面向战场环境下的语音传输与重构
2022-12-01邵玉斌刘晶龙华李一民
邵玉斌, 刘晶, 龙华, 李一民
(昆明理工大学 信息工程与自动化学院, 云南 昆明 650500)
0 引言
电话是人们进行交互的最直接的远程通信方式[1]。然而通信的频谱资源有限,使得语音传输资源紧张[2]。在军事演习或实战中,战场环境下充斥着各种人为干扰和军事噪声,在紧张频谱资源下高效的话音压缩编码和噪声抑制方法将是提高海陆空的信息快速交互和语音质量的重要途径[3]。
Donoho等[4]提出利用压缩感知技术对语音信号进行压缩,可有效提高信号的传输效率,再通过重构算法恢复原始信号,从而能在音频传输时减小频谱资源开销。但是,战场环境下语音信号会带有大量的背景噪声,导致重构语音质量不好[5]。目前,含噪语音压缩感知的重构算法主要有基追踪[6]、匹配追踪算法[7]以及贝叶斯算法[8]等。孙林慧等[9]提出含噪语音信号的自适应基追踪去噪算法;杨真真等[10]提出含噪语音压缩与重构的自适应共轭梯度重构算法;季云云等[11]提出针对脉冲噪声的贝叶斯稀疏重构算法,都能够在一定程度上取得较好效果,但是,这些算法复杂度高,重构时间长。为此,张殿飞等[12]提出压缩感知自适应快速重构算法;马春等[13]提出改进Kalman滤波L1模加速算法的语音信号重构;Kim等[14]提出一种视频编码方案的语音压缩传输方法;Abbas[15]提出了基于离散小波变换和混沌信号的语音压缩算法;Qin等[16]提出了基于贝叶斯压缩感知的数据压缩方法。实验发现,以上方法在高压缩比和低信噪比下重构的语音质量不佳,而且要求重构信号必须具有一定的稀疏性。
本文针对各类战场环境噪声的高压缩比的语音传输与重构进行研究,将语音传输转为图像传输,提出一种基于语谱图压缩传输和重构的方法。首先将语音信号压缩为语谱图进行传输;再在接收端对图像进行去噪;最后根据图像重构出语音信号。实验结果表明,本文方法在一定程度上解决了高压缩比和低信噪比下重构语音质量不佳问题,达到了提高重构语音质量的目的。
1 构建语音传输和接收模型
声音和图像是听觉和视觉上两种模态接收的输入信息,在数字处理领域各自有不同的处理方法[17]。考虑到可以进行视听觉交互融合的方式进行信息交流,本文将语音信号压缩为语谱图信号传输。对语谱图的研究表明:语谱图包含大量的语音学信息,语音学家可以通过语音学知识和发声特征解释语谱图[18]。因此对语谱图进行传输再重构是可行的。
1.1 传输模型
将语音信号压缩为二维灰度语谱图信号。具体流程如下:
1)将语音信号x(n)进行分帧,n为离散信号时间序列,帧长为M,M为偶数,帧移为零,从而压缩图像的大小。再对每帧信号加窗,防止频谱泄漏,采用的是汉明窗,加窗后的第i帧信号为s(i)(n)。
2)将信号s(i)(n)进行短时傅里叶变换后再求功率谱:
(1)
P(i)(k)=|X(i)(k)|2
(2)
式中:X(i)(k)为第i帧信号的离散傅里叶变换后的结果,k为傅里叶变换的第k个频谱,1≤k≤M/2;P(i)(k)为功率谱。由于幅度谱对称,因此取一半求功率谱P(i)(k)。
3)求对数的功率密度谱,定义如下:
(3)

