基于生成对抗网络的音频补偿方法
2022-12-02观元升胡文林
王 杰,观元升,胡文林
(1 广州大学 电子与通信工程学院, 广东 广州 510006;2 中国铁路设计集团有限公司 城市轨道交通数字化建设与测评技术国家工程实验室,天津 300308)
音频补偿(audio inpainting),即对受到非期望的局部损失影响的音频进行修复工作[1]。音频的局部损失可能来自记录过程中的误操作、传输过程中的数据丢失或储存器件的损坏等不可逆损坏,进而导致音频的时间片段缺失或频域局部缺失。音频补偿算法的目标是对带有这些缺失的音频片段进行连贯、无失真的修复。
音频补偿也被称为音频插值、音频推测、音频修复或波形替换。在音频补偿尚未得到正式定义前,就已经有研究者尝试对丢失音频进行填补。最初较为成功的方法之一是对丢失的音频样本进行时域插值,例如Janssen等[2]提出了一种自适应插值方法,将音频信号建模为自回归(auto regressive,AR)过程,即设计丢失样本的估计与恢复信号的AR系数进行函数最小化,该方法可成功填补45 ms左右的音频间隙。Adler等[1]提出基于稀疏性的音频补偿方法,基于时频变换中音频信号的能量通常集中在相对较低的变换系数区域,该方法利用短时傅里叶变换(short-time Fourier transform,STFT)获得具有稀疏表示的信号,并用该信号来修复间隔,文中使用正交匹配追踪(orthogonal matching pursuit,OMP)来寻找信号。近年来也出现了非局部结构(non-locals structures)相似性搜索稀疏表示[3],或使用稀疏表示统计先验信息[4]的一些匹配方法。这类音频补偿算法具有结构简单、运算速度快的优点,但修复时长一般仅有几十到一百毫秒。
在利用音频相似性进行补偿的方法中,最成功的是相似图算法(similarity graphs algorithm,SGA)[5],该方法重复性地从输入信号的未损坏部分寻找相关信息,然后将确定片段插入间隙来修复。SGA无须训练,可修复多种类别的音乐或自然声间隙,且修复间隙长达几百毫秒;但SGA性能依赖于待修复音频中是否有重复片段,这导致SGA算法的重建效果不稳定。
语谱图是语音图像化的表示方法,许多研究提出将图像修复领域的神经网络方法用于音频补偿,例如:文献[6]使用深度神经网络(deep neural network,DNN)进行中等时间间隔的音频STFT谱图修复,证明了DNN在音频补偿上的潜力。而文献[7]则考虑基于时频掩蔽的语音修复,使用U-Net网络[8]体系结构来修复STFT谱图,并加入Speech VGG[9](Speech VGG是基于文字分类训练的经典VGG-16体系结构)进而提取STFT谱图中多维语音特征。引入Speech VGG的U-Net网络能有效复原长达400 ms的缺失或扭曲的语音片段。
