基于深度学习的公路路面病害智能化检测系统
2022-12-04吴海军王武斌张宗堂
余 俊,吴海军,王武斌,张宗堂
(1.成都工业职业技术学院 现代轨道交通应用技术研究中心,四川 成都 610000;2.湖南省交通科学研究院有限公司,湖南 长沙 410015;3.西南交通大学 陆地交通地质灾害防治技术国家工程实验室,四川 成都 610000;4.湖南科技大学 岩土工程稳定控制与健康监测湖南省重点实验室,湖南 湘潭 411201)
1 概述
公路交通作为一种重要的交通方式,对我国的政治、经济、军事发展有着重大的作用,也对人民生活水平的提高有着重要的意义。对任何一个国家而言,公路都至关重要。
近年来,随着公路的持续使用和极端天气的影响,公路路面会出现不同程度的病害,导致大量公路进入维护阶段[1-3]。如果对公路路面病害的处理不够及时,不仅会减少公路的使用寿命,导致更严重的病害,还会造成巨额的后期维护费用,甚至引发交通事故,危及出行人员的生命安全[4-6]。
因此,安全高效的公路路面病害检测方法对及时维护公路、保持公路路面路面状态良好有着重要意义。传统的人工检测公路路面病害方法效率低且误差大。因此,研究者提出了许多基于图像处理和机器学习的方法进行公路路面病害检测。
通过激光扫描可以获取公路路面病害图,并进行公路路面病害检测分析。BOYKO[7]等分析了不同时间点叠加扫描的三维离散数据,提取出了公路路面病害的特征。GUAN[8]等扫描了公路路面病害图像,并将图像进行分割,根据形态学算法得到病害特征。
在早期研究中,研究者多采用传统的图像处理算法。如BO[9]等利用形态学滤波算法对公路路面病害进行检测,HU[10]等提出局部二值算法来检测公路路面病害。但随着机器学习的快速发展,精度更高、提取特征效果更好的机器学习算法被应用于公路路面病害检测。SHI[11]等利用一种基于结构随机森林的算法对公路路面病害特征进行提取,李楠[12]应用LeNet-5网络结构对公路路面病害进行检测,张宁[13]使用Faster R-CNN进行公路路面病害检测,分类效果良好。
本文介绍了一种智能检测公路路面病害的方法,能够准确并高效地对公路路面病害图像进行处理和分类,提取特征。该方法包括异常检测、异常提取和公路路面病害分类3个组成部分。首先,在异常检测阶段构建卷积自动编码器训练异常检测器,快速在大量图像中检测到公路路面病害。然后,在异常提取阶段通过阈值分割法提取公路路面病害特征。最后,进行公路路面病害分类。在给图像添加标签后,利用ResNet结构训练模型并根据交叉验证选取分类器。
2 图像数据集
本文用佳能EOS 500D、7D和77D对公路路面病害拍摄了200幅图像,并分别以3 168×4 752、3 456×5 184和4 000×6 000像素分辨率存储。在适当情况下,需使用三脚架和稳定器来保证图像质量。为了消除不同公路路面中环境变化带来的影响,需通过各种拍摄角度、照明和摄像机距离来获取公路路面病害图,从而最大程度地提高分类器的适应性。由于GPU内存的限制,无法将完整的高分辨率图像直接用作输入。因此,需将图像裁剪成较小的图块,并通过深度学习模型逐块对公路路面病害进行检测和分类。图1显示了针对不同类别公路路面病害的图块(裁剪图像)示例,有关训练和测试阶段数据准备的更多详细信息,请参见下一部分。

(a) 正常公路路面
3 人工智能识别流程详述