LM ×M2


图1 压缩后的语谱图
1.2 接收模型
由于本文方法应用于噪声环境下的语音传输,语谱图上夹带噪声,而且在信道传输的过程中也会有噪声干扰。因此,本文引入自动色阶算法[19]进行图像增强处理,再逆向还原幅度谱矩阵。具体步骤如下:
1)利用直方图统计语谱图像素矩阵x的像素值,将像素值高于高阈值的部分置为255,将像素值低于低阈值的部分置为0。由于大部分噪声像素值低于低阈值,将低于低阈值部分置为0,从而实现对噪声的抑制。像素值在高低阈值之间采用线性量化的方法重新分配像素值,使图像更具有层次感和目视效果。阈值定义如下:
Mmin=max (x1),x1(n)=x0(n) 1≤n≤K×α
(4)
Mmax=max (x2),x2(n)=x0(n)
1≤n≤K×(1-β)
(5)
式中:Mmax为高阈值;Mmin为低阈值;x0为总像素值从小到大排列向量;x1为低于低阈值的向量;x2为高于高阈值的向量;α、β为可控色剂因子取值;K为像素点的总个数。“可控色剂因子”指的是控制高低阈值大小的可调节因子,将第K×α个像素值设定为低阈值和第K×(1-β)个像素值设定为高阈值。线性量化的公式如下:
(6)
式中:s为阈值之间的像素最大值;l为阈值之间的像素最小值;Rz为高低像素阈值之间的像素值;R为量化后的像素值。图2为不同噪声源5 dB语音原始语谱图和采用自动色阶算法增强语谱图的图像,可控色剂因子α=0.7、β=0.005。从图2中可以看到噪声明显减弱,语义信息凸显。图2中,噪声代号说明:N1为白噪声,N2为粉红噪声,N3为高斯信道噪声,N4为军用车辆噪声,N5为F16驾驶舱噪声,N6为机枪噪声,N7为攻击机驾驶舱噪声,N8为驱逐舰作战室背景噪声。

图2 原语谱图和增强后的语谱图
2)将增强后的像素值矩阵转换为对数功率谱矩阵,公式如下:
(7)

LM ×M2
式中:P′dB为转换后维的增强对数幅度谱矩阵;R为增强后的像素值矩阵;ε为对数能量的显示范围;η为最小的显示范围的绝对值。
3)将对数功率谱矩阵转换为幅度谱矩阵,公式如下:
(8)
式中:P2为转换后的幅度谱矩阵;PdB(j,i)为矩阵第j行第i列的对数幅度值。
2 语音重构模型
语音的频谱由相位谱和幅度谱两部分组成,缺少任何一部分还原到时域时,会导致语音质量下降。在1.2节中已经得到语音的幅度谱矩阵,因此只需要重构出相位谱即可得到语音信号。本文提出正弦模型(SM)、噪声模型(NM)、发声模型(VM),分别对语音进行重构。
2.1 正弦重构模型
由于绝大多数周期信号均可以分解为一至无数个不同频率的正弦信号,本文考虑采用正弦信号进行语音重构。具体步骤如下:
(9)
式中:Z为组合正弦信号。
2)将组合正弦信号进行分帧,帧长为M,帧移为0。得到分帧后的矩阵Z1。
3)用(8)式得到的幅度谱矩阵对Z1进行变换,公式如下:

