融合多头注意力机制的新冠肺炎联合诊断与分割
2022-12-21李金星孙俊李超BilalAhmad
李金星,孙俊,李超,Bilal Ahmad
江南大学,无锡 214122
0 引 言
自2020年,一种新型冠状病毒引发的肺炎疫情在全世界迅速蔓延,严重威胁着人类生命与健康。世界卫生组织将这种新型冠状病毒肺炎命名为“2019新型冠状病毒病”,简称“新冠肺炎”或“COVID-19”(corona virus disease 2019)。据Worldometer网站报道,截止到2021年9月23日,全球约有2.3亿新冠感染病例。新冠肺炎是一种由新型冠状病毒引发的急性呼吸道传染病,传染性强,症状隐蔽,病死率高;而控制新冠肺炎传播的关键是尽快筛查出被感染者并及时隔离治疗,防止出现大规模的“人传人”。但是如何快速识别出人群中的病毒携带者,这是疫情防治过程中的一个重大难题。目前,大规模使用的方法是核酸检测,即聚合酶链反应(polymerase chain reaction,PCR),该方法通过查找人的呼吸道标本中是否存在新冠病毒的核酸,来确定是否被感染。一旦核酸检测为 “阳性”,即可证明患者体内有病毒存在,然而这种检测存在一定的局限性。一是传统的实验室方法耗时耗力;二是检测结果会存在假阴性;三是检测结果反馈具有一至两天的滞后性。因此,为应对大规模的实时检测,开发一款快速精准的计算机辅助诊断方法至关重要。
人工智能飞速发展,并广泛应用于各个领域。其中,深度学习作为人工智能技术的核心,已成功地应用在肺部医学影像的自动诊断或病灶分割(康波 等,2020)。而且主要涉及两种放射成像影片,即胸部CT(computed tomography,CT)和X线胸片(chest X-Ray,CXR)。由于CT成像会产生强辐射,一般禁止用于孕妇和儿童,而CXR作为一种非侵入性检查,辐射明显低于CT(孟琭和李镕辉,2020),并且CXR成像比CT成像更快、更便宜。因此,相比CT,CXR更适合大规模使用。本文工作主要面向CXR的深度网络构建。
为对抗新冠病毒,前人已经提出了各种CXR自动诊断分类网络,并且绝大多数都基于卷积神经网络(convolutional neural networks,CNN)的架构。Farooq和Hafeez(2020)通过改进ResNet50提出了COVID-ResNet,用于CXR的4分类诊断,准确率达到了96.23%。Apostolopoulos和Mpesiana(2020)报道了一种结合迁移学习的VGG19(Visual Geometry Group)网络,可以在CXR的2分类诊断上达到98.75%的准确率。Das等人(2020)精简了Inception_v3网络,面向CXR的3分类和4分类诊断,分别达到了99.96%和99.92%的准确率。此外,Owaist等人(2021)提出一种聚合了多级特征的深度网络,能以95.38%的准确率筛选出COVID-19感染者(CXR的2分类诊断)。虽然现有网络表现出卓越的分类精度,但由于它们训练测试的数据过少,有的只有几百幅CXR,很难满足深度网络的数据需求,网络可能存在过拟合,而且网络对CXR的分类相对简单。并且在CNN中,卷积操作只能从图像的固有像素提取局部特征,而无法关注到这些特征的优先级。当肺部疾病的分类粒度进一步细化,使用CNN去处理CXR可能不再适合。为此,Park等人(2021)首先提出了一种基于视觉Transformer(vision transformer,VIT)的模型,实现了对CXR的自动分类诊断和肺部感染严重性的分析,在3个外部数据集上测试,该模型分别实现了93.2%、92.1%和92.8%的3分类诊断(Park等,2021)。但是Park等人(2021)提出的Transformer网络只使用深层抽象特征(通过DenseNet主干提取)作为嵌入特征。虽然这与大多数计算机视觉中的VIT架构(Carion等,2020)设计相符,但完全忽视了医学影像CXR的表观特征。
