融入混合注意力的可变形空洞卷积近岸SAR小舰船检测
2022-12-21龚声蓉徐少杰周立凡朱杰钟珊
龚声蓉,徐少杰,周立凡,朱杰,钟珊
1. 东北石油大学计算机与信息技术学院, 大庆 163318; 2. 常熟理工学院计算机科学与工程学院,常熟 215500
0 引 言
合成孔径雷达(synthetic aperture radar,SAR)可以提供全天候全天时的高分辨率图像,在海洋监测和海上交通监管中发挥着重要作用(Liu等,2019)。近年来,SAR图像的舰船检测引起了人们的关注(Heiselberg和Heiselberg,2017;阮晨 等,2021),传统方法主要依赖于恒虚警率(constant false-alarm rate,CFAR)及其改进算法(Dai等,2016;Ao等,2018),这些方法基于手工制作的特征,速度慢,易受屋顶、集装箱等类似船舶的物体或由海杂波引起的干扰,对复杂背景下的小型船舶识别效果不佳。因此,迫切需要新的目标检测模型来提高SAR舰船的检测性能,尤其是提高近岸复杂背景下小型舰船检测性能。
卷积神经网络(convolutional neural network,CNN)可以从数据本身学习深层特征,它的特征提取能力比手工制作的特征提取器更为优越(Wang等,2019)。因此,基于CNN的检测器已经广泛应用于SAR图像舰船检测中。Li等人(2017)使用迁移学习和困难样本挖掘等策略将Faster-RCNN(faster region convolutional neural network)(Ren等,2017)算法用于SAR舰船检测,但忽略了SAR图像中各种舰船尺寸差距过大的问题。Zhao等人(2019)在Li等人(2017)方法的基础上,采用多层次特征融合改进了一阶段检测器SSD(single shot multibox detector)(Liu等,2016),大幅改善了模型对多尺寸舰船检测效果。
但是,针对SAR图像近岸复杂背景下小型舰船检测任务的深度学习目标检测模型依然较少,且具有诸多挑战(阮晨 等,2021)。首先,与光学图像不同,SAR图像主要通过不同目标的后向散射回波来构建图像。因此,在SAR图像中没有颜色、纹理等特征,只能大致显示目标的形状和亮度。在空旷海面上,舰船目标在SAR图像中呈现亮白色舰船形状,海水则是黑色,易于网络区分学习。然而,近岸港口情况多变,现有方法无法正确区分部分建筑物、暗礁与小型船舶,造成误检和漏检。此外,在内陆河道、港口等场景中,小型舰船通常紧密停靠在一起,在SAR图像中呈现为连成一体的形状,现有方法难以精确定位每艘船的边界,导致多艘舰船检测为1艘舰船,造成漏检。
针对上述问题,Lin等人(2019)在Zhao等人(2019)方法的基础上,使用编码尺度向量排序来过滤向量值较低的候选框,减少了近岸建筑物的干扰,但同时也使网络直接忽略图像质量不高的小型舰船,造成漏检。Gui等人(2019)基于轻量级检测器,直接合并浅层和高层(丢弃中间层)来提高模型定位精度,却降低了模型对中型舰船的检测精度。Dai等人(2020)引入双向多尺度特征融合技术来加强网络对已提取特征图的融合效果,却忽略了对近岸复杂背景的抑制,虽然提升了对小型舰船的查全率,但降低了查准率。阮晨等人(2021)在Dai等人(2020)方法的基础上,引入权重机制,区分不同尺度特征图的重要性,并在融合前使用视觉注意力机制引导网络抑制近岸复杂背景,提出了一种无锚框近岸舰船检测方法。
上述方法主要考虑对SAR图像提取的多层级特征图做一些复杂融合,用上层语义信息辅助模型进行分类,下层空间信息辅助模型进行定位,未充分考虑卷积核形状与舰船形状之间的联系,导致模型对近岸小型舰船检测精度依然较低。本文以Cascade-RCNN(Cai和Vasconcelos,2018)模型为基线模型,分析模型误检漏检的场景及原因,针对性地提出一种基于可变形空洞卷积的SAR舰船特征提取网络。首先,使用一种加权融合可变形空洞卷积(weighted fusion deformable atrous convolution,WFDAC)替代ResNet-50(He等,2016)中的3×3卷积模块,扩大模型感受野,进行多感受野特征提取与融合,引入目标极点的局部信息辅助模型分类。接着,提出3通道混合注意力机制(triple mixed attention,TMA),引导网络更加关注近岸细节提取,提高模型细分类效果。
