基于LSTM(长短期记忆)网络的城市轨道交通列车停站精度预测*
2022-12-10谢嘉琦邹喜华汪小勇毕文峰华志辰
谢嘉琦 邹喜华 汪小勇 毕文峰 华志辰
(1.西南交通大学信息科学与技术学院, 610031, 成都; 2.卡斯柯信号有限公司, 200072, 上海∥第一作者, 硕士研究生)
0 引言
许多城市轨道交通线路采用了全自动运行系统。全自动运行系统不仅可以保障列车的运行安全,有效提升线路的折返效率,还可以减轻运维作业的工作量[1]。与传统有人驾驶城市轨道交通线路相比,列车进站自动停车功能是全自动运行线路的优势之一。在列车进站自动停车的过程中,停车精度是衡量列车是否停准的一个重要指标。
影响列车停车精度的因素主要有以下几点:首先是列车自身因素,ATO(列车自动运行)系统会给空气制动系统设定一个预压力,以提高空气制动的响应速度,从而导致列车实际的制动力偏高[2];其次,考虑到故障-安全原则,ATO会对制动系统设定一个空气制动余量,这个余量会导致列车实际制动力略大于所需值;再次,在线路方面,某些车站的线路曲线半径过小,以及露天线路天气的影响、各站点应答器的安装差异、站台门的对位差异等因素,都会在一定程度上影响列车的停车精度[3]。
国内外关于ATO模式下列车停车控制的研究主要集中在两大方面:优化控制算法和机器学习方法。由于城市轨道交通线路投入运营后基本不会更改列车运行的控制算法,且停车过程的建模较为困难,因此,优化控制算法在城市轨道交通中的适用性不强。在机器学习方法的相关研究中,文献[4]对停车过程中列车的速度、位置等信息进行建模,对比了CNN(卷积神经网络)和DNN(全连接神经网络)两种算法的优劣。文献[5]利用多种数据挖掘算法(如Ridge回归、RBF(径向基函数)神经网络等)构建了列车停车精度的预测程序。文献[6]采用了机器学习中的Boosting回归算法对列车停车精度进行了回归预测。
城市轨道交通的运维人员通过收集长期的列车停车精度数据,根据数据每日的变化趋势,手动对列车停车的追踪目标点进行调整。这种做法工作量大、效率低下,严重影响了生产效率。因此,迫切需要找到一种有效的方法,通过对历史大数据进行分析,找出隐藏其中的数据规律,为列车进站自动停车精度提供辅助预测,用以指导车辆运维人员进行参数配置。
本文提出一种列车进站自动停车精度的预测方法。该方法采用Weibull分布参数拟合每期的停车精度分布,得到分布拟合结果后,构建LSTM(长短期记忆)网络算法模型。在此基础上,采用成都某地铁线路列车的历史数据对模型进行训练和验证,对预测模型的分布参数进行回归预测。在工程应用上,城市轨道交通车辆运维人员将列车实时的停车精度数据序列输入到模型后,模型将自动预测列车在下一个车站的停车精度,运维人员从而可以通过手动移动列车的追踪目标点来确保列车精确停车。
1 列车进站自动停车精度预测分析与拟合
1.1 列车进站自动停车精度预测分析的算法框架
图1为列车进站自动停车精度预测分析的主要流程。该流程主要包括以下5个步骤。
步骤1:数据清洗。运维人员获得现场停车日志后,提取出列车停车精度的记录信息,并对其中无效的数据予以去除。
步骤2:对列车停车精度数据进行预处理。根据城市轨道交通一线员工的工作经验,将列车停车精度的历史数据以1 d为1个统计周期进行预处理(如数据清洗、数据转换等)。
步骤3:采用Weibull最小极值分布法和Weibull最大极值分布法对每个统计周期的数据进行拟合,得到对应的分布参数;对比分析这两种分布的拟合度,得到对应参数的时间序列。
步骤4:构建LSTM预测模型。在已获得的时间序列基础上,采用LSTM网络算法构建列车进站自动停车精度的LSTM预测模型;对模型进行验证评估,并对下一个统计周期的分布参数进行预测。
步骤5:预测模型的应用。通过预测获得的下一个统计周期的分布参数,综合评估下一个统计周期列车停车精度调整的偏差值。