现如今,医学影像分割领域也越来越多地采用CNN的深度网络。Ronneberger等人(2015)提出了U-Net模型,它采用U形编码器—解码器架构对图像进行像素级的分类以完成分割任务。编码器通过卷积和下采样提取高分辨率的语义信息,解码器通过卷积和上采样将编码特征输出为二值分割掩模(分割标签),而且网络使用跳跃连接将编码特征与解码特征连接,以避免梯度消失。U-Net具有优异的分割性能,自其出现以来大量的改进架构相继提出。Zhou等人(2018)提出了一个具有密集和嵌套连接(跳跃连接)的U-Net版本,有效地提升了分割精度,称做U-Net+,然而在U-Net和U-Net+中,编码器的连续下采样和大步长的卷积操作可能会导致某些特征信息的丢失。因此,Gu等人(2019)使用了一种新的语义编码器,即ResNet34的前4层,以收集更多的上下文特征,减少特征的丢失,称做CE-Net(context encoder network)。但同样地,由于卷积操作固有的局部性,这些CNN的分割模型不能实现对全局特征的建模。为增加图像的全局信息,本文使用Transformer架构,通过注意力机制对图片的高级上下文特征进行建模。本文的工作体现在以下4个方面:
1)构建了一个名为ViTNet(vision transformer network)的Transformer深度网络,能够同时实现肺部影像的分类诊断和区域分割。
2)提出了一种适合分类和分割联合训练的混合损失函数。
3)编译了一个CXR 5分类并带有新冠肺部感染区分割掩膜的数据集。
4)将提出的架构应用于CXR自动诊断分类和新冠感染区分割,结果明显优于主流的分类和分割网络。
1 多头注意力机制
Transformer的初次提出是为了解决机器翻译问题,因为它能捕获到全局的上下文信息,相比于传统的循环神经网络(recurrent neural network,RNN)具有明显优势。Transformer的全局属性主要体现在它的编码方式和多头注意力机制(multiple head attention,MHA)(Vaswani等,2017)。Transformer的编码输入是同维(d维)向量的有序序列,表示了所有的特征信息。多头注意力机制将输入序列矩阵中每个向量h等分,整个输入矩阵随即分为h个不同的子块,原序列特征被映射到了h个子空间中,h是总头数,每个注意力关注一个子空间上的输入信息。图1显示了多头注意力模块的计算过程,MHA的输入是3个输入序列矩阵(查询矩阵、关键值矩阵和数值矩阵)分别映射到h个子空间的结果,表示为[q1…qh],[k1…kh],[v1…vh]。当[q1…qh],[k1…kh],[v1…vh](3个输入矩阵)的输入特征完全相同时,MHA输出自注意力后的结果;当[q1…qh],[k1…kh],[v1…vh]的表示特征不同时,MHA输出交叉注意力后的结果,即
output=MHA([q1…qh], [k1…kh], [v1…vh])
(1)
多头注意力机制最大的特点就是能够根据头数平行地计算,以节省运行时间。如图1中MHA过程,对于第i个头的输入qi,ki,vi,首先进行线性映射Linear(),分别输出Qi,Ki,Vi,即
Qi=Linear1(qi)=Wqqi
Ki=Linear2(ki)=Wkki