图 2展示了本文采用的智能检测流程的架构,该流程有3个核心组成步骤,即异常检测、异常提取和公路路面病害分类。首先执行异常检测来生成异常图。根据异常图,可以提取可疑公路路面病害,并过滤未损坏的区域。然后,将提取的图块分类为适当的病害类别。该流程使用Python编程语言编写,基于TensorFlow编写深度学习模型,并在Nvidia 2080-ti图形处理单元上执行。

图2 智能检测流程示意图
3.1 异常检测
作为检查流程的第一步,异常检测可以快速可靠地从大量图像数据集中检测公路路面病害。在本项研究中,公路路面病害属于异常情况,而正常(未损坏)的公路路面和公路路面中发现的其他物体则被归为正常。本文通过构建卷积自动编码器(一种基于重构的深度学习模型)来训练异常检测器。在现有的研究中,这种异常检测技术已用于其他领域,例如,纺织物表面的缺陷检测,交通控制和监视的视频监控,及从热图像中异常温度区域的检测。其他基于重构的深度学习模型也可用于异常检测。例如,变分自动编码器(VAEs)、生成对抗网络与其扩展已广泛应用于临床成像和航空安全检查。但是,在使用这些高级模型进行异常检测具有一定的局限性。训练深度生成模型时,模式坍塌经常发生。此外,生成器仅能够生成有限种类的样本,导致分类器可能无法区分正常样本和异常样本。HENDRYCKS[14]等提出VAEs和其他深度生成模型学习的概率分布可能无法对训练数据的真实可能性进行建模。因此,根据CHOW[15]等提出的内容,本文决定应用卷积自动编码器对公路路面病害进行异常检测。主要特征描述如下。
卷积自动编码器是一个编码器-解码器网络[16]。编码器从输入数据中学习并提取有用的特征,然后解码器对编码后的特征进行反向映射,从而重建输入数据。编码后得到的特征维度(也称为瓶颈)通常比输入维度小得多,以防止卷积自动编码器直接复制。利用大量的正常类图像,对卷积自动编码器进行训练,以使其尽可能完整地重建正常实例。由于没有事先学习任何异常特征,这种训练会导致公路路面病害的重建效果不佳,重建误差较高。
在编码器中,将输入数据输入连续的卷积块,并在每个下采样步骤中将通道数量加倍,以增强编码特征。在出现瓶颈(也称为代码/潜在空间,即具有50个神经元的全连接层)之前,将特征图展平并下采样到具有100个神经元的全连接层,使特征之间具有良好的一致性。解码器是编码器的反向操作,逐步执行上采样以重建输入数据。在最后一层引入双曲正切函数,将每个神经元的值压缩到-1和1之间。
对于每个像素,计算输入和输出(即重构的输入)之间的平方差,以评估重构质量。这种误差称为重建误差e:
(1)

为了人为地创建不同比例的图块,增强深度模型学习的特征,本文在原始训练数据集(即约200张高分辨率图像)中,应用无重叠的滑动窗口将图像裁剪为不同大小的较小正方形块(256×256、384×384、512×512和768×768像素),然后将所有图块重新缩放为256×256像素。选择正常类别的样本作为异常检测的训练数据集(剩余的公路路面病害图块用于分类器的监督训练)。该训练数据集由约42 000个256×256像素的图块组成。训练数据还包括公路路面中可能发现的其他物体。
根据RONNEBERGER[17]等的方法,利用镜像技术将图块放大到320×320像素(即卷积自动编码器的输入大小),以确保在后续测试阶段中无缝生成异常图。将每个像素的值归一化为-1.0到1.0之间,然后为模型训练准备图块。选择均方误差即图块重建误差的平均值作为损失函数,并选择ADAM[18]作为优化算法以最小化重建损失。由于卷积自编码器会尽可能完美地重建训练数据集(即正常类),因此无需采用过多的正则化。一旦损失值收敛并变得稳定,训练过程就完成了。根据上述设置,该训练过程大约花费12 h。由于标签就是图像本身,该训练属于无监督训练过程。因此,对于这种费力且视觉密集的标注任务,可以节省大量的时间和人力。