随着深度学习与神经网络的发展[10],生成对抗网络(generative adversarial network,GAN)[11]作为一种高性能的生成式模型受到极大的关注。而其他音频领域的工作如语音增强、语音合成等已经表明,GAN可以生成几秒钟质量稳定的声音信号,因此研究者也考虑将其应用于音频补偿中。Marafioti等[12]提出TiFGAN(time-frequency generative adversarial network)模型,使用基于语谱图的生成对抗网络进行音乐音频补偿,并展示了时频系数在生成式建模中的潜力。文献[13]的音乐音频补偿不使用STFT等音频特征系数,使用直接基于音频时域信号的双鉴别器Wasserstein-GAN结构[14],两个鉴别器分别提取缺失片段周围可用内容和远离间隙的音频内容,因此丢失数据的修复将利用更多的相关信息。Marafioti等[15]提出的基于音乐补偿的生成对抗上下文网络GACELA(generative adversarial context encoder for long audio inpainting)使用5个并行鉴别器在5个不同时间尺度下处理STFT谱图,已能做到数百毫秒到秒之间长间隔音乐信号的修复。
综上所述,当前研究主要包括3类音频补偿方法:(1)寻找相似音频来填补空白部分的传统建模方法,这类方法可修复时间过短、补偿结果不稳定,且仅适用于重复性高的音乐和自然声;(2)基于语谱图的图像修复方法,这类方法都存在谱图逆变换导致补偿后的音频失真问题;(3)基于GAN的音频补偿方法,该类方法可修复的间隙长度更长且生成质量更稳定,但也仅限于纯音乐音频,尚未涉及语音信号。直接使用GAN针对语音进行音频补偿,学习难度将更大,因为与音乐和自然声相比,语音不仅有音高的差别,还有音素、语义等复杂的语音特征,网络需进行更深层的特征学习。
因此,本文基于GAN的高质量音频生成能力,及其在语音领域学习语义的潜力,进行端到端的语音补偿工作,提出基于GAN的语音补偿网络(speech inpainting generative adversarial network,SIGAN)。SIGAN网络直接以时域语音信号作为输入和输出,以避免语谱图逆变换时因相位不确定所带来的音频失真,旨在补偿长间隙语音,生成与语音特征相匹配、间隙与前后文语义连贯及质量稳定的语音内容。
1 SIGAN网络模型
SIGAN模型结构如图1所示,主要由生成器和鉴别器组成。生成器为前后文编解码器结构,用于接收缺失的语音信号。该结构比以往算法更适用于一维时域语音信号的音频补偿,因为通过编码器记忆间隙前后的可用内容,解码器利用潜在变量及跳跃连接传输过来的编码器信息生成补偿后的语音。此外,在鉴别器中加入语音特征提取模块,加入该模块后的鉴别器将通过音素、音高语音特征信息区分补偿语音和真实语音,从而生成可懂度更高的补偿语音。

图1 SIGAN模型结构
补偿语音能保持较好的音质并具有较高的可懂度是针对人类语音的补偿算法需要关注的重点。因此,本文最终语音补偿的评价指标为多位受试者给出的音质和语音可懂度的主观评分。
1.1 生成对抗网络GAN