1 本文算法
1.1 FENDet模型整体结构
为了探究传统方形3 × 3卷积在SAR舰船领域的使用效果,本文使用HRSID(high-resolution sar images dataset)数据集(Wei等,2020)进行研究与实验。HRSID数据集将舰船分为近岸场景与离岸场景,近岸场景与离岸场景的舰船图像示例如图1所示,其中,绿色矩形框为舰船标注。

图1 HRSID数据集示例Fig.1 Samples of HRSID ((a) offshore sample; (b) inshore sample)
表1展示了Cascade-RCNN在HRSID数据集中近岸和离岸场景下的检测结果。Cascade-RCNN在离岸简单背景下的平均精度(average precision,AP)为98.0%,在近岸复杂背景下的AP值却只有79.6%。其中,小舰船与大舰船的AP值较低。表明模型对近岸复杂背景下的小舰船和大舰船检测效果不佳。在HRSID数据集中,小、中、大型舰船的占比分别为60.2%、36.8%、3%。大型舰船检测精度低可能是由于样本数量较少等原因造成的。
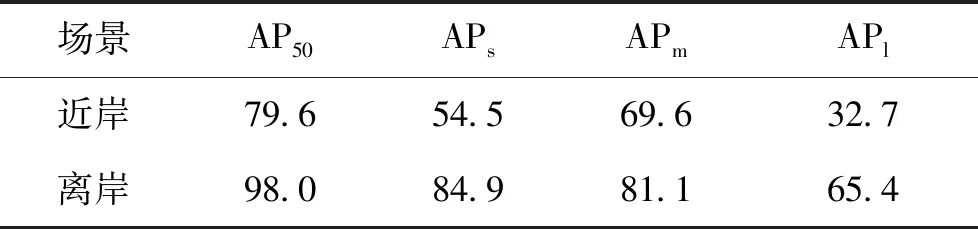
表1 Cascade-RCNN在HRSID数据集上的检测精度Table 1 Cascade-RCNN detection precision on HRSID /%
为了探究小型舰船在近岸复杂场景下检测精度低的原因,本文分别选取在简单背景下、近岸复杂场景下、近岸密集场景下和近岸建筑物干扰场景下的SAR舰船图像,Cascade-RCNN的检测结果如图2所示。可以看出,在简单场景下(图2(a)),Cascade-RCNN检测舰船的能力较高,但是对图像边缘和紧靠在一起的舰船出现了误检和漏检情况,说明模型对舰船定位精度不够。在近岸复杂场景下(图2(b)—(d)),Cascade-RCNN容易将近岸的建筑物或水中的岛屿误检成舰船。通过对误检漏检小目标的观察与分析,本文发现许多误检的岛屿和陆地建筑,在某些特征上与舰船目标相似,如长宽比都在1.5-2.2之间,整体亮度均衡等。说明Cascade-RCNN对小目标的细节特征提取与细分类效果不佳。原因可能是这些小目标像素总量较小,在高层次特征图上无法提供详细语义信息,在低层次特征图上提供了许多相似的细节信息。
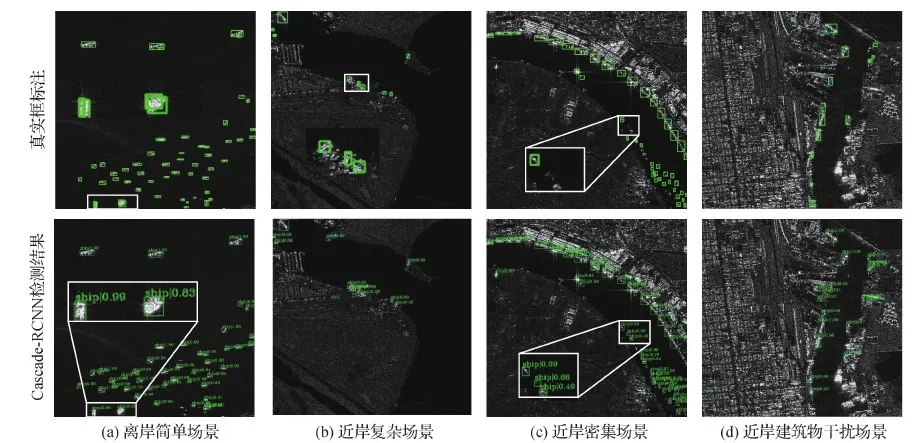
图2 Cascade-RCNN在不同场景下的检测结果可视化Fig.2 Visualization of detection results of Cascade-RCNN in different scenarios ((a) offshore simple; (b) inshore complex; (c) inshore dense; (d) inshore building disturbance)
针对模型对小目标的细节特征提取与细分类效果不佳问题,本文提出一种针对复杂背景下SAR近岸舰船的特征提取网络(feature extraction network,FEN)。图3展示了FEN与Cascade-RCNN结合后的检测器FENDet结构。本文算法首先使用加权融合可变形空洞卷积模块取代残差块中的3 × 3传统卷积,接着在每一层级特征图前使用3通道混合注意力机制引导网络关注细节特征,最后通过原Cascade-RCNN检测网络进行特征融合、候选框筛选与预测,生成最终结果。
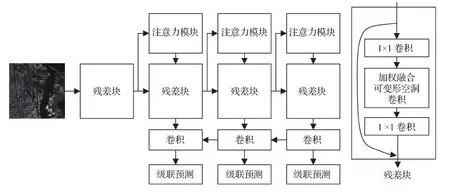
图3 FENDet模型结构Fig.3 The structure of FENDet
1.2 加权融合可变形空洞卷积
