基于词嵌入特性聚类的文本主题挖掘
2022-12-17曹中华彭文忠刘媛春
曹中华,黄 欣,彭文忠,刘媛春
(1.江西师范大学软件学院,江西 南昌 330022;2.江西财经大学信息管理学院,江西 南昌 330032)
0 引言
主题模型常用于挖掘在大批量文本集中隐含的主题语义信息,获得表示文本集语义的主题词,用户通过主题词集能够了解每篇文本的主题分布和文本集的主要内容.隐含狄利克雷分配(latent Dirichlet allocation,LDA)[1]是一种广泛使用的主题语义分析模型,它以概率方式描述文本内容的生成,通过近似求解的方法获得文本的主题信息,但是LDA使用词袋模型描述文本生成,忽略了词间序列等关键语义信息.
词嵌入表示[2-4]含有丰富的词间相关和相似语义,可以为主题模型提供词间序列等语义信息,目前已经出现了许多应用词嵌入的文本主题挖掘模型[5].研究者或是将词嵌入应用于概率模型中,求解词袋模型缺少词语义信息等问题[6-7];或是将词嵌入应用于神经网络结构的主题模型,通过生成或对抗学习挖掘出文本集的主题信息[8-9].由于词嵌入维度较高,所以神经网络结构主题模型会显著提高模型参数的复杂度,增加模型的计算成本.
近期的一些研究表明:常见词嵌入模型的词嵌入语义和文本主题一致性评价存在联系[10],通过对文本嵌入或词嵌入进行聚类分析能够挖掘出一致性较好的主题内容,但是这些研究还是使用常见的聚类算法来获取词嵌入的簇类信息,缺少根据词嵌入学习方式及语义特点来获取词嵌入的簇类信息的研究.如Word2vec的SGNS(skip-gram with negative-sampling)模型采用负采样方法,使相关词嵌入相似性增强,目标词和负样本词嵌入相互远离;BERT(bidirectional encoder representations from transformers)等上下文内容词嵌入学习模型,通过多层注意力机制使重要相关词嵌入的相似性增强,其他词嵌入间的相似性减弱.
本文根据一些词嵌入模型通过预测相邻词的生成,使相关、相似语义词间的嵌入表示相似性较大,不相关词的嵌入表示相互远离,从而使隐含有相关、相似语义的词嵌入表示在特征空间中聚集在一起的特点,设计并实现了一种基于该特性的聚类算法(word embedding characteristics clustering,WECC),该算法充分利用词嵌入特性信息,能够较好地发现词嵌入聚类的簇中心,且能够适应大规模词嵌入聚类任务,从而可实现挖掘大规模文本的主题信息.实验表明:在一些词嵌入模型的预训练词嵌入上,该算法能够挖掘到主题一致性和多样性更好的结果.
1 相关研究工作
聚类是常见的无监督学习方法,聚类分析首先需要提取数据特征,确定数据相似性度量方法,然后依据特征和距离度量方法将数据划分到不同簇中,使簇内数据相似性较大,簇间数据相似性较小.词嵌入表示具有丰富的语义信息,也使得文本内容具有了形式多样的语义表征,通过对文本的各种表征信息进行无监督聚类,可以分析文本的各方面内容.近期一些研究者提出了基于文本嵌入或词嵌入无监督聚类的主题挖掘算法,根据需要聚类的数据类别,这些研究主要可以分为以下2大类.
一类是通过文本嵌入聚类获得文本的簇中心嵌入,然后分析簇中心和词之间的关系,挖掘文本主题信息.D. Angelov[11]首先使用Doc2Vec模型[12]学习文本和词的嵌入表示,然后通过文本嵌入聚类获得簇中心,并将其作为主题语义嵌入,最后计算词嵌入和主题嵌入的相似距离,挖掘文本主题信息.BERTopic[13]首先使用Sentence-BERT框架[14]将句子或文本转换为密集的向量表示,然后将这些文本嵌入进行聚类操作后获得文本集的簇结果,最后使用类别TF-IDF方法提取每个簇的主题词.但是这类模型方法在文本内容篇幅较大时所获得的文本嵌入语义并不能准确表示文本主要内容,从而会影响到主题词的提取.
