基于视点差异和多分类器的三维模型分类
2022-11-29范宇飞何勇军
丁 博 范宇飞 高 源 何勇军
(哈尔滨理工大学计算机科学与技术学院 哈尔滨 150080)
1 引言
近年来,随着3维成像传感器和3维重建技术的发展,人们可以从生活中便捷地捕获大量的3维物体结构信息。同时,计算机网络的发展进一步促进了3维模型呈指数型增长,其多样性与复杂度更是显著提高。越来越多的3维模型数据集可供研究者分析,也为数字几何处理带来全新的挑战[1]。目前,3维模型分类作为3维数据分析的基础,已经成为计算机视觉领域的一个重要研究方向。
3维模型的多视图表示结合深度学习成为该研究方向的一个热点。卷积神经网络通过一系列的卷积池化操作可以很好地表达图像特征信息,因此被广泛用于基于视图的3维模型特征学习中[2]。基于多视图的3维模型分类方法可以分为两大类:基于多视角特征结合特征级融合和基于独立视角特征结合决策级融合。特征级融合是将各视角下的视图通过特征编码融合为一个特征,通常又称特征描述符。决策级融合重点在于将每个独立视角表示成对应的视角特征。利用视角间空间位置关系提升特征描述能力,进而进行分类[3]。
在特征级融合方面,Su等人[4]提出了多视角卷积神经网络(Multi-View Convolutional Neural Networks, MVCNN),可使用View-Pooling层对一个对象的多个渲染视图表示为形状描述符。然而View-Pooling层只保留特定视图中的最大元素,忽略了连续视图序列中包含的上下文信息。为此,Liu等人[5]提出了语义和上下文信息融合网络(Semantic and Context Information Fusion Network, SCFN),对每个视图的特征提取都加入了软注意力机制,且采用3D CNN融合多视图的上下文信息,增强了网络对输入变化的敏感性。多重判别和成对卷积神经网络(Multiple Discrimination and Pairwise CNN,MDPCNN)将Slice层和Concat层加入到网络中,可以同时输入多批次和多个视图,采用对比损失与对比中心损失优化网络,加快了网络的收敛速度[6]。FusionNet方法结合体素和多视图表示3维模型,然后用CNN提取模型特征后分类[7]。Liu等人[8]提出的多视角注意卷积神经网络(Multi-View Attentional Convolutional Neural Network, MVACNN)引入软注意力机制来调整形状描述符,同时利用长短期记忆网络(Long Short-Term Memory, LSTM)发掘多视角上下文的对象特征,实验展示出了较好的结果。Liang等人[9]提出了多视角卷积LSTM网络(Multi-View Convolutional LSTM Network, MVCLN),同时利用时间和空间信息进行3维模型分类,该方法在多个数据集中展示出了良好的分类效果。