Z2(j1,i)=Z1(j1,i)×P3(j1,i),1≤i≤ LM ,
1≤j1≤M
(10)
(11)
式中:替换:Z2(j1,i)为第j1行第i列变换后正弦矩阵数值;Z1(j1,i)为正弦矩阵的第j1行第i列的数值;P3(j1,i)为对称幅度谱矩阵的第j1行第i列的数值;P4为P2上下翻折所得到的矩阵;P3为上下对称的的矩阵。将调整的Z2逆分帧得到重构语音信号序列Z3。
2.2 噪声重构模型
高斯信号近似等于无数个相位和幅度都是随机的正弦信号叠加的结果,在频率上是连续的,从而更好地模拟声道中的气流,因此可以采用噪声进行信号重构。具体步骤如下:
1)产生采样率为fs,长度为L的零均值单位方差高斯白噪声信号序列Y(n)~N(0,1)。
2)对Y(n)进行分帧处理,帧长为M,帧移为0,得到分帧后的矩阵Y1。
3)用(8)式得到的幅度谱矩阵对Y1进行转换,公式如下:
Y2(j1,i)=Y1(j1,i)×P3(j1,i)
(12)
式中:Y2为变换后的矩阵。通过对Y2逆分帧得到重构的语音信号Y3(n)。
2.3 发声重构模型
长期研究表明,语音信号可以视为由激励模型产生的信号,通过声道模型和辐射模型的级联产生的[20],因此采用发声模型可以重构出语音信号。具体步骤如下:
1)语音信号具有短时平稳性,因此(8)式得到的幅度谱估计每帧的单脉冲响应,作为声道模型FIR滤波器。先求取对数幅度谱,公式如下:
P5(j,i)=10lgP2(j,i)
(13)
式中:P5为对数幅度谱。再对P5作离散余弦变换得到P6,这样方便将声门激励和声道激励分离。以倒谱中的第λ=25条谱线为界,用1~25区间构建声道冲激响应倒谱矩阵,公式如下:
(14)
式中:P6(j)为矩阵的第j行;G为声道冲激响应倒谱矩阵。对G进行逆离散余弦变换得到声道冲激响应频域矩阵G1,对矩阵G1取反对数,再进行翻折变换,公式如下:
(15)
(16)
式中:G2为反对数后的声道冲激响应频域矩阵;G3为G2上下翻折后的矩阵;G4为上下对称矩阵。再对G4进行逆傅里叶变换取实数部分,得到声道模型全极点滤波器矩阵G5。图3为声道滤波器冲激响应在一帧内的波形。

图3 一帧单脉冲响应波形
为了加快计算效率,对每帧256点取冲激响应最高峰128点左右能量集中的部分,本文取经验值[67,190]之间的冲激响应点数,该范围的能量占总能量的96%,构造新的冲激响应矩阵G6。
2)根据倒谱法估计清音浊音,浊音的倒谱中可以清晰地看到基音峰突出,而清音的倒谱中基本没有出现基音峰。因此可以(8)式得到的幅度谱矩阵估计出清音和浊音,从而采用不同脉冲激励声道模型。先对P5作逆傅里叶变换得到倒谱域矩阵P7,浊音和清音估计公式如下:
(17)
式中:P7(i)为矩阵的第i列数据,即第i帧数据,1表示该帧为浊音,2表示该帧为清音。max(|P7(i)|)-min(|P7(i)|)为最大峰与最小峰的差值。

1× LM
3)采用倒谱法估计基音周期。如果对数振幅频谱包含许多规则间隔的谐波,则频谱的傅立叶分析将显示一个与谐波之间的间隔相对应的峰值:即基频。从而得到维的基音频率序列J。

1×( LM ×M)

1×( LM ×
4)再采用三次样条插值法生成帧与帧之间更加平滑的维的基音频率序列J11。然后将生成的序列通过压控振荡器生成M)维的脉冲压控信号J1。
5)研究表明声带振动类似于斜三角脉冲[20],因此将生成的J1的冲激部分采用斜三角波形替代,斜三角波形公式如下:
(18)
式中:N1=4,N2=5,替代后的压控信号序列为J2。图4为一帧压控输出信号的波形。