另一类方法不需要获得文本嵌入,这类算法通过直接对词嵌入聚类来挖掘词嵌入的簇中心.S. Sia[15]直接对词嵌入聚类获得簇中心,并将其作为主题嵌入,通过计算主题嵌入和词嵌入的相似性以及词在文档集中的相关权重选择主题词,从而挖掘文本主题结果.R.M. Guilherme等[16]提出使用自组织映射对Word2vec方法生成的词嵌入进行聚类,从而挖掘文本集的主题内容.L. Laure等[17]研究了具有上下文内容的词嵌入聚类,发现聚类结果能够自然地捕获词的多义性,主题内容能达到常见主题模型类似结果.上述这些词嵌入聚类研究需要将所有的词类嵌入输入系统中,由于词嵌入维度较高,当需要聚类的词类数较大时,对机器的计算资源要求较高,所以常见算法在一般硬件环境下很难满足大规模词嵌入聚类任务需求.因此一些词嵌入聚类算法会先对预训练词嵌入降维,然后使用K-Means(KM)、高斯混合模型(GMM)等算法挖掘词嵌入的簇中心.词嵌入降维会造成词语义丢失,使降维的数据特征不一定适合数据聚类目标,而且一些研究实验表明词嵌入降维对提高主题结果影响有限[15,18].
针对近期各类词嵌入聚类挖掘文本主题研究,Zhang Zihan等[19]比较了多种词嵌入聚类文本主题挖掘算法,并提出了一种新的主题词权重计算方法;Yu Meng等[18]认为BERT的MLM(masked language model)预训练学习目标的上下文词嵌入可看作是由与文本集词典大小的高斯模型混合生成的,提出文本嵌入和主题嵌入联合学习算法,挖掘文本集内的主题.
数据的特征表示会极大地影响聚类性能,词嵌入作为词语义的特征表示,含有词嵌入聚类的有关信息内容,上述这些工作都忽略了词嵌入聚类可以深入理解词嵌入模型学习机制,依据词嵌入数据的特征表示设计聚类算法,从而更好地挖掘词嵌入的簇类结果.
2 本文工作
2.1 词嵌入相关及相似性
设文本集D的词典集合是W,词wi∈W为在文本内句子中某个词,wi的上下文内容词集为h(wi),上下文内容词集可以像BERT的MLM模型一样是句子内其他未缺失词,或是像SGNS模型一样是在中心词wi前后固定窗口范围内的词.语言模型学习目标是最大化对数似然函数
L=lgp(wi|h(wi)).
(1)
令vi∈Rk表示词wi的嵌入表示,vh∈Rk是在上下文内容h(wi)中有关词经过神经网络函数后的嵌入表示,如在SGNS模型中vh表示上下文内容中的某个词嵌入,在MLM模型中vh为上下文内所有词嵌入的加权表示,k表示词嵌入维度,k≪|W|,pwi|h(wi))使用词嵌入方式
(2)
Li Bohan等[20]认为词和上下文嵌入的点积可以表示为
(3)
其中pmi(h(wi),wi)表示词wi和上下文h(wi)之间的点互信息,点互信息能够评价它们之间共现的重要性,lgp(wi)、λh分别是中心词和上下文内容有关常量.
式(3)表明词嵌入学习会使相关的词和上下文内容嵌入相似性较大,此外一些模型(如SGNS、BERT)还采用负采样或注意力机制等方法强化它们之间的相似性.根据分布假设,若词wi、wj具有相同且重要的上下文内容,则词wi、wj的嵌入表示相似性也会较大.在词嵌入训练后,这些具有相关和相似关系的词嵌入表示会在特征空间中聚集在一起,但是由于词嵌入维度较高,所以这种空间聚集关系不是很明显.
词嵌入聚类的目标是发现在空间中相似节点的聚集中心.设词wi属于簇类cj,则vi在特征空间与簇中心嵌入vcj(1≤j≤l)应该最相似,l表示簇数.由于词wi的相关、相似语义词嵌入会聚集在一起,所以为增强簇中心cj与词wi的相似性,与语言模型训练词wi的嵌入表示类似,构造簇中心cj和词wi及词的上下文h(wi)的相似关系,并且使簇中心cj和其他负样本词相互远离,从而得到优化的簇中心嵌入.
图1描绘了WECC算法工作情况.设实心圆表示当前中心词,空心实线圆表示它的相邻词,空心虚线圆表示负样本词,星型为当前中心词的最相似簇中心.在训练过程中,中心词和相邻词会将簇中心拉向自己,而负样本词会将该簇中心推离自己,由此簇中心将到达词嵌入空间中的合适位置.
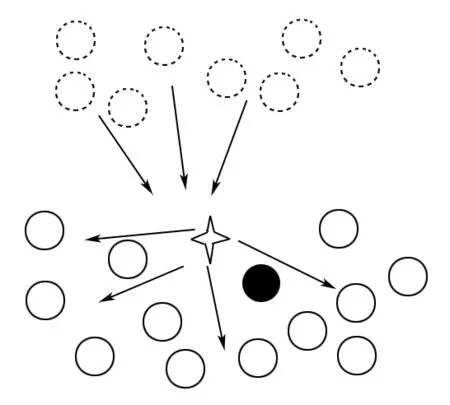
图1 WECC算法工作表示图
2.2 词嵌入特性聚类
设文本集的预训练词嵌入为{v1,v2,…,v|W|}、簇类中心集合C={c1,c2,…,cl}、簇中心嵌入表示为{vc1,vc2,…,vcl},vcj∈Rk,则词wi属于第j个簇的概率为
(4)
词wi概率值最大的簇类号m为
m=argmax(p(c1|wi),p(c2|wi),…,p(cl|wi)).