在决策级融合方面,VS-MVCNN首先采用CNN提取不同视角下的视图特征,然后利用支持向量机对目标进行分类,其准确率可以达到90%以上[10]。CNN-VOTE采用深度学习模型CaffeNet作为弱分类器分类2维视图,然后利用加权投票方式作为强分类器完成3维模型分类[11]。Kanezaki等人[12]以多视图为输入,构建了一个基于CNN的RotationNet分类器,联合3维模型的位姿信息对3维模型进行分类。同时,该方法将视点标签视为潜在变量,这些变量在使用未对齐的数据集进行训练时以非监督的方式学习。该方法在ModelNet10和ModelNet40数据集上取得了较好的分类效果。
除此之外在3维模型的描述和表示方面,有些学者采用全景视图表征3维模型,进而实现3维模型分类。DeepPano方法将3维模型围绕其主轴的圆柱进行投影,得到全景视图,然后通过改进的CNN,直接学习深度表示[13]。Geometry image方法首先将3维模型投影到球面上,然后进行切割,获得平坦且规则的几何图像[14]。采用全景视图进行3维模型分类的方法还有PANORAMA-NN[15],但全景图大小相当于多视图,计算复杂度很高。
目前基于多视图的3维模型分类方法中,主流的3维模型表示方法仍是从不同的角度对3维模型进行投影,获得一组2维视图表示3维模型,以此通过围绕3维模型的多个视图表示其全局特征[16]。但是这种方法在模型分类的时候要产生大量视图,通过对视图的分类达到对模型分类的目的。虽然取得了较高的准确率,但是还存在两个问题。首先,在训练分类器时,将同类3维模型的所有视图看作同一类,这降低了分类器的区分性。3维模型不同视点上的视图存在巨大差异,笼统地放在一起作为一个类别的训练数据,无法训练出一个好的分类器。其次,在分类阶段,对每个3维模型的分类要做大量的视图分类,这降低了3维模型分类效率。如图1所示,在绿色虚线框中,同一类别的3维模型Desk1,Desk2和Vase1, Vase2,在不同视点下,投影得到的视图差异大。在相同的视点下,投影得到的视图基本没有差异。有的不同类别的3维模型,在某个视点组下,极具相似性。如在红色实线框中,Desk2与Dresser在上视点组下的投影视图都近似矩形,Vase2与Bottle在上视点组下的投影视图都近似圆环。因此,在该视点组下很难区分他们的类别。而Desk2与Dresser, Vase2与Bottle在前视点组下的视图存在很大区分性。由此可以看出,当仅用1张视图有时难以有效判断3维模型的类别。针对以上两个问题:(1)本文通过将3维模型限定在正多面体中,根据划分的多个视点组训练对应分类器,以此充分利用视点差异下的视图信息对3维模型分类;(2)通过本文的视图选择方法,在差异甚远的视点下选择少量视图用于分类,旨在提高3维模型的分类准确率和效率。
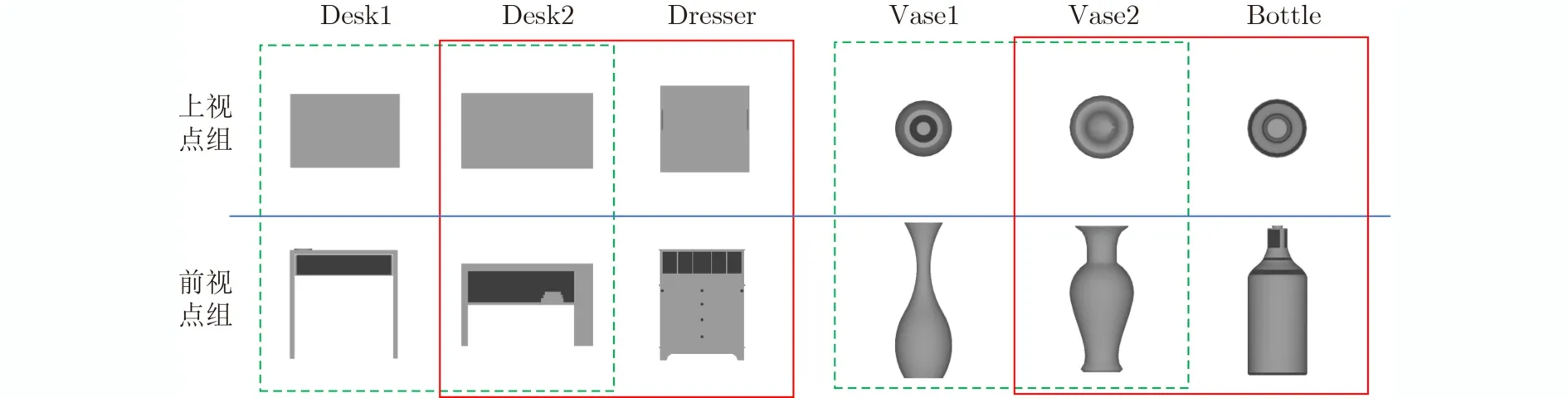
图1 不同视点组下的视图
本文方法建立在决策级融合的层面上,本文的3维模型分类网络分为特征提取网络和分类网络两部分。特征提取网络采用卷积神经网络(Convolutional Neural Network, CNN),并加入轻量级的卷积块注意力模块(Convolutional Block Attention Module, CBAM)来挖掘视图区分性特征[17]。分类网络中的每个视点组对应一个分类器,所有分类器共享卷积层参数。在分类时,每个视图分类器输出一个分类结果,然后采用本文提出的分类策略得出最终的分类结果。