目前普遍认为性能最好的音频补偿算法是生成对抗网络。Goodfellow等[11]提出的原始GAN是一种基于博弈理论的网络架构,包含两个同时训练、相互竞争的神经网络:生成器与鉴别器。生成器从随机变量的样本中生成新数据;鉴别器试图区分生成数据和真实数据。在训练过程中,生成器的目标是生成可欺骗鉴别器的假数据,而鉴别器试图学习更好地分类真实和生成(假)数据。
具体来说,生成器须学习使用已知先验分布pz,从目标数据分布px输出生成数据分布为pg的样本。而鉴别器需分辨生成数据分布(pg)的样本是否来自实际分布。在原始GAN中,pz分布通常来自均匀随机噪声向量,取值范围是[-1,1]。通过输入生成样本和真实样本,鉴别器将输出在[0,1]取值范围内的鉴别结果值,指代该样本属于目标数据分布px与生成数据分布pg的概率。GAN的训练过程定义如下:
V(G,D)=Ex~px[logD(x)]+
Ez~pz[log(1-D(G(z)))]。
(1)
式中:G(·)、D(·)分别代表生成器、鉴别器的映射函数;G(z)和x分别是生成样本和真实样本;E为相应分布的数学期望。函数V(G,D)为在博弈中对立优化的目标函数,由生成器最小化、鉴别器最大化得到。该函数确保2个网络在训练期间会相互竞争:生成器生成更多的真实样本,同时鉴别器区分生成样本与真实样本时变得更精确。
GAN的网络结构可以不断改进,例如:鉴别器、生成器数目增加或结构改变,或损失函数修改,但改进的目的都是提高补偿语音质量与减少GAN训练难度。在实验中,基于时域的GAN会出现以下问题:生成语音过度失真,修复部分与前后文信息衔接不连贯;由于语音的高采样率,时域模型需模拟波形的大量数据点,该训练过程难以收敛,生成随机结果,即梯度消失现象。为避免以上问题,并结合音频特性,本文提出的SIGAN对生成器、鉴别器两部分均进行改进。
1.2 SIGAN生成器
音频补偿生成器的作用是根据音频间隙以外的前后文内容,生成无空白间隙的完整语音。本文提出基于前后文编解码器结构的生成器,以编码器结构接收带间隙语音,结合以一维转置卷积为核心的解码器生成补偿语音,如图2所示。

图2 SIGAN生成器结构
在编码阶段,输入带空白间隙的语音送至多个一维扩张卷积层中进行降维和前后文的特征提取。扩张卷积用于提高上下文信息提取的效率,而语音的上下文内容已被证明对语音修复极重要[13]。扩张卷积的机制是将一维输入信号z(i)经过扩张卷积滤波器w(s)运算,产生输出信号
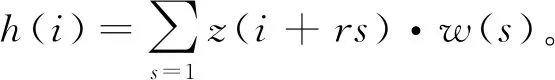
(2)
式中:r为扩张率;s为卷积核大小。扩张卷积s的核大小与普通卷积相同,注意当扩张率成倍增加时,感受野也会增加,以保证能捕捉到信号的更大背景。因此,扩张卷积允许增加感受野大小以捕获更大的上下文并减少计算量;而且扩张卷积在GAN训练中比其他池化操作更为稳定,可生成更平稳的时域语音。