(5)
若将最大的簇类号m作为词wi的所属簇,则由前述分析,词wi相关、相似的其他词嵌入表示应该聚集在簇类m附近,从而词嵌入簇类优化目标是使簇中心cm与wi、h(wi)的相似性增加,因此模型目标是最小化对数似然函数
(6)
直接优化上述目标,会面临Softmax函数计算量较大和模型坍塌问题,因此本文采用和SGNS模型类似的优化方法,根据词wi采样簇中心cm的负样本词,使簇中心与当前词嵌入及上下文嵌入相近,并且使簇中心远离负样本词,该对数似然函数最小化目标为
(7)
其中σ为Sigmoid函数,NEG(wi)为负样本词集,负样本词采样算法和SGNS模型负样本采样方法类似.模型只需要优化簇中心嵌入,利用随机梯度下降对其优化求解,其梯度计算公式为
(8)
上述词嵌入聚类算法描述如算法1所示.
算法1词嵌入聚类训练算法.
输入:预训练词嵌入、簇类数、训练文本.
输出:簇中心嵌入.
(i)文本数据预处理;
(ii)提取文本内词间上下文关系数据;
(iii)初始化簇中心嵌入,导入预训练词向量;
(iv)While not收敛或迭代次数超过阈值;
(v) 训练数据混淆;
(vi) for所有批数据;
(vii) 计算每个输入数据最大簇类号;
(viii) 采样该批数据的负样本;
(ix) 参照式(7)更新簇中心嵌入;
(x) 更新收敛条件数据.
(xi)输出所有簇中心嵌入.
3 实验与分析
3.1 实验数据
本文实验选择用3种经典的文本数据集,它们分别是20个新闻组(20Newsgroups)、路透社新闻数据(Reuters 21578)、搜狗新闻(Sogou).20Newsgroups数据集由20个不同类别的新闻组数据组成,总共有18 846篇文本,每类数据大小几乎相同,实验使用Sklearn工具库获取该数据集,使用NLTK库去除了常见停用词、数字、特殊符号和低频词等,仅保留名词、动词、形容词,经过预处理后20Newgroup词典含有约1.50万个单词.路透社数据集通过NLTK库获取,NLTK库使用该数据的ModApte子集,总共包括10 788篇文本,该英文数据集也采用20Newsgroups相似的预处理方法,在经过预处理后,数据集词典含有约0.58万个单词.搜狗新闻使用2008年1个月的精简版数据,该语料文本包含15种不同类别的新闻信息,如军事、商业、健康、体育运动、奥运等.实验从每个类别中随机取5 000篇文本形成文本集,使用前先将其转码为简体中文编码,然后使用结巴分词工具去除非中文字符、停用词和低频词,同样也仅保留名词、动词、形容词,经过处理后,训练数据集词典含有约3.50万个单词.本文算法在计算词嵌入聚类时,需要获得词间相邻关系,为减少噪声对簇结果的影响,在原始数据集上,实验只获取在词典内默认窗口大小等于5的词间相邻关系.
3.2 实验设置
实验主要通过主题的一致性(topic coherence,TC)和主题词的多样性(topic diversity,TD)2个部分内容评估主题质量.主题的一致性使用归一化的点互信息(normalized pointwise mutual information,NPMI)评价主题词之间的共现紧密程度,主题一致性值越大表示主题词内容更容易被人理解[10];主题多样性[9]衡量在所有主题中单词的唯一性,多样性值越大表示主题内容涵盖面更广泛.基准模型使用S. Sia等[15]提出的词嵌入聚类主题挖掘算法、M. Grootendorst[13]提出的先文本嵌入聚类,然后寻找簇内主题词的方法以及其他概率模型、神经网络模型方法,这与本文直接词嵌入聚类技术线路不同,所以未列入比较.
实验使用SGNS、GloVe、BERT等3种主流模型的预训练词嵌入来比较不同模型的词嵌入使用各种聚类算法的主题挖掘质量.在词嵌入聚类前,先用相关工具获得文本集的词嵌入,SGNS、GloVe是使用较广的静态词嵌入模型,SGNS模型的词嵌入使用Gensim工具训练得到,GloVe词嵌入使用Pennington提供的程序训练得到,它们的词嵌入维度k=300,其他模型参数都使用默认值.BERT是具有多层结构的动态词嵌入模型,模型会根据上下文内容动态产生不同的词嵌入,实验使用它的最后层输出作为词嵌入,并计算每类词嵌入的平均值作为聚类输入数据.英文BERT词嵌入使用Transformers的bert-base-uncased预训练模型库获得,中文使用WoBERT Plus模型[21]获得动态词嵌入,BERT模型词嵌入维度k=768,本文簇类中心维度和当前使用的词嵌入维度大小一样.