图1 列车进站自动停车精度预测分析算法框架
1.2 列车停车精度分布拟合
目前,主要采用两种方法对Weibull分布进行参数拟合:最大似然估计法和矩估计法。本文经过大量的实践验证后,采用简单有效的最大似然估计法对Weibull分布进行参数估计。Weibull分布的最大似然函数为:
L(x1,x2,x3,…,xi,α,β)=
(1)
式中:
由于车次数一般少于车组数,因此,首先需将车组号对应的最佳匹配车次进行补全,依次加1,作为车组号最佳匹配车次参考。车组Ti与车次Fj的匹配度Cij的计算公式如下:
L——Weibull分布的最大似然函数;
x1,x2,x3,…,xi——各维度的数据值,i为停车精度的维度;
α、β——Weibull分布拟合参数;
n——自然数序列。
式(1)两边取对数,可得:
lnL(x1,x1,x1,…,x1;α,β)=
(2)
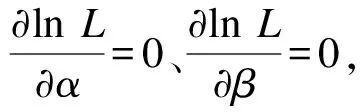
(3)
求解上式(3),即求得α和β。
2 LSTM预测模型的实例验证与结果分析
2.1 数据的处理及拟合
从图2 a)可以看出,这些数据在整体分布上具有正态分布的特点。采用Alpha分布、Weibull分布(包括Weibull最大极值分布、Weibull最小极值分布)及Laplace分布对数据进行拟合,得到的拟合结果如图2 b)所示。其中,Weibull分布拟合效果最好。因此,本文采用Weibull分布对该线列车后续每一个统计周期的数据进行拟合并分析。

a) 整体停车精度分布

b) 分布拟合
根据列车运行计划,该列车在1 d内停靠站台的次数为534次。该列车的历史数据统计了256 d,以1 d为1个统计周期,则将历史数据划分为256期,即有256个数据样本。对每1期数据采用Weibull分布进行拟合,可得到Weibull分布拟合尺度参数和形状参数的时间序列。由于数据过多,为便于展示,本文仅列出第1期、第50期、第100期、第150期、第200期及第250期的数据样本,以及这些样本对应的分布参数,如表1所示。
2.2 构建LSTM预测模型
利用多层网络搜索法,寻找LSTM网络最佳拟合参数的三维图,3个维度分别是窗口长度l、学习率η、状态大小Sstate。对这3个维度进行量纲一化处理,可以得到最佳的拟合参数分别为:l=3,η=0.012 84,Sstate=4.573 5。

表1 列车停车精度的Weibull分布参数
图3是测试集上对Weibull最小极值分布和Weibull最大极值分布的形状参数和尺度参数的预测结果。这两个参数均具有周期化波动的趋势,传统的机器学习方法不适用于处理这类预测问题。并且,本文所研究的数据是一维的时间序列,而在时间序列的预测方面,基于RNN(循环神经网络)的LSTM网络有较好的效果,因此,构建基于RNN的LSTM预测模型。由图3可看出,量纲一化后得到的列车停车精度分布预测效果与各统计周期下的现场原始数据分布基本吻合。由此可以得出结论:LSTM预测模型能够较好地捕捉尺度参数和形状参数的变化趋势,并可准确地预测后续统计周期的参数值。

