类别敏感的全局时序关联视频动作检测
2022-12-21王东祺赵旭
王东祺,赵旭
上海交通大学自动化系,上海 200240
0 引 言
摄像头和智能手机的大规模普及以及移动互联网的迅猛发展,为视频数据的获取和传播带来了巨大便利,视频数据量呈现爆发式增长。记录着人类活动的海量视频数据中携带了大量对人类社会交互极为重要的信息,通过算法理解视频中的人体动作具有重要研究价值,是计算机视觉领域的前沿课题。视频动作检测任务要求在一段未裁剪的长视频中标注出动作发生的片段,同时完成动作类别的判断。该研究在智能监控、医学诊疗、人机交互和无人驾驶等领域具有广阔的应用前景。受到图像目标检测中两阶段方法的启发,现有的视频动作检测模型分为两个阶段:第1阶段从视频中提取出候选动作片段;第2阶段对候选片段包含的动作进行分类。
视频动作检测的精度依赖于两个关键环节:1)识别动作模式;2)探索视频内部不同片段间的时序关联。近年来许多研究者在这两方面开展了大量工作,取得了显著进展:Wang等人(2019)和Lin等人(2018)提出通过识别动作的开始模式和结束模式来定位视频中的动作边界,进而连接边界点生成候选动作片段;Lin等人(2019)和Qing等人(2021)的工作则表明边界之间的动作模式对候选片段置信度的预测起到重要作用,因此可以通过识别分析动作模式,评估某一视频片段包含动作的可能性,该片段的动作模式越明显,则其置信度越高。其次,考虑到视频是一种在时间维度上紧密关联的信息载体,研究表明视频内部的时序关联对于检测精度至关重要:Zhao等人(2017a)的工作证实了局部相邻片段间信息关联的重要性,Zeng等人(2019)和Xu等人(2020)使用图模型和图卷积(Kipf和Welling,2016)来探索相距较远的视频片段之间的关联,并取得了一定成效。在不同视频片段之间建立全局时序关联可以为模型提供更大的感受野,有助于捕获动作片段的上下文信息以及理解不同片段之间的语义关联,从而提升检测精度。
然而,现行方法在上述两项关键技术中均存在不足。1)在动作模式识别方面,几乎所有的方法都试图让模型不加区分地检测所有类别的动作,这意味着,模型必须归纳出一种普适于所有动作类型的边界模式和动作模式。这一思路具有明显的局限性,因为不同类别的动作具有截然不同的动作模式,强制模型去学习一种放之四海而皆准的动作模式加大了训练难度,因此限制了检测精度。如图1(a)所示,“绘画”归属于“室内装饰”类别,而跳远则归属于“体育运动”类别,它们在场景、动作幅度和动作频率上截然不同;而同样属于“体育运动”类别的“掷标枪”动作则与“跳远”有相似之处,例如二者都发生在体育场中,都是幅度较大、频率较快的动作,而且都以“跑动”作为动作的开始。因此本文提出,对于差异较小的类别可以用统一的方法进行处理,而对于差异较大的类别应该进行针对性、区分性的检测。目前的动作检测方法往往都忽略了不同动作间的差异,以Lin等人(2019)提出的边界匹配网络(boundary matching network,BMN)为例,图2是该模型对动作起点检测的可视化结果,图中横轴为时间轴,纵轴代表视频中某一时刻为动作开始点的预测概率,红色实线为真实的动作开始点,绿色虚线为BMN的边界预测结果。图2表明,BMN在寻找动作起点时存在误检(如11 s-33 s区间内)和漏检(如11 s和44 s附近的动作真实边界并未检出)。2)在视频时序关联方面,不论是传统卷积操作还是改进后的膨胀卷积操作,都只能建立局部关联,感受野较小。然而,很多动作的边界十分模糊,仅凭借局部特征难以区分动作和非动作,例如图1(b)的高尔夫挥杆动作,在动作发生前的一段时间内,画面内容十分相似,如果模型的感受野仅限于局部,那么很难确定究竟哪一片段才是动作的起点,但如果扩大模型的感受野,允许模型获取过去和未来的信息,将有助于模型理解视频内部信息关联,从而更好地定位动作边界。为了建立全局时序关联,Xu等人(2020)使用图模型和图卷积神经网络构建视频内部的时序关联,提出了用于时序动作检测的子图定位模型(sub-graph localization for temporal action detection, GTAD),Bai等人(2020)同样使用图模型构建时序关联,提出了边界内容图神经网络(boundary-content graph neural network,BCGNN)。尽管克服了传统卷积操作的局限性,但图模型和图卷积计算量较大,仍然存在改进空间。

图1 时序动作检测(TAD)中的关键问题Fig.1 Key points of TAD((a) different action classes have huge pattern difference; (b) global temporal relations benefit the boun-dary localization)