Vi=Linear3(vi)=Wvvi
(2)
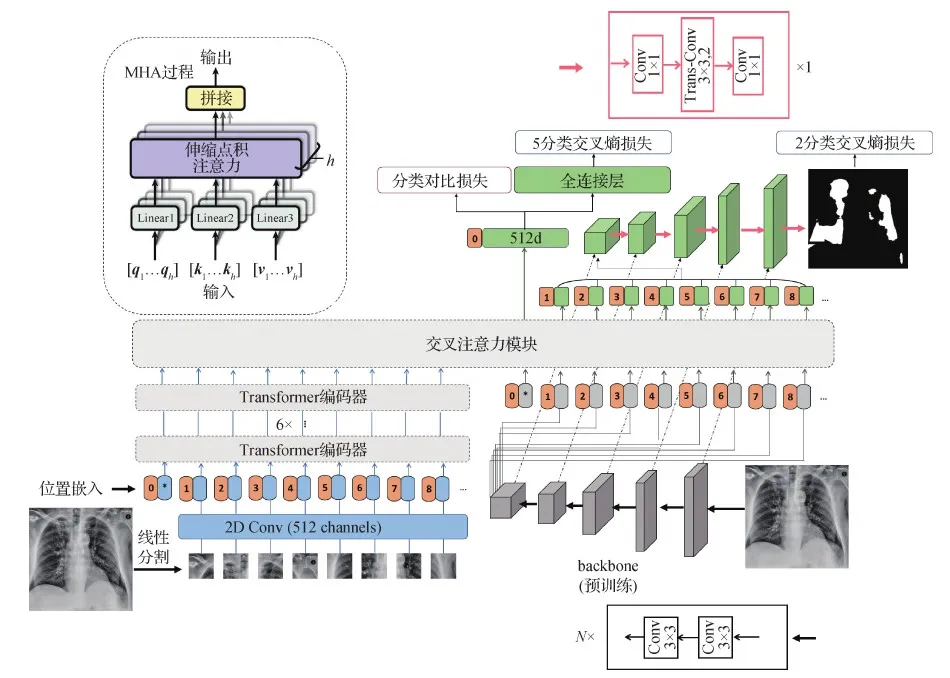
图1 自动诊断与区域分割的网络架构Fig.1 The network frame for CXR auto-diagnosis and lung region segmentation
然后,通过式(3)计算第i头的输出。最后,将各个头的输出拼接起来即为MHA的最终输出,即
(3)
output=[H1…Hh]
(4)
式中,softmax函数计算了注意力权重矩阵与Vi的乘积,输出了数值特征Vi经注意力后的结果。d是常数,等于输入序列中向量的维度,用于缩小(scaled)高维向量的数值。
2 联合诊断与分割网络
2.1 整体架构
如图1所示,本文提出了一种基于Transformer的深度网络,能同时进行CXR分类诊断与感染区分割。当CXR被认为感染新冠肺炎,网络能同时将其感染区域分割出来。网络的整体框架主要由3个部分组成,即双路嵌入层、Transformer模块和分割解码器。
2.2 双路嵌入层
大多数Transformer编码器的嵌入特征单一,或是深层特征序列,或是浅层特征序列。双路嵌入层通过两种映射方式,分别提取出CXR的浅层直观特征与深层抽象特征。一是线性分割CXR为多个小补丁块,将每块补丁的像素数据直接卷积映射到D维空间,得到表示直观特征的向量序列[x1,x2,…,xN];二是使用预训练的网络生成D通道的特征图(H,W,D),再将其线性展开,得到长度为H×W的D维特征向量序列[x′1,x′2,…,x′N],以表示图像的深层抽象特征。
如图1所示,对于同一幅CXR输入,一方面,以32×32像素的滑动窗口线性分割图像(linear project)并使用2维卷积映射出512维向量;另一方面,通过预训练的backbone(选用ResNet34的前4层,原因见5.3节)提取尺寸为(14, 14, 512)的特征图,按通道展开为196个512维向量的线性序列。第1种方式中,每次卷积操作都被限制在滑动窗口裁剪出来的补丁块;第2种方式中,特征图上的边缘位置的感受野不能覆盖原图。因此,两种方式嵌入的向量表示都相对局部。
2.3 Transformer模块
首先,在嵌入的浅层特征向量序列[x1,x2,…,xN]中添加一个用于分类预测的头向量(head token),得到[xpred,x1,x2,…,xN]。然后,添加位置编码,具体为
Y(0)=[xpred,x1,x2,…,xN]+Epos
(5)
式中,xpred∈RD称为预测头,Epos∈RN+1,Y(0)表示第1个Transformer编码器的输入。同样的操作处理深层特征序列[x′1,x′2,…,x′N],得到Y′(0)。
如图1所示,Transformer模块由6个编码器和1个交叉注意力模块串联构成。第i个编码器计算为
Y′(i-1)=LN(MHA(Y(i-1),Y(i-1),Y(i-1)))+Y(i-1)
Y(i)=LN(MLP(Y(i-1)′))+Y′(i-1)
(6)
式中,LN为层归一化(layer normalization)。Y(i)表示第i个编码器的输出。多头注意力的3个输入矩阵都是Y(i-1),输出是自注意力后结果。通过自注意力机制,每个编码器非线性地输出全局感受特征。多个编码器串联使用,能使网络获得不同层次的特征,低层次特征包含的信息更多,而高层次特征的语义性更强。最后6个编码器输出高阶的上下文特征。