a) 最小极值尺度参数预测

b) 最小极值形状参数预测

c) 最大极值尺度参数预测
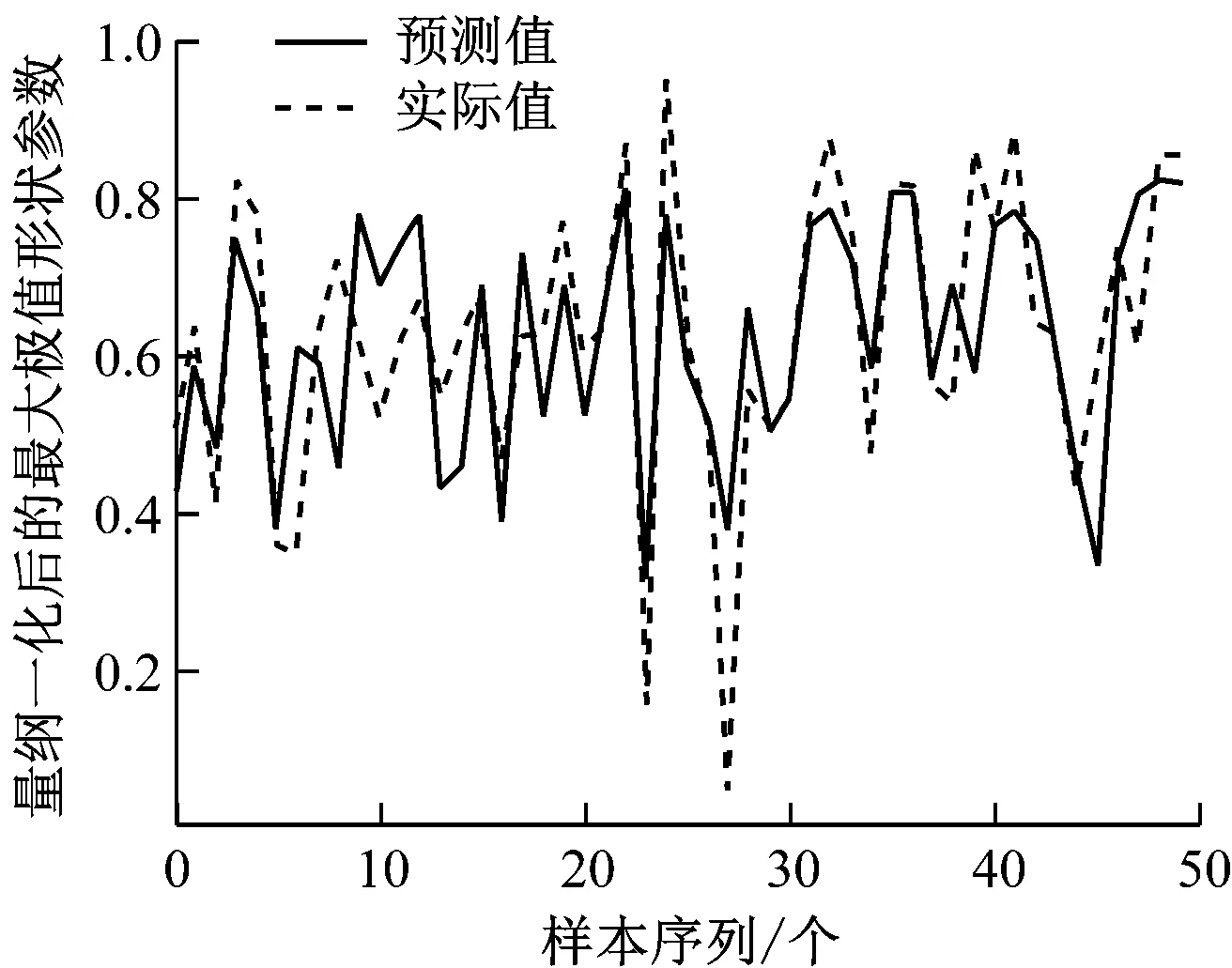
d) 最大极值形状参数预测
图4为LSTM预测模型最小极值尺度参数的均方误差值ERMS,以及预测值分布和实际值分布的相似度MS的计算结果。由图4可知,随着训练轮数的增加,ERMS大为降低,在100轮左右ERMS下降到0.043 7并趋于稳定。这说明模型训练比较充分,可满足统计学角度对ERMS的要求。形状参数和尺度参数时间序列的预测效果较好,从而验证了LSTM预测模型的有效性。
从分布相似性的角度看,预测值分布和实际值分布的相似性均值EAR为0.942 6,且每一个统计周期的MS均大于0.9。这说明LSTM预测模型具有较好的普遍适用性和有效性。