本文提出了类别敏感的全局时序关联动作检测模型,以解决上述问题并提升动作检测的精度。首先,考虑到不同类别之间边界模式和动作模式差异巨大,为此设计了动作逐类检测机制,该机制包含了若干个动作分支和一个通用分支。每个动作分支专门负责一类动作的检测;通用分支则为动作分支提供互补信息以实现更加准确的检测。对于输入视频,首先进行视频级别的动作粗略分类,动作分类结果会激活逐类检测机制中的对应动作分支和通用分支,二者融合后作为最后的输出结果。图2中的蓝色实线是配备逐类检测机制的模型的边界检测结果,可以看到该模型有效减少了漏检和误检现象,提升了边界的检测精度。此外,为了在视频内部不同片段之间建立全局时序关联,设计了一个三元时序模块来进行时序建模。该模块以Cho等人(2014)提出的门控循环单元(gate recurrent unit,GRU)和1维卷积神经网络(convolutional neural network, CNN)为核心组件,通过灵活调节视频特征的输入顺序,借助GRU的“选择记忆”特性实现了不同视频片段之间的信息聚合,从而建立了全局时序关联。与采用图模型进行时序建模的GTAD (Xu等,2020)相比,三元时序模块在取得性能提升的同时,计算复杂度降低了46%左右。
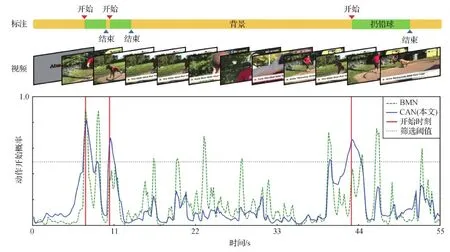
图2 传统模型与逐类检测模型的动作边界检测能力对比Fig.2 Traditional model v.s. class-aware model on action boundary detection
本文的贡献主要包括以下几点:
1) 考虑到不同类别的动作具有截然不同的边界模式和动作模式,提出对于差异较大的类别应该进行针对性、区分性处理,因此设计了视频动作逐类检测机制以解决该问题;
2) 为了建立视频内部片段之间的全局关联,灵活应用门控循环单元设计了一个三元时序模块,与GTAD中采用的图模型相比,减少了大约46%的计算量,同时提升了检测性能;
3) 上述逐类检测机制和三元时序模块整合为类别敏感的全局时序关联动作检测模型,并使用多种特征提取器在两个公开数据集上进行实验,验证了本文方法的有效性。在THUMOS-14数据集(Idrees等,2017)中,使用时序分段模型(temporal segment network,TSN)(Xiong等,2016)作为特征提取器时,该方法的平均mAP(mean average precision)为54.90%,较主流方法提升了约3%,达到了目前的最佳水准。在ActivityNet-1.3数据集(Heilbron等,2015)中,使用TSN作为特征提取器时,该方法的平均mAP为35.58%,与其基准模型BMN(Lin等,2019)相比提升了大约2%,同时也优于目前最佳性能(Qing等,2021)。使用膨胀3维卷积特征(inflated 3D convolutional network,I3D)(Carreira和Zisserman,2017)和时序敏感预训练特征(temporally-sensitive pretraining,TSP)(Alwassel等,2021)时,平均mAP可以分别达到36.23%和37.32%。
1 本文方法
1.1 方法概述
为提升视频动作检测精度,本文提出了类别敏感的全局时序关联动作检测模型(class-aware network with global temporal relations,CAN), 该方法的整体流程如图3所示,其主要模块包括视频动作分类器、视频特征提取器、三元时序模块(ternary basenet,TB)和动作逐类检测机制(class-aware mechanism,CAM)。这些模块将在后文中详细介绍。
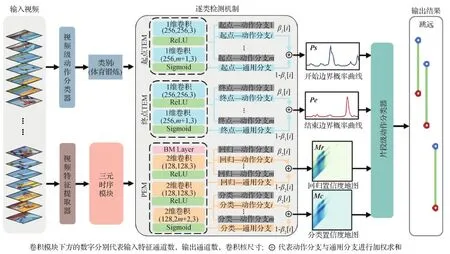
图3 类别敏感的全局时序关联视频动作检测模型Fig.3 Overview of class-aware network with global temporal relations
CAN的输入是未裁剪的视频数据,输出是具有类别信息的视频动作片段。首先,原始的视频数据被同时送往视频级别的粗分类器和视频特征提取器,粗分类器产生一个粗略的视频级动作标签,特征提取器则从视频数据中提取包含动作信息和表观信息的特征序列。接下来,三元时序模块TB对视频特征序列进行处理并建立全局时序关联,然后具备时序关联的视频特征和视频级动作标签被送入逐类检测机制CAM中。在CAM内部,与类别标签对应的动作分支以及通用分支会被激活,二者融合后输出候选动作片段(action proposals)。最终,一个片段级别的分类器为每一个候选动作片段进行精细分类,得到最终的输出结果。
1.2 特征提取器与动作分类器
特征提取器用于从原始视频中提取包含动作信息和表观信息的特征序列作为视频的特征表示。在视频动作检测任务中,大多数模型(见表1)均采用了基于双流架构的TSN模型和I3D模型作为特征提取器,为了保证性能对比的公平性,本文遵循了这一范式。另外,使用了2021年提出的TSP特征提取器来验证本文方法的有效性。1)使用在Kinetics数据集(Kay等,2017)上预训练、在ActivityNet-1.3上精调的TSN模型(Xiong等,2016)作为特征提取器,特征维度为400,该特征记为“TS”。同时,在THUMOS-14上还使用了由GTAD提供的、仅在Kinetics上预训练的TSN模型提取的特征,特征维度为2 048,该特征记为“TS*”。2)使用在Kinetics数据集上预训练的I3D模型(Carreira和Zisserman,2017)提取视频特征,维度为2 048,该特征记为“I3D”。3)使用在ActivityNet-1.3上预训练的TSP模型(Alwassel等,2021)进行特征提取,维度为512,该特征记为“TSP”。