2 本文方法
2.1 总体框架
如图2所示,本文提出的3维模型分类方法步骤如下:(1)3维模型的多视图表示;(2)视图分类器的训练;(3)3维模型分类。3维模型的多视图表示的重点在于投影视点的位置和数量的确定。本文首先通过设置主视点和附属视点,形成多个视点组。3维模型在每个视点组下产生多张投影视图。在分类器的训练中,共享的特征提取网络上增加注意力机制,目的在于抑制无用特征,挖掘视图区分性特征。每个分类器与一个视点组相对应,采用所有3维模型在该视点组下的视图和附加类中的视图进行训练。当进行3维模型分类时,首先采用本文提出的视图选择方法选取视图,然后将视图依次输入分类器中,每个分类器均输出一个结果。最后采用本文提出的分类策略,以获得最终的分类结果。
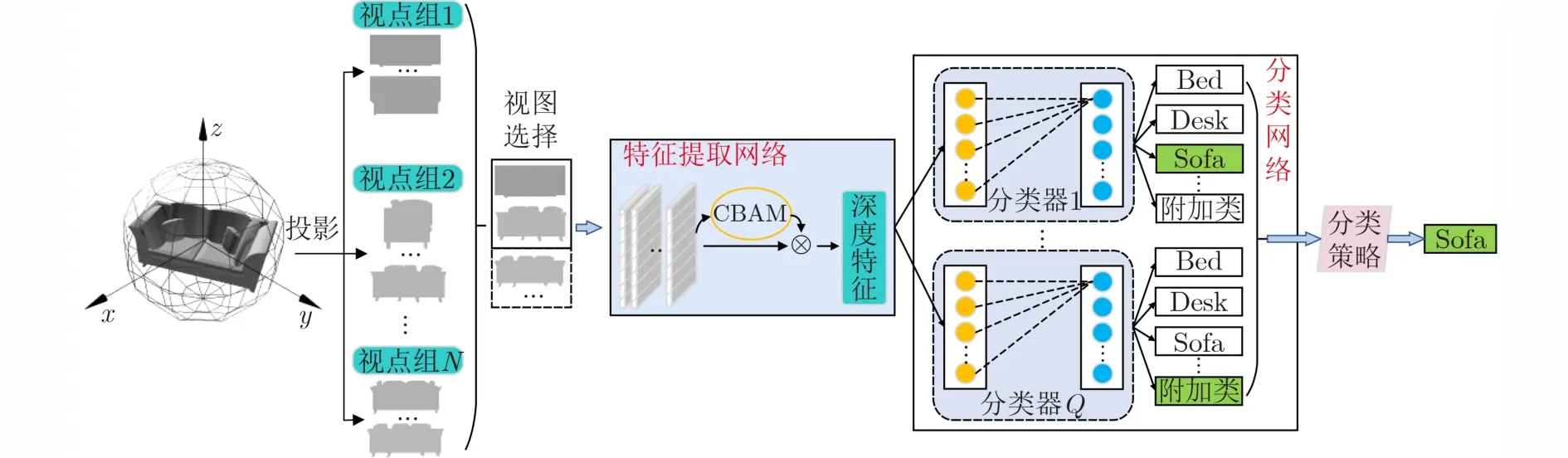
图2 分类过程
2.2 3维模型的多视图表示
3维模型的投影视图受多种因素影响。其中主要因素包括视点的选取和渲染方式的选择。不同视点下得到的3维模型的视图不尽相同,而同样的视点下不同的渲染方式得到的视图所携带的信息量也不同,本文采用了基于冯氏光照[18]的多光源渲染方式。2维视图的数量与设置视点的数量相同,同时3维模型的姿态与设置视点的位置相对应。
本文选择设置N个视点组,每个视点组设置M个视点,即一个视点组包含1个主视点与(M–1)个辅助视点。以正方体包裹模型为例,为兼顾从多方位投影视图,在每个视点组中设置1个主视点和8个辅助视点。主视点分别位于单位正方体的上、下、左、右、前、后6个面的中心。为了增加数据的多样性,增强CNN的鲁棒性,在每个主视点的上、下、左、右、左上、右上、左下、右下设置8个辅助视点,共计M×N(54)个视点。视点组设置如图3所示。
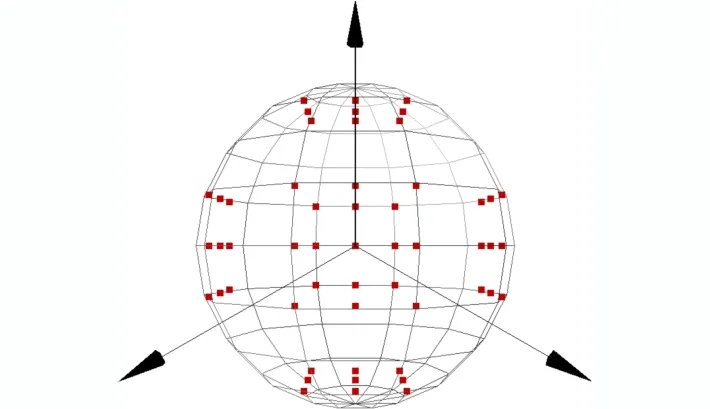
图3 视点组设置
为了增加每个视点组下视图的区分性,同时尽可能减小相邻视点组之间的相似性,本文将辅助视点、3维模型中心与主视点夹角正切值设为tanθ=0.75 ,其中θ的值约为36.87°,俯视图如图4所示。本文设置的视点可以全方位表地示3维模型,并且不同视点组下产生的2维视图差异性大,易于利用3维模型不同视点下的信息对模型进行分类。
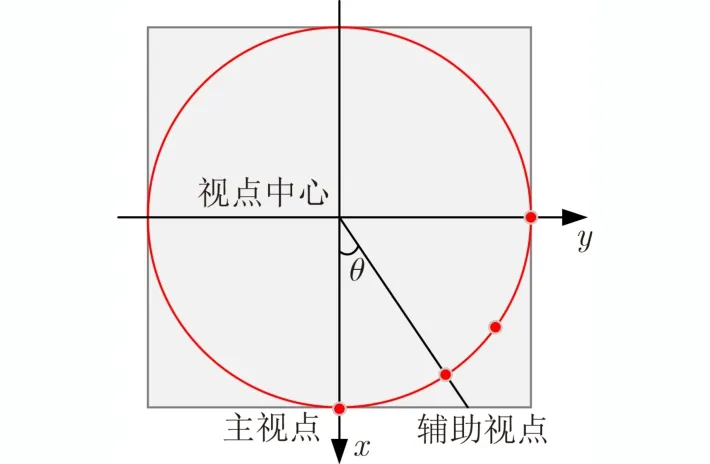
图4 视点设置俯视图
2.3 视图分类器
目前的3维模型分类方法没有考虑不同视点下的模型差异巨大,这降低了分类器的性能。不同视点下的3维模型和模型类别是紧密耦合的。给定3维模型的一张视图,通过多分类器可以很容易推断出该视图属于哪一个视点下的视图,从而推断出这个模型的类别。
2.3.1 CBAM
如何合理有效地利用投影视图的信息是特征提取的关键。本文采用ResNet50提取视图的深度特征。为了能让卷积神经网络模仿人类观察物体时,把焦点目光聚集在物体重要的部分上,本文引入了注意力机制。CBAM是在ECCV2018中提出的用于前馈卷积神经网络的注意力模块[17]。
