基于改进Apriori算法的网络入侵数据挖掘仿真
2022-11-29曹丽娜杨凤丽
王 霞,曹丽娜,杨凤丽
(石家庄铁道大学四方学院,河北 石家庄 051132)
1 引言
网络是信息交流平台,在给人们带来方便时也伴随着一些潜在的危机,因网络中每天都会产生大量数据信息,人们非常担忧网络中数据信息的安全问题,据相关资料表明,网络入侵事件频繁出现,在2000年著名国际购物网站惨遭黑客攻击,导致经济损失高达12亿美元。网络入侵数据一般以木马病毒、DDoS攻击等形式出现,通过网络植入客户端,窃取机密数据[1]。因此,网络安全问题逐步得到人们的重点关注,一些网络安全产品应运而生,比如网络安全软件、防火墙等。虽然这些产品在网络安全方面起到一定保护效果,但是仍然存在防攻击能力差的劣势,面对高级手段的不法黑客的攻击也无法实现精准防御,导致网络安全性下降。网络性能因网络中存在异常数据导致其性能下降,网络入侵数据一方面因不法分子恶意攻击代码造成,另一方面因个人用户操作不当,下载一些带有病毒的软件或插件导致网络入侵数据产生[2]。
关于网络入侵数据挖掘课题是当前最热门课题之一,入侵检测技术可检测网络入侵数据类型,并依据类型属性进行相应的安全防御措施或杀毒[3]。该技术中误用检测是通过构建入侵规则库进行网络入侵数据判断,但该检测技术存在局限性,对于不在入侵规则库内的新入侵数据无法检测;而异常检测将网络采集数据作为正常行为库,对比网络入侵行为与正常行为库的差异实现检测。通过将入侵检测技术的优势融入侵检测系统内,但仅仅依靠系统检测是不行的,需要加入先进算法提高检测效率,在网络安全中,网络入侵数据挖掘最为复杂,针对这一难题,我国相关学者在网络安全课题中加强对网络入侵数据挖掘方法研究,但以往研究的网络入侵数据挖掘方法存在一定缺陷,如蔡柳萍等人研究稀疏表示和特征加权的挖掘方法[4],该方法通过进行数据处理并利用数据加权实现数据挖掘,但是因该方法计算过程过于复杂,导致数据挖掘不佳,无法挖掘出网络中隐蔽的异常数据的情况时有发生;杨卫等人研究云计算平台挖掘方法[5],该方法侧重于软件设计,导致检测成本上升。
数据挖掘技术可通过发掘数据内隐含规律,找寻有价值数据,Apriori算法作为一种数据挖掘技术,其适应性较广,但该算法运行时负载较大,冗余性高,可通过可拓理论改进该算法,改进Apriori算法计算效率较高,因此有效利用改进Apriori算法,研究基于改进Apriori算法的网络入侵数据挖掘仿真方法,提高网络入侵数据挖掘效率和网络安全管理水平。
2 基于改进Apriori算法的网络入侵数据挖掘仿真
2.1 Apriori算法
在Apriori算法内,数据集k+1项集需要通过k项集进行搜索。设置L1、L2为频繁项集,直至任一r值满足Lr=∅时结束。在第k次循环内,生成候选k项集合用Ck描述,通过对两个Lk-1频集经过连接k-2生成Ck内各项集。候选集通过Ck生成,其子集为Lk。Ck各元素在数据库进行搜索,但该算法负载较大。
