扎心了,机器比我会学习
2022-12-17□汪寒
□ 汪 寒

能自动避开障碍物的无人驾驶汽车,在无聊时陪主人“神聊”的智能手机语音助手,比亲朋好友还“懂”我们的推荐算法……不知道你是否已经注意到,人工智能技术早已渗透进生活的方方面面,正以前所未有的速度接近下一次技术革命,而开启下一次技术革命大门的钥匙就藏身于人工智能技术的广阔蓝海中。
机器学习,也要先打好基础
面对自动运行的家用电器或与智能音箱对谈的时候,也许你会对它们的贴心、智能化感到不可思议,机器为何能读懂人类的想法呢?其实,目前的人工智能基本都是基于机器学习技术实现的,可以说,是“机器学习”让家里的电器读懂了你。
机器学习,顾名思义,就是让机器具有学习的能力,而学习能力正是普通机器与人工智能的分水岭。
18 世纪中叶,在瓦特改良蒸汽机的时代,开启了人类第一次工业革命的蒸汽机只会夜以继日地重复一个动作,任何看过这台机器的人都不会把它与“智能”二字联系起来。随着科技的进步,人们设计了许多更为复杂的机器,但它们仍然不具备基本的智能。
20 世纪50 年代,计算机理论迅速发展,机器学习终于登上了历史的舞台。机器学习的基本思想其实并不复杂,即将大量数据输入人工智能算法(AI 算法)中,对其进行训练,让AI 算法生成模型,从而实现对事物潜在规律的揭示和对未来情况的预测。
例如,你想观察家门口路过的洒水车,并对它的“行为”进行预测。在观察的前6 天,你发现洒水车每天清晨5 点准时路过家门口,此时便形成了一个简单的认识模型:洒水车每天清晨5点都会路过。如果第7 天是周日,是洒水车司机的休息日(但你并不清楚),你发现洒水车没有像往常一样路过,此时意味着之前的模型并不准确。又过了一周,洒水车仍然是周一到周六每天清晨5 点路过,周日不再出现,你便可以通过新数据来纠正模型,从而更加接近事实。
机器学习的过程与观察洒水车差不多。输入数据之前,机器就像一张白纸,一无所知,正如同第一天之前你也不知道洒水车会来。当研究者试图给具有学习能力的机器输入数据时,一切都变得不一样了。假设洒水车的观察者是一个十分懒惰的人,不愿意动脑筋推测洒水车的运行规律,他就可以把每一天洒水车的“行为”数据输入到机器的AI 算法中,这个过程被称为“训练”。通过大量的数据训练,AI 算法对于洒水车“行为”的预测将会越来越准。
机器也躲不过题海战术
有了数据之后,研究者还需要选择合适的“学习方法”才能让机器学得更快、更好。你也许听说过一些与机器学习有关的名词,比如监督学习、强化学习等,实际上这些都是描述机器学习过程中不同的训练方法,往往适用于不同的情况。
例如,研究者希望让一个算法学会辨认猫和狗,如果提前给算法输入大量猫和狗的照片,并且告诉它这张照片是猫还是狗,那么这就是监督学习(Supervised Learning);如果研究者给算法大量猫和狗的照片,但是不告诉它哪些是猫,哪些是狗,而让算法自动寻找猫和狗的差异,这就是非监督学习(Unsupervised Learning):如果让算法不断地做选择题,每次都让算法“看图”后选择是猫还是狗,答对奖励加分,答错惩罚扣分,算法在试图尽量得分且规避扣分的情况下,经过大量训练便会“进化”出辨认猫狗的能力,这就是强化学习(Reinforcement Learning)。
正是通过大量的数据训练,机器才获得了强大的能力,即使人工智能“阿尔法围棋”(Alpha Go)背后的科学家们并不是围棋大师,有些甚至完全不会下围棋,也能让它战胜人类围棋世界冠军,而这在传统的机器上是不可能发生的。传统机器的所有“行为”都是设计者提前编写好的,因此它无法实现超出设计者认知的行为。
机器学习并非无懈可击
虽然机器学习让人们身边的很多物品越来越智能化,但距离真正的“强人工智能”还有很大的差距,这是因为当前基于数据的AI 算法在很多时候有很大的局限性。比如,一个长期接受“辨识猫狗”训练的AI 算法可能会把吉娃娃错认为猫,也有可能把无毛猫误认为狗,这主要是因为机器学习得到的结果与训练数据高度相关。如果训练AI 用的数据是偏颇的,比如训练用的猫的照片基本都是有毛的长尾猫,狗的照片基本都是大型犬,那么这样训练得到的AI 算法就很容易在辨识某些其他种类的猫狗时犯错。