一个视图经过卷积操作后的输出特征为F,F ∈RC×H×W,CBAM沿通道和空间两个维度依次生成一个1维通道注意图(Mc∈RC×1×1)和2维空间注意图(Ms∈R1×H×W)。再与原特征相乘进行自适应。特征提取表示为
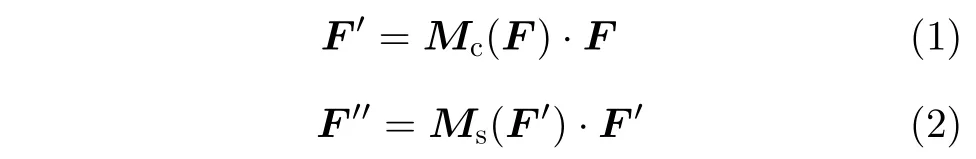
其中,·表示相乘,F′是通过通道注意力后的输出特征,F′′是通过空间注意力后的输出特征。通道注意力机制可以表示为
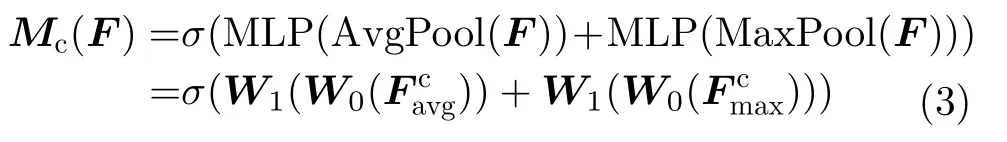
其中,MLP为多层感知器,AvgPool和MaxPool分别表示平均池化和最大池化。平均池化和最大池化后的和共享MLP,σ为Sigmoid激活函数,W0和W1是要学习的参数。空间注意力机制可以表示为
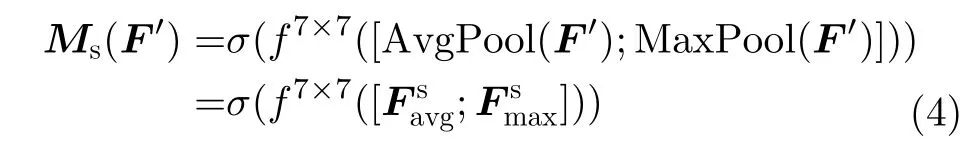
其中,f表示卷积操作,采用7×7卷积核。
本文在ResNet50最后一层卷积与全连接层之间加入CBAM,目的在于增强有用特征,抑制无用特征,从而提取到具有代表性和区分性的视图特征。特征提取网络如图5所示。
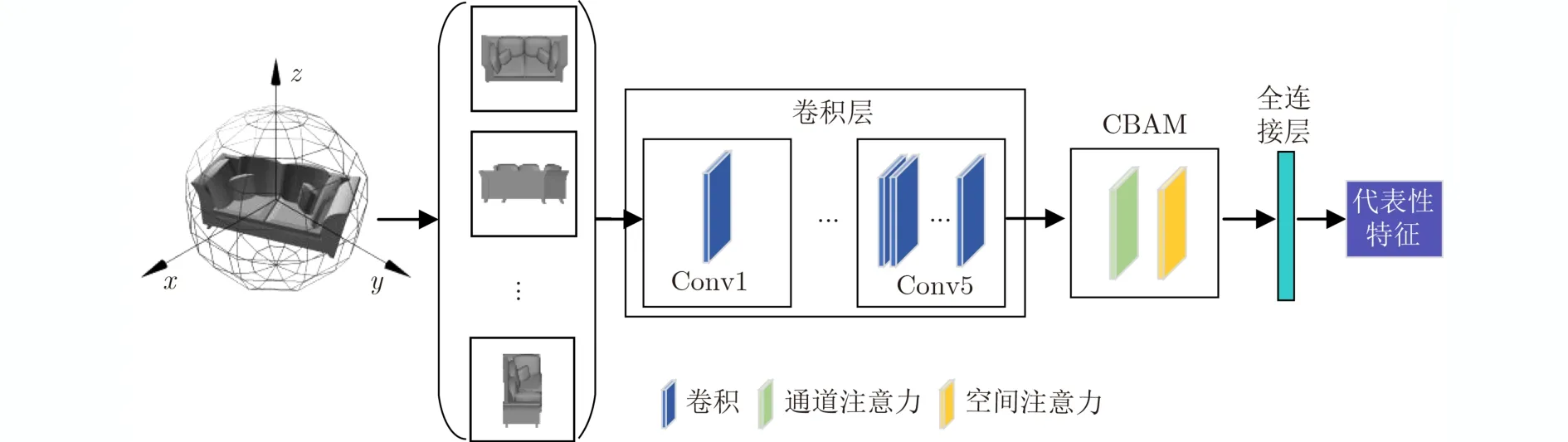
图5 加入CBAM的特征提取网络
2.3.2 附加类
传统方法在分类视图时认为每个3维模型所有视点上的视图属于同一类。事实上,同一模型在不同视点上的视图差异很大,将其放在一个类别中,将使得分类器很难学习到一个合理的分类面。本文认为3维模型的一个视点组下的视图属于一个类别,这个模型其他视点组下的视图都不属于这个类,但也不属于这个分类器上其他的类别。因此我们为这些数据构建一个新的类别,即附加类。这样可以有效提高分类器的区分性。
本文设置了N个视点组,每个视点组下有M个视点,每个视点对应1张投影视图。附加类的数据需要覆盖所有3维模型在非本视点组下的投影视图。因此附加类视图取自所有模型在剩余N–1个视点组下的视图。由于选择剩余N–1个视点组下的所有视图,数据量大,本文采用抽样选择的方式。同时,由于对称视点组中的视图存在一定的相似。因此,本文在含有对称视点组抽样选取附加类视图时,只考虑非对称视点组,即只在剩下的N–2个视点组中抽取。
2.3.3 视图分类器的设置
本文共有Q个视图分类器和N个视点组(Q=N),二者一一对应。Q个视图分类器共享卷积层,但却有各自的注意力层、全连接层和Softmax层。把卷积层与注意力层看作特征提取层,把全连接层和Softmax层看作不同视点组下的分类器,每个分类器输出一个分类结果。这样做的目的是不同视点组下产生的3维模型的2维视图差异性大。例如有的3维模型的上视点组得到的2维视图和前视点组得到的2维视图截然不同。这种差异性大的视图放到同一个分类器中训练是无法得到好的训练效果的。因此,本文根据3维模型的不同方位确定了N个视点组,为每一个视点组分配一个分类器,目的是为达到好的训练效果,进而提高分类准确率。
2.3.4 视图分类器的训练