一般情况下,出于性能和计算量的考虑,大部分基于CNN的检测模型以ResNet-50为骨干网络,这种模型深度限制了网络的感受野,导致模型在浅层特征提取时只能提取每一像素点周围8个点的特征并进行融合,在高级语义特征提取时也只是机械性提取方形区域内固定点的信息。而在SAR图像中,舰船通常为长条形斜向停靠,在舰船目标周围的任一方形区域内,既存在舰船信息,也存在舰船附近的背景信息。因此,固定方形形状与大小的传统卷积核,会同时提取舰船与舰船周围的背景特征,给模型分类和定位造成干扰。此外,传统卷积的感受野RFi较小,计算为
(1)
式中,RFi-1表示上一层的感受野,ki表示第i层的卷积核尺寸,sj表示第j层的卷积步长。
在浅层网络中获得舰船目标的整体信息有助于模型进行分类。然而,普通的卷积在浅层的感受野有限,因此本文引入空洞卷积(Chen等,2018)来扩大卷积的感受野。空洞卷积是一种能够扩大卷积核感受野的有效技术。空洞率为r的空洞卷积会在普通的卷积核权值之间引入r-1个零点,相当于将k×k卷积核扩大到k+(k-1)×(r-1),却不增加任何参数或计算量。然而,单纯的使用空洞卷积提取特征,由于零点的存在,会造成特征图中相邻信息的不连续性。因此,本文对不同空洞率卷积核提取的特征图进行加权融合,增加了特征图中特征的关联性。此外,大部分舰船在SAR图像中呈长条形。如果直接使用空洞卷积进行特征提取,方形提取框会引入更多的背景信息干扰模型进行分类与定位。因此,本文在空洞卷积的基础上引入可变形卷积(Zhu等,2019),使卷积核提取的位置更加贴合舰船形状,极大程度地减少了背景信息对目标分类的干扰。
图4直观展示了传统卷积和本文所提加权融合可变形空洞卷积的感受野对比。图4(a)中的绿色方形框表示传统卷积的感受野,图4(b)中的紫色不规则多边形框表示加权融合可变形空洞卷积的感受野。可以看出,在同一深度条件下,加权融合可变形空洞卷积的感受野更大,能基本包含舰船目标整体,使网络获得舰船整体信息。

图4 传统卷积与加权融合可变形空洞卷积感受野对比Fig.4 Comparison of traditional convolution and WFDAC perceptual fields ((a) traditional convolution; (b) WFDAC)
图5对比了同一网络深度下,传统3 × 3卷积与WFDAC在特征提取时卷积核权重的相对位置。在图5中,绿色圆点和橙色圆点分别表示3 × 3传统卷积和空洞率为3的3 × 3空洞卷积在提取特征时权重的相对位置,绿色矩形框表示舰船目标。传统卷积如图5(a)所示,通过权重与固定位置像素相乘来提取特征。图5(b)为在传统卷积的基础上增加一个空洞卷积后,两个卷积权重的相对位置,通过不同空洞率卷积核权重分别与固定位置像素相乘并融合来提取特征。图5(c)为对两个卷积分别逐一预测相对偏移位置,使权重相对位置更贴合舰船形状后,可变形空洞卷积权重的相对位置。然后将不同空洞率卷积核权重分别与相对偏移位置上的像素相乘并加权融合来提取特征。
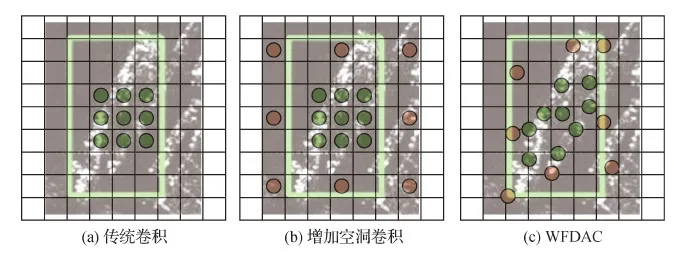
图5 传统卷积与WFDAC卷积核权重相对位置对比Fig.5 Comparison of the relative positions of ordinary convolution and WFDAC convolution kernel weights((a) traditional convolution; (b) add atrous convolution; (c) WFDAC)
对一个以x为输入,w为权重,空洞率r为1的传统卷积Conv(x,w,1),转化为WFDAC的计算过程为
fWFDAC=S(x) ·Dconv(x,w,1)+ (1-S(x))·Dconv(x,w+Δw,r)
(2)
式中,S(·)由5 × 5的平均池化和1 × 1的卷积组成,Dconv为可变形卷积,Δw为空洞率为r的卷积核的偏移权重。如果不做特别说明,在实验中,r=3。