目前,人工智能系统的问题在于机器学习的可解释性缺陷,即机器学习是一个“黑箱”过程,我们无法解释它到底根据什么特征做出判断。人类在学习辨认猫狗的时候,往往会把判断特征集中在猫狗身上的某些关键部位。一个通过图像训练得到的AI 算法,即使结果正确率很高,却有可能把某些判断特征放在环境上,显然这是不合理的,可能导致其系统应用存在潜在的风险。例如,在研发一个人工智能自动驾驶系统时,如果研发者不能判断它是根据什么做出驾驶决策的,那么即使该系统在推广前的测试中表现完美,也可能在遭遇复杂路况时出现致命错误。曾有一场发生在美国的车祸,就是因为人工智能自动驾驶系统错误地把卡车的白色车厢识别为天空,导致汽车径直撞了上去。
这也从另一个角度阐明了一个道理:题海战术虽然有用,但并不高效,而且会导致潜在错误,要想学习新知,还是要运用因果逻辑,从根本上搞清楚事物的来龙去脉。目前,科学家希望能在人工智能上实现这一点。
实现因果逻辑,机器还需努力
贝叶斯网络的创始人、图灵奖得主朱迪亚·珀尔认为,让人工智能实现本质飞跃的关键就藏在每一个人的大脑中,即上天赐予人类的强大武器——因果逻辑。
珀尔把思维分成三个等级:第一个等级是关联,与之对应的是观察的能力,这是目前基于数据的“弱人工智能”所处的级别;第二个等级是干预,与之对应的是控制变量实施行动的能力,即能够借助干预来获得认知;第三个等级是反事实,与之对应的是想象的能力。幸运的是,人类的大脑处在第三等级,想象力给予我们通过想象构建反事实——虚构世界的能力,从而建构认知。例如,爱因斯坦通过思想实验将狭义相对论推广到具有加速度的非惯性系中。
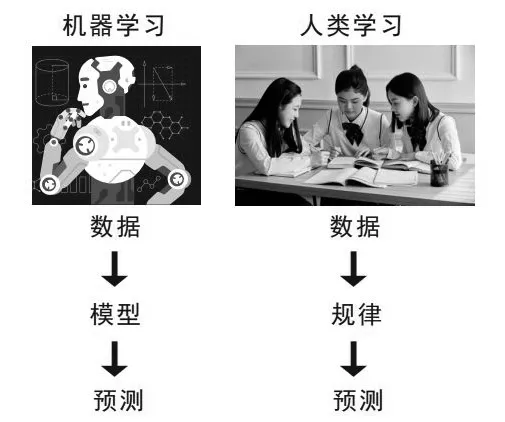
机器学习过程与人类学习过程异同
关联和因果的区别在于,关联仅反映数据间最表层的信息,即相关性。例如,有数据表明,气温与犯罪率有相关性,气温低的时候犯罪率更高。我国春节期间的犯罪率的确会上升,其原因主要是春节期间小偷的活动变得频繁,而恰好春节一般处于一年中气温最低的时间段。如果我们把数据输入只懂得分析关联性的人工智能系统中,仅从关联的角度分析数据,将会得到“气温降低导致犯罪率上升”的结论。如果利用这个人工智能系统预测一个没有春节文化的国家的犯罪率,或者一个气温异常年份的犯罪率,很有可能会得到“谬以千里”的结论。
从因果关系的角度出发,研究者不仅要分析数据之间的关联性,还要判断其内部的逻辑链条,比如,当全年气温保持不变时,犯罪率是否会变化?如果得到的答案为“是”,那么便可以认为除了气温还有其他影响因素。比如,由于新冠肺炎疫情暴发,2020 年春节期间人员流动降低,虽然冬天的气温仍照常下降,但犯罪率却没有随之变化。
珀尔认为,从机器学习上升到因果学习的一个重要渠道是引入“干预”算子。“干预”与“观测”有本质上的不同,例如,观测到公鸡打鸣和强制让公鸡打鸣是完全不同的两件事。目前的AI算法可以判断公鸡打鸣和太阳升起这两件事之间的相关性,可是却很难判断强制让公鸡打鸣时太阳是否也会随之升起。珀尔认为,只接受被动观测数据的人工智能无法攀登上第二等级回答与“干预”有关的问题,也就无从理解“公鸡打鸣”与“太阳升起”这两件事之间的因果关系,因为因果关系的确认需要进行控制变量实验,而这样的实验本身是建立在干预上的。
也许你会问,如果观测到的维度足够丰富,获得的数据足够充分,观测是否可以代替干预呢?实际上,我们很难保证数据范围与实际测试环境一致,更困难的是,很多时候无法知道数据本身是否完备。这就导致无论用多么巨量的数据训练AI 算法,都有可能因为数据与测试环境不完全一致而出错,这被称为OOD(Out Of Distribution)问题。图灵奖得主约书亚·本吉奥也认为,OOD 泛化是当前人工智能最急需解决的一个问题。
现在,生活中常见的人工智能系统与“强人工智能”还有很大差距,它们还不具备判断因果关系的能力,也完全没有第三等级的想象力。不过,科学家已经认识到“因果学习”是让人工智能实现下一次飞跃的关键,许多科学家相继投入到“因果机”的理论研究中。例如,清华大学的崔鹏教授提出了通过将因果推理与机器学习相结合的稳定学习(Stab1e Learning)来改进OOD 泛化问题;卡内基梅隆大学的黄碧薇博士利用因果关系发现框架,在时间序列的非稳态数据上实现了更精准的预测。随着技术的发展,人工智能技术一定会越来越可靠,并能最终造福人类。