具体的特征提取方式如下:将视频解帧后,每隔σ帧抽取一帧RGB图像,与以该帧为中心的堆积光流图像组成一个片段(snippet),送入特征提取器得到对应的特征向量。设视频帧数为L,特征向量的维度为C,则最终得到视频特征序列Fv∈RC×T,其中T=L/σ为特征序列长度。对于ActivityNet-1.3数据集,σ设置为16,并采用线性插值的方法将特征序列的长度调整为100;对于THUMOS-14数据集,σ设置为5,并使用长度128、重叠率50%的窗口将原始视频特征序列截取为若干窗口,对每个窗口分别进行检测,在后处理过程中对每个窗口的输出结果进行拼接,作为最终的检测结果。
动作分类器负责对视频中的动作进行分类。CAN中包含一个视频级动作分类器和一个片段级动作分类器。视频级分类器输入完整视频并对视频整体进行粗粒度分类(例如分类为“体育运动”),该分类器对应类别数为m,片段级分类器输入的是候选动作片段并进行细粒度的分类(例如分类为“扔铅球”),对应类别数为n,其中m≤n。以ActivityNet-1.3数据集为例,根据标注信息中的层级类别结构以及2.4.2节中的消融实验结果,m设置为14,n设置为200。在THUMOS-14数据集中,未裁剪视频分类模型Untrimmed Net(Wang等,2017)是绝大多数两阶段动作检测方法广泛采用的动作分类器,Zhao等人(2017b)提出的动作分类器则在ActivityNet-1.3数据集中作为基准。这两种分类器在视频时序动作检测领域内得到广泛采用,包括BMN、GTAD、BCGNN以及时序尺度不变模型(temporal scale invariant network,TSI)(Liu等,2020)、时序上下文积聚网络(temporal context aggregation network,TCA-Net)(Qing等,2021)等。为与大部分两阶段的视频动作检测模型公平比较,仍采用Untrimmed Net和Zhao等(2017b)提出的模型作为动作分类器。
1.3 逐类检测机制
为了差异化地对不同类别的动作进行针对性检测以提升检测精度,设计了逐类检测机制CAM。该机制的内部结构如图3所示。逐类检测机制借鉴并改进了BMN中的模块结构,设计了具备多分支的时序评估模块(temporal evaluation module, TEM)和提名评估模块(proposal evaluation module, PEM),两类模块均配备了m个动作分支和一个通用分支。两个时序评估模块分别用于评估每个片段是动作起点和动作终点的概率,而提名评估模块用于评估视频内部每个锚框包含完整动作的概率。
起点时序评估模块(起点TEM)通过识别动作起点的边界模式,输出长度为T的起点概率序列Ps;类似地,终点时序评估模块(终点TEM)通过识别动作终点的模式,输出终点概率序列Pe。按照1.2节所述的特征提取方式,视频特征序列中每一列实际代表了原始视频中的一个小片段,因此Ps和Pe分别代表视频特征序列中每一个片段是动作开始或结束的概率。
提名评估模块PEM在视频中设置了大量密集分布的锚框,锚框的设置策略如下:对于任意时刻t1,将它与所有满足t2>t1的时刻t2关联起来,组成一个锚框(t1,t2)。PEM通过识别锚框特征的动作模式来预测其包含动作的可能性,即锚框的置信度。将所有锚框的置信度排列成为T×T的矩阵M,称为置信度地图。该地图以左上角为原点,横轴代表锚框的开始时刻,纵轴代表锚框的持续时长,例如矩阵中t1列、t2-t1行的数值M[t1,t2]就代表了锚框(t1,t2)的置信度。该矩阵中副对角线左上方代表了所有有效的锚框(t2>t1),右下方则为无效区域。使用BMN中提出的边界匹配层(boundary-matching layer,BM Layer)为每个锚框生成特征表达。具体而言,对于每个锚框,在其对应区域内均匀采样32个特征向量,然后使用卷积操作将32个特征向量融合为一个128维的特征向量,作为该锚框的特征。PEM的输出包括用分类损失训练的置信度图Mc和用回归损失训练的置信度图Mr。
本文方法的重要创新在于提出了逐类检测机制,该机制的核心是多分支结构。TEM模块包含m+1个输出通道,分别对应m个动作分支和1个通用分支。起点评估模块中,动作分支的输出是所有动作类别的起点概率序列,可记为Psa∈RM×T,通用分支的输出则记为Psu∈RT。类似地,终点评估模块可以输出Pea和Peu。另外,时序提名模块PEM包含2(m+1)个输出通道,前m+1个通道用于输出回归置信度地图Mr∈RT×T,后m+1个通道用于输出分类置信度地图Mc∈RT×T。由于每个动作分支只负责识别某一种动作类型,因此动作分支可以对特定类别进行针对性的学习和检测,避免了多种动作共用同一输出通道所引起的类内方差。与动作分支互补的是通用分支,它负责从视频中提取通用的动作模式,实现更加精准的动作模式识别。