由于词嵌入只含有词语义信息,而文本主题需要挖掘文本集的总体语义信息,因此只依据聚类的簇中心很难全面地反映词在文本集的重要性.算法没有采用式(5)将每个词分配给概率最大的簇,根据簇内词的概率值大小选择它的代表词,而是依据簇中心嵌入和词嵌入的余弦相似性大小获得每个主题的初始主题代表词,这样可以和LDA模型一样,每个主题都含有所有词的生成概率.每个主题的初始代表词将按照词的文本权重进行调整,选择前10个词作为主题代表词,相关权重设计方法为
(9)
tfdf(wi)=tf(wi)|{d∈D|wi∈d}|/
|D|,
(10)
tfidf(wi)=tf(wi)lg(|D|/(|{d∈D|wi∈d}|+1)),
(11)
其中ni为词wi在数据集D中的总词频数,d为数据集D的某篇文本.若不依据词权重进行调整,则直接取最相似的10个词作为主题词,本文称其为原始(original)方式.
3.3 实验结果与分析
实验获取了本文算法在多个不同簇类数下的主题评价结果,当用于文本主题挖掘时,簇类数即为主题数作为超参数预先设定.和S. Sia等[15]实验一样,在这3类数据集下,当主题数等于20时得到最优的NPMI值.表1列出了当主题数等于20时各类算法的最优实验结果,其中20Newsgroups和Reuters数据集使用S. Sia等研究的最优结果,S. Sia等未进行Sogou中文数据实验,在其工作基础上,本文补充了其在Sogou新闻数据集上的主题结果.
从表1实验结果可以看出:本文算法在SGNS模型词嵌入的主题一致性结果上都优于其他所有情况.在词的多样性方面,除WECC算法在GloVe词嵌入的情况外,其他算法的结果表现都较好;对于同种预训练词嵌入,本文算法在SGNS词嵌入的主题一致性值上提高了0.10;BERT模型词嵌入在英文数据集下的主题一致性提高了0.05,在中文数据集下的BERT词嵌入比一些算法的有所降低.这是由于中文分词会影响BERT模型的词嵌入表示.对于GloVe词嵌入,本文算法得到的主题结果则不理想,这可能是由于在SGNS、Bert模型训练词嵌入时能够增强词嵌入的相关性,而GloVe词嵌入模型只是拟合词间全局相关性值,没有去调节词间的重要相关性.本文的词嵌入聚类算法和SGNS模型学习词嵌入过程非常相似,更能够捕获该模型的词嵌入簇类结构信息.

表1 各模型最优一致性和多样性值
表2~表4分别为本文算法运行于20News-groups、Reuters 、Sogou数据和主题数为(20,50,80,100,120)的实验结果.从每类数据的实验结果可以看出:当主题数增加时,主题一致性值都呈现递减趋势.对于主题词的多样性,未调整的original结果都保持有较好的结果.其他经过调整的结果也随着主题数的增加,主题词的多样性呈递减趋势.

表2 20Newsgroups一致性和多样性值

表3 Reuters一致性和多样性值

表4 Sogou一致性和多样性值
在相同主题值时,通过词的文本权重调整后的主题一致值比直接采用original方式的主题一致性值都有所增加,而主题词的多样性则有所降低.这说明词嵌入在特征空间上的分布间隔并不明显,使得一些簇间的边界并不清晰.当主题词调整后能够成为主题词时,降低了主题词的多样性.tf、tfidf和tfdf这3种词的文本权重方法通过调整聚类的初始主题词都能够提高主题的一致性.从结果来看,很难判别出哪种方法更好.
综合比较这3类数据集结果,在数据预处理方法一样的情况下,随着数据规模的增加主题一致性也逐渐变大,这体现了数据量的增加词间的共现密集程度也增加、词嵌入的重要聚集关系表现更加明显.同时可以看出:虽然各类词嵌入模型的理论分析上和词嵌入的最相似词计算结果等方面都比较接近,但不同模型的词嵌入还是具有各自特点,它们的词嵌入特征在空间上的分布并不一样,这需要后续持续研究.
4 结束语
本文设计并实现了一种基于词嵌入特性的聚类算法,该算法通过增强中心词的簇中心与相邻词的相似性,并且使其远离负样本词,可以从SGNS、BERT模型词嵌入中学习到更好的词嵌入簇类结构信息,并将其应用于文本主题挖掘.实验表明本文词嵌入聚类算法挖掘到的主题词能够显著提高主题一致性值,并且算法采用批量文本训练方式,能够适用于大规模词嵌入聚类任务需求.
