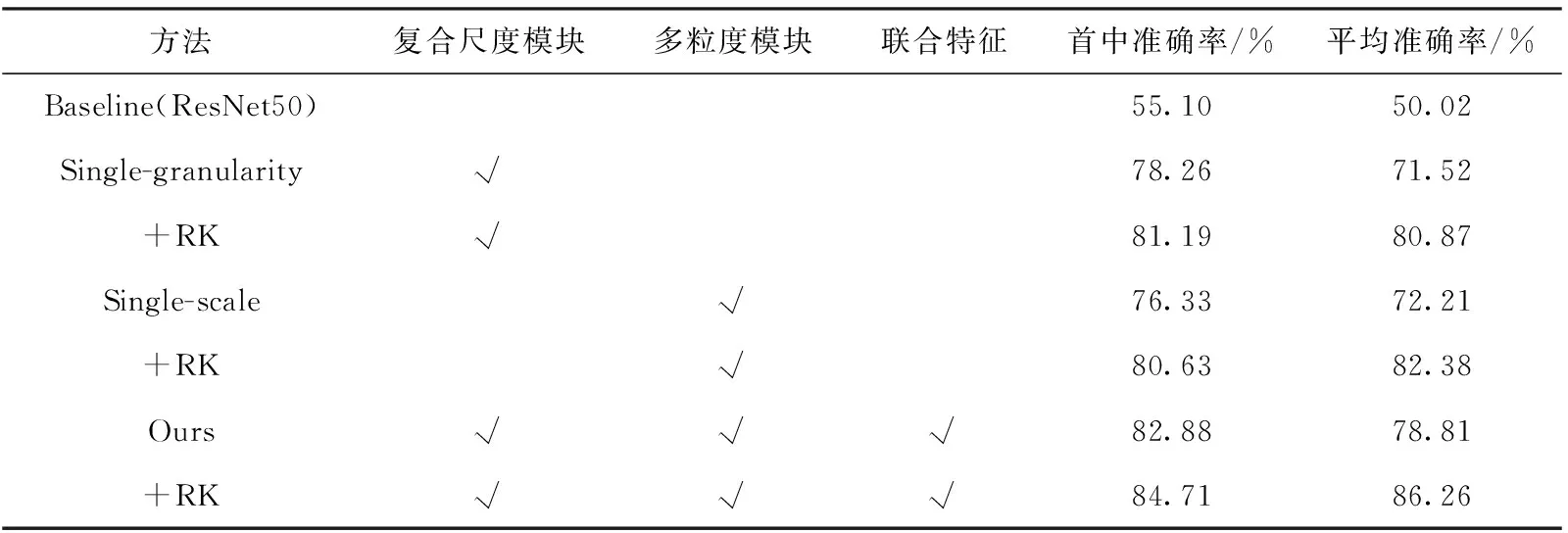
表2 CUHK03-detected数据集的消融实验结果
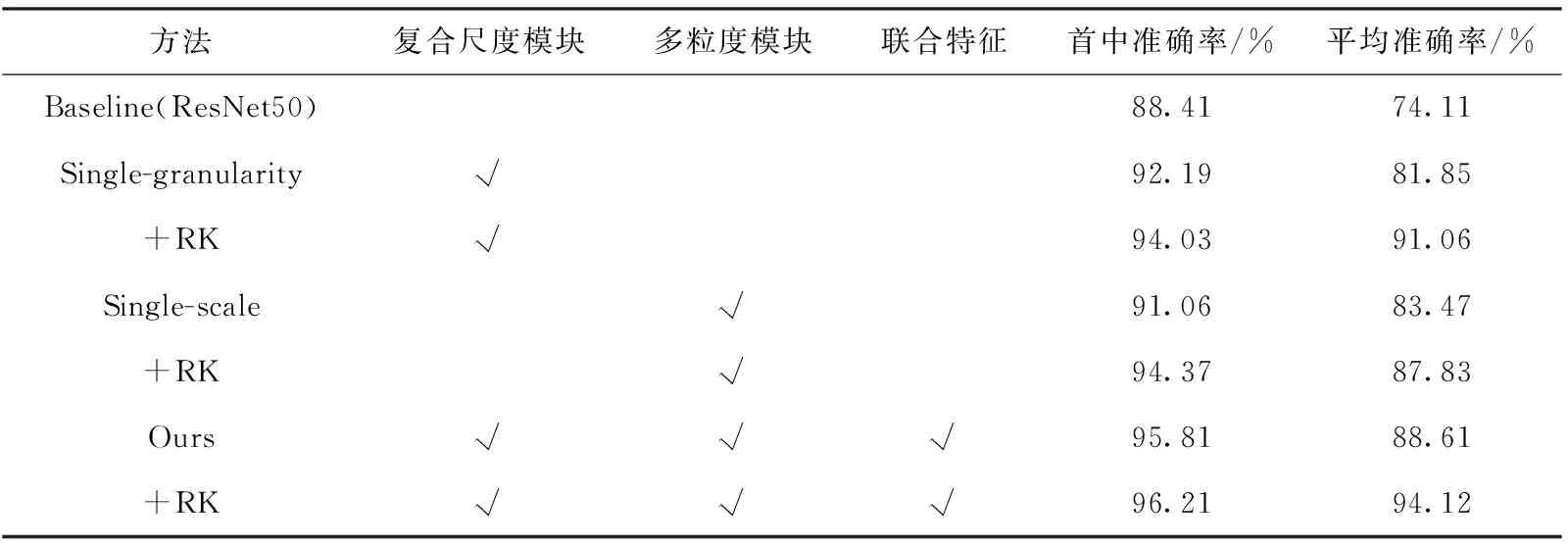
表4 Market-1501数据集的消融实验结果
在CUHK03-detected数据集上,通过表2可以发现,在rank@1和mAP指标上,与baseline相比,复合尺度模块分别提升了20.16%和21.50%,多粒度模块分别提升了21.23%和22.19%。本文模型与baseline模型相比,rank@1和mAP分别提升了27.78%和28.79%,同时利用reran-king技巧,使效果再度提高1.83%和7.45%,最终达到了84.71%和86.26%,因此可以看出reranking技巧提升效果明显。
在DukeMTMC-reID数据集上,通过表3可以发现,在rank@1和mAP指标上,与baseline相比,复合尺度模块分别提升了5.52%和3.24%,多粒度模块分别提升了5.19%和9.64%。本文模型与baseline模型相比,rank@1和mAP分别提升了6.23%和10.24%,同时利用reranking技巧,使效果再度提高2.35%和11.15%,最终达到了91.89%和91.19%。
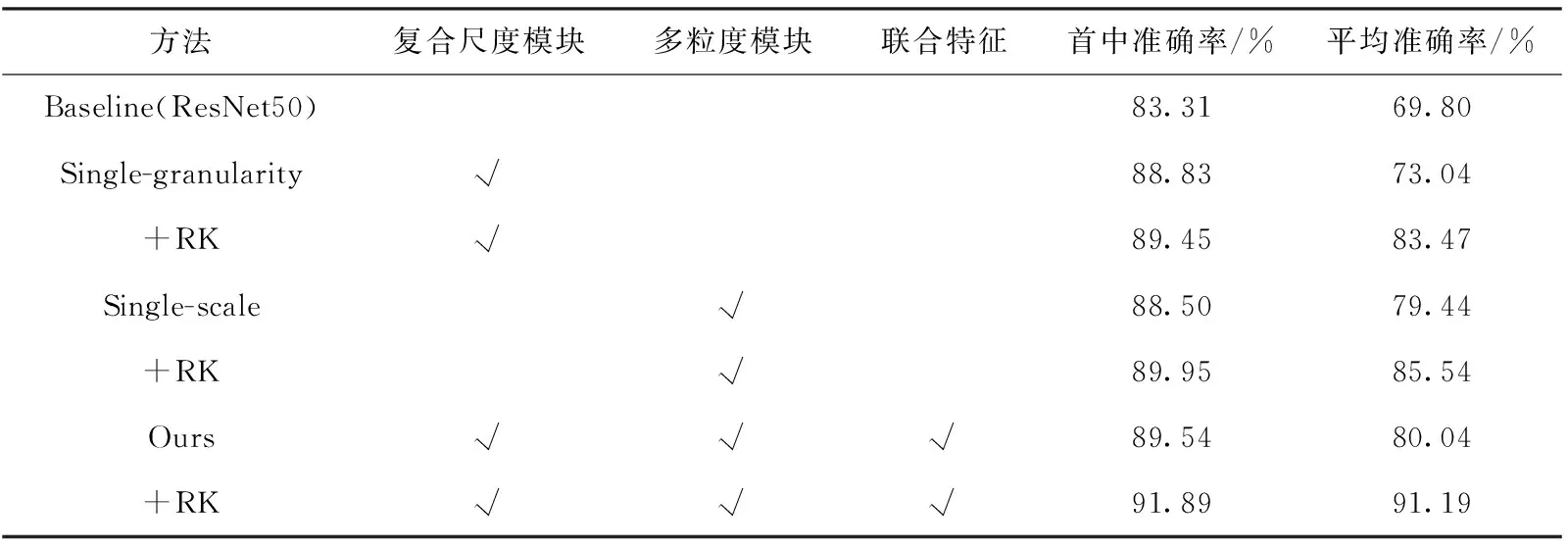
表3 DukeMTMC-reID数据集的消融实验结果
通过表4可以发现,与baseline相比,多粒度模块和单尺度模块对实验效果有所提升,在rank@1和mAP指标上,复合尺度模块分别提升了3.75%和7.74%,多粒度模块分别提升了2.65%和9.36%。本文模型与baseline模型相比,rank@1和mAP分别提升了7.40%和14.50%,同时利用reranking技巧,使效果达到了96.21%和94.12%。