卷积层连接的激活函数是具有泄露修正的线性单元(leaky rectified linear unit,LReLU),该激活函数能有效防止训练过程中出现梯度消失问题。卷积核大小设置为25,阶跃步长选择4,编码阶段每个正卷积层对应的采样点和特征层数在图2中有具体描述。编码结果是待修复语音的特征向量,将其与潜在向量z合并。生成器的潜在向量z为服从均匀分布、由随机均匀噪声值组成的100×1向量,然后输入至全连接层。
解码器使用与扩张卷积相反的转置卷积,结构与编码器相对称。转置卷积来自深度卷积对抗网络(deep convolutional GAN,DCGAN)[16],DCGAN原本应用于图像合成中,对低分辨率特征图进行多次上采样,生成高分辨率图像。而Donahue等[17]改进的一维转置卷积更适合音频合成。因此SIGAN使用改进后的一维转置卷积来对合并特征向量进行逆卷积,卷积层后接修正线性单元激活函数(rectified linear unit,ReLU)。卷积滤波器大小为25×1,滤波器步长选择4。转置卷积最终层的激活函数用双曲正切函数,生成补偿后的完整语音样本。
为进一步提高SIGAN生成器的稳定性,并保证低层次细节不会丢失,SIGAN生成器引入跳跃连接[18]。跳跃连接可将每一个编码层的特征信息直接传递到对应的解码层,使得生成器的输入和输出共享相同的底层结构,即语音非间隙部分的前后文信息,最终可生成长时间的正确语音。
值得一提的是,SIGAN生成器直接生成完整语音,例如单词seven,在缺失了中间的eve后,SIGAN直接生成完整语音seven而不是仅生成缺失的间隙部分eve然后与存留的s-n拼接。这是因为仅生成间隙部分语音会导致补偿语音与前后文的边界信息冲突,导致语音不连续,容易出现语音的语义断层现象;而直接生成完整语音可保证音质和听感的统一,具有更高的语音质量和可懂度。
1.3 SIGAN鉴别器
由生成器生成假语音后,补偿语音与真实语音共同加入鉴别器。鉴别器的工作是区分真实语音和虚假语音,将判断结果传递给生成器,这样生成器就可以修正输出音频,使其逐渐接近真实分布。
SIGAN鉴别器在原始GAN鉴别器层基础上增加语音特征提取模块(如图3所示)。语音特征提取模块由多个神经网络块(block)组成,神经网络块对生成的带空白间隙语音与真实语音进行下采样,即从低到高分别提取语音的低层、高层语音特征与全特征,以更全面的特征信息作为判别标准,进而提高生成器补偿质量。

图3 SIGAN鉴别器结构
图3a中块1、块2和块3为注意力机制神经网络块,其具体结构如图3b所示。神经网络块由扩张卷积、通道注意力模块和空间注意力模块[19]组成,依次沿通道和空间维度计算注意力权重,并与输入特征相乘以实现自适应特征提取,以加强记忆语音中音素的排列组合。通道注意力模块是将特征图在空间维度上进行压缩,在空间维度上进行压缩时,同时使用平均值池化(average pooling)和最大值池化(max pooling)来聚合特征映射的空间信息,用来发现输入波形与其特征图的相同内容。空间注意力模块是在通道维度进行压缩,在通道维度分别进行平均值池化和最大值池化,获得最大特征通道。块4和块5由2个扩张卷积层和单个MaxPooling1D池化层组成,进一步汇总并压缩提取到的语音特征,其扩张卷积步长为2。