在前向传播的过程中,对于给定输入视频,分类器预测出视频级类别标签i(1≤i≤m),TEM和PEM中第i个动作分支被激活,输出Psa[i],Pea[i],Mra[i]和Mca[i]。通用分支则输出Psu,Peu,Mru和Mcu。动作分支和通用分支的输出通过加权的方式进行融合,β1和β2分别是TEM和PEM中的融合权重向量,β1,β2∈Rm且0≤β1[i],β2[i]≤1,这代表着每个动作分支在与通用分支进行融合时均有单独的权重分量,例如对于动作类别i,它在TEM和PEM中的融合权重分别为β1[i]和β2[i]。融合权重是可训练参数,这是考虑到一部分动作的准确检测可能依赖于其独有的特征,而另一些动作的检测可能更依赖通用的动作特征,将权重参数设置为可训练意味着将最终决定权交给了模型自身,使检测更具灵活性。最终,CAM输出当前视频的起点概率序列Ps、终点概率序列Pe以及两张锚框置信度地图Mr和Mc,即
Ps=β1[i]·Psa[i]+(1-β1[i])·Psu
(1)
Pe=β1[i]·Pea[i]+(1-β1[i])·Peu
(2)
Mc=β2[i]·Mca[i]+(1-β2[i])·Mcu
(3)
Mr=β2[i]·Mra[i]+(1-β2[i])·Mru
(4)
1.4 三元时序模块
特征提取器将视频分割成片段(snippet),然后依次提取每个片段的特征,最后拼接形成视频整体特征序列。这种特征提取方式导致各片段特征之间相互独立、缺乏关联。三元时序模块用来探索并建立视频内部的全局时序关联。该模块的结构如图4所示,特征序列下方的数字代表特征序列的形状,其中C是特征提取器输出特征的维度,T是视频特征序列的长度。首先,视频特征序列经过了卷积核为3的1维卷积层,此时,特征序列中的每一列仅包含了其对应时刻附近的信息,称之为“当前特征”。接下来,当前特征按照时间顺序自前向后地送入顺时针GRU中,由于GRU具有对历史输入选择记忆的功能,因此顺时针GRU输出的特征序列中,每一个时刻的特征向量均包含了过去时刻的有价值信息,称其为“过去特征”。同时,可以沿时间轴翻转“当前特征”,按照从后向前的顺序送入逆时针GRU中,这样GRU可以“记住”未来时刻的有价值信息,此路径输出的特征称为“未来特征”。最后,过去特征、当前特征和未来特征被拼接在一起,让每一个时刻的特征都积聚了过去、当前和未来的信息,从而在视频特征内部建立起全局的时序关联。三元时序模块以一种简洁的结构为模型赋予了全局视野。2.3节中的实验结果证明了该模块的有效性。
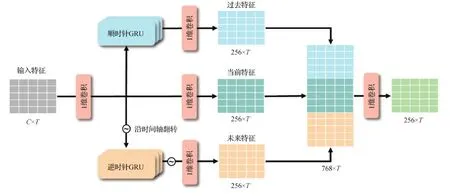
图4 三元时序模块结构Fig.4 Structure of ternary basenet
1.5 训练阶段
1.5.1 训练标签生成
逐类检测机制CAM的输出包括视频的边界概率序列Ps,Pe以及置信度地图Mr和Mc。需要为4种输出分别设置训练标签。数据集中一个真实的动作标注为φ={ts,te},其中,ts和te分别代表动作的开始和结束时刻。为了生成边界标注,将边界扩展为一段区域:设视频时长和特征长度分别为Tv和T,则开始区域为rs={ts-1.5·Tv/T,ts+1.5·Tv/T},结束区域为re={te-1.5·Tv/T,te+1.5·Tv/T}。由于特征序列中的每一列与原始视频中的一个片段(snippet)对应,因此,开始概率序列的训练标签Gs是通过计算特征序列中每一个片段与开始区域rs的重叠率确定的。同理,可以得到结束概率序列的训练标签Ge。对于置信度地图的训练,沿用BMN和TSI的做法,计算所有锚框与真实动作的时间交并比(temporal intersection over union,tIoU)作为训练标签Gm。
1.5.2 基础损失函数
TEM通过识别局部特征的边界模式来判断视频中每一时刻是否是动作起点或终点。该部分采用重加权的二分类交叉熵损失进行训练,损失函数为
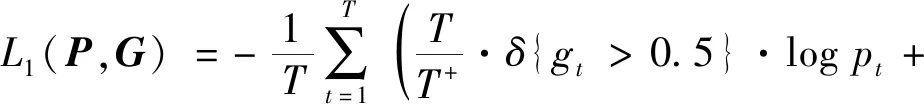
(5)
式中,视频特征序列长度为T,P是模型预测的边界概率序列,G代表真实的边界概率序列,pt和gt分别代表t时刻的预测值和真值,其中gt>0.5的时刻作为正样本,其余为负样本,即δ{gt>0.5}=1,否则为0;T+和T-分别代表正样本和负样本的数量,损失函数中的重加权系数缓解了正负样本数量不均衡的问题。
PEM通过识别锚框内部的动作模式来判断其包含完整动作的可能性。PEM的基础损失函数包括分类损失和回归损失。按照1.3节中的锚框设置策略,设锚框总数为Na,M代表所有锚框的预测置信度地图,Gm代表每个锚框与真实动作的时间交并比(即真实置信度),mj和gj分别代表第j个锚框的预测置信度和真实置信度。分类损失函数为
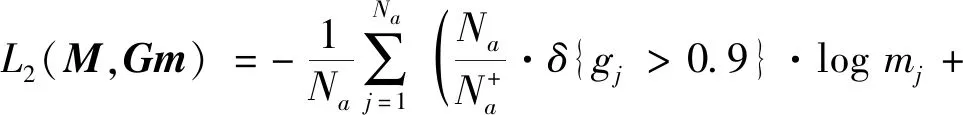
(6)
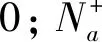
(7)
所有样本均参与训练。
1.5.3 CAM损失函数
设视频级动作类别为i,借助1.5.2节中定义的基础损失函数,动作分支损失和通用分支损失可以分别表示为
LACT=L1(Psa[i],Gs)+L1(Pea[i],Ge)+
L2(Mca[i],Gm)+L3(Mra[i],Gm)