WFDAC模块在浅层特征图中提取更大范围的细节信息,并使模型感受野更贴合舰船形状,减少对复杂背景的特征提取。在深层特征图中,空洞率为1的卷积由于其感受野自然增加,会重复提取浅层特征图中空洞率为3的卷积感受野内的特征,这使得同一感受野、同一区域下的图像区域至少为两个跨层卷积提取特征并进行加权融合,增加了特征提取效率。
加权融合可变形空洞卷积WFDAC的总体结构如图6所示,在WFDAC模块的前后分别增加了一个全局上下文模块。这个模块与SENet(Hu等,2020)相似,但没有任何非线性层,且输出被加回输入特征图而不是与它相乘。增加前处理全局上下文模块是为了给S(·)函数提供全局上下文指导,使其能生成更有效的融合权重。增加后处理上下文模块是为了减少不同感受野特征图相加带来的混叠效应。实验表明,前后全局上下文模块使AP值提升了0.5。
在实验时,本文加载了在ImageNet上训练好的权重文件作为骨干网络ResNet-50的初始权重。但对于从传统卷积层转化来的WFDAC卷积来说,缺少了空洞率为3的权重。针对这一问题,基于不同尺寸的物体可以被同一组权重粗略检测出来这一实际经验,将空洞率为1的卷积权重初始化为W1,空洞率为3的卷积权重初始化为W1+ΔW,这就是图6中的锁定参数机制。其中,W1是ResNet-50在ImageNet上的预训练权重,ΔW初始化为0。实验表明,当固定ΔW为0时,会有0.1AP的下降。但是没有锁定机制的模型会造成5AP的下降,其原因本文推测是因为不同权重会提取特征图的不同信息,如果权重相差过大,在信息加权融合时会出现干扰和矛盾。
1.3 3通道混合注意力机制
人类在视觉感知过程中会将注意力集中于视野中的一部分而忽略其他部分。人类感知中的注意力涉及选择性地集中于给定信息的一部分而忽略其余部分的过程。这种机制有助于提炼感知信息,同时保留其上下文。一些方法提出在CNN架构中有效地合并这种注意机制,以提高大规模视觉任务的性能。这些注意力机制具有通过明确建立通道之间的依赖性或空间上的加权掩膜来改进由传统卷积层生成的特征表示的能力。学习注意力权重本质上是使网络有能力学习不同特征点的重要程度,从而进一步关注目标对象。Wang等人(2017)在残差注意力网络中提出了一种额外掩膜编解码器模块来直接生成立体注意力权重矩阵。Hu等人(2020)在Wang等人(2017)方法的基础上,提出了SENet,通过学习网络中每个通道的权重来模拟特征图中的跨通道关系。Woo等人(2018)在Hu等人(2020)的通道注意力基础上再度集成了空间注意力机制,提出了CBAM(convolutional block attention module),在通道维度和空间维度上利用全局平均池化和全局最大池化来生成注意力权重。Zhao等人(2020)将CBAM注意力模块和空洞卷积模块引入到SAR舰船目标检测任务中来,提高了舰船检测精度。
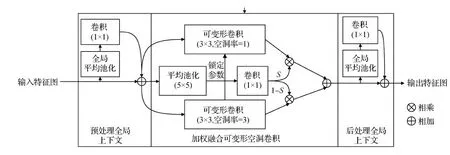
图6 WFDAC模块结构Fig.6 The structure of WFDAC
尽管CBAM引入空间注意力作为通道注意的补充模块,弥补了空间信息的主要损失,但它的空间注意权重和通道注意权重是相互独立计算的,并不考虑两者之间可能存在的依赖关系。受Misra等人(2021)方法的启发,本文引入了跨维度交互的概念,通过捕捉输入张量的空间维度和通道维度之间的交互来解决这个缺陷,提出了3通道混合注意力机制TMA。
本文通过旋转和残差连接寻找不同维度之间权重的依赖关系,并通过一个3分支结构和池化操作融合交叉维度之间权重的依赖关系。3通道混合注意力机制示意图如图7所示,由3个平行的分支组成,其中两个负责捕捉通道维度C与空间维度H或W之间的跨维度权重,另一个分支类似于CBAM,用于建立空间注意力权重。所有3个分支的输出通过简单的平均进行融合。输入特征映射F∈RC×H×W分别与空间注意权重矩阵WS∈R1×H×W、通道—横向注意权重矩阵WCW∈R1×C×W和纵向—通道注意权重矩阵WHC∈R1×H×C相乘,获得显著特征映射F′∈RC×H×W。计算过程为
(3)
式中,⊙表示点乘。
空间注意模块主要提取特征映射的位置信息。
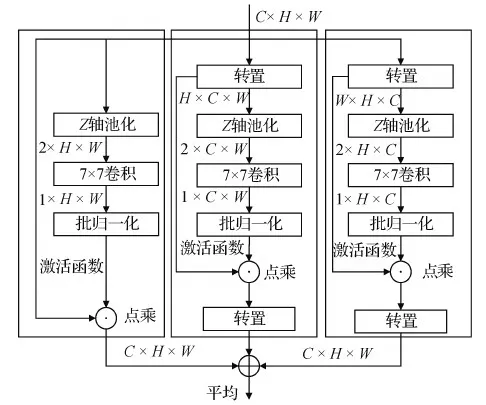
