基于数据驱动的高校学生心理健康评估研究
2022-12-07李刚陈洁
李刚,陈洁
(1.陕西中医药大学第二附属医院,陕西,咸阳 712000;2.西安市大数据服务中心,陕西,西安 710001)
0 引言
大学生对自己未来的人生饱含期待,充满着激情和活力,但他们抗压能力严重不足,易受外界干扰,心理变化较大,导致许多大学生不自觉地产生不同的心理健康问题[1-3]。
针对大学生日趋严重的心理健康问题,该课题越来越多成为学术研究主题[4-5]。有学者在基于积极心理学视角下研究的学生心理健康评估方法,采用Cronbach’s α系数和Pearson相关系数评价量表的内容效度获取学生心理健康评估结果[6];有学者基于多特征融合的在线论坛研究的用户心理健康自动评估方法,基于多特征设计的融合心理健康评估框架与贪婪法、降噪自编码器等策略相结合的方式,实现对学生的心理健康评估目的[7]。虽然这两种方法都能有效评估学生的心理健康状态,但是不完全体现出在校大学生的心理健康,基于此,本文进行了基于数据驱动的大学生心理健康评估研究,数据驱动是一种解决问题的方法,当我们不能简单且准确的解决一个问题的时候,就可以根据实际的历史数据和关系数据构造与真实情况相近的模型对问题进行求解,在适应过程中具有实践指导作用。
1 数据驱动的大学生心理健康评估方法
1.1 基于数据驱动的改进模糊聚类算法
1.1.1 改进模糊聚类算法模型
假设数据集为n,类别数为c,类别数取值区间为[1,n]。
定义1hik为可能隶属度,表示第k个对象与第i类别之间相对应的隶属程度,取值区间为[1,n],该类别的隶属度与代表该类别的点和聚类中心之间的距离相关,间距越小,则隶属度越大,无关其他聚类中心。
定义2sik为不确定性隶属度,表示第k个对象属于第i类别的可能性,取值为0和1,不确定性隶属度具备记忆存储功能,能够记忆以往的迭代过程。

(1)
本算法被定义为不确定性隶属关系的前提条件时不同聚类的隶属度均为1时,这与其他概念中的不确定性有所不同[8]。
定义3 算法的准则函数基于参数hik、sik进行构造,即:
(2)

结合定义3和拉格朗日求值方法计算hik,拉格朗日函数为
(3)
F对hik求偏导,即:
(4)
(5)
F对λ求偏导,即:
(6)
在式(6)中代入hik,得:
(7)
在式(5)中代入式(7),即:
(8)
求解最终可能隶属度公式为
(9)
所有数据点基于参数tik、sik进行加权求均值,求解新的聚类中心公式为
(10)
1.1.2 评价指标体系构建
依据改进模糊聚类算法聚类结果,构建心理健康评估指标体系如图1所示。通过学习、生活、未来发展3个方面的共计11项指标衡量大学生心理健康[13]。

图1 大学生心理健康评估指标体系
1.2 大学生心理健康模糊综合评估设计过程
(1) 针对评估对象确定指标论域A,
A={a1,a2,…,an}
(11)
其中,n表示评估指标数,大学生心理健康的评估体系采用两层结构式,评估对象为大学生心理健康状况,指标论域表示一级指标。
(2) 确定评估等级论域B,
B={b1,b2,…,bm}
(12)
其中,m表示评估等级数,各等级与各模糊子集呈一一对应的关系,一般m为奇数,可方便利用其中间等级进行评估。评估标准B分别为优秀、良好、一般、较差、差。
(3) 建立模糊关系矩阵C。针对待评估项目依次对所有评估指标进行量化,模糊关系矩阵C根据模糊子集各等级的隶属度C(ai)确定
(13)
式中,C为从A到B的模糊关系,cij表示第i个因素获取的第j种评估结果。
(4) 确定评估因素的模糊权向量D,
D={d1,d2,…,dn}
(14)
对于评估对象来说,所有的评估指标不具备相同重要性,每个因素对总体影响性不同。在模糊评估中,di表示ai对模糊自己的隶属度,采用归一化方法确定模糊权重,然后进行合成。
(5) 模糊评估结果向量E通过合成算子对D和C合成得到C中不同的行反映的是不同的指标对模糊子集的隶属程度,对不同的行采用D进行综合即得到所有等级模糊子集的隶属程度,模糊综合评估的模型为
=(e1,e2,…,en)
(15)
式中,C表示模糊变换器,用于指标论域A和评估等级论域B之间,每个模糊向量都能得到相应的综合评估结果E,评估过程如图2所示。