图2显示了编码器中具体的计算过程,输入序列首先经过多头的自注意力模块,然后使用残差,层归一化(layer normalization,LN)得到中间输出Y′(i-1),最后送入多层感知机(multiple layer perceptron,MLP)中,继续采用残差,层归一化,得到输出Y(i)。残差和层归一化能避免梯度消失,以加速网络的收敛。
交叉注意力模块是整个Transformer模块的核心。它将Transformer编码器的高阶上下文特征与卷积出来的深层抽象特征送入交叉注意机制。计算如式(7),过程见图2。
(7)
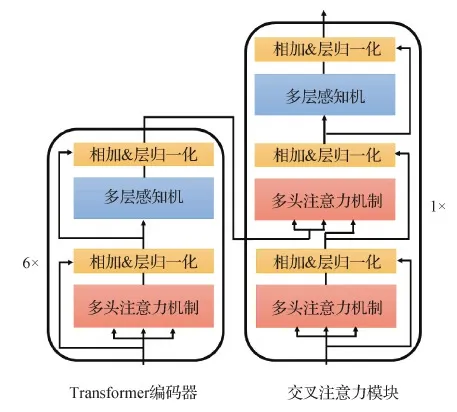
图2 Transformer模块的网络结构Fig.2 The architecture of Transformer module
式中,Y′(0)是深层特征序列添加预测头和位置编码后的结果。在交叉注意力模块中,先使用自注意力处理深层特征序列,再将处理结果与高阶的上下文特征进行交叉注意力,最后送入多层感知机。这样有两个优点:一是使网络综合了ResNet34提取的局部特征与Transformer编码的全局特征;二是使网络综合了深层抽象特征与自注意力编码后的浅层高级特征。
Transformer模块的输出结果为
Z=[zpred,z1,z2,…,zN]
(8)
式中,输出的预测头zpred用于分类任务。剩余向量序列[z1,z2,…,zN]经过拼接用于分割任务。[z1,z2,…,zN]拼接后的维度是196×512,重组后,特征图的维度为14×14×512。
2.4 分割解码模块
在医学影像分割的编码器—解码器架构中,典型的解码器主要采用两种方法来还原图像尺寸:上采样和逆卷积。上采样通过线性插值的方式来改变特征图尺寸,而逆卷积使用卷积映射自适应地增大特征图。本文中,网络的分割解码器使用逆卷积操作来恢复图像尺寸。为了保证解码特征图与相应的编码特征图尺寸相同,分割解码器依次由1×1的卷积、滑动步数为2的3×3的逆卷积和1×1的卷积3部分构成,见图1。3×3的逆卷积扩大特征图的尺寸为原来的一倍。1×1的卷积可以有效地控制输入输出的特征图通道数,尽可能减少语义信息的丢失。最后,使用跳跃连接将编码特征图对应地加到尺寸相当的解码特征图,使网络具有较大的反向梯度,以使网络尽快收敛。
3 联合训练的混合损失
3.1 分类任务损失
分类任务的损失函数fcls由对比损失fA(cont-rastive loss)(He等,2021)和交叉熵损失fB两部分构成,表达如下
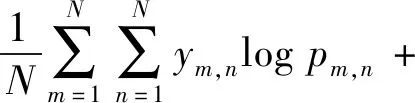
(9)
式中,sim函数表示计算zi,zj两个向量的余弦相似度,zi,zj对应着Transformer模块输出的预测头,即zpred。α表示截断值,设置为0.4。对比损失函数可以减小不同类别预测头的相似度,增加同一类别的预测头的相似度。最后对每个预测头使用全连接,分类结果向量送入交叉熵损失函数。
3.2 分割损失与联合训练损失
CXR分割任务的目标是将新冠肺炎的病灶区域标注为前景色,其他部分划分为背景色。它是一种像素级别的二分类任务,最常用的损失函数是二分类的交叉熵损失(binary cross entropy loss),表达为
fseg=-wi[yilogxi+(1-yi)log(1-xi)]
(10)
最后,模型使用不确定性损失动态平衡分类与分割任务(Zhang等,2021),表达为
(11)
式中,w1和w2是可学习参数,初始值分别设置为-4.85和-6.55。
4 数据集与实验参数
4.1 数据集的构建