图7 TMA模块结构Fig.7 The structure of TMA
首先,沿通道轴分别进行最大池化和最小池化,突出显示特征图空间中的极值信息并将结果拼接起来。接着,使用一个7 × 7的卷积层对拼接后的特征图进行降维与特征提取,生成空间注意图。计算过程为
WS(F)=σ(conv7×7(concat(Pmax(F),Pmin(F))))
(4)
式中,σ表示sigmoid函数,conv7×7表示7×7的卷积和批归一化运算,concat表示拼接操作,Pmax表示最大池化,Pmin表示最小池化。通道—横向注意模块和纵向—通道注意模块主要提取跨维度权重的相互关系,如图7所示,计算过程与空间注意力相似,只是在开始和末尾对输入特征映射F∈RC×H×W进行了90°的旋转与逆旋转操作。
本文将TMA模块添加在每个阶段输出特征图之前,通过连续的空间注意力和跨维度注意力提高特征图的区域关注能力,可有效减少SAR近岸场景中的复杂背景干扰,如暗礁、近岸形似建筑等。
2 实验与分析
2.1 实验平台
实验运行环境为i7-9750 CPU,Nvidia Tesla P100 GPU,16 GB显存。操作系统Ubuntu16.04,深度学习框架Pytorch 1.6.0,脚本语言Python 3.7。CUDA(compute unified device architecture)和cuDNN(compute unified device architecture deep neural network)版本分别为CUDA 10.1和cuDNN 7.6.4。
2.2 实验数据集
选用HRSID(Wei等,2020)和SSDD(SAR ship detection dataset)数据集(Li等,2017)评估本文方法。SSDD是第1个公开的SAR舰船检测数据集,数据主要由RadarSat-2, TerraSAR-X, and Sentinel-1提供,拍摄于中国烟台和印度维萨卡帕特南,分辨率为1-10 m,包含海洋和近岸地区的大量船舶目标,共有1 160幅图像和2 456个舰船目标,平均每幅图像包含2.12艘舰船,小型、中型和大型舰船占比分别为60.2%、36.8%和3%,训练集和测试集分别包含928和232幅图像。
HRSID数据集是2020年发布的一个大型SAR舰船检测数据集,包含不同场景、不同雷达和不同极化方式生成的图像。HRSID中有5 604幅经过裁剪的舰船图像,包含16 951个舰船目标,平均每幅图像包含3艘舰船,小型、中型和大型舰船占比分别为54.5%、43.5%和2%,训练集和测试集分别包含3 642和1 962幅图像。
SSDD和HRSID数据集的对比如表2所示。
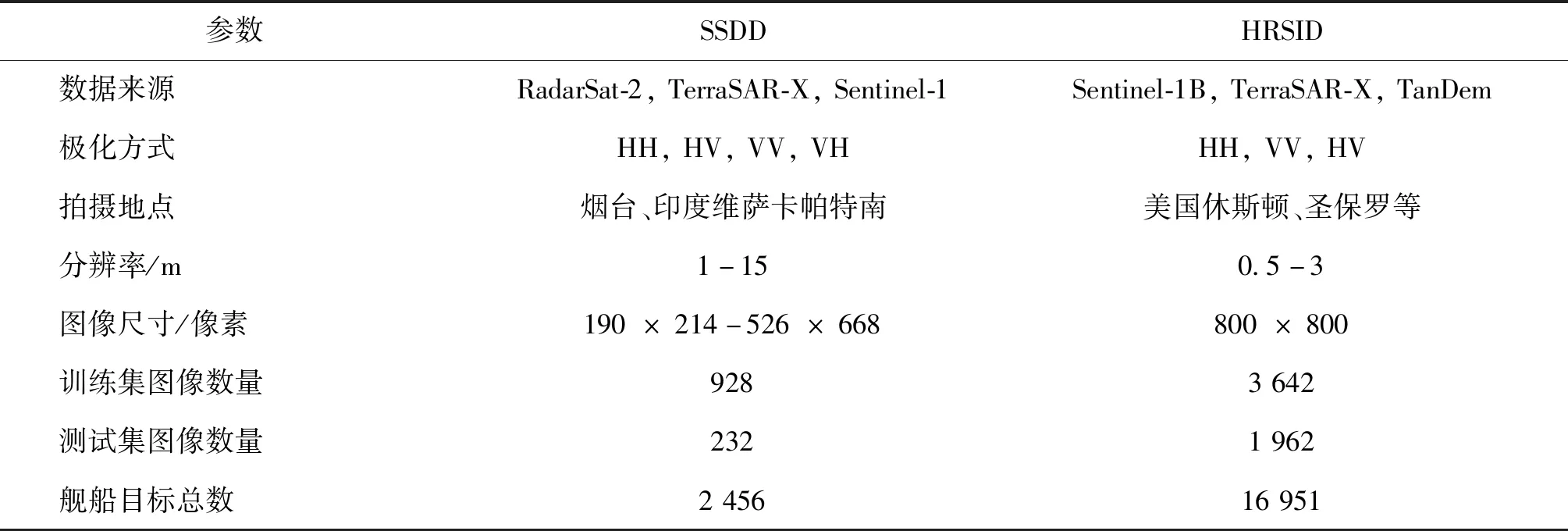
表2 SSDD和HRSID数据集参数对比Table 2 Comparison between SSDD and HRSID datasets
2.3 模型评价指标
采用精度P(precision)和召回率R(recall)两个平均精度系列指标评价和对比模型效果。
精度P定义为预测正确的正例占预测结果中所有正例的比例,即
(5)
召回率R定义为预测正确的正例占被预测样本中所有正例的比例,即
(6)
式中,TP为预测正确的正样本数量,FP为预测错误的负样本数量,FN为预测错误的正样本数量。
以舰船类目标的精度为x轴以及召回率为y轴绘制P-R(precision-recall)曲线,然后计算这条曲线与坐标轴之间的面积,得到舰船类目标的AP,具体为
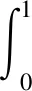
(7)
式中,P表示精度,R表示召回率。
根据区域交并比(inter of union,IoU)取值的不同和目标大小的不同,本文将AP指标细分为AP、AP50、AP75、APs、APm和APl。AP系列指标有10个IoU阈值,分布在0.5-0.95之间,步长为0.05。AP是10个IoU阈值AP分数的算数平均,AP50和AP75分别是IoU阈值选择为0.5和0.75时的AP分数。APs、APm和APl分别是尺寸较小(面积< 32×32像素)、尺寸中等(32×32像素<面积<64×64像素)和尺寸较大(64×64像素<面积)对象的AP分数。