图2 模糊评估过程示意图
(6) 分析模糊评估结果向量。每个大学生的心理健康评估结果为一个模糊评估值集合,与其他评估方法相比其结果中包含了更丰富的信息量,对心理健康指数的评估结果通过评估等级呈现在相对应的数值集合上。模糊综合评估模型的工作流程如图3所示。
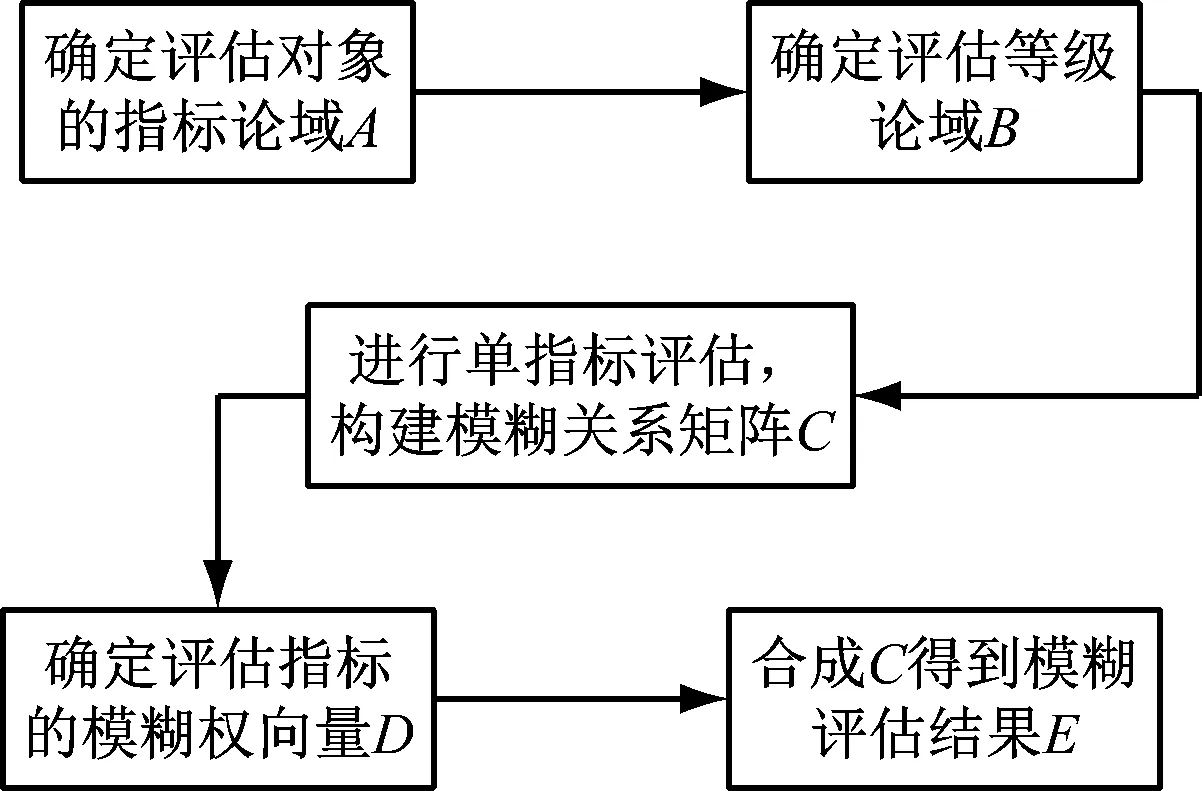
图3 大学生心理健康模糊评估模型的工作流程
2 实验结果与分析
选取某高校为实验对象,对该校近3年的3 600名应届毕业生进行心理普查、学生基本情况、社会支持度等历史数据作为实验数据集。利用本文评估方法对大学生心理健康进行评估,评估指标见图1。邀请10位心理健康方面权威专家对每个治疗进行打分,每位专家的平均值为二级指标评估结果。估计等级结合被评估学生心理健康状况,评估标准如表1所示。为了验证本文评估方法的有效性,分别采用文献[8]和文献[9]方法进行对比实验。