Apriori算法基本思路:
Step 1:需找全部项集,项集发生的频繁性与预定义最小支持度相同。
Step 2:强关联规则通过项集生成,该规则一定符合最小可信度与支持度。
2.2 改进Apriori算法
通过可拓理论改进Apfiofi算法,将事物名称用N表示,其特征c的量值用v描述,物元为有序三元组用R=(N,c,v)表示。其中N,c,v为物元三要素,物元受三要素影响较大[6]。
在网络入侵数据挖掘中,关联规则的定义为:对于1个征集X和一个概念描述Y,指定支持度阈值s0和置信度阈值c0,若s(XyY)Es0并且c(XyY)Ec0,则规则XyY成立。其内,s(XyY)=card(XHY)/card(N),c(XyY)=card(XHY)/card(X)。数据记录对象集中事务数量用运算符card(#)求解。支持度计数用card(XHY)描述。
当s(XyY)Es0时,大征集是征集X。征集X内某一征集Xk,为降低冗余挖掘可拓关联规则XkyY需满足置信度大于置信度阚值条件,对Xk进行删除。
改进Apriori算法的思路为:
1)大征集交运算
将2个大征集分别用X1,X2描述,通过交互运算得出征集X;
2)征集删除运算
对k元征集集合内各征集Xk的全部k-1元子句进行查看操作,当Xk-1不是大征集时进行删除。
改进Apriori算法流程如下:
关联规则集用R描述,作为数据输出;最小支持度阈值用s0描述,数据库用D描述,最小置信度阈值用c0作为数据输入。
Step 1:为求出元素集合A,通过扫描总体数据库,统计各条记录内的各元素得出[7-9]。
Step 2:为生成一元候选集H1,通过A内各元素集合生成,将k表示为1个元计数单位设置为k=1。
Step 3:Y表示概念,求解Hk内各征集XkyY的置信度c与支持度s,若Xk的支持度用sEs0描述,进行判断:
1)当置信度阈值c0既定时,若Xk的置信度用cEc0描述,得出输出规则用XkyY描述。
2)若Xk的置信度用cFc0描述,在大征集Lk内存进Xk。
Step 4:当Lk内元素数量小于2个时,则结束;反之,当Lk内的各Xk,依据字典顺序对X内全部元素进行排列。
Step 5:通过比较Lk内征集Xki,xkj的元素,为生成k+l候选集,需要对Lk内的全部征集进行组合操作;若第k个元素不一样,k-1个元素一样时,则Hk+1存全新k+1元征集。
Step 6:令k=k+1,返回到Step 3。
2.3 基于改进Apriori算法的网络入侵数据挖掘
2.3.1 网络入侵行为模式
设定一个阈值并通过正常行为模式和在含有网络入侵的数据集中挖掘出的模式对比后得出阈值距离,进行发生网络入侵行为模式判定[10],采用MEOM(Heterogeneous Euclidean—overlap Metric)函数求解两种模式距离,具体如公式(1)~公式(2)所示
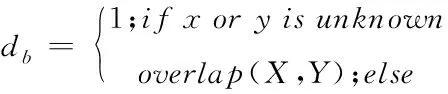
(1)