图4 一帧压控输出信号的脉冲波形
6)通过不同脉冲去激励声道模型,如图5所示。

图5 发声重构模型
其中,J3(i)为矩阵的第i列数据,J3为J2分帧后的压控信号序列矩阵,Q(i)=1即该帧为浊音,采用压控信号序列脉冲激励该帧声道模型,Q(i)=2即该帧为清音,采用高斯噪声脉冲激励该帧声道模型。从而得到语音信号分帧矩阵Z3,进行逆分帧得到未经过辐射模型的语音信号序列Z4。
7)声道模型相当于两次低通滤波,导致高频部分弱化,因此需要经过辐射模型提高高频部分,从而得到重构语音信号序列Z5。本文采用高通滤波和预加重组成辐射模型提高高频部分。
3 实验设计与结果分析
3.1 实验设计
本实验在MATLAB2019R上进行仿真,硬件的配置为Win10,运行内存为8 GB,处理器Intel-i7-4710MQ。语料为中国广播电台的音频,每段音频为10 s,采样率为8 000 Hz,16位单通道的wav格式汉语音频。分别与白噪声、驱逐舰作战室背景噪声、军用车辆噪声、高频信道噪声、粉红噪声、F16座舱噪声、攻击机驾驶舱噪声和机枪噪声构造SNR=[0 dB,5 dB,10 dB]带噪语音,噪声来源于Nonspeech公开噪声库。重构语音质量采用客观平均意见得分(PESQ)作为评价指标,PESQ分取值范围为-0.5~4.5,PESQ是由P.862的PESQ程序对比原始语音与重构语音打分得出的。语音传输采用的是压缩比[21]作为评价指标。去噪效果采用的是平均信噪比(ASNR)作为评价指标。压缩比的计算公式如下:
(19)
式中:F为压缩前的信号大小;CR为压缩后的信号大小。平均信噪比定义如下:
(20)
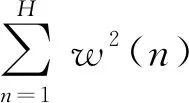
3.2 实验结果分析
3.2.1 不同帧长下重构语音质量
先验证不同帧长下语谱图重构的语音质量,选取M=64和M=256分析本文提出的3种不同重构模型的差异。根据(21)式计算出语音数据量为160 kB。待重构语谱图分辨率为312×128,量化位数为8,实际大小约为15.1 kB的jpg格式的图片,根据(19)式计算可得ρ≈10。
(21)
式中:f为语音的采用率;d为量化位数;s为声道数;t为语音总时间。
图6为原始语音波形和语谱图及3种重构模型不同帧长下重构语音波形和语谱图。表1为3种重构模型平均意见的得分。

图6 原始语音和重构语音的波形及语谱图

表1 3种方法重构语音的PESQ分
从图6和表1可知,发声模型重构的语音质量高于其他两种方法。由于发声模型是基于人的发声方式重构的,可以很好地重构出清音和浊音,相位和幅度都高度重构,从而使得听觉上更优于其他两种方法,本文采用讯飞语音识别软件,精确识别出了语音的内容。噪声重构模型的优点是不存在卡顿和无声调发声现象,这是因为在频率和时间上断层被噪声所弥补,从而稍微平滑,但是一直伴随着少量的噪声存在。正弦模型的优点是可以很好地重构出语音的波形和语谱图,但是在M=64时,频率上存在断层,导致语音没有声调;M=256时,时间上存在断层,导致语音出现卡顿现象,但是在听觉上依然很清楚。由于M=64时,语音声调总体质量不如M=256,因此本文后续在M=256上进行实验。
3.2.2 不同压缩比下重构语音质量
为了验证本文方法无噪语音条件下,不同高压缩比重构语音质量。下面分别采用文献[6]基追踪、文献[22]快速重构算法(FRAT)、文献[12]自适应快速重构算法以及本文提出的3种重构模型对压缩比为ρ≈10和ρ≈40的语音进行重构。压缩比ρ≈10选取的语谱图分辨率为312×128,约为15.1 kb的jpg格式的图片,压缩比ρ≈40选取的语谱图分辨率为156×64,约为3.8 kb的jpg格式的图片。实验结果如表2所示。

表2 6种方法重构语音的PESQ分
从表2中可以看出,在高压缩比情况下,对比方法几乎无法重构出语音信号。而本文提出的3种方法都可以相对较好地重构语音信号。ρ≈40时,接收到传输的语谱图后,采用临近插值处理的方法将分辨率156×64的语谱图转换为分辨率为312×128语谱图,再进行语音重构,因此相对于ρ≈10时,语音质量有所下降,从而证明了本文方法在高压缩比下有效。
为了验证噪声环境下不同方法重构语音的平均信噪比的大小。在压缩比为ρ≈10,信噪比为10 dB的语音信号条件下对语音进行压缩重构。实验结果如表3所示。