2.4.3 实验结构讨论
本模型所选用的基础骨干模型为ResNet,初始的参数权重是在imageNet上预训练过的,为了验证本Backbone的性能,实验选用ResNet家族性能较为优越出众的变体网络SE-ResNeXt50[20]作为基础网络进行对比实验,同时P3和P4分支的BottleNeck替换成SE-ResNeXt BottleNeck模块,由于SE-ResNeXt50网络参数较多,拟合难度较大,因此在实验部分迭代次数为1500。
由消融实验部分可知,多粒度模型存在具有其必要性,但是分块策略的具体数量需要确定,因此为了探究实验中采用的软分割数目的有效性,在多粒度模块中进行粒度的测试实验,鉴于ReID深度学习领域,经典方法PCB和HPM不同分割策略的出色性能表现,本文也对6等分和8等分策略进行了验证,P3和P4分支的分别采用了“1-2-3”等分粒度、“1-2-4”等分粒度、“1-3-4”等分粒度、“1-6”等分粒度和“1-8”等分粒度,其中“1-6”和“1-8”粒度的划分实验,取消了P4分支,只保留P0至P3分支,同时,“1-2-3”等分策略即为ResNet50实验结果,因此不再赘述。
由表5可以发现,在Market-1501数据集上,首先对于不同的Backbone网络,本模型采用的ResNet和SE-ResNeXt50对比,可以看到ResNet50网络具有良好的性能表现,而在分类任务中性能优越的SE-ResNeXt50出现了精度下降的现象,rank@1和mAP相较于ResNet50分别下降3.85%和0.84%,具体分析可能是如下原因:①网络较为深入,难以进行训练;②数据集信息较少,在SE block中压缩操作中丢失部分特征信息;③网络模型复杂,参数量较多,对不同的特征学习分类,出现了过拟合现象。同时由于SE-ResNeXt50网络的大型架构和参数计算,使得网络训练时间较长,迭代次数也比ResNet50多较多。