a) ERMS随训练次数的变化情况
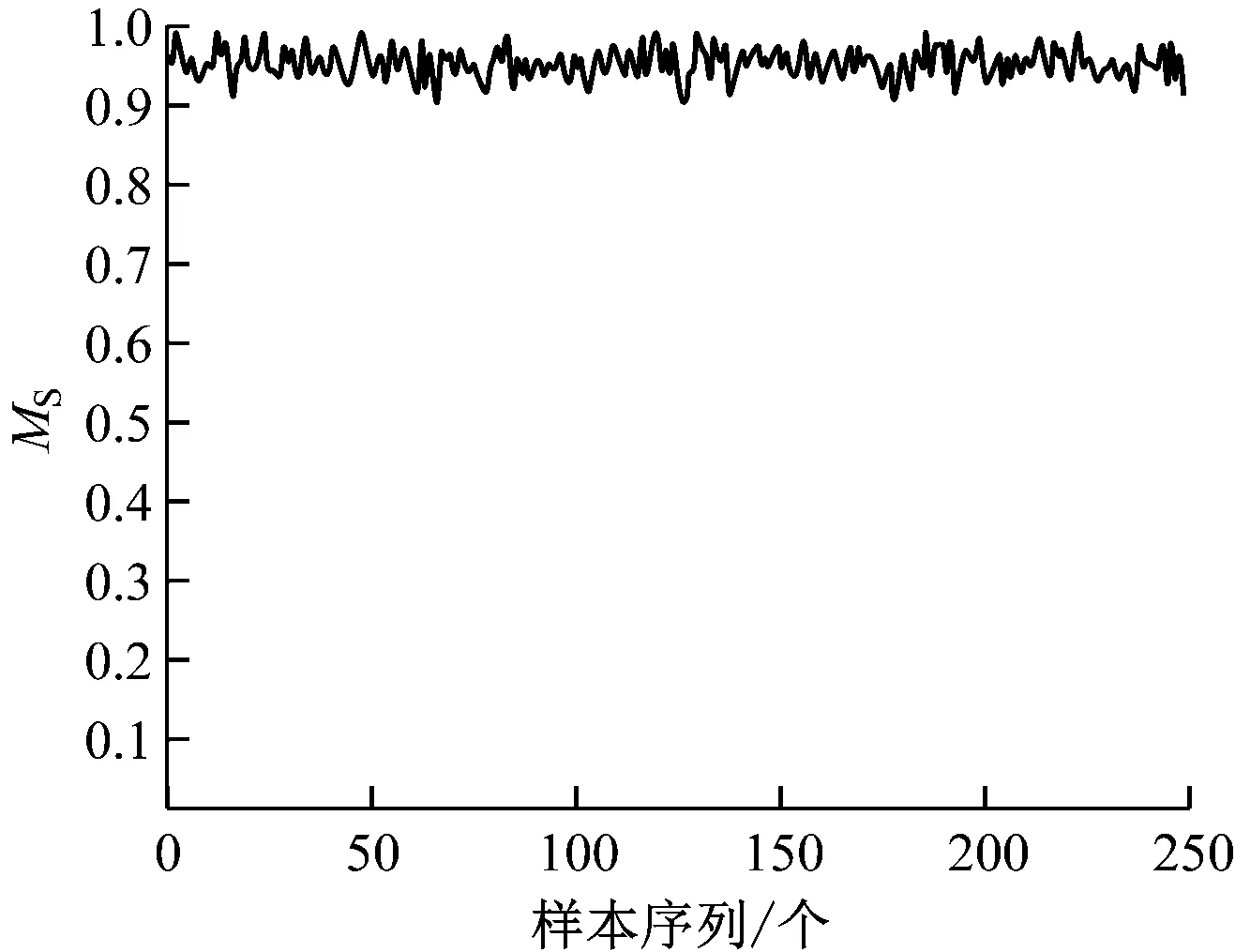
b) 预测值分布与真实值分布的MS
3 结语
本文通过对成都某地铁线列车停车精度的历史数据进行数据分割和数据预处理,对获得的256个样本序列采用Weibull分布的方式对样本数据进行拟合,获得了Weibull最大极值分布的尺度参数和形状参数,以及Weibull最小极值分布的尺度参数和形状参数。采用对时间序列预测表现良好的LSTM算法对这4个参数值的时间序列进行训练,在100轮训练后用测试集对参数值进行验证,其均方误差ERMS满足统计学的要求。因此,本文研究得到的LSTM预测模型对列车停车精度的预测有效且准确。