2.4 模型训练参数
为保持检测器的相同超参数,选择mmdetection(Chen等,2019)进行训练和测试。为了进行更精确的分类与定位,训练和测试过程中,SAR图像按比例调整为1 000 × 1 000像素。检测器用GPU(graphics processing unit)训练,共12轮;动量和权重衰减分别设置为0.9和0.000 1。训练和测试中对低精度边界框严格过滤时,IoU阈值设置为0.7。Cascade-RCNN中的IoU阈值设置为{0.5,0.6,0.7}。本文选择初始学习率为0.002 5的SGD(stochastic gradient descent)作为优化器,其他超参数在mmdetection中设置为默认值。
2.5 结果与分析
2.5.1 各模块有效性分析
为了验证WFDAC和TMA两个模块对检测效果的影响,对各模块进行评估,在HRSID数据集上以Cascade-RCNN为检测模型,对两个模块进行消融实验,结果如表3所示。可以看出:1)添加WFDAC模块(第2行)后,模型在各方面,尤其是大型舰船检测精度得到较大提升,从26.6%提升到31.4%。主要是由于WFDAC模块扩展了模型每一层的感受野,使模型能够将大型舰船当做一个整体来学习。此外,空洞率为1的卷积与空洞率为3的卷积融合方式,使模型在不同深度上提取同一感受野不同层次的特征并加以融合,这种特征重提取也是模型能提高小型舰船检测精度的原因。2)TMA注意力机制模块(第3行)的AP75指标有较大提升,这是因为原来的Cascade-RCNN提取底层位置信息不够明确,造成了模型预测时高质量目标框不多。TMA模块增强了网络对舰船区域的关注度,使预测的目标框更加精准。3)两个模块结合使用后,模型对特征信息的提取更加精准,能有效区分小型舰船与相似岛屿、小型建筑物之间的细微区别,AP50和APs在原来的基础上分别增加了2.8%和3.5%。
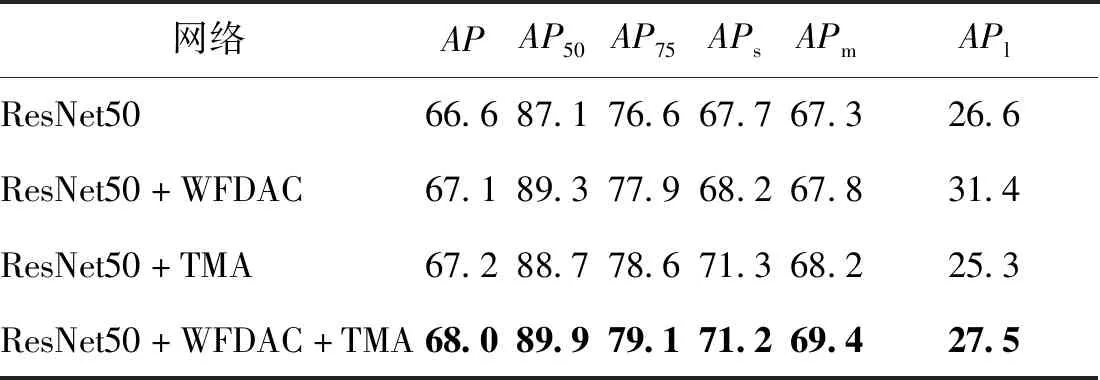
表3 在HRSID数据集上的消融实验Table 3 Ablation experiments on HRSID dataset /%
空洞率r对WFDAC模块的性能影响如表4所示。为提高特征提取效率,本文根据两个可变形空洞卷积相对位置偏移不重合和传统卷积跨两个阶段对可变形空洞卷积感受野特征进行高级语义特征提取这两个规则,将实验中的空洞率r设置为1、3、5。可以看到,当r=3时,效果最佳。当r=1时,WFDAC模块退化为两个同样感受野的可变形卷积进行特征提取与融合,因此提升较小。当r=5时,可能由于两个卷积之间距离太远,模型难以获取两个卷积之间的权重关系,造成精度下降。
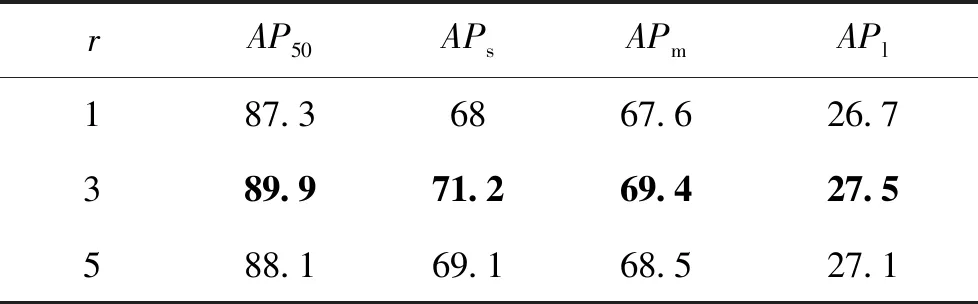
表4 空洞率r对可变形空洞卷积模块性能的影响Table 4 Effect of void ratio on WFDAC module
TMA与其他注意力模块在ResNet-50上的参数增加量对比如表5所示。在参数计算公式中,C表示该层的输入通道数量,r表示在计算通道注意力时在MLP(multi-layer perceptron)瓶颈中使用的缩减率,k表示注意力模块中卷积核的大小。实验中,设置r= 16,k= 7。结果表明,TMA的参数开销较小。

表5 不同注意力模块在ResNet-50上的参数增加对比Table 5 Comparison of parameter increases for different attention modules on ResNet-50
传统卷积和WFDAC在相同深度下的特征提取结果对比如图8所示。图8(b)(c)分别取自原始ResNet-50模型第一层和最后一层卷积的前9个通道,图8(d)和图8(e)分别取自WFDAC替换传统卷积后ResNet-50模型第一层和最后一层卷积的前9个通道。可以看出,相比于传统卷积提取的细节特征(图8(b)),WFDAC在浅层网络可以提取更多全局信息(图8(d)),且对输入图像中各物体的位置保留得非常完整,更有利于模型对舰船目标进行定位。相比于传统卷积提取的语义特征(图8(c)),WFDAC在深层网络可以提取更多有效语义信息(图8(e)),辅助模型进行分类。