同时,在水平划分粒度实验中可以发现,对于多分支多粒度网络,当深层的输出特征使用较多的分块策略时,效果往往也有所提升,而对于分支较少的细粒度模型而言,往往是较大的分块策略使得平均准确率较高,而较多的分块会破坏细粒度特征原有的语义信息。综上,考虑速度与精度问题,本文最终选择Backbone为ResNet50、分块策略为“1-2-3”的组织架构。

表5 Market-1501数据集上不同结构的实验结果
2.4.4 实验结果可视化
为了验证本模型中的复合尺度模块和整体算法的有效性,对网络最后提取的特征图进行可视化处理,可视化实验选取了3大数据集中的图片,通过通道像素值绝对值相加[21]的办法,最终得到原始图像、基线方法和本文的可视化结果,由于本文网络为多分支结构,因此可视化采用信息量较大的P3分支的粗粒度特征,高层映射为ResNet50网络的最终输出特征。实验结果如图4所示。

图4 可视化的特征激活图像
由图4可以发现,由于图像存在的清晰与模糊问题,基线方法在模糊的图片上,网络的注意力集中在某一区域,并非全局特征,因此会遗漏很多重要的表征信息,而在较为清晰的图像上,基线方法表现的比非清晰图像更具有全局性,但是本文方法无论是在模糊图像还是清晰图像,都关注到了全局特征,并且不放过细节和不受环境干扰,将行人图像提取的较为完整。
本实验将最终测试评估结果可视化,如图5所示,左侧为查询行人图像,右侧为Gallery图库中检测到的匹配图像,白色框表示查询出错,ID不为同一人。由图5可以发现,匹配的行人图像准确率较高,模型的识别效果较好,在错误的识别分类中,Gallery库中存在与Query图像较为相似的穿着打扮,如相同颜色的衣服和款式,这同时也说明,细粒度模块的存在使网络不仅注意到了全局特征,也注意到了局部信息的表征效果。因此本模型具有较高的准确率和有效性。

图5 行人重识别效果可视图