在测试阶段,将滑动窗口应用于测试图像,使其达到所需的尺寸,然后重新缩放为256×256像素的图块。将裁剪的图块进行放大和标准化来生成异常图,其中每个像素代表重建误差。然后进行拼接以生成整个图像的异常图;整个测试过程不到一分钟即可生成高分辨率图像(3 456×5 184像素)的异常图。
3.2 异常提取
得到异常图后,需要根据异常分数来确定如何分割和提取图块中的公路路面病害。一方面,如果将阈值设置得太高,可能会出现分割不足的情况,其中提取的公路路面病害可能会分散并且不完整。另一方面,如果将阈值设置得太低,可能会导致过度分割,从而浪费计算资源和时间。
由于在不同测试位置上公路路面病害的属性大不相同,随机选择异常分数作为阈值的方法是无效的。本文根据异常分数计算得到多个阈值,以促进可疑公路路面病害的异常提取。结合局部阈值(基于单个图像,TL)与全局阈值(基于整个图像数据集,TG)来提取病害图块,并过滤正常的公路路面图像。以正常公路路面图像为例,无论局部阈值取什么异常分数,都只能提取几个图块。因此需引入全局阈值,以避免不必要的信息影响后续数据分析。
根据CHOW[15]等的研究,全局阈值TG的值对于不同的训练数据集可能有所不同,本文根据训练集的异常分数分布将TG默认值设为0.5。首先对图像的所有像素的异常分数进行排序,然后选择与要求的百分位数相对应的异常分数,如下所示:
(2)
其中,APG代表百分位数PG的异常得分;ni代表图像i的总像素;N代表图像总数。如果APG大于默认TG值,则更新TG值。接下来,根据所有像素的异常分数确定TL,如下所示:
(3)
其中,PL代表用于计算TL的选定百分比;n代表图像的总像素。然后,为了降低阈值,确保提取的图块数量与实际有病害的图块数量之间达到最佳平衡,借助降低系数α(0<α<1)将TL与TG进行比较来确定最终阈值T。根据异常分数确定阈值T的过程概述如下:
① 将TG的默认值设置为0.5。
② 根据选定的百分位数PG计算APG。
③ 如果APG大于默认值,则更新TG值。
④ 根据选定的百分位PL计算TL。
跟吴梅见面回来,心里莫明其妙地烦。恰好吃饭时,伟翔说了句这个菜有点咸了,我便啪地把筷子扔在了餐桌上,我说:“李伟翔,你把我林薇当成老妈子了吧?”
⑤ 判断是否有TL>αTG。如果式子成立,选择TL作为阈值T,否则,选择TG作为阈值T。
在确定阈值T的值之后,将图像划分为大小相等的正方形块(例如256×256; 512×512像素)。如果图块中一个像素的任何异常分数大于T,则提取对应的图块以进行后续公路路面病害分类。
3.3 公路路面病害分类
智能检测流程的最后一步是公路路面病害分类。构造分类器并对其进行训练,可以将图像分为3类,即无病害、开裂和剥落。
3.3.1标签准备
与之前的异常检测类似,在标注标签之前,将高分辨率图像裁剪为不同的尺寸,即256×256、384×384、512×512、768×768像素,再重新缩放为256×256像素(即分类器输入层的尺寸),以便针对不同的比例创建公路路面病害的图块,并使分类器具有适用性。由于放大的图块不能适当代表公路路面病害的特征,本文没有使用小于256像素的图像。例如,放大的图像可能过于黑暗导致无法分辨物体,继而在分类过程中引起混乱。接下来,为每个裁剪的图块分配一个标签,整数值0、1和2代表无病害、开裂和剥落;图2中给出了每个类别的示例。总共标注了18 165个图块,其中无病害、开裂和剥落的比例为4∶3∶3。仅将无病害图块的一部分(即约42 000个图块中的7 266个)用作公路路面病害分类的训练数据集,以避免不平衡数据集对分类性能的严重影响。