本文首先用含有注意力块的网络训练一个基线系统。该系统采用所有视点下的视图训练,然后利用训练好的基线系统参数去初始化Q个视图分类器的参数。因此,分类器的训练分为两步:(1)基线系统训练。基线系统以所有2维视图为输入,并且采用训练ImageNet得到的权值参数进行初始化。(2)分类器训练。每个分类器与一个视点组相对应。每个分类器采用对应视点组下的视图和其余视点组下抽样选取的视图的集合进行训练。以Model-Net10为例,视图分类器的训练过程如图6所示。
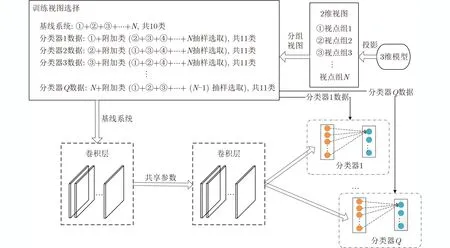
图6 分类器的训练过程
3 视图选择和分类策略
本文通过构建连通图选择视图,目的在于选取少量的区分性视图,提高3维模型分类的准确率。由于在现实中对称的3维模型较多,在视图选择时,首先考虑选择非对称位置上的视图,这样可以有效减少冗余视图。以正方体包裹3维模型为例,其连通图如图7所示。连通图的顶点和边与正方体的顶点和边一一对应,一个面代表一个视点组。视图选择策略如下:(1)视点组选择。首先,从某一顶点出发,选择含有该顶点的所有面(视点组)。然后,从该顶点进行广度优先搜索(Breadth First Search, BFS),每遍历到一个顶点时,选择过该顶点且未被选择的面。直至选择完指定数量的视点组。该方法优先选择非对称视点组,在模型对称的情况下,可有效减少冗余视图。(2)视图选择。每个视点组中随机且不重复地选择1张视图。
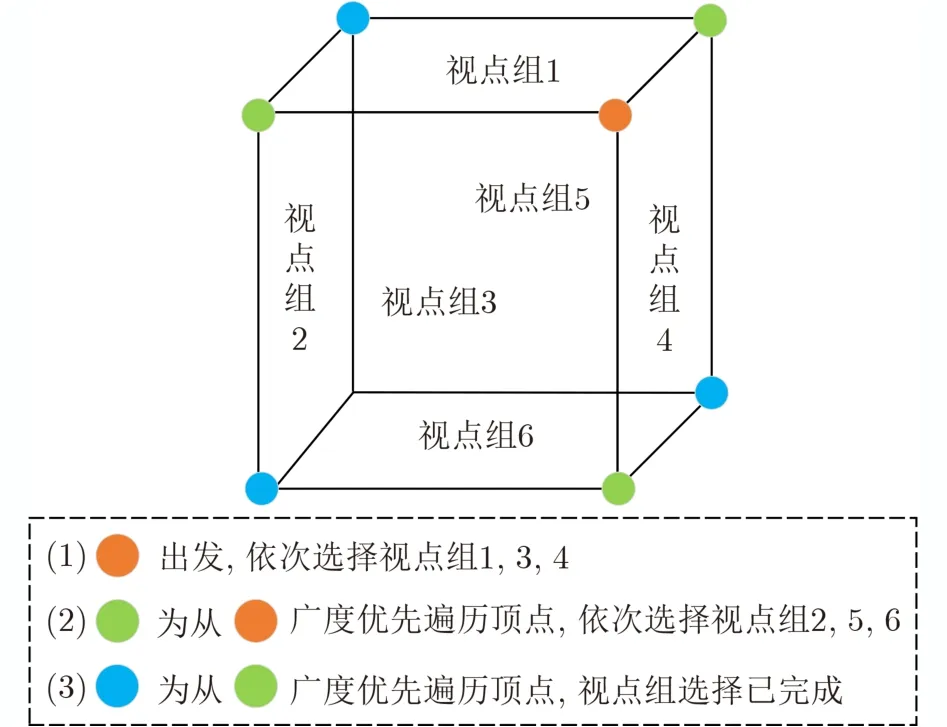
图7 视点组选择
分类策略:给定一个3维模型D的P张视图,将选择的视图依次输入到Q个视图分类器中,如果所有分类器都将输入视图分类到附加类,表明分类信息不足,则在视图所在的视点组中再选择1张视图用于分类。否则累计在类别i所获分类器分类结果概率值Tva(ωi|D),ωi表示类别i(i=1, 2, ···, I,I为类别数,不包括附加类),Tva(ωi|D)计算过程为
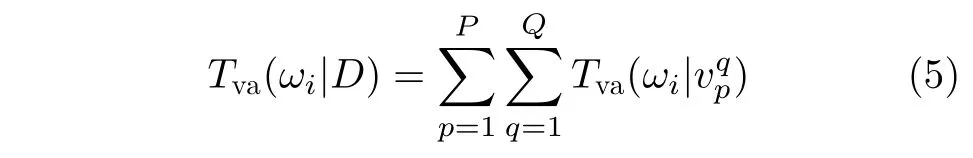
Tva(ωi|)表 示视图vp在第q个分类器所得分类结果概率值(p=1, 2 , ···, P; q=1, 2, ···, Q),P和Q分别表示视图与分类器的总数。最终分类结果为
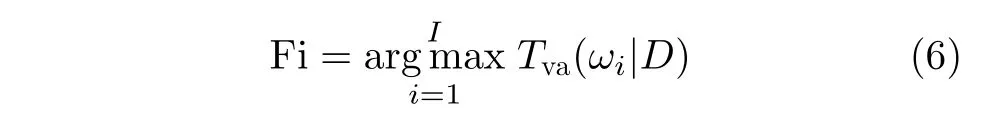
Fi表示3维模型D最终分类结果。通过不同视点组下的多分类器共同决断,充分利用了3维模型的视点差异对类别预测。
4 实验结果与分析
本文设置N个视点组,在确定视点组时,可以采用正多面体包裹3维模型,不仅可以兼顾到3维模型的各个角度,且同时可以达到均匀布点的效果。下面以正方体包裹3维模型,设置6个视点组为例,对提出的3维模型分类方法进行性能分析。
实验基于PYTORCH框架,使用ResNet50和CBAM完成视图特征提取。在Intel i5 8400 +GTX 1060的PC机上测试。选用的数据集为Model-Net10和ModelNet40[19]。ModelNet10共有4899个模型,分为10类。ModelNet40共有12311个模型,分为40类。ModelNet10和ModelNet40已经将训练数据和测试数据分离,分别使用3991和9843个模型作为训练集,908和2468个模型作为测试集。