本文编译了一个CXR 5分类的数据集。所有新冠患者的CXR都标注了感染区的分割掩膜。所有数据来自于6个Kaggle公开集,它们收集自GitHub、Kaggle的其他存储集、SIRM(Italian Society of Medical and Interventional Radiology)、NIH(National Library of Medicine)、国外大学(Qatar University, Tampere University, the University of Dhaka)和医疗机构(Hamad Medical Corporation)等的公开数据。每个存储集中CXR的类别与数量显示在表1。
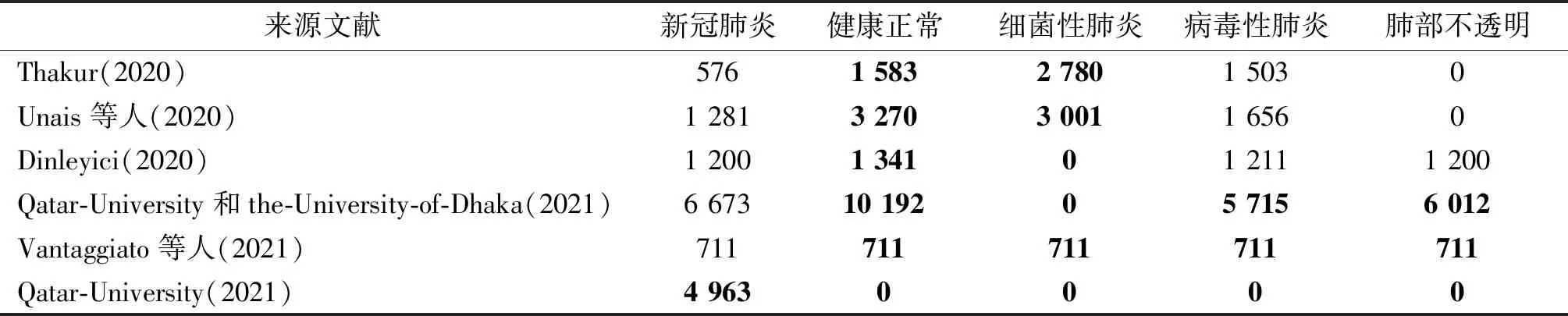
表1 各公开数据集的CXR分类统计Table 1 The statistics of classified CXRs in each repository /幅
表1中前5个存储集都没有新冠肺炎感染区的分割掩膜,所以引入第6个存储集QaTa-COVID19。各类别CXR总数之间相互比较,健康正常类明显高于其他类,细菌性肺炎明显低于病毒性肺炎类和肺部不透明类。为模拟真实的检测情景(绝大多数案例为健康正常),保留了所有存储集的健康正常CXR。但为保持数据平衡,病毒性肺炎类和肺部不透明类的CXR仅从表中第4(Degerli等,2021)和第5(Rahman等,2021)存储集中收集。最后使用的数据集由表1中各加粗项组成,删除重复图像,并将每幅图像尺寸调整为448×448 像素。编译好的数据集总共有38 466幅CXR,其中有2 951幅新冠肺炎患者的CXR,16 964幅健康正常人的CXR,6 103幅细菌性肺炎患者的CXR,5 725幅病毒性肺炎患者的CXR和6 723幅肺部不透明的CXR。
各病症的CXR通常表现介绍如下:
1)新冠肺炎。磨玻璃样(ground-glass opacity,GGO)改变,通常出现在双侧、外围;随着疾病的进展,有时会出现铺路石征(小叶间隔增厚和小叶内线与磨玻璃影叠加,称之为铺路石征);GGO区域出现血管扩张或牵拉性支气管扩张。
2)病毒性肺炎。检查可见肺纹理增多,可能出现网状影;多表现出斑片状或结块状的实变影;伴有广泛的GGO;会产生支气管壁增厚等症状。
3)细菌性肺炎。支气管肺炎型改变;多会出现肺叶实变、空洞形成或较大量胸腔积液;炎性浸润阴影,可呈大片絮状、浓淡不均匀。
4)肺部不透明。CXR影像上出现部分肺缺失。
其实,实际临床中细菌性和病毒性肺炎大类下又有复杂多样的细分,它们的CXR亦有一定差异。图3中展示了各类具有代表性的案例。
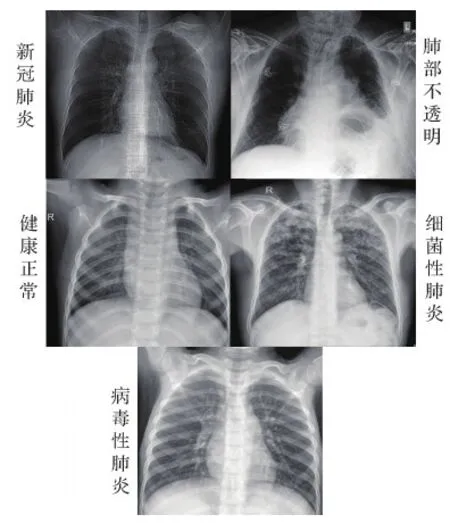
图3 各类X光片的例子展示Fig.3 The examples of different X-ray images
4.2 实验参数设置
实验硬件环境为搭载Intel Xeon CPU E5-2650 v4,2.2 GHz处理器和Tesla K80,12 GB显卡的服务器集群。软件环境为64位Centos7操作系统下的Pytorch深度学习框架。
各网络通过4张K80显卡并行训练。网络参数设置如下:批处理大小由模型大小和显卡容量人为确定,VITNet采用16;总的迭代次数为200;使用Adam优化器;学习率的初始值为0.000 2,若模型迭代10步后没有更新权重,缩小学习率为原来的一半。
5 实验结果与讨论
5.1 CXR自动诊断结果比较