(8)
LUNI=L1(Psu,Gs)+L1(Peu,Ge)+
L2(Mcu,Gm)+L3(Mru,Gm)
(9)
融合损失LMER是动作分支和通用分支损失的加权和,即
LMER=β1[i]·(L1(Psa[i],Gs)+
L1(Pea[i],Ge))+
(1-β1[i])·(L1(Psu,Gs)+L1(Peu,Ge))+
β2[i]·(L2(Mca[i],Gm)+L3(Mra[i],Gm))+
(1-β2[i])·(L2(Mcu,Gm)+L3(Mru,Gm))
(10)
加权方式如1.3节所述,TEM中的融合权重为β1[i],PEM中的权重为β2[i]。
1.5.4 整体损失函数
模型整体的损失函数为
L=LACT+LUNI+LMER+λ·J
(11)
式中,J代表了L2正则化项,衰减系数λ设置为10-4。总体损失中保留了动作分支损失LACT和通用分支损失LUNI,这是因为LMER中包含了可训练权重,在训练早期权重参数没有得到充分训练的情况下,LACT和LUNI的加入可以保证动作分支和通用分支的有效训练。
1.6 推理阶段
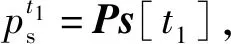
(12)
最后,采用软阈值非极大值抑制方法(soft non-maximum suppression,Soft-NMS)(Bodla等,2017)对动作片段进行后处理以去除重复预测。
2 实验结果与分析
2.1 实验设置
2.1.1 数据集简介
在两个极具挑战性的公开数据集上进行了实验。THUMOS-14(Idrees等,2017)共有413个有时序标注的视频,分为20类动作,其中验证集包含200个视频,测试集包含213个视频;ActivityNet-1.3(Heilbron等,2015)包含了19 994个时序标注视频,分为200类动作,按照2 ∶1 ∶1的比例划分了训练集、验证集和测试集,而且该数据集的标注信息中提供了动作类别的层级结构。按照本领域通用的训练与评估方法,使用THUMOS-14中200个验证集视频进行模型训练,并在213个测试集视频上进行测试;对于ActivityNet-1.3,使用训练集进行训练,并在验证集进行测试。
2.1.2 实现细节
1)特征提取器方面。为了与本领域其他方法进行公平比较,本文采用了主流视频时序动作检测模型广泛采用的TSN双流模型(Xiong等,2016)和I3D双流模型(Carreira和Zisserman,2017)作为特征提取器,此外还使用了一个较新的特征提取器TSP(Alwassel等,2021)来验证本文方法的性能。特征提取器的具体设置如1.2节所述。
2)动作分类器方面。如1.2节所述,Untrimmed Net(Wang等,2017)和Zhao等人(2017b)提出的分类器分别在THUMOS-14和ActivityNet-1.3上取得了较高的识别精度,绝大多数两阶段视频动作检测方法均使用这两种模型作为动作分类器。为与其他方法公平比较,本文沿用了这一设置,并为视频级动作分类器和片段级动作分类器设置不同的输出类别。在ActivityNet-1.3的标注信息中,动作类别分为4个层级,分别包含了5、14、53和200类动作,根据2.4.2节中消融实验的结果,选择第2层的14类作为视频级分类器的输出类别,最底层的200类作为片段级分类器的输出类别。对于THUMOS-14,两个分类器的类别均设置为20类。使用Adam优化算法进行模型训练,批量样本数(batch size)设置为16,学习率设置为10-3。训练的迭代次数设置为10。在THUMOS-14中,第5次迭代后,学习率衰减到10-4,ActivityNet-1.3中,第7次迭代后学习率衰减到10-4。
2.2 与当前主流方法的比较
在两个数据集上对CAN的检测性能进行测试,并与目前主流方法进行了比较。在THUMOS-14的测试集上,表1列出了tIoU阈值为{0.3,0.4,0.5,0.6,0.7}下的mAP以及这5个指标的平均值作为平均mAP(Avg.mAP)。在ActivityNet-1.3的验证集上,列出了tIoU阈值为{0.5,0.75,0.95}的mAP指标,另外,按照官方的评判标准,以0.05为步长、tIoU在0.5-0.95之间的10个mAP指标进行平均作为平均mAP。
除了前文提到过的BMN方法、GTAD方法、TSI方法和BCGNN方法外,用于比较的其他主流方法还包括Zeng等人(2019)提出的提名图卷积网络(proposal graph convolutional network,PGCN),熊成鑫等人(2020)提出的时域候选区域优化方法(temporal proposal optimization,TPO),林天威(2019)提出的边界敏感网络(boundary sensitive network,BSN),Su等人(2020)提出的改进的边界敏感模型BSN++,Zhao等人(2020)提出的自底向上的时序动作定位模型(bottom up temporal action localization,BUTAL),Lin等人(2020)设计的密集边界生成网络(dense boundary generator,DBG),Tan等人(2021)提出的松弛的自注意力架构动作检测网络(relaxed transformer decoder network,RTD-Net),Qin等人(2021)提出的位置敏感上下文建模网络(position-sensitive context model network,PCM-Net),Lin等人(2021)提出的基于显著特征的无锚框边界检测网络(anchor-free saliency-based detector,AFSD),以及Qing等人(2021)设计的时序上下文积聚网络(temporal context aggregation network,TCA-Net)。