3.3.2网络架构
在训练深层神经网络时经常会遇到衰退问题,导致较大的训练和测试误差。这是因为存在梯度消失的问题,使得在反向传播时模型不能进行优化。为了解决此问题,ResNet提出了残差学习的概念,当某一层的损失值开始增大时,在后面的层与层之间添加恒等映射,避免模型衰退。通过将上一层中的重要信息传播到下一层,增强了网络的表示能力,从而最大程度地减少信息损失并保证训练的准确性。此外,为了避免使用过多的参数,ResNet中广泛采用“瓶颈”结构来呈现深层网络。用1×1、3×3和1×1的3层卷积结构替代常用的2个连续的3×3卷积层。在本文中,考虑到计算资源和所需的训练时间,采用了由50个卷积层组成的ResNet-50。
3.3.3模型训练
应用5折交叉验证来评估和验证ResNet-50在分类公路路面病害方面的性能。将图像数据集划分为5个大小相等的子集,并且在每次训练中选取其中一个子集用作验证数据集。即验证集是一个子数据集(即3 633个图块),而训练集是其余的4个子数据集(即14 532个图块)。然后在k个交叉验证中,选取性能最好(即验证集损失值最低)的模型来作为智能检测的分类器。
在模型训练之前,为了便于数据归一化,分别计算训练集和验证集的均值和标准差。除了应用不同的裁剪规模外,为了进一步提高分类器的鲁棒性和适应性,本文还进行了实时数据扩充,在将图像发送到ResNet模型之前立即实施数据扩充。为了增强对不变表示的学习,通过几何运算和谱运算将训练数据集的图像进行随机变换,使分类器在每个时间点都使用不同的不变图像数据集进行训练。比如,首先对图像进行水平或垂直的随机翻转,再随机旋转90°。然后,通过在适当范围内随机调整其对比度、亮度和锐度来对图像的光谱空间进行扰动。最后进行归一化,即用均值减去变换后的图像,然后除以标准差。
此外,本文标签采用的是独热编码,将标签的数值转换为具有3个元素的一维向量。例如,将开裂图像的标签(数值1)转换为向量(<0,1,0>)。这表示图像属于开裂类别的概率为1.0,而属于其他2个类别的概率为0.0。这样的变换可以将分类器的预测结果与转换后的标签进行比较,从而利用反向传播以优化模型参数。
损失函数采用分类交叉熵(CC)。将每个类别标签的损失之和作为图像的损失值,如下所示:
(4)
其中,l=0、1和2代表无病害、开裂和剥落的类别;yl表示类别l的独热编码标签;p1表示分类器预测的属于l类的概率,因此p0+p1+p2=1.0。本文采用小批量训练,并使用ADAM[18]作为优化算法。为了确保结果平滑收敛,将初始学习率设置为0.001,且每10次迭代学习率会以0.9的基本因子呈指数衰减。此外,为了降低性能在迭代过程中对权重的严重依赖、改善通过网络的梯度流、正则化分类器,在每个卷积层之后立即应用批处理进行归一化[15]。在分类器中还应用了Dropout[21](比率为0.5)和L2正则化(比率为0.000 1)来防止过拟合。
3.3.4模型验证和测试