4.1 ModelNet10数据集
以ModelNet10为例,数据集划分如表1所示。

表1 ModelNet10数据集
(1)基线系统的视图选择。这里的基线系统既是传统方法中的分类网络,也是本文方法的特征提取网络。在训练时以3维模型为类别,不考虑视点差异。基线系统的最后一层采用Softmax做分类,其分类结果作为基线系统的识别率。基线系统采用ResNet50+CBAM网络架构。首先使用ImageNet数据集进行预参数训练,然后使用所有2维视图进行视图分类。按照2.2节的投影方式,每个3维模型产生5 4 张视图。因此,基线系统的测试集有49032(908×54)张视图,训练集有215514(3991×54)张视图。
(2)附加类的视图选择。若所有附加类视图都参与训练,则训练集附加类共有143676(3991×9×4)张视图,与前10类类均3592张视图数量上差异过大。因此,对于每个模型在剩余的4个视点组下各取1张视图,组成附加类。即训练集附加类共有15964(3991×1×4)张视图。从32688(908×9×4)张视图中抽取3632(908×1×4)张视图作为附加类测试数据。
(3)6个视图分类器的视图选择。采用6个视点组下的视图和附加类中的视图分别训练6个分类器。前10类数据的训练集共有35919(3991×9)张视图,测试集有8172(908×9)张视图。则每个分类器的训练集共有51883(35919+15964)张视图,测试集有11804(8172+3632)张视图。
4.2 视图分类器评价
针对本文提出的3维模型分类网络中是否含有CBAM以及数据集中是否含有附加类分别进行了实验,如表2所示。在没有添加CBAM模块的基线系统中,视图的分类准确率是87.28%。添加CBAM模块后,视图的分类准确率是88.42%。可见添加CBAM模块可以有效提高分类准确率。表2展示了不同视点组下的分类准确率,其中高于基线系统的准确率在表中加粗表示。
(1)添加附加类。在没有添加CBAM模块时,相比于基线系统,不含附加类的视图分类器的测试准确率有增有减。其中视点组1和视点组6对应的分类器的准确率较基线系统准确率稍有降低,分别为85.88%和83.92%。视点组2和视点组4对应的分类器准确率与基线系统的准确率基本一致。视点组3和视点组5对应的分类器准确率有所提升,分别是89.72%和89.03%。原因是不同视点下的视图包含的信息不同,区分性不同,分类准确率也就不同。视点组3和视点组5对应3维模型的前面和后面,数据区分性大,因此分类准确率高。视点组1和视点组6对应3维模型的上面和下面,数据区分性小一些,因此分类准确率低。
含有附加类的分类器测试集的分类准确率除了视点组2和视点组4与基线系统的准确率基本相同,其他分类器的准确率均有所提升。尤其是视点组3对应的视图分类器,分类准确率达到了89.74%。综上所述,增加附加类后,对附加类的正确识别可以提升分类准确率。同时,增加附加类可以让视图选择正确分类器的概率更大。可以预见,本文方法对于现实应用中3维模型表面比较复杂、各视点下的视图差异较大的情况效果会更好。