(2)
向量X和向量Y的距离,如公式(3)所示

(3)
式中:属性数量用n描述,向量属性用b描述。用HOEM(X,Y)描述向量间距离,其值越小表示2个向量大致一样。
因各属性的重要性存在差异[11],需要对各属性设置权值,重要性和权值成正比。在公式(2)内,若2个向量一致,其值是零,无法表示权值,因此需要对公式(2)进行修改,修改后如公式(4)~公式(5)所示
(4)

(5)
向量X和向量Y的距离,如公式(6)所示

(6)
式中:各属性的权值用ϑ描述,用HOEM(X,Y)描述向量间距离,其值越小表示2个向量间距离越大。
若异常模式内的一个向量用Y表示,阈值用δ描述,正常模式内的一个向量用X表示,通过公式(4)~公式(6)求解HOEM(X,Y),当该值小于δ时,判定Y模式为入侵模式,其内存在网络入侵的数据[12]。
2.3.2 挖掘结果的分类处理
在完成网络入侵模式识别后,通过改进的分类规则生成(Ripper)算法对不同的网络入侵的数据类型进行分类,并赋予不同标签。改进的Ripper分类算法,流程如图1所示。

图1 改进的Ripper分类算法流程
由图1可知,该分类算法的基本流程情况,其中在判断POS主动数据项为空时,将训练数据分成缩减集与增长集;在规则扩展中,在置空规则后,添加合法条件,重复此次操作直至规则内包含增长数据集内全部数据项;在规则缩减中,为了实现函数值V最大,需要删除最后条件,重复此次操作直至V最大,通过规则缩减可提高规则适应性和精度。
3 实验分析
为验证本文方法的有效性,在MATLAB_7.0软件测试平台上进行仿真实验测试,选取某网络中数据作为实验数据。
从实验数据中选取4种网络入侵数据的特征样本,对比应用Apriori算法和改进Apriori算法对网络入侵数据挖掘的效果,算法运行时间设置为30分钟,可行性测试结果如图2所示。

图2 可行性测试结果
通过分析图2可知,采用改进Apriori算法进行网络入侵数据挖掘的效果较好,比传统Apriori算法所挖掘4种网络入侵数据的特征样本数量分别约高出1700万条、1800万条、2000万条、2500万条,因此表明应用改进Apriori算法的本文方法的可行性较高。
统计采用Apriori算法和改进Apriori算法在不同支持度的条件下以及不同数据规模条件下进行挖掘的执行效率,如图3所示。

图3 执行效率对比
分析图3可知,应用两种算法进行数据挖掘的稳定性均较优,在不同数据量耗时方面,本文方法应用的改进Apriori算法明显优于Apriori算法,平均耗时比Apriori算法的平均耗时节省19ms左右,在最小支持度不同条件下,应用两种算法进行挖掘的耗时随最小支持度的升高而降低,但本文方法应用改进Apriori算法进行数据挖掘的耗时较少,由此说明本文方法的入侵数据挖掘执行效率较高。
设定c0表示最小置信度阈值,s0表示最小支持度阈值。对实验数据进行7次数据挖掘,在第1次数据挖掘时,设置c0=0.15、s0=0.25;第2次数据挖掘时,设置c0=0.15和s0=0.50;第3次数据挖掘时,设置c0=0.25和s0=0.25;第4次数据挖掘时,设置c0=0.45和s0=0.50;第5次数据挖掘时,c0=0.55和s0=0.70;第6次数据挖掘时,设置c0=0.65和s0=0.70;第7次数据挖掘时,设置最c0=0.85和s0=0.70;得出本文方法挖掘入侵数据的关联规则数量和运行时间结果,如图4所示。

图4 不同置信度与支持度下关联规则数量图
分析图4可知,当最小置信度阈值c0设置在0.45~0.85,s0为0.50~0.70时,数据挖掘的运行时间短、关联规则数量波动较小;c0为0.15~0.25,s0为0.25~0.50时,数据挖掘的运行时间长、关联规则数量波动较大。由此可知,运行时间和关联规则数量受c0、s0影响较大。
实验数据集内网络入侵数据607条,网络正常数据2337条。统计不同算法下网络入侵数据误检率和漏检率,仿真试验结果见表1。

表1 网络入侵数据误检率和漏检率
由表1可知,采用改进Apriori算法下入侵检测的漏检率与误检率分别比传统Apriori算法下的入侵检测的漏检率与误检率降低6.24%、6.14%,说明应用改进Apriori算法的本文方法性能更优,可有效提高网络数据安全性。
4 结论
为提高网络入侵数据挖掘效率,本文提出基于改进Apriori算法的网络入侵数据挖掘方法。构建改进Apriori算法的网络入侵数据挖掘模型,实现网络入侵数据挖掘。仿真实验结果表明,采用本文方法可行性强,可解决网络入侵检测中的大量数据挖掘问题,使挖掘效率提高。因本人时间与精力有限,研究仍处于起步阶段,仍有许多不足,需要在以后社会实践中逐步完善。本人以后研究方向如下:
1)将本文方法应用在网络流量数据异常检测或系统开发内,拓展本文方法应用范围,需要我们继续研究进一步提高算法的挖掘能力。
2)为了提高本文方法在网络数据检测中的性能,可以引入更多先进技术和方法,并与之结合提高数据检测精度和适应性。