表1 大学生心理健康评估标准
从3 600名大学生的历史数据中选取1 000个数据样本并将其分为5组数据集,采用3种方法分别进行数聚类性能测试,对比结果如图4所示。由图4聚类结果可知,随着数据样本个数的增多,3种方法所耗时间均呈上升趋势,但是本文方法的聚类效果与文献[8]方法和文献[9]方法具有明显的优势,耗时短,运动平稳,时间控制在0.1 s以内,这是因为本文方法在聚类方面独具记忆存储功能,能够有效减少循环次数,确保结果的稳定性。
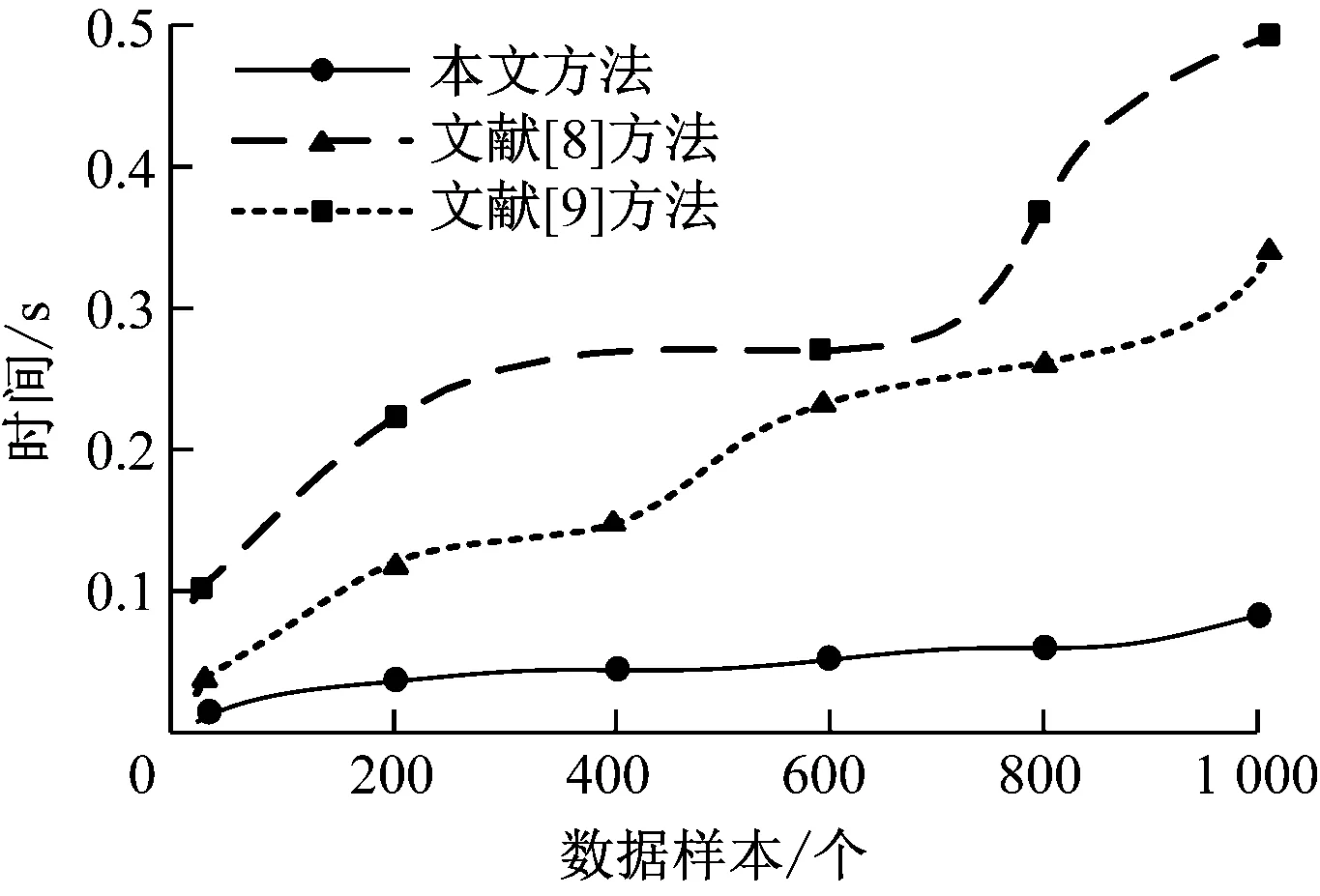
图4 数据聚类对比结果示意图
本文方法获取各指标模糊权重明细如表2所示。

表2 大学生心理健康指标权重明细表
根据以上指标权重,计算获取大学生心理健康各指标评分及相对应综合评估等级,评估结果如表3所示。

表3 大学生心理健康指标综合评估结果
参考专家实际综合评估结果,将表3的本文评估结果与文献[8]和文献[9]的评估结果进行对比,对比结果如表4所示。由表4可知,采用本文方法进行的大学生心理健康评估结果与实际评估结果一致,效果与两种对比评估方法具有明显准确率的优势,说明本文基于数据驱动的大学生心理健康评估方法切实有效,能够为大学生心理健康的评估提供有力的参考价值。