表1列出了各个方法在ActivityNet-1.3数据集上的检测性能。1)当使用双流特征TS时,本文提出的CAN与其基准模型BMN相比,在mAP@0.5和mAP@0.75两个指标上提升了大约2%,而平均mAP指标则为35.58%,超越了TCA-Net和PCM-Net方法,达到了目前的最佳水平。2)当使用I3D特征时,本文方法的优势进一步显现,在mAP@0.5、mAP@0.75和平均mAP上均超越了其他现有模型,其中平均mAP为36.23%。3)使用新近提出的TSP模型作为特征提取器时,CAN全面超越了GTAD和BMN,平均mAP达到了37.32%,同时高tIoU阈值下的mAP@0.95达到了10.33%,是目前唯一超过10%的方法,说明CAN的预测结果更加可靠。表2列出了各个方法在THUMOS-14数据集上的检测性能。在TS、TS*和I3D这3种特征下,本文方法均超越了现有的其他方法,达到目前的最佳水平。
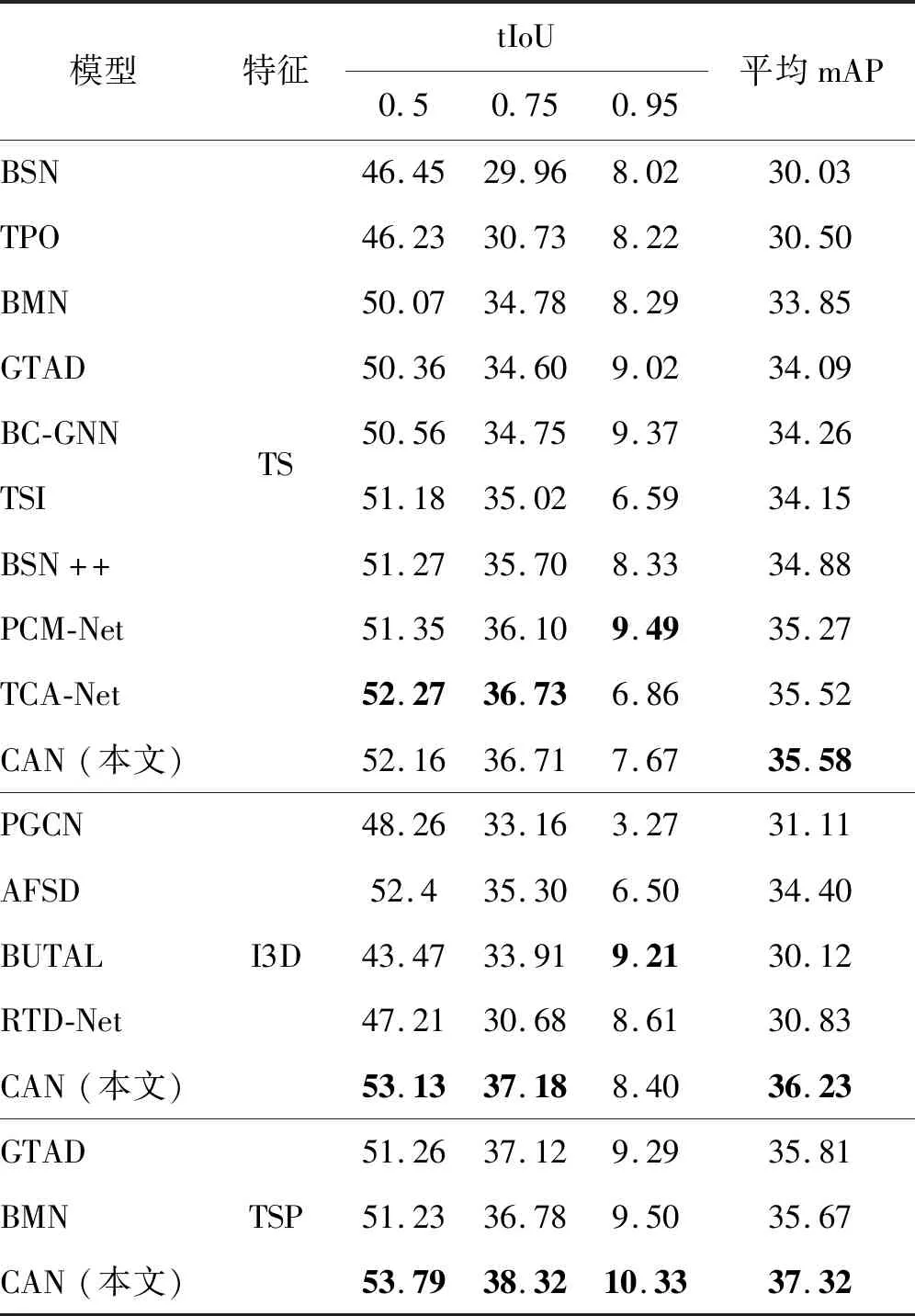
表1 不同方法在ActivityNet-1.3数据集上的动作检测性能mAPTable 1 Temporal action detection performance mAP comparison with state-of-the-art methods on ActivityNet-1.3 /%
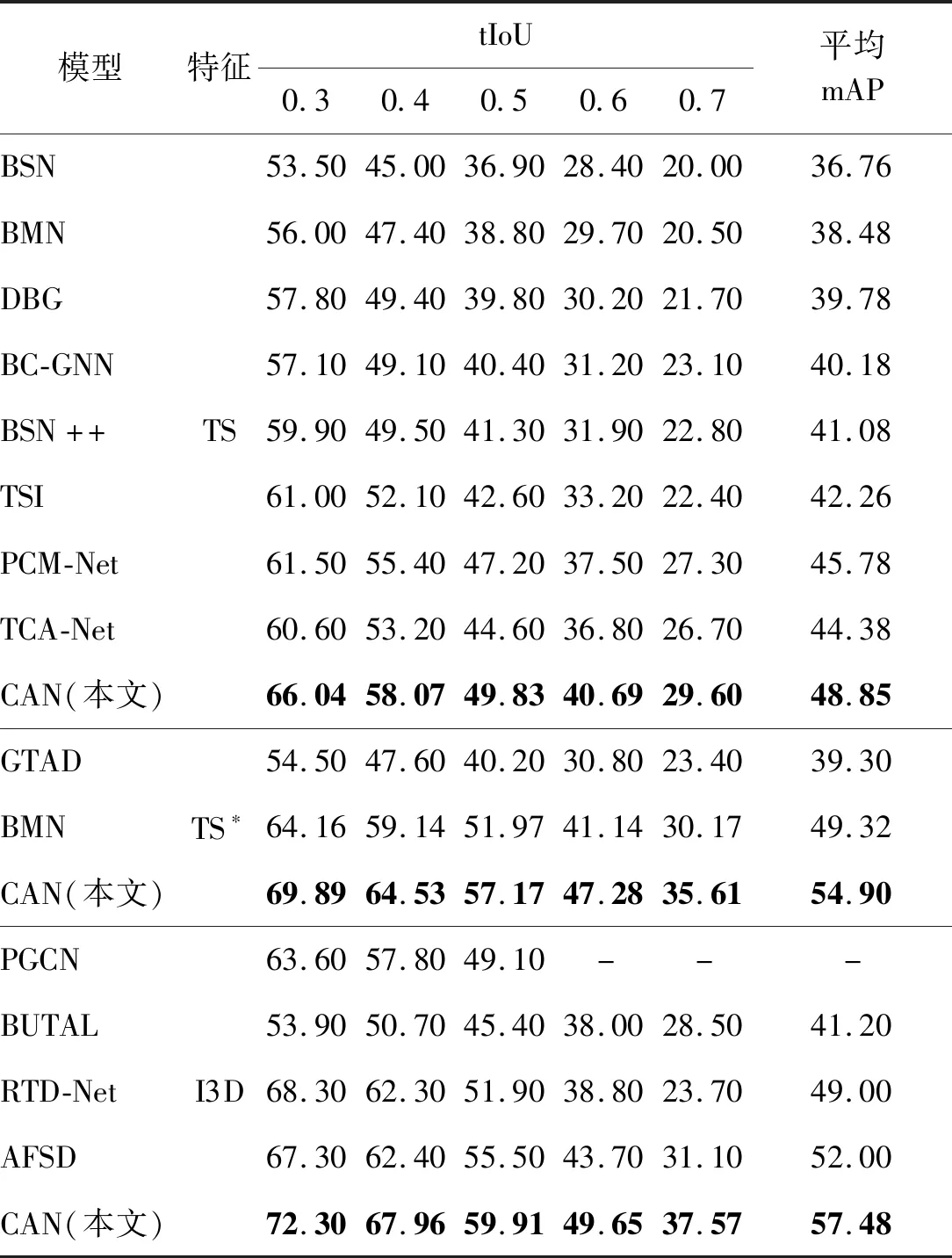
表2 不同方法在THUMOS-14数据集上的动作检测性能mAPTable 2 Temporal action detection performance mAP comparison with state-of-the-art methods on THUMOS-14 /%
本文方法在两个数据集上均取得了优异的检测性能,验证了本文思路的有效性。值得指出的是,由于ActivityNet-1.3数据集中平均mAP的计算标准更为严苛,因此该数据集的平均mAP指标显著低于THUMOS-14数据集。除此之外,其他造成两个数据集之间的性能差异的原因将在第3节详细讨论。
2.3 三元时序模块的有效性验证实验
三元时序模块(TB)用于建立视频内部的时序关联,为了充分证明该模块的作用,同时避免逐类检测机制(CAM)对模型性能的影响,本实验去除了所有的动作分支,仅保留了通用分支,然后在THUMOS-14数据集上进行实验并给出平均mAP。在视频动作检测领域,图模型和图卷积是另一种时序建模方法,该思路的代表性工作是BCGNN和GTAD。将CAN与图模型方法进行了对比实验,结果如表3所示。分别使用TS特征(与BCGNN相同)和TS*特征(与GTAD相同)在THUMOS-14上进行测试,比较CAN、BCGNN和GTAD的检测性能,并对比CAN与GTAD的参数量、计算量,其中计算量以“乘加操作数”(multiply-accumulate operations,MACs)衡量(由于BCGNN没有提供开源代码,且论文中没有给出相关数据,因此无法统计BCGNN的计算量和参数量)。在相同的输入特征下,CAN均取得了更好的性能。同时,CAN的运算量比GTAD降低了46%左右。由此说明与图模型相比,借助门控循环单元构建的三元时序模块是更加有效、计算量更小的时序建模方法。
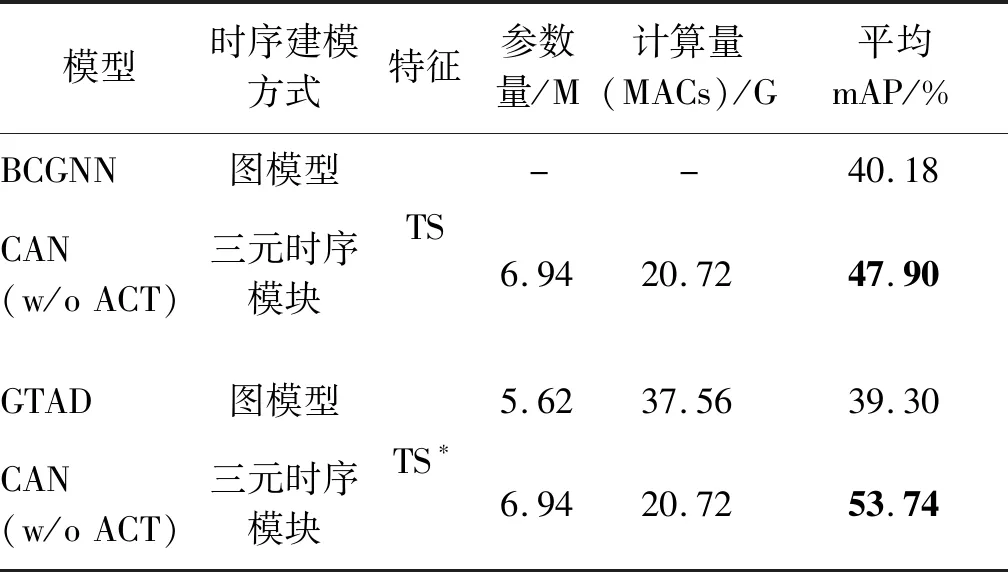
表3 CAN与BCGNN、GTAD在THUMOS-14数据集上的时序建模有效性对比Table 3 Comparison of temporal modeling effectiveness on THUMOS-14 between CAN, BCGNN and GTAD
此外,为了验证本文提出的三元时序模块的泛化性,选择TSI(Liu等,2020)和BMN(Lin等,2019)作为基准,这是因为TSI和BMN仅仅使用卷积核大小为3的1维卷积来处理时序信息,缺乏全局时序建模能力。为此,用三元时序模块来替换TSI和BMN中的前3个卷积层,使用TS特征在THUMOS-14数据集上进行实验,实验结果如表4所示。
从表4中可以发现,三元时序模块的引入为BMN和TSI带来了可观的性能提升。在THUMOS-14上,二者的mAP@0.5和平均mAP都得到了5%左右的提升。该实验表明,三元时序模块可以有效建立时序关联并增强特征的表达能力,有助于检测精度的提升,同时具备一定的泛化能力,可以用于其他视频时序动作检测模型。