普通鉴别器与语音特征提取鉴别器的性能对比如表1所示,表中使用来源于图像处理的平均初始分数(inception score, IS)作为评价指标,IS由补偿语音谱图与真实语音谱图对比计算差异得到,分数越高表示差异越小。IS计算简单,可直接加入模型训练中,以体现训练进程。由表1可知,加入语音特征提取模块使得训练时间缩短,并提高了IS,说明语音特征提取模块确实大幅提升了鉴别器性能。但补偿语音的音高、音素位置与真实语音往往存在差异,这会体现为语谱图间的差异,将导致IS较低,但补偿语音的可懂度仍可能较高,因此IS仅作为训练进程参考。

表1 普通鉴别器与语音特征提取鉴别器的性能对比
语音特征提取模块后连接的判别层由整形层与全连接层组成,对语音特征提取模块传递过来的特征进行整形和判别后,最终生成维度为Sb×1的判别结果向量,Sb为批处理大小。
针对GAN出现的模式崩溃与梯度消失问题,本文采用WGAN-GP[20]作为鉴别器损失函数来解决。包含梯度惩罚的WGAN-GP损失函数可以确保模型避免WGAN权重裁剪所带来的参数集中化等负面影响。
在WGAN-GP中,鉴别器的损失函数通过在计算目标数据分布px和生成数据分布pg之间的Wasserstein距离后新增梯度惩罚项来实现,损失函数为
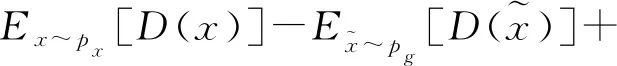
λEm~pm[(|mD(m)|2-K)2]。
(3)

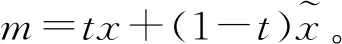
(4)
式中,中间系数t从0到1均匀采样。梯度惩罚项通过利用真假语音样本之间的随机中间值m来限制鉴别器的训练梯度,以保证真假语音样本之间的过渡区域满足1-Lipschitz约束。鉴别器通过WGAN-GP的损失函数充分训练后,其梯度值将在K值附近,能保证稳定训练的前提下拉大真假语音样本在鉴别器中的分数差距,进而对生成器的生成样本质量判别更为分明。
2 实验设置
2.1 数据预处理
本文模型在单个NVIDIA 1080 TI GPU上训练,基于Tensorflow[22]框架实现,网络训练参数为:每次训练以10-4的学习率开始,批处理大小Sb=32,多次实验的训练步控制在8 000,每训练5轮鉴别器更新1次生成器,每300步保存一次模型。对比算法的复现都使用相同的网络训练参数,以保证对比实验合理。
以时域语音作输入输出的端到端GAN网络普遍会输出带噪声的语音,因此本文在SIGAN生成器结构中加入降噪的后处理。语音增强算法使用MMSE谱减法[23],因为该算法运算速度快、无运算负担且能有效提高SIGAN补偿语音的音质。
2.2 主观评价方法
语音补偿算法需要关注的是人类可接受的音质和可懂度,因此更适合采用主观评价来判断算法性能。组织了4名受试者进行听力测试,以评价SIGAN模型的补偿效果。实验前,受试者了解实验的目的和步骤,并收到从0到9的各1个示例性英语单词语音,即发音正确且清晰无杂音的语音。之后对比示例性语音,对训练后的SIGAN模型和其他两个对比模型使用测试集生成的语音进行评分,测试集语音为从0到9的英语单词各10条,因此每位受试者共进行300次评分。