2.4.5 与主流算法比较
为了验证本算法的有效性,将本文算法与当前几种主流算法识别性能进行比较,如表6所示,这些对照方法的网络参数均为最优值,对照组包括OSNet、PCB等经典的深度学习算法,同时包括最新的Top-DB-Net、OGNet和CBN模型等。

表6 本文算法与主流算法评价指标比较/%
由表6可发现,在CUHK03-detected数据集上,与最新的算法OGNet相比,rank@1提高了22.28%,mAP提高了24.41%,与经典细粒度算法MGN虽然rank@1只有0.78%的提升,但是在mAP方面却提高了18.21%,与最新的Top-DB-Net相比,rank@1和mAP分别提升了16.08%和12.81%;在DukeMTMC-reID数据集上,与经典分块策略模型的PCB相比,rank@1提高了7.84%,mAP提高了13.94%,与最新的CBN相比,rank@1提高了7.04%,mAP提高了12.74%;由于在Market-1501数据集上,大量的算法使得性能达到了饱和,但是本算法与分块策略模型HPM相比,rank@1仍提高了1.61%,mAP提高了5.91%。因此,本文所提算法具有较高的精确度,并在目前主流算法中有一定的优势。
3 结束语
本文提出了一种基于复合尺度与多粒度联合特征的行人重识别算法。利用复合尺度模块提取不同深度的全局特征,通过多粒度模块将复合尺度的全局特征进行多粒度划分,使得网络能够在不同的粒度中进行区域的显著特征提取,利用不同尺度信息补充了单一粒度信息的不完整性,最后对粗粒度语义信息进行全局平均池化和细粒度语义信息全局最大池化,以增强特征的判断力。针对损失函数,利用批次难样本三元组损失函数进行样本约束,有效地解决身份丢失问题。通过不同的数据集实验,说明本文方法具有良好的泛化性以及较强的识别能力。接下来的工作是探索本方法在跨模态领域中的研究,进一步提高精度。