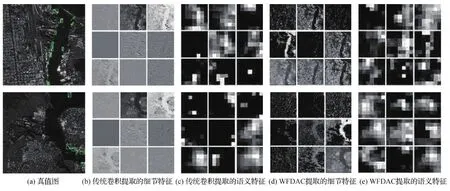
图8 传统卷积与WFDAC特征提取结果对比Fig.8 Comparison of traditional convolution and WFDAC feature extraction results((a) ground truth; (b) detailed features by traditional convolution; (c) semantic features by traditional convolution; (d) detailed features by WFDAC; (e) semantic features by WFDAC)
图9展示了模型增加TMA前、后对输入图像的类激活图的对比结果。图9(a)中,舰船目标用绿色矩形框标出。图9(b)和图9(c)分别为模型增加TMA前、后对输入图像的类激活图,蓝、绿、黄、红表示激活程度递增。
从图9(b)可以看出,原模型对舰船目标的关注度较为宽泛,对舰船目标周边的背景像素给予了较高关注度,在舰船像素上的激活程度不高。增加TMA模块约束了模型的关注范围,降低了模型对舰船目标周边背景像素的特征提取能力。此外,TMA模块在一定程度上增加了模型对舰船像素的类激活度,突出了舰船和舰船周边相似建筑的差异性。
2.5.2 FEN有效性分析
为验证骨干网络FEN的有效性,在两阶段、一阶段和无锚框目标检测器中分别挑选一种经典方法Cascade-RCNN、YOLOv4(you only look once v4)(Bochkovskiy等,2020)和BorderDet(Qiu等,2020)作为检测器在HRSID数据集上进行实验,结果如表6所示。在第1组实验中,3种模型使用ResNet-50作为骨干网络进行特征提取。结果表明,在相同训练参数下,BorderDet的检测精度最高,可能是因为HRSID数据集中小型舰船占比较高,且舰船一般呈斜向分布。而通过预测极值点来确定目标位置,并通过极值点信息进行分类的无锚框方式不容易受到舰船目标周围环境的影响。3种检测器中,Cas-cade-RCNN对大型舰船的检测精度最高,因为在区域推荐过程中,所有特征图压缩为20 × 20像素,有利于模型生成更能多包含大型目标的候选框。在第2组实验中,3种模型使用本文所提的FEN作为骨干网络。可以发现,3种检测器的AP50分别增长了2.8%、2.6%和1.6%。说明FEN能够显著增强模型的特征提取能力,并进一步提升舰船检测精度。在小型舰船检测精度上,3种检测器分别增长了3.5%、2.6%和2.9%,在中型舰船和大型舰船上,3种检测器的精度也有一定上涨,充分验证了FEN特征提取网络在改善小型舰船误检漏检情况时的有效性。值得一提的是,在BorderDet中,模型主要通过4个极值点的信息进行目标的定位和分类,致力于提取目标周边局部信息的FEN反而对模型造成了干扰,导致模型对大型舰船的检测精度有所下降。

图9 TMA模块的类激活图对比Fig.9 Comparison of class activation diagrams with and without TMA modules ((a) ground truth; (b) without TMA; (c) with TMA)

表6 在HRSID数据集上不同模型使用ResNet-50和FEN作为骨干网络的平均精度比较Table 6 Comparison of the average accuracy among different models on the HRSID dataset using ResNet-50 and FEN as the backbone network /%