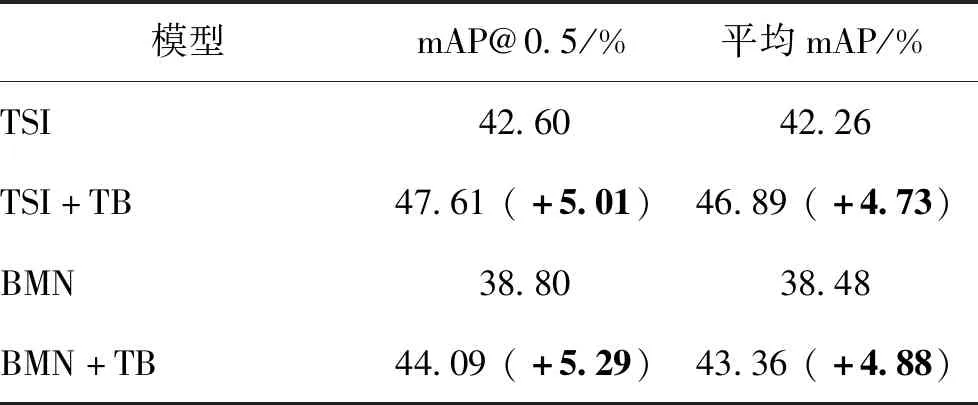
表4 三元时序模块(TB)在TSI和BMN上的泛化性能实验(THUMOS-14,使用TS特征)Table 4 Generalization of ternary basenet(TB) on TSI and BMN (THUMOS-14, using TS feature)
2.4 消融实验
为了充分证明本文方法有效性,分别就模型整体结构设计和逐类检测机制中的动作分支设置进行了消融实验。
2.4.1 整体结构的消融实验
表5展示了对CAN进行整体结构消融实验的结果,其中不同设置的含义解释如下:1)对于三元时序模块,“过去特征”、“未来特征”选项分别代表在该模块内部是否将过去特征或者未来特征拼接到当前特征上。2)对于逐类检测机制,“动作分支”和“通用分支”选项表示模型是否具备动作分支和通用分支(模型至少要有一个通用分支)。表5中最后一行则是配备了三元时序模块和逐类检测机制的完整模型CAN。使用不同的模块设置和相同的输入特征在ActivityNet-1.3和THUMOS-14两个数据集上进行对比实验(ActivityNet-1.3使用了TS特征,THUMOS-14使用了TS*特征)。表5列出了在两个数据集上的mAP@0.5和平均mAP。
对于三元时序模块而言,模型1)和5)的对比表明,单纯增加三元时序模块可以为原始的基础模型带来改进。根据表5中模型2)—4)的实验结果,在时序模块内部,拼接过去特征或者拼接未来特征均会带来一定的性能提升,而最优的选择是将过去、当前和未来3种特征拼接在一起,如模型7)的性能所示。

表5 模型整体结构消融实验的mAP结果Table 5 mAP results of ablation study on model whole structure /%
对于逐类检测机制而言,模型1)和2)的对比说明,在不使用三元时序模块的情况下,逐类检测机制本身就可以带来较为可观的性能提升。对比模型5)和6)可以发现,在增加三元时序模块后,进一步设置动作分支并对每类动作进行定制化处理可以提升检测精度。对比模型6)和7)可以发现,通用分支的增加可以进一步改善性能,从而说明通用分支可以为动作分支提供有价值的补充信息。
以上消融实验证明了三元时序模块和逐类检测机制在本文模型CAN中的重要作用,同时说明了模块内部结构设置的合理性。
2.4.2 动作分支的消融实验
逐类检测机制的设计引发了两个问题:1)将m个动作分支嵌入到原本只有单一输出通道的模型中,是否会导致模型参数量和计算量扩大m倍?2)ActivityNet-1.3的类别层级中有4层,分别有5、14、53、200类动作,应该选择哪一层作为动作分支的数目?为了回答这两个问题,进行了针对动作分支的消融实验:在ActivityNet-1.3中,改变动作分支的数目,在其他设置全部相同的情况下进行实验,计算不同模型的参数量、计算量,并比较平均mAP。实验结果如表6所示,模型名称CAN后的数字代表了动作分支的数目。
对于第1个问题,如表6所示,随着动作分支的数目从5增加到200,参数量和计算量略有增加,但始终维持在可接受的范围内。值得注意的是,即便是具有200个动作分支的CAN200模型,其计算量也只有GTAD的55%左右。这一现象的原因在于,动作分支的增减仅仅通过改变最后一层卷积的输出通道来实现,因此模型复杂度和计算量的增加并不明显。
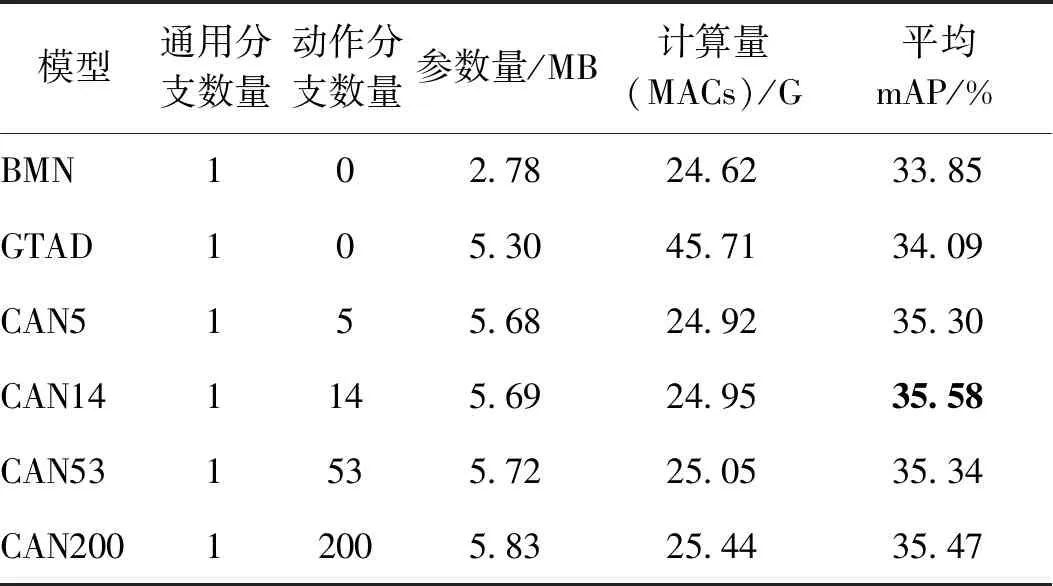
表6 动作分支数量的消融实验(ActivityNet-1.3)Table 6 Ablation study on the number of action branch (ActivityNet-1.3)
对于第2个问题,从表6中可以发现,增加动作分支的个数并不意味着总是带来更好的性能。一个可能的解释是,动作分支数目与检测精度之间存在一种制衡关系:动作分支过少,会导致每个分支内部产生较大的类内方差,因此降低了性能;动作分支过多,参与每个分支训练的有效样本个数又会显著降低,使动作分支无法得到充分训练,同样会影响检测精度。14个动作分支的设置对于ActivityNet-1.3而言是合理的。一方面,这一设置以较低的附加计算量带来了可观的性能提升;另一方面,由于视频级分类器主要进行粗略宽泛的动作分类,所以动作分支的数目不宜过多。
2.5 可视化与定性分析
选择THUMOS-14测试集中“掷铅球”和“扔链球”动作,分别使用本文模型CAN和BMN对视频进行检测,并选取置信度最高的3个预测片段进行可视化,结果如图5所示,红色区域为视频中的真实动作片段(ground truth,GT),蓝色区域和绿色区域分别为BMN和CAN的检测结果。
两种模型都实现了动作类别的准确预测,但与BMN相比,CAN可以提升动作边界检测的准确性,并且预测结果能够较好地覆盖真实动作区域。
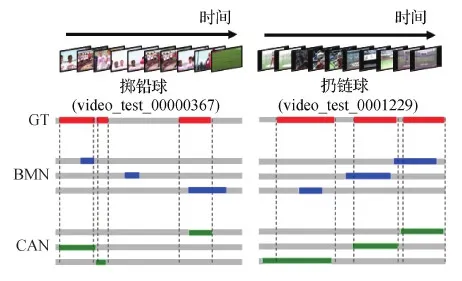
图5 CAN与BMN检测结果的定性比较Fig.5 Qualitative comparison between CAN and BMN
3 讨 论
3.1 本文方法泛化性的讨论