每次评分中,需要分别对补偿语音的音质、可懂度(发音是否准确无误)两项标准进行评估。评估标准参考文献[24],通过失真平均意见分(distortion mean opinion score, DMOS)对补偿语音与示例语音的差异进行分值范围为[1,5]的音质评价。由于本文主观评价基于单词的语音材料,受试者在评价语音可懂度时根据单词中音节组成进行分析。两者具体分值含义见表2。

表2 主观评价等级
3 实验结果及分析
为进一步证明本文提出的SIGAN模型用于语音补偿的优越性,选取TiFGAN[12]和WaveGAN[17]进行相同配置下的语音补偿实验,并与本文提出的SIGAN模型进行主观评价结果对比。
TiFGAN算法是经典的基于谱图的生成对抗网络,网络经训练后生成STFT对数幅度,经STFT逆变换得到生成音频。与该算法的对比可以探讨SIGAN以原始语音作输入输出与基于谱图的算法之间的差异。WaveGAN算法是将生成对抗网络应用于无监督合成原始音频的方法,与本文提出的SIGAN都属于直接在GAN网络中利用时域音频的语音生成方法。
3.1 对比实验的结果与分析
针对原始样本长度为1 s、间隙长度为256 ms的单词,SIGAN与其他模型的补偿语音音质、可懂度的主观评价结果对比如表3和表4,表中数值为所有受试者对该模型输出的对应单词语音的评分均值。评估结果显示,SIGAN网络生成样本的音质平均评分都在3.40±0.30范围内,即滤波后的SIGAN补偿语音已满足多数语音通信系统的使用要求。受试者反映补偿语音部分带可感知的噪声,但语音清晰度仍很好。补偿语音的可懂度平均评分在3.25±0.25范围内,受试者基本都能确定SIGAN的补偿语音是对应的单词,尽管某些补偿语音带有轻微读音错误,SIGAN生成的补偿语音质量稳定同时可理解。

表3 SIGAN与其他模型的音质主观评价结果

表4 SIGAN与其他模型的语音可懂度主观评价结果
对于TiFGAN算法,受试者反映TiFGAN补偿语音中噪声较低,音质仅受限于单词读音失真。这是因为STFT逆变换丢失相位信息会带来元音、辅音共振峰改变等音频失真,但该失真对音频的音质影响不大,所以TiFGAN的音质评分较高,都在3.30±0.15范围内。然而TiFGAN补偿语音的语音可懂度评分明显低于SIGAN,可以看出这类音频失真容易导致音频补偿模型对单词中音素的错误修复,从而影响语音可懂度。因此SIGAN以时域语音作输入输出虽然容易产生噪声,影响补偿语音的音质,但也保证了补偿语音较高的语音可懂度。
而在WaveGAN的主观评价中,受试者反映该模型生成语音不仅带有明显噪声,很多单词读音还带有很多无法理解的读音错误,如six读为sex,seven读为sev,four读为flour,这些音节不是训练集内音节的拼接组合,疑是模型无规律随机生成的产物。因此,WaveGAN的音质和可懂度的总体评分均低于SIGAN。