在分类诊断实验中,将VITNet与通用的Transformer分类网络(Dosovitskiy等,2021)和5种流行的深度学习模型进行对比,即ResNet18,ResNet50,VGG16,Inception_v3和Dla(deep layer aggregation),结果展示在表2。ResNet18,ResNet50,VGG16,Inception_3都是经过预训练的分类模型;Dla是一种多特征融合的深度网络,不使用预训练(与VITNet一样)。就诊断的精度而言,VITNet模型具有最高的分类精度(95.37%),而后依次是Inception_v3(95.17%),Dla(94.40%),VGG16(94.16%),以及ResNet50和ResNet18(93.48%和92.18%)。单纯Transformer分类的精度是92.22%,仅优于ResNet18。召回率描述了模型准确识别出不同类别为正例的能力,召回率越高,模型对于X线胸片的误诊率越低。总体上,通用Transformer的误诊可能性最大,除此之外,其他各模型的召回率顺序与其精度顺序一致。F1指标综合考虑了精度与召回率,其结果更能反映模型准确性。可以看出,所有模型在F1上的表现顺序与召回率的顺序完全一致。kappa系数是统计学中评估一致性的方法,也可用来评估多分类模型的准确度。显然,表2中各模型在精度和kappa上有相同的性能排列。综上,VITNet在精度、召回率、F1和kappa系数上都表现最好,具有最佳的诊断效果。
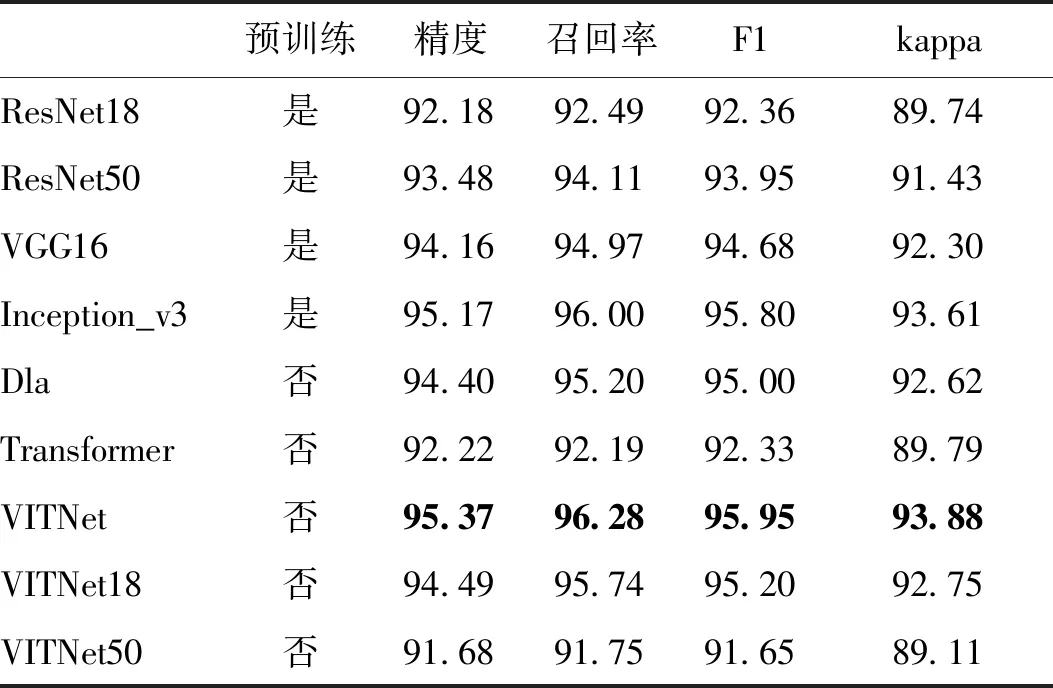
表2 各网络的分类性能对比Table 2 The comparison of classification accuracy /%
图4中绘制了各模型分类结果的混淆矩阵(由于ResNet网络已有ResNet50作为对比,未绘制ResNet18的结果)。依次单独分析5个类别的结果,就新冠肺炎而言,VGG16和Inception_v3表现最佳,然后是VITNet和Dla;就肺部不透明和病毒性肺炎的分类效果,VITNet表现出了最佳的效果;而就健康正常类而言,单纯的Transformer分类网络表现最佳;就细菌性肺炎的分类结果,本文模型仅次于Inception_v3模型。
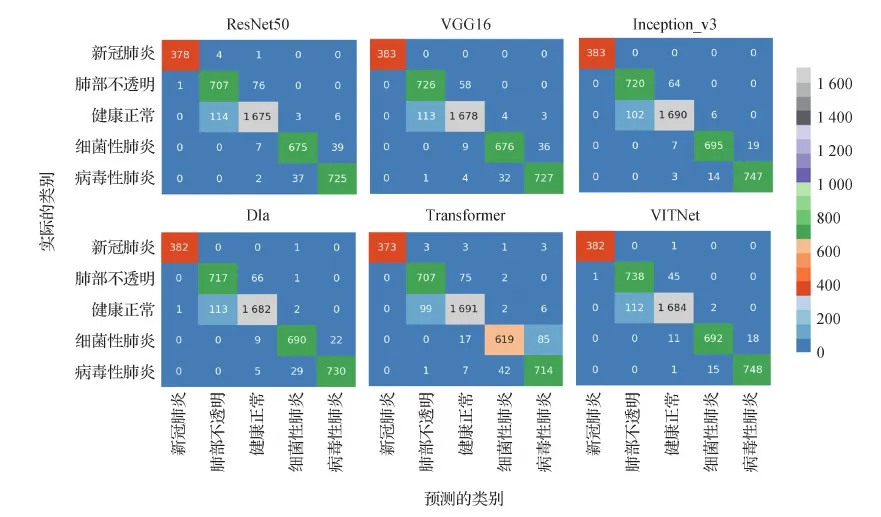
图4 各网络分类结果的混淆矩阵Fig.4 Confusion matrixe maps of network classification results
5.2 新冠肺炎感染区域的分割结果
为了验证分割效果,本文网络与4种主流网络进行对比,结果如表3所示。PSPNet(pyramid scene parsing network)是通用的语义分割模型,它的分割效果在所有网络中最差。U-Net、U-Net+、CE-Net是面向医学影像的专用网络,模型中都引入了跳跃连接,网络可以将浅层特征与抽象特征结合起来,有效提升网络的收敛速度与分割效果。相比这4种分割网络,VITNet在精度和AUC(area under ROC curve)上都具有更好的表现,但在敏感度上稍逊色于U-Net+。这可能还要涉及到网络的稳定性,测试发现,U-Net+敏感度指标随着迭代的波动非常大,相邻两次保存权重的网络敏感度可能会相差6%左右。在分割任务中,敏感度是衡量网络正确预测病灶区的能力,特异度则用于衡量正确预测无病变正常区域的能力。同一个分割网络很难兼具好的敏感性和特异性,就像表3中特异度最好的前两名网络,敏感度表达反而最差。VITNet的特异性表现相对较差,仅优于CE-Net。Dice系数是表达分割的预测与真实结果之间相似性的指标,表3中VITNet具有最高的指标数值,即表现出的相似性最好。通过各指标的比较,VITNet的分割效果最好。
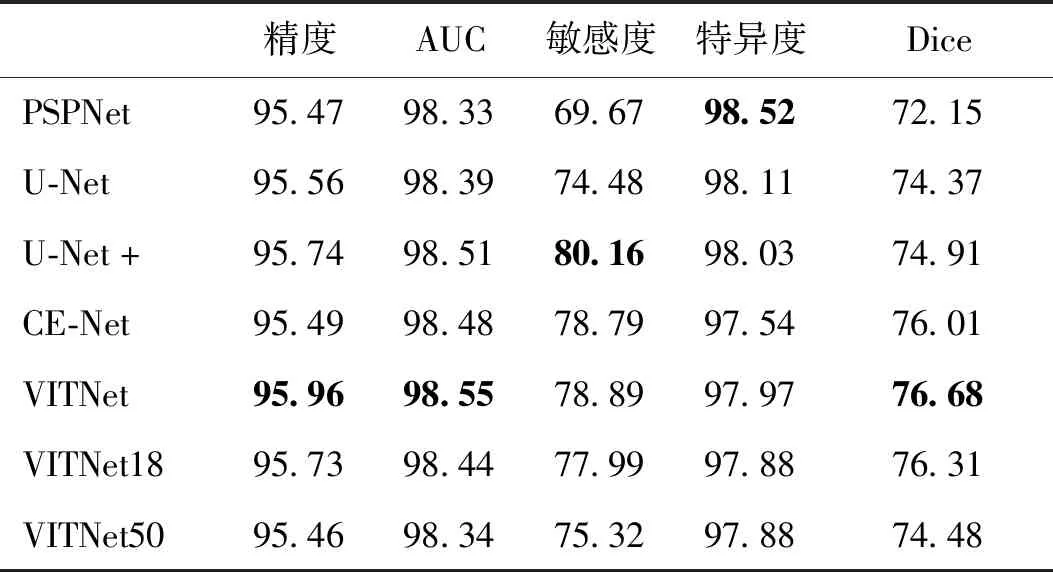