本文方法在HRSID数据集上不同场景的测试结果可视化样例如图10所示。图10(a)是在空旷海面上对稀疏简单背景下小型舰船的检测结果,图10(b)—(d)分别是在近岸复杂背景下对小型密集分布舰船、多尺度分布舰船和大型舰船的检测结果。可以看出,本文算法对简单背景下的小型舰船检测基本无漏检误检,对近岸复杂背景下停靠较近的小型舰船可分辨舰船数量并精准定位,对与舰船相似的岛屿和岸上建筑物,由于注意力机制的存在,也能区分它们与舰船的差别。此外,对占据图像大部分区域的大型舰船,由于模型感受野的增加,也能较为准确地识别。

图10 Cascade-RCNN+FEN在HRSID数据集上的检测结果Fig.10 Detection results on HRSID dataset with Cascade-RCNN+FEN ((a) small ships in sparse background empty sea surface; (b) small and densely distributed ships in nearshore complex background; (c) multi-scale distribution of ships in nearshore complex background; (d) large ships in nearshore complex background)
为探究本文方法主要提升简单背景还是复杂背景的舰船检测精度,对本文基准方法和Faster-RCNN(Ren等,2017)、RetinaNet(Lin等,2017)、Mask-RCNN(He等,2017)、Mask Scoring RCNN(Huang等,2019)、Cascade Mask RCNN(Cai和Vasconcelos,2018)等先进检测器以及本文方法进行测试。测试时,将HRSID数据集分为近岸和离岸场景,近岸场景背景较为复杂,离岸场景背景较为简单。测试结果如表7所示。可以看到,本文方法在近岸和离岸场景中均取得了最优结果。其中,相较于基准模型Cascade-RCNN,本文方法在近岸和离岸场景中AP分别提升了3.5%和1.2%,表明本文方法的提升主要体现在复杂场景下的精度提升,证明了本文方法在复杂场景下的有效性。
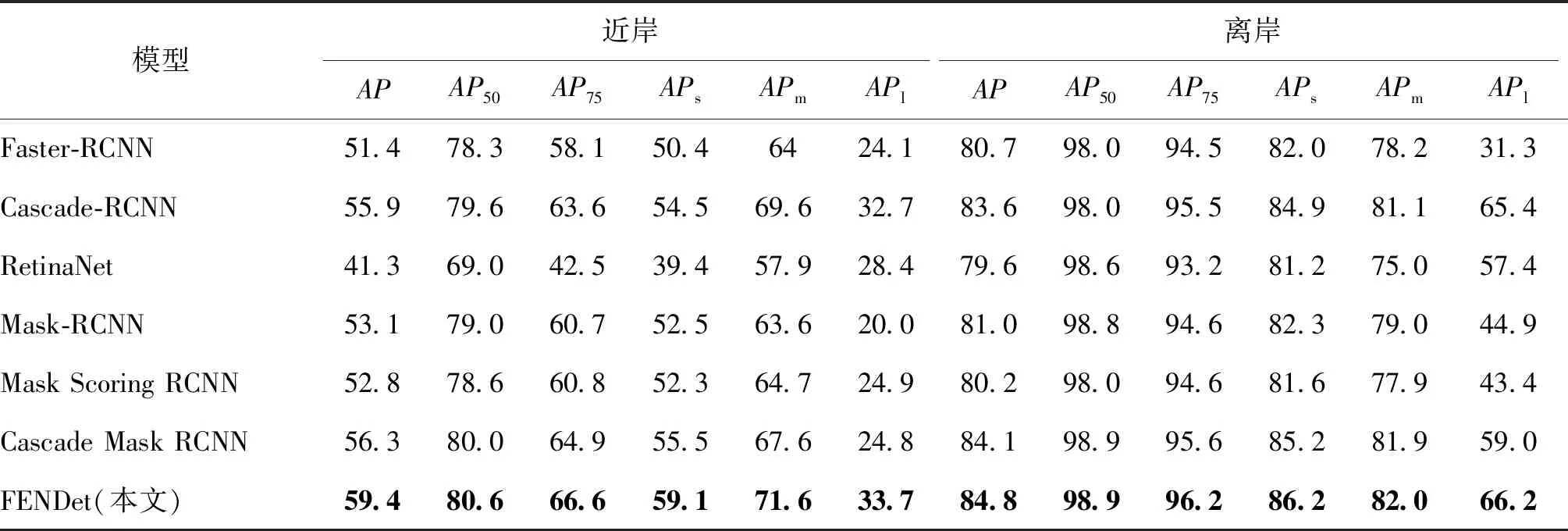
表7 HRSID数据集中近岸与离岸场景检测情况对比Table 7 Comparison of nearshore and offshore scenario detection results in the HRSID dataset /%
2.5.3 泛化性分析
HRSID数据集是2020年提出的SAR舰船检测数据集。为了证明本文模型的泛化性,在经典SAR舰船检测数据集SSDD上,将本文方法与其他先进检测器精度进行对比,结果如表8所示。可以看到,一阶段的目标检测器精度落后于二阶段检测器,在二阶段检测器中,级联的检测器精度高于原本的检测器。需要说明的是,由于SSDD数据集并没有语义标注,所以表8中的检测器都没有语义分支。实验结果表明,与其他先进检测器相比,本文方法效果最佳。
3 结 论
SAR图像舰船检测的挑战之一在于对近岸小舰船目标的细节特征提取和细分类效果不佳。为了缓解上述问题,本文从微观上引入加权融合可变形空洞卷积替代传统卷积,使每层网络可以自适应提取和融合不同感受野特征。此外,本文引入3通道混合注意力机制,使网络可以关注更重要的信息,减少陆地复杂情况干扰。本文方法提高了模型在HR-SID和SSDD舰船检测数据集上的检测精度,分别从87.1%和93.1%提高到89.9%和95.9%。然而,本文方法所需计算资源较多,在下一步工作中,将重点关注现有模型无法在卫星等资源受限场所应用的问题,围绕模型压缩与轻量化展开研究,进一步提升模型的实用性。
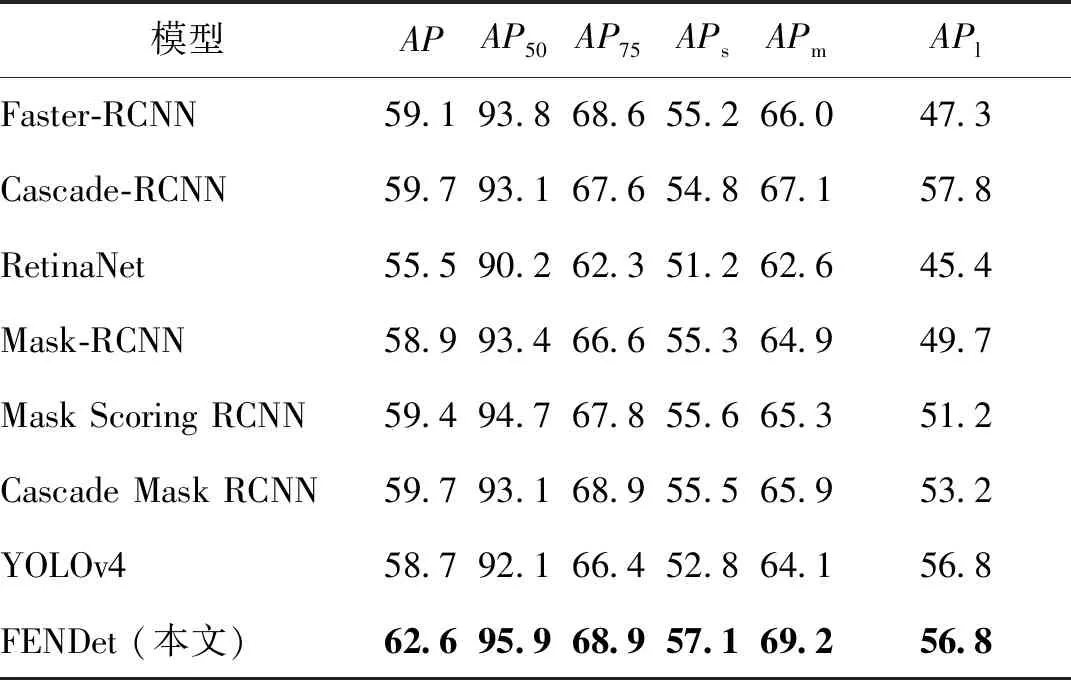
表8 在SSDD数据集上本文方法与其他检测器的精度对比Table 8 Accuracy comparison of our method and other detectors on the SSDD dataset /%