表3 6种方法重构语音的平均信噪比
从表3中可以看出,在噪声环境和高压缩比下,对语音进行重构,对比方法重构的语音的平均信噪比低于原始信号的平均信噪比,是由于噪声和抽样的数据不足导致重构不理想。而本文提出的3种重构方法较原始语音信号在平均信噪比上都有些许提高,由于本文采用了图像传输的方式,在提高压缩比的同时,尽量减少了语音信号的抽样,而且还采用了图像去噪算法进行噪声抑制,从而证明本文方法在噪声环境下的进行语音重构有效。
3.2.3 不同信噪比下重构语音质量
由于对比方法在高压缩比下,基本无法重构语音,下面仅验证本文3种方法在不同噪声环境的不同信噪比下,压缩比ρ≈10的条件下重构的语音质量。分别测试在8种不同噪声源下,不同信噪比环境下的语音重构质量。实验结果如表3所示。表3中噪声代号与图2相同。
从表4可以看出,本文提出的3种重构模型在白噪声、粉红噪声、高斯信道噪声重构语音质量最优,在F16战机噪声和攻击机驾驶舱噪声环境下,重构的语音质量稍微有所下降,在驱逐舰作战背景噪声环境下,重构语音质量相对较差,机枪噪声和军用车辆噪声环境下重构语音质量最差。结合图2可知,频率上均匀分布的噪声采用自动色阶算法可以很好地被抑制,从而得到较好的重构效果;噪声在频率上分布较为集中的情况下,导致图像处理后,依然存在小部分噪声存在,导致重构质量下降;噪声大部分分布在频率段较低的位置时,由于语音信号主要集中在中低频部分,采用图像处理的方法无法很好地抑制噪声,导致重构出的语音依然存在噪声的影响,导致语音质量差。从重构方法分析,在噪声环境下,发声重构模型效果最差,由于噪声影响导致语音的相位无法较好地重构,从而使得随着信噪比的降低重构语音质量急剧下降。正弦重构模型次之,随之信噪比的下降,无法将噪声全部抑制,导致重构出的语音具有滋滋声,从而影响听觉,导致语音质量不佳。噪声重构模型最佳,由于图像处理后语音较弱的部分被噪声间接增强,卡顿部分被噪声衔接上,导致滋滋声不明显,从而提高了重构语音质量。

表4 不同方法重构语音的PESQ分
3.2.4 不同方法重构语音时间
采用AFRAT、以及本文的提出的三种重构方法重复实验10次,对比AFrat、SM、NM、VM4种重构模型的重构语音时间对比。实验结果如表5所示。

表5 4种方法重构语音时间
从表5中可以看出:VM模型重构时间最短,由于只存在卷积运算,而且只取部分有效脉冲响应,从而重构速度快;NM的重构速度次之,由于NM重构模型存在矩阵运算,相对于VM模型,重构速度稍慢;SM模型相对于NM模型,由于SM有多个矩阵运算,导致重构时间增加很大;AFrat模型随着语音信噪比的增大,重构时间增大,由于AFast模型选择的原子个数接近于稀疏向量的行数,从而导致的浮点计算增大。
根据上述实验结果及分析可知,在高压缩比和不同噪声源下,本文提出的噪声重构模型具有较好的重构性能;在高压缩比和无噪环境的情况下,本文提出的发声重构模型具有较好的重构性能。
4 结论
本文针对高压缩比和战场环境下语音重构性能差甚至无法重构的问题,提出了一种基于图像传输处理的语音传输重构一体化模型。根据声音和图像是听觉和视觉两种交互形式,将语音转换为内存更小图像进行传输;考虑到战场环境噪声复杂,引入图像增强技术,抑制环境噪声;最后根据不同的重构模型进行语音重构。实验结果表明:高压缩比及无噪的情况下,基于发声重构模型具有很好的重构性能;在高压缩比及噪声环境下,基于噪声重构模型能较好的重构出语音信号,语音质量也能达到人耳接受范围。后续继续在高压缩比以及语音重构质量上进行提高,实现传输和重构一体化智能系统。