每次在模型训练之后需进行一次模型验证。与训练阶段不同,这一阶段没有数据增强和模型优化,将归一化后的原始图块逐个输入到分类器中来计算分类交叉熵和精确度。根据验证集损失值来决定是否终止训练过程,如果验证损失值在连续30次迭代训练中都没有降低,则终止模型训练。选取具有最小验证集损失值的模型作为最佳模型。每次训练和验证过程约耗时3 min。
除了考虑异常提取中检测到的可疑公路路面病害,测试阶段与验证阶段类似。为了得到图像属于无病害、开裂或剥落的概率,将归一化的图块依次发送给5折交叉验证得到的5个分类器。然后,概率值最大的类就是图块最有可能属于的类。分类结果如图3所示。

图3 裂缝图像识别结果
3.3.5分类器性能评估
一次交叉验证的损失值和平均精确度的变化如图4所示。尽管训练阶段的损失值持续减小,但为了确保不会发生严重的过拟合,本文选择最小验证损失处的权重参数。此外,本文总结了交叉验证所有折的每个类的验证精确度。其中,开裂和剥落的分类性能较好,分别在94.2%~96.1%和92.8%~94.5%范围内。然而,无病害类别的准确性略低,约为90.6%~92.8%。这是由于图像子集包括不同照相距离、照明和拍摄角度获得的无病害图像和不同公路路面中的物体图像,子集较为复杂。

图4 一次交叉验证的损失值和精确度变化
3.4 应用实例分析
公路路面病害识别的最终目的是对路面病害信息进行统计和汇总,为公路路面的养护提供充足的数据支持。因此,为了分析本文提出的基于深度学习的路面病害智能化检测系统的有效性,本文对长沙市内多条城市道路主干道(云栖路罗家嘴立交桥至长潭高速路段)进行了深度学习病害检测。为了对检测结果进行对比,同时对该路段进行了人工视觉病害检测。所识别的路面病害结果样例见图 5。

(a) 开裂识别结果
表1与表2所示为路面开裂和剥落的检测结果,其中人工检测对开裂和剥落同时进行,因此根据开裂和剥落的比例计算分别的耗时;智能检测耗时包括采集的数据进行处理、模型训练和测试的全过程。对比结果中人工检测和智能检测结果可得:
a.人工检测和智能检测结果基本一致,各项检测指标准确率误差不超过10%,满足我国工程检测的需求。相比于人工检测,智能检测耗时更短,且不会影响正常公路交通。

(b) 剥落识别结果
b.与人工检测结果相比,智能检测结果相对粗糙,但准确率仍高于90%。造成误差的原因主要包括:① 沿途拍照获取数据集不够全面;② 部分病害特征提取不完整,尤其是部分病害图像。

表1 开裂病害统计结果Table 1 Statistical results of cracking类别准确率/%耗时/h人工检测9949智能检测92.416
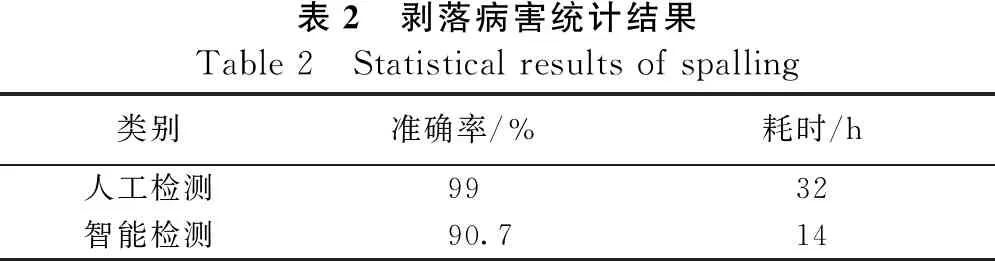
表2 剥落病害统计结果Table 2 Statistical results of spalling类别准确率/%耗时/h人工检测9932智能检测90.714
4 结论
本文提出了一种基于深度学习的公路路面病害智能化检测系统。首先,拍摄了200张公路路面病害图并通过裁剪将图像转化成256×256像素的图块,以此为训练集。整个公路路面病害检测系统包括3个阶段:异常检测、异常提取和公路路面病害分类。在异常检测阶段,构建卷积编码器从大量公路路面图像中提取出病害图。然后,在异常提取阶段,利用阈值分割法提取公路路面病害特征。最后,在公路路面病害分类阶段,利用ResNet结构训练模型来确定公路路面病害所属的分类。结果表明,该方法一次模型训练约3 min,且分类准确率在90%以上。对公路路面的实例研究表明,本文提出的智能化检测方法可以大量节约人力,并提高检测效率。