在应用场景方面,由于THUMOS-14数据集和ActivityNet-1.3数据集中的视频直接取自Youtube等在线视频网站,涵盖了日常生活、体育运动和影视片段等类别,并且没有进行视频去噪、画面截取等后处理,因此数据集视频与真实视频差异较小。以下主要对本文方法的泛化性进行讨论。
就三元时序模块而言,该模块的设计目的是借助GRU来增强不同视频片段特征之间的关联,根据2.3节中泛化实验的结果(表4),对于缺乏长距离时序建模能力的模型TSI和BMN,三元时序模块的引入均可带来可观的性能提升,这说明本模块具备一定的泛化能力。
对于逐类检测机制,该机制的核心设计思想在于:进行动作片段检测时应该考虑动作类别,这是因为不同类别的动作具有截然不同的特征,正如引言中图1(a)和图2所示,在类别信息的辅助下,模型可以更具针对性地检测动作片段。需要注意的是,此处的动作类别并非细粒度的,而是一个粗略的视频级别动作标签。以ActivityNet-1.3数据集为例,本文根据数据集中的官方标注,将200类片段级的精细类别划分为14个视频级的粗略类别,例如,视频级类别“艺术与娱乐”中,包含了“芭蕾舞”、“肚皮舞”等动作,而视频级类别“体育锻炼”中则包含了“掷标枪”、“扔铅球”、“跳远”等动作。这样的划分方式保证了类内动作方差较小、降低了视频级动作类别预测的难度。同时,由于视频内容的语义关联性,一段完整视频中出现的不同动作很可能属于同一视频级类别,例如体育赛事的视频中,可能会依次出现跑步、跳远和掷铅球等动作,但它们都属于“体育”这一上层类别,这种情况下,多类别的动作标签并不会过多影响这一思路的泛化性能。此外,在动作分支与通用分支的融合策略中,目前仅将置信度最高的动作分支与通用分支进行加权融合,在后续的研究中,将尝试探索更加全面合理的动作分支融合策略,从而兼顾视频中的多类动作,进一步提升模型的泛化性能。
3.2 ActivityNet-1.3数据集性能瓶颈的讨论
在ActivityNet-1.3数据集上,尽管CAN相对于其基准模型BMN而言获得了性能提升,并且取得了超越其他模型的最佳性能,但与其在THUMOS-14数据集上的性能提升相比,CAN在ActivityNet-1.3上的提升稍显不足。实际上,如何提升ActivityNet-1.3的检测性能是该领域的共同难题。就平均mAP而言,其最佳性能在过去两年内仅仅从33.85%提升到35.52%,性能提升不足2%。尽管如前文所述,ActivityNet-1.3计算平均mAP的标准更为严苛,从而导致两个数据集之间平均mAP在数值上的差异,但除此之外,导致该数据集性能瓶颈的深层原因仍然值得探究。2.4节中的消融实验表明动作分支数目并不是阻碍性能提升的关键因素,因此,造成ActivityNet-1.3性能瓶颈的原因可能包括以下几点:
1) THUMOS-14数据集中的动作多是具有较为明确的边界的体育运动,有利于模型进行边界模式的识别,特别是在增加动作分支之后,减少了训练时的样本内部方差,进一步降低了模型的训练难度,从而取得了性能提升;与之相对应,ActivityNet-1.3中的视频包含了大量日常生活中的动作,例如“喝咖啡”、“吹头发”等,这类动作的边界相对模糊,增大了检测的难度。
2)ActivityNet-1.3包含大量持续时间较短的动作片段,类似目标检测中的小目标难题,短动作的样本个数较少,内部特征丰富度不足,导致目前的模型对于短动作的检测性能不佳,影响了整体性能。
3)现行的视频动作检测方法大多使用由特征提取器提取好的离线特征作为输入,该特征提取器并不参与模型训练。考虑到特征提取器往往采用预训练的动作分类模型,导致对动作边界缺乏关注,因此这种离线特征可能不完全适用于动作检测任务,有待探索更合适高效的视频特征提取方式。
4)在CAN中,动作分支仅仅通过增加卷积层输出通道的方式实现,这一简单的改动可能无法应对ActivityNet-1.3中的复杂数据。接下来会在对模型结构设计时进行更加深入和详尽的实验。
4 结 论
本文对视频动作检测算法进行了深入探索,指出识别动作模式和建立时序关联是该任务中至关重要的关键环节。通过对相关文献的分析梳理发现,当前方法往往不加区分地处理所有类别的动作,试图让模型归纳出一种普适的动作模式,进而定位动作片段,这忽视了不同类别之间动作模式的巨大差异。此外,现行的使用图模型在视频内部建立全局时序关联的方法存在计算量大的不足。
为此,本文从动作模式识别和时序关联建立两个方面出发,对现有方法进行了创新和改进。首先,考虑到不同动作间的巨大差异,将动作检测任务与视频级的动作分类任务相结合,在获得视频粗略类别信息的基础上,为每类动作进行定制化处理,实现了逐类别的精细化动作检测。其次,灵活利用门控循环单元GRU构造了一个三元时序模块,通过改变特征序列的输入顺序,在视频内部建立了全局时序关联,与采用图模型的其他主流方法相比降低了计算量。以上两点创新融合为类别敏感的全局时序关联视频动作检测模型,并在两个公开数据集上取得了优异性能,相关消融实验的结果则充分表明了该方法的有效性和合理性。
最后,本文对视频动作检测任务的难点以及后续改进方向进行了分析和讨论。后续工作将进一步完善模型结构,探索更好的动作分支融合策略,并尝试对当前检测性能较差的类别进行针对性改进。