据澳大利亚广播公司近日报道,目前在南澳的标志性葡萄酒产区─巴罗萨谷,有多达10%的葡萄园和酒庄属于中国人所有。当地一名从事葡萄园收购业务的从业人员表示,他经手的过去7宗收购里有6家酒庄被中国人买去,而目前他们公司接到的咨询电话里面,有大约50%来自中国人以及代替中国人表达收购意愿的团体。
从实验得知,直接针对时域语音进行补偿的算法一般存在两个问题:内容丰富多变的多音节单词较难被补偿;前后文内容很少、读音短暂且无尾音单词的补偿难度大。在这两种情况下,网络生成的补偿语音都会有音质差或可懂度低的问题。本文通过主观评价结果的对比来分析SIGAN网络对这两个问题的改善。
SIGAN针对多音节单词补偿难的改善可由实验中zero和seven的补偿情况验证。如表3所示,SIGAN和WaveGAN中多音节单词zero和seven的音质得分都低于同列的其他单音节单词的得分。受试者反映这两个算法对zero、seven的补偿语音中存在类似电流声的杂音,这可能是“z”“v”等浊辅音的端到端补偿造成的。然而,SIGAN对于zero、seven补偿语音的可懂度评分比WaveGAN提升较大。seven在SIGAN补偿前后的波形图与语谱图如图4所示,对比可知补偿语音能保持较好的还原度。这证明在引入本文提出的前后文编码和解码器及语音特征提取模块后,SIGAN网络比WaveGAN网络利用更多的前后文内容,生成的多音节单词更容易被听众辨认,多音节单词的语音可懂度有较大提升。
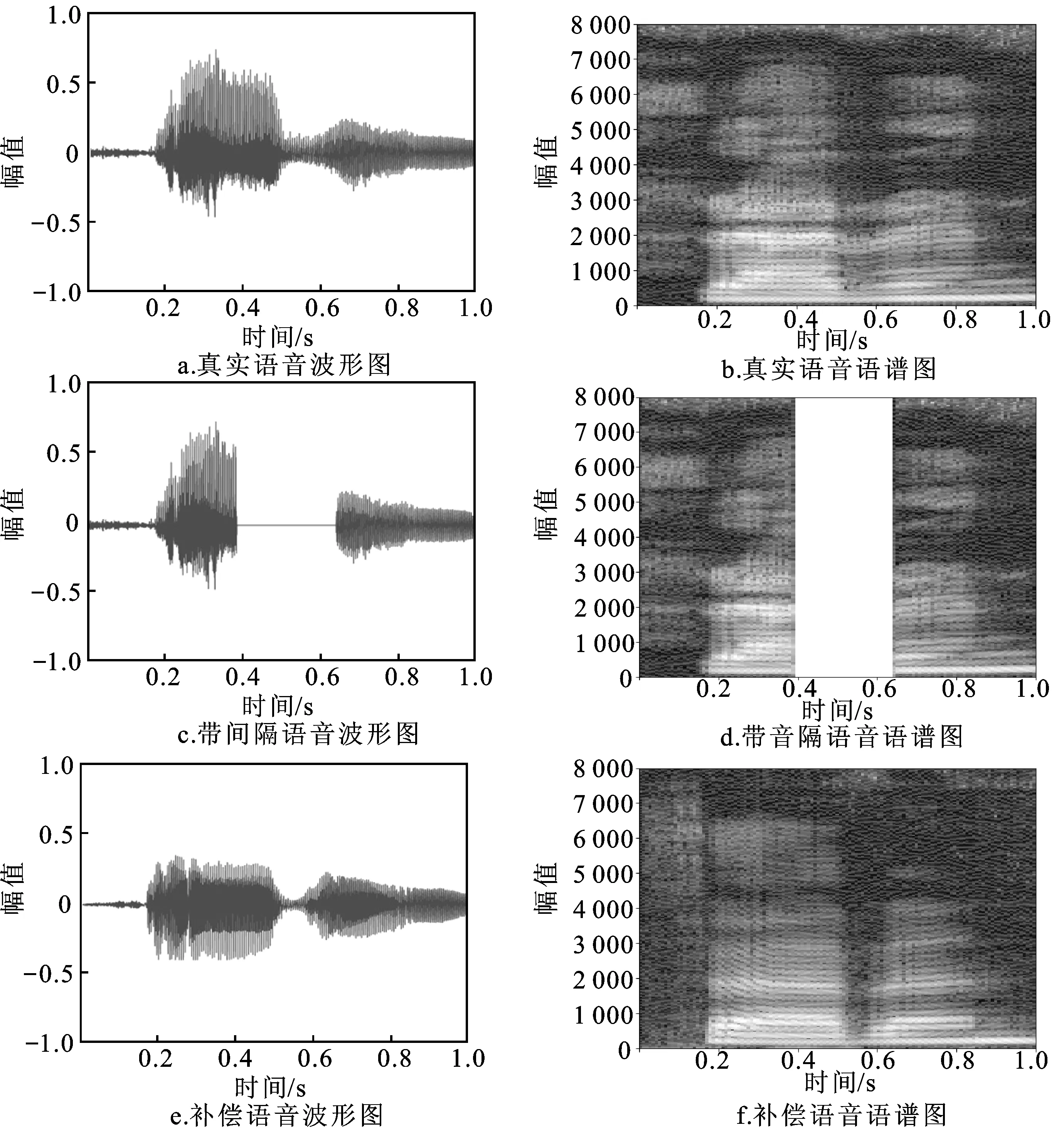
图4 Seven补偿语音与真实语音对比
实验中进一步发现,带间隙语音的前后文内容很少或无前后文内容时,补偿带间隙语音中的空白段并生成相对应的单词较为困难。例如:two和three,这两个单词播放时间很短且没有尾音,语音与间隙的时长可能会一样,前者完全会被后者遮蔽,导致网络无法抓取到前后文内容,最终无法正常补偿。因此,本文对它们的测试集做了一定的筛选:选择上文带较明显首辅音的带间隙语音,例如选择two测试集中首辅音“t”读音明显的语音和three测试集中“th”读音明显的语音。最终的主观评价结果中,two和three的音质评分与可懂度评分与总体评分均值的差距很小。这证明SIGAN网络对于前后文内容很少的语音仍然有效地学习到它们的语音特征并正确补偿。
SIGAN模型从中间过程到训练结束,都未出现过补偿前后说话者性别不一致的补偿语音,即补偿语音与真实语音的语音音高基本相同。这些结果都证明在引入语音特征提取模块后的SIGAN能更有效地捕捉语音中的音素、音高特征。
本文还使用语音质量感知评价[25](perceptual evaluation of speech quality, PESQ)对SIGAN、WaveGAN和TiFGAN模型的补偿语音进行客观音质评价。PESQ通过比较补偿语音与真实语音计算语音质量分数,差异性越大分数越低。如表5所示,SIGAN十条补偿语音的平均PESQ得分高于WaveGAN与TiFGAN得分。

表5 SIGAN的PESQ客观质量评价结果