表4 大学生心理健康评估对比结果表
综合运用3种误差评价指标,分别为平方均根差(RMSE)、归一化方均根差(NRMSE)以及平均绝对百分比误差(MAPE),确保评估效果检验的全面性与客观性。
(16)
(17)
(18)
3种方法评估误差比对结果如图5所示。由图5可知,3种方法的误差结果中,本文方法的误差值始终保持最低,RMSE、NRMSE和MAPE误差值分别为0.276、0.382和0.468,表明本文方法的预测误差最低,能够满足对大学生心理健康评估的需求。
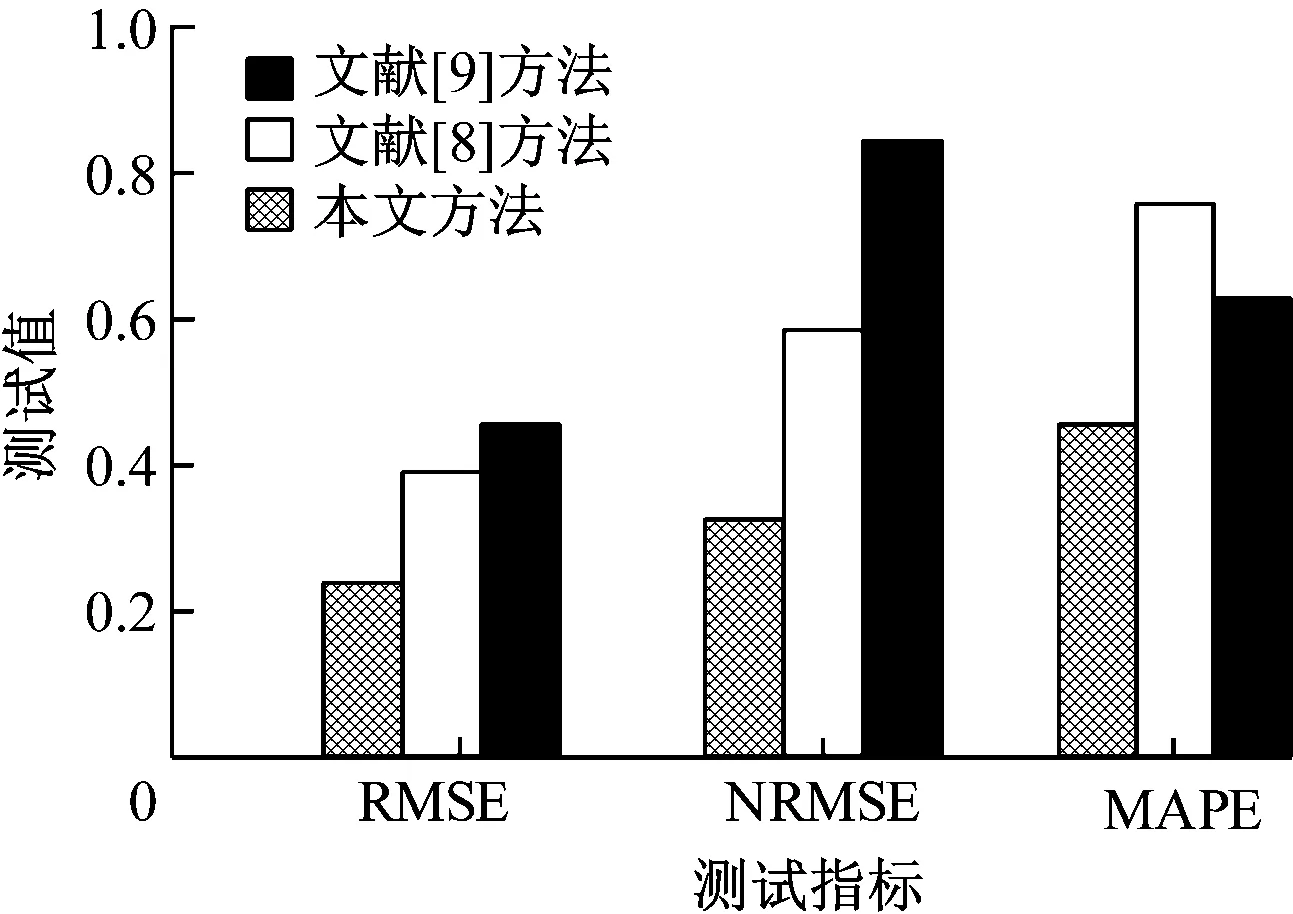
图5 误差测试结果
3 总结
大学生在面对学业、家庭和即将踏入社会的三重压力之下,出现心理健康问题的逐年增多,通过对在校大学生近几年的心理普查、学生基本情况、社会支持度等调查的历史数据,提出基于数据驱动的大学生心理健康评估方法,该方法通过改进模糊聚类算法和模糊综合评估模型的高效结合,有效降低数据冗长的影响,减少计算循环次数,确保结果的稳定性,提升大学身心理健康评估指标的合理性和正确性,促使结果量化,方便对评估结果进行分析和比较,有效消减评估过程中人为因素的干扰,具有良好的客观性和科学性。试验结果表明,该方法能有切实有效地评估大学生心理健康状况。在后续的研究中,可以针对调查问卷的编制进行合理性的加强,尽量保证所有问题都具有适用价值且符合实际情况,完善问题的选项全面问题。