(2)增加注意力机制。添加CBAM模块后,在没有增加附加类的情况下,只有视点组6下的分类器的准确率低于基线系统。增加附加类后,各视点组对应的分类器准确率均高于无附加类的分类器。其中,视点组1和视点组6提升最大,分别提升了2.34%和3.44%。以上结果表明,视图经过深层卷积以及CBAM后,可以增强重要特征,抑制无用特征,从而达到有效区分差异较小的视图的目的。并在结合附加类的优势下,能进一步提高视图的分类准确率。因此本文选择表2含有CBAM和附加类的分类器对3维模型进行分类。
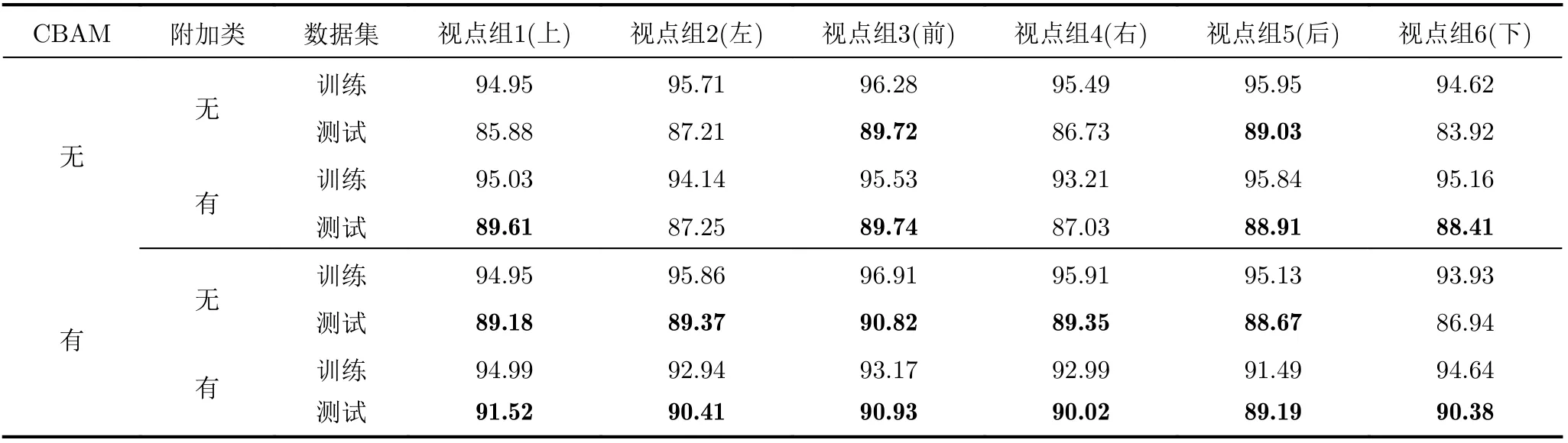
表2 视图分类准确率(%)
4.3 分类结果
本文研究使用尽量少的视图对3维模型分类,充分利用视点差异突出3维模型不同角度的区分性,提高3维模型的分类准确率。单张视图仅是3维模型一个视点下的视图,难以有效分类3维模型。因此本文最少选取2张视图,并逐步增加视图数进行实验。并分别给出了本文方法选取2, 3和6张视图时与其他基于视图的3维模型分类方法的比较,结果如表3所示。
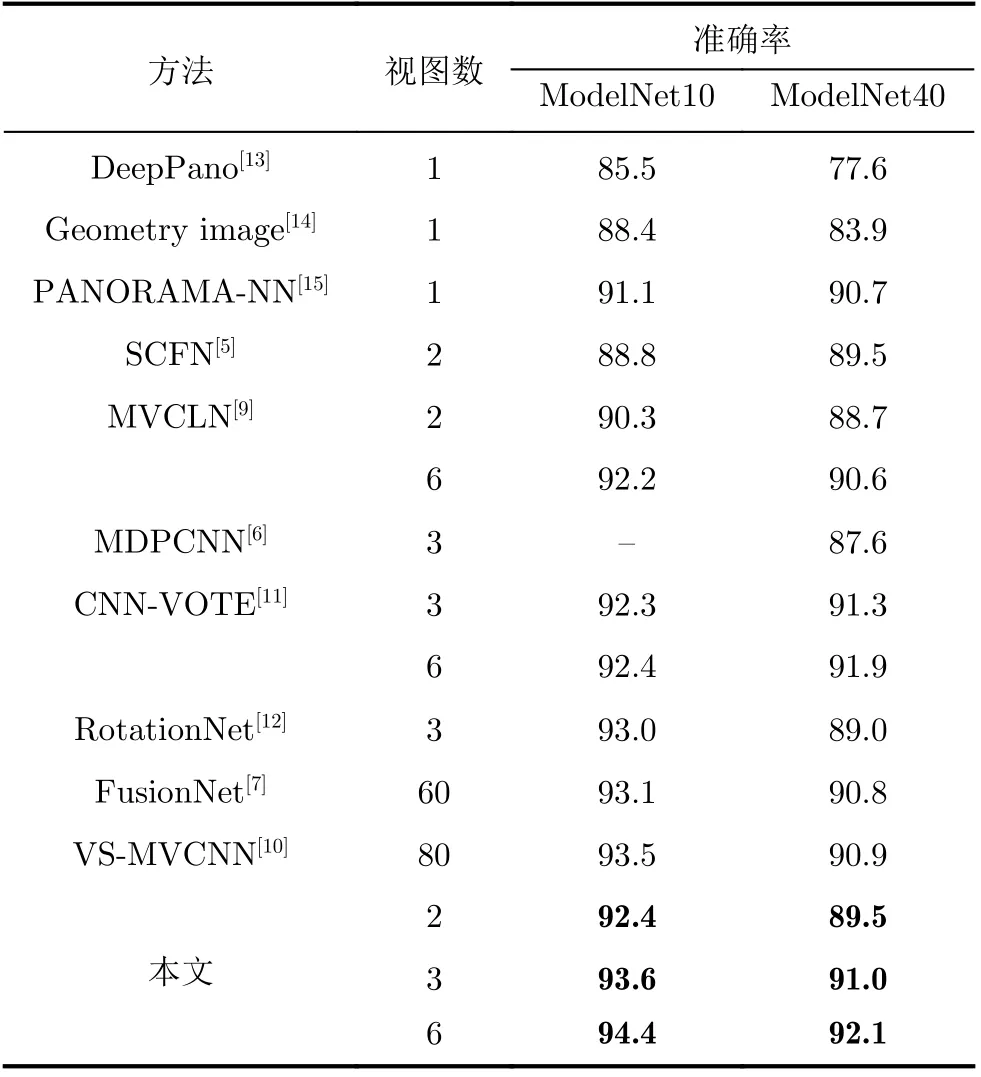
表3 分类准确率比较(%)
DeepPano, Geometry image和PANORAMANN使用的是一张全景视图进行3维模型分类。全景图是由多张视图拼接得到的。当本文方法使用3张视图时,在ModelNet10和ModelNet40数据集上均高于这3种方法。
在采用多张视图的3维模型分类方法中,在ModelNet10数据集上,当本文方法采用2张视图时,分类准确率是92.4%,远高于SCFN和MVCLN使用2张视图的方法。当本文方法采用3张视图时,分类准确率高于CNN-VOTE和RotationNet使用相同数量视图的方法。FusionNet和VS-MVCNN分别采用60和80张视图,而本文方法仅采用3张视图就高于他们的分类准确率。在ModelNet40数据集上,本文方法与其他方法使用相同数量的视图时,仅比CNN-VOTE低了0.3%,其余均优于其他方法。当本文方法使用6张视图时,分类准确率远高于其他算法。
以ModelNet10为例,本文给出了3维模型分类结果的混淆矩阵,结果如图8所示。从图中可以看出,大部分模型可以被正确分类,特别是Bed,Chair, Monitor, Sofa和Toilet,分类准确率接近100%。原因在于:(1)充分利用了3维模型的视点差异;(2)这些类比较复杂,视图含有的信息量大,区分性强,因此能达到高分类准确率。

图8 基于3张视图的3维模型分类混淆矩阵
分类不正确的3维模型出现在多个不同的类别中。这是因为这个形状可能与很多模型的某个视点下的视图有相似之处,因此分类错误时会被分到不同的类别中。同时,形状相似的类别之间被错分的可能性很大,如Table和Desk类,以及Night_stand和Dresser类。
4.4 视图数对分类准确率的影响