综上所述,SIGAN在可懂度方面比以往的算法有了实质性的改进,这归功于本文网络使用针对语音的端到端结构,并作出更适合语音补偿的网络改进。
3.2 扩展实验
为验证SIGAN模型在面对间隙长度更大的语音时也能保持较好的补偿能力,扩展实验使用间隙长度翻倍的语音对网络进行训练。为方便与未扩展语音的实验进行对比,该实验的数据集是对整理后SC09数据集进行变速操作,即语音变为原来的0.5倍速。变速后的语音依然为16 kHz采样率,样本长度增加1倍至32 768,间隙长度也由4 096扩大至8 192。
训练集中每个单词的样本数保持与原实验一致,真实语音与带空白间隙语音各10 000个。网络结构基本保持不变,生成器由于其对称性无须变动,鉴别器只需在判别层前新增阶跃步长为2的扩张卷积层。网络参数不变,使用相同的评价方法对其进行主观评价。
扩展后SIGAN补偿语音的语音可懂度主观评价结果如表6所示,扩展后的SIGAN补偿语音的语音可懂度平均评分都在3.70±0.30范围内,明显高于扩展前的总体评分。而扩展后的补偿语音的音质平均评分在3.40±0.20范围内。语音长度和间隙长度翻倍后,音质与1 s样本长度实验相比变化不大,语音可懂度却提升显著。这表明变速后的2 s语音中,单词的读音放慢,语音的特征更加清楚,网络更加容易学习,故间隙长度也随着翻倍,SIGAN依然能有效改善补偿样本的质量。
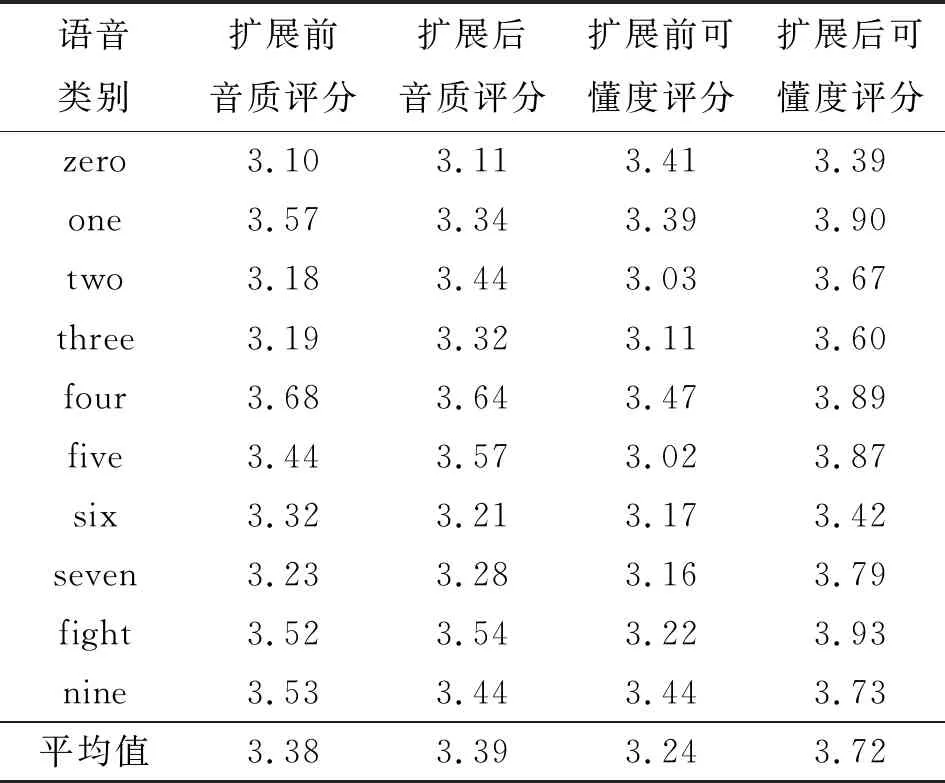
表6 语音扩展后的主观评价结果
原来发音很短暂的单词two和three,前后文内容的增加使其补偿样本的语音可懂度有了较大幅度提升,受试者对扩展前的two可懂度评分均值为3.03,扩展后提升至3.67;three可懂度评分均值也从3.11提升至3.60。总的来说,SIGAN模型在补偿大时长的语音时更有优势,在达到模型可修复的间隙长度最大值之前,间隙长度的增加对补偿语音的质量影响较小[15]。
4 结论
本文提出了基于生成对抗网络的无监督语音补偿模型SIGAN,用于恢复数百毫秒的空白间隙语音信息。SIGAN模型直接以时域语音作为输入输出,着重学习语音间隙前后文中的语音特征,生成与前后文内容相对应的语音。首先,设计了一个对称性的前后文编解码器作为生成器,使用一维的扩张卷积、转置卷积与跳跃连接,使生成器更适合接收并输出音频的时域波形。其次,提出在鉴别器中加入语音特征提取模块,以多个神经网络块组合的结构帮助生成器的输出考虑更多的语音特征。
在与其他算法的客观和主观对比实验中,SIGAN算法的PESQ得分、音质和语音可懂度总体评分均优于现有方法。本文也使用SIGAN对降速后获得的长语音进行了补偿实验,结果发现,更多的前后文内容对补偿语音的质量提升较大,尽管间隙长度增加但可懂度依然能得到进一步的改善,这表明SIGAN模型对高时长的音频补偿仍具有较好的潜力。
SIGAN也还有很多改进的空间,如潜在变量的改进、加入并行鉴别器等方法。未来研究的目标是SIGAN能够更好地学习人类语言中的语义,对多个单词连续组合的长语句音频进行补偿工作。