表3 各网络的分割效果对比Table 3 The comparison of segmentation performance /%
图5显示了6幅新冠肺炎感染的CXR影像及它们的分割结果。相比之下,VITNet具有更好的分割表现,这一点通过各分割预测结果的边缘与真实标签边缘的相似性可以明显看出。特别地,当病灶区域相对较小时,VITNet的分割性能愈发突出。
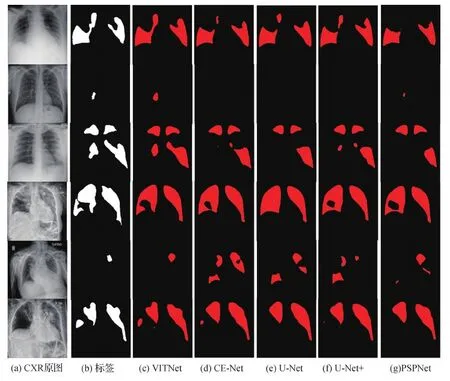
图5 不同分割网络的分割案例结果展示Fig.5 Illustrative examples of the lung infected region segmentation obtained by different networks((a) original CXR; (b) ground truth; (c) VITNet; (d) CE-Net; (e) U-Net; (f) U-Net+; (g) PSPNet)
5.3 Backbone的消融实验
VITNet的Backbone使用的是ResNet。原因如下:1)ResNet使用的残差网络能有效避免梯度消失,加速网络收敛。2)ResNet的网络结构符合嵌入特征的维数需要。由于Transformer模块中的输入序列必须是同维向量,双路嵌入层中2维卷积核的数量必须与Backbone提取的特征图的通道数一致。之前的实验表明,当输入图像尺寸固定为448×448像素,这个维数设置为512时,网络性能最突出,而Inception、DenseNet和VGG等网络提取的特征图维数大都为1 024或2 048,维数过高。若直接使用这些网络作为Backbone,将使得整个网络冗余且难收敛;若更改这些网络结构使输出降维就无法导入开发者预训练好的权重。3)ResNet的网络结构层次明确,可以有效地与解码器构成U形分割网络架构。Backbone编码的中间特征图与解码输出的中间特征图有相同的尺寸,可直接进行跳跃连接。
表2和表3对比了3种ResNet网络作为Backbone的实验结果,即VITNet18、VITNet和VITNet50分别使用了ResNet18、ResNet34和ResNet50作为Backbone。很明显,使用ResNet34的VITNet诊断与分割的性能最佳,然后是VITNet18,最后是VITNet50。ResNet18作为Backbone的效果不及ResNet34,是因为ResNet34网络结构更复杂,能够提取到更深层次的特征。VITNet50的性能最差,是因为ResNet50的网络结构得到了更改,以使输出的特征图维度等于512,因此作为Backbone的ResNet50不能使用预训练好的权重,结果自然相对较差。
5.4 联合网络性能的分析
通过以上图表可以看出,VITNet分别与主流的CNN分类或分割网络进行比较,结果显示VITNet具有优异的联合诊断与分割性能。单就诊断性能而言,VITNet相比其他网络具有最好的分类效果,网络结构中使用了交叉注意力,能同时考虑Backbone提取的深层特征信息与Transformer自注意力编码后的浅层高级上下文信息。而其他网络的分类特征相对单一,ResNet18,ResNet50,VGG16和Inception_v3网络通过多层卷积提取高维深层特征来完成分类任务;Dla则将多级特征聚合以完成分类,在未使用预训练的情况下,预测结果超过了VGG16和Res-Net网络,但仍比VITNet差。