图9给出了随着视图数量增多,在ModelNet10和ModelNet40数据集上的分类准确率情况。从图中可以看出,单张视图分类准确率最低,当达到3张视图时,准确率明显提高。原因是单张视图包含信息少,无法很好地表示3维模型。当增加视图数量后,通过视点下的差异很好地增加了类间区分性,因此分类准确率有所提升。当达到6张视图时,由于部分3维模型具有对称性,因此产生了冗余视图,所以准确率增幅较缓。当选择多于6张视图时,ModelNet40的准确率基本保持平稳,ModelNet10的准确率有所下降。

图9 不同视图数量的分类准确率
4.5 效率分析
本文仅使用3张视图的准确率接近甚至超过了现有方法。本文方法虽然使用了6个分类器,但这些分类器共享卷积层参数,特征提取只用卷积网络计算1次。注意力层与分类层虽然要计算6个结果,但CBAM是轻量级注意力块,并且分类层只有1层,参数与运算量上只有少量增加。以本文3通道的256× 256视图作为输入,11个类别作为输出为例,加入CBAM后参数量增加了2.23%,浮点运算量基本与ResNet50的5.38 GFlops相同。
4.5.1 视图选择分析
以ModelNet10为例,该数据集中共有49032张视图,分别对各类中全部被分到附加类的视图数量进行统计,如表4所示。从表4可以看出,视图都被分到附加类的总和共计236张,只占全部视图的0.5%,并且每个类别中占该类总数最多不超过1%。说明当1个视点组下的1张视图被6个分类器均分为附加类时,重选1张视图仍然被分到附加类的概率很低,这说明了本文分类方法的有效性。

表4 视图被分到附加类的数量统计
4.5.2 训练与分类效率分析
本文的6个分类器训练各自的注意力层、全连接层和Softmax层,并增加附加类,目的是让分类器提高不同视点组下视图区分度,并提升分类准确率。而分类器的卷积层共享基线系统参数,目的是为了保证特征充分提取的同时提高网络训练和分类的效率。以ModelNet10为例,将本文方法(权重共享方式)和单独训练6个分类器(非权重共享方式)进行了对比。图10对不同类别中每个3维模型分类平均耗时进行了统计。
从图10可以看出,不同类别下的3维模型分类时,本文方法的平均耗时在0.7 s左右,而使用单独训练的6个分类器耗时大约在1.1 s。原因是共享卷积层权重使每个分类器对视图特征仅需提取1次,而单独训练6个分类器需要提取6次,导致分类时间变长,分类效率大大降低。而本文方法在保证分类器准确率的同时对3维模型分类时间更短,效率更高。
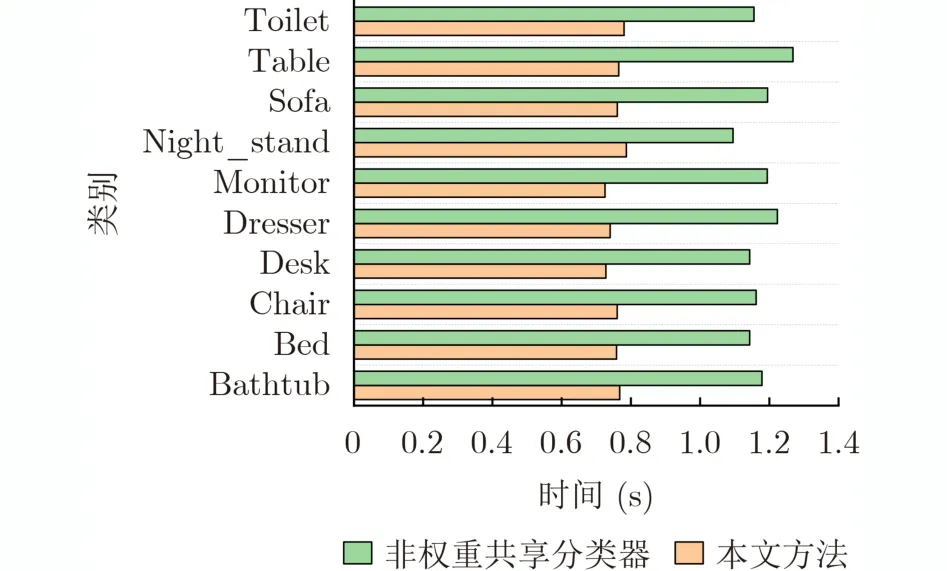
图10 不同类别中3维模型分类平均耗时
5 结束语
随着3维模型规模的不断增加,3维模型的分类准确率和效率成为最大挑战。本文提出了一种基于视点差异和多分类器的3维模型分类方法。在提高分类准确率方面,通过不同的视点组训练相应的视图分类器。在视图特征提取阶段,采用卷积神经网络和注意力机制相结合的方式提取视图的代表性特征。通过增加附加类,充分利用不同视点组下的3维模型的姿态信息,提高分类器的区分性。在提高分类效率方面,提出了视图选择策略,用少量视图在保证分类准确率的前提下,有效提高了分类效率。