再者在损失函数上,VITNet不仅进行交叉熵的分类损失计算,还将预测头向量送入分类对比损失,以使特征空间中的同类别预测头尽可能接近(相似),不同类别的预测头尽可能远离,而在其他网络中,全连接分类的结果则直接通过交叉熵损失进行分类预测。单论新冠感染区的肺部分割,VITNet在精度上表现最好,因为它摒弃了U-Net和U-Net+编码器中的连续下采样,使用CE-Net中的编码器(ResNet34的前4层),以更完整地保持图像的语义信息。并且VITNet中引入了注意力机制,通过自注意力机制关注全局特征,通过交叉注意力综合考虑深层抽象特征与浅层高级特征,而CE-Net网络更多地关注了局部抽象特征。通过图5发现,当肺炎的感染偏小时,VITNet的分割效果更好,很少出现检测不到分割区域的情况。这可能是由于网络是同时进行分类和分割任务的,当分类任务诊断出新冠感染时,网络也能同时学习到需要进行必要的分割输出。
联合网络对每幅图像进行肺炎诊断与感染区域分割,而其他网络只能处理一种任务。图6显示了联合网络与其他分类分割网络组合运行的时间对比结果,数字标签显示了各网络处理每幅图像的时间,并且分类和分割网络分别表示为无阴影和实阴影柱状图,VITNet网络是图6中最后一个柱状图。从图6可以看出,诊断分类网络花费的时间极少,分割由于本身任务相对复杂需要较多的时间,联合网络仅与分割网络相比,就已经显示出了最快的分割速度,处理每幅图像的耗时是0.56 s。VITNet运行效率最高,因为网络使用了多头注意力模块,相比其他网络通过大量卷积操作提取图像特征,VITNet通过空间换取时间的思想平行地编码图像全局特征,减少了运行时间。
虽然联合网络具有最优的性能,但是就实际应用而言,VITNet仍然存在不足。观察图4中VITNet的混淆矩阵,可以发现有一个新冠感染者被错误地诊断为健康正常,这种错分类的案例在现实中可能会产生无法估量的伤害,鉴于新冠肺炎极强的传染性,而基于深度模型的预测出现这种错分类的情况很难避免,VGG16和Inception_v3虽然表现出100%的新冠肺炎分类精度,但是如果继续增加测试数据,很大可能也会出现错分类的案例。虽然传统的核酸检测也可能存在假阴性的情况,但在大规模应用上,核酸检测相对要更加严谨。尽管如此,考虑到核酸检测结果的时间滞后性,本文提出的联合诊断与分割网络可以作为核酸测试前的辅助测试,配合医生诊断以快速筛查人群。
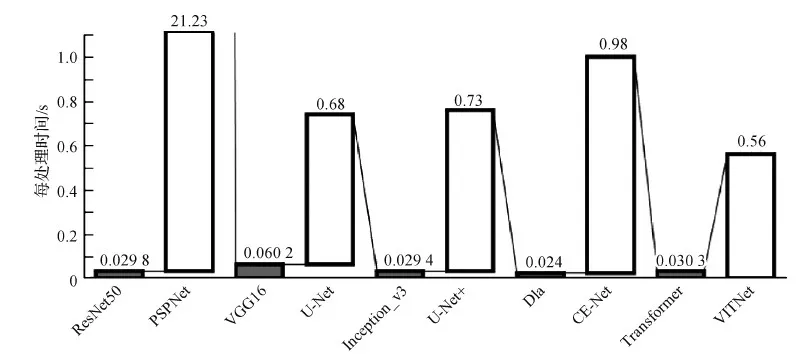
图6 VITNet网络与其他网络组合的运行效率对比Fig.6 The efficiency comparison between VITNet and other networks
6 结 论
本文提出了一种基于Transformer的联合学习网络,能够同时完成对X线胸片的诊断分类和新冠感染区分割。为实现自动诊断分类任务,网络通过自注意力编码和ResNet34前4层获取肺部图像的浅层高级特征和深层抽象特征,并经由交叉注意力模块输出用于分类的预测头;就肺部感染区分割任务,网络使用了U型编码器—解码器架构,编码器依托诊断分类的网络,解码器主要是通过逆卷积实现。为实现两种任务的联合训练,使用了一种分类和分割损失混合函数,它能在训练时动态地平衡两种任务的训练尺度。实验中,将联合网络同时输出的分类与分割结果,分别与主流的分类或分割网络的输出比较,联合网络都能有一定程度的提升,并且网络具有突出的运行效率。但从分类输出的混淆矩阵可以看出,网络有一次错误地将新冠肺炎患者诊断为正常,使得这个网络不适用于大规模的精细筛查诊断,可能更适合粗略的初步筛查和配合医生诊断。也因此认识到一种高精度的分类算法对新冠肺炎的诊断和筛查至关重要,这也是未来自动诊断的重点研究方向。
