基于个性化查询的用户生成多源文本融合
2022-11-29李祯其孙晓燕纪南巡
李祯其,孙晓燕*,胡 尧,纪南巡
(1. 中国矿业大学信息与控制工程学院,江苏 徐州 221116;2. 香港城市大学工程学院,香港 999077)
1 引言
用户提供的文本评价,尤其是电子商务领域中各电商平台的用户评论,作为用户生成内容(User Generated Content,UGC)[1]重要组成部分,是用户根据个人喜好和使用感受从不同角度对所购买产品或服务给出的描述。充分挖掘和利用用户评论隐含的偏好和需求信息,将会有效提高电商平台个性化搜索的准确率和个性化服务水平,并改善用户的搜索体验。由于电商平台的用户评价数据通常以短文本形式存在,且评论内容具有局部性、知识粒度和精度差异大等特点,融合多用户多角度评价文本数据则可望获取关于评价对象的全局知识。此外,用户一般通过向系统输入简短查询文本确定搜索对象,且更关注与其查询对象相关的评价,因此,以用户搜索对象为参考对商品评论进行个性化融合,则有望进一步精准定位到用户感兴趣的物品集合。图1给出一实例,对于产品帽子,若可将其评价进行向量化表示,然后进行融合,将所有融合了多源文本(即多个用户的历史评价)的数据模型作为搜索或者推荐对象,则该对象包含了除搜索对象自身特征之外的更丰富的社会评价信息。

图1 融合用户生成多源文本的物品向量化表示
鉴于此,本文利用Doc2Vec模型实现多源文本的向量化表示,并提出基于欧氏距离和余弦相似度的加权文本融合策略,以获取与客户端查询对象相关的多源文本融合的精准向量化表示。所提算法的贡献主要包括如下3点:1)在个性化搜索中,基于用户生成内容的图像、视频数据处理研究成果较多,而本文是研究基于客户端简短输入文本的多源评价文本融合的搜索物品向量化表示,出发点与已有研究不同;2)研究方法上,分析了在文本高维向量空间中欧氏距离和余弦相似度的差异互补特点,提出基于双相似度加权的用户生成多源文本融合策略;3)给出了基于多物品向量化表示的分类评价准则,以衡量多源文本融合及向量化表示的有效性。
2 相关工作
在文本融合方面,Macedo等[2]针对社交活动推荐中的冷启动特性,将社交信息、位置信息以及时间信息进行融合,将融合后的信息看作推荐方法的输入特征。Xie等[3]将用户在搜索中的情感信息与基于情感所产生的用户信息融合起来,并提出基于情感相似性度量的情感排序准则以获取更为精准的推荐排名。琚春华等[4]考虑地域文化背景、领域主题情景和主题特征等信息,提出了一种基于情境和主题特征融合的多维度个性化推荐模型,克服了数据稀疏性等问题。Ding[5]提出NRPMT深度学习框架,在该框架中,多标准评级和用户评论可以相互补充,以提高推荐的准确性。上述研究成果表明融合多种信息之后的对象包含了更为丰富的内容,更有利于实现个性化的推荐与搜索。不难看出,当前已有关于UGC数据挖掘的研究尚未考虑用户生成多源文本对于个性化搜索对象精准向量化表示的价值。本文出发点是多源文本信息的融合向量化表示,因此,下面进一步说明文本向量化表示方面的相关工作。
关于文本的向量化表示,随着深度学习的发展,谷歌公司提出Word2vec[6]和Doc2vec[7]算法框架,基于充足的语料库训练深度神经网络,以充分获取词与词之间的相关性,实现对词和文本的向量化表示,并进行相似性度量。进一步,Mikolov等[8]利用Word2vec算法将一个向量空间向另一个向量空间转换,实现了词粒度上的机器翻译。已有文本向量化工作主要关注了自然语言处理时的语义理解和生成,而文本向量化表示过程并未涉及多源文本向量化融合。
在进行多源文本向量化融合时,需要依据相似度进行度量。朱命冬等[9]针对TF-IDF信息的余弦距离不属于度量空间且难以构建索引的问题,面向不确定文本数据研究了基于余弦相似度的相似性查询方法。陈小辉等[10]在欧氏距离计算的基础上引入归一化处理和Jaccard相似系数,以缓解推荐系统中用户对项目的评价数据的多样性和稀疏性。Ayeldeen等人[11]提出在模糊欧氏距离聚类算法基础上考虑文本关键字权重,实验结果表明所提方法有助于提升聚类效果。上述成果表明,融合不同的相似度评价方法可以提升相似度计算的准确性,但目前在多源文本融合以及向量化表示方面的相关研究较少。
综上所述,本文结合电商平台中用户的搜索方式及特点,以用户提供的个性化查询文本为参考,研究多源文本融合的物品向量化表示,提出一种基于欧氏距离和余弦相似度的加权文本向量化融合策略,以期为个性化搜索对象的表示提供更多更精准信息,从而更好的服务于个性化搜索。
3 个性化查询引导的多源文本融合
本文所提算法框架如图2所示,主要包括3部分,一是面向用户生成多源文本的Doc2vec训练;二是文本向量化表示的相似度计算;三是基于双相似度的多源文本向量化融合及其向量化输出。

图2 所提算法框架
3.1 面向文本信息的Doc2vec训练

3.2 多源文本向量化表示的评价相似性
文本相似性度量已有较多研究,传统的方法如基于词频统计的字面匹配、语义匹配等;此外,基于文本向量化表示的相似性计算主要有欧氏距离、曼哈顿距离、切比雪夫距离、海明距离,以及最常用的余弦距离等。在本文所研究的用户生成评价文本问题中,由于这些评价文本可同时反映用户的认知和偏好,所以不同用户对同一物品的评价具有一定的差异性。而本文目的是基于客户端当前用户所输入查询文本信息,将同一物品的多源文本按照其与查询文本的相似认知(即讨论的对象和情感)和偏好程度(即对象的细节部分,如价格、材质、用途等)进行精准向量化融合,融合向量用以表征该物品,从而更加准确、主动的识别出用户决策需求,为用户提供高效的决策支持服务。
由于余弦距离对绝对数值不敏感,更加体现在文档基于词典的不同方向上的差异,而欧氏距离主要体现的是文档相似度的具体数值差异[12]。因此,本文采用Doc2vec提取文本特征,对多源文本进行向量化表示,并考虑基于欧氏距离和余弦距离的相似性度量。具体来说,当两用户对某物品具有相近认知时,则对应向量方向越一致,可采用余弦相似度衡量;而当两用户评价偏好相近时,其空间距离应较小,可采用欧氏距离衡量[13]。如图3所示,假定用户查询文本的向量为xu,用户A提供的评价文本向量为xA,B的评价文本向量为xB,C的评价文本向量为xC,其中,用户u查询文本与用户A和B评价文本的欧氏距离相同,余弦距离不同;用户u查询文本与用户B和C评价文本的余弦距离相同,欧氏距离不同。此时,若仅采用单一的欧氏距离或者余弦距离,则不能全面评价用户查询文本和评价文本的相似性,进而影响基于该相似性的文本融合。因此,本文采用双相似度衡量文本评价的相似性,进而提出基于欧氏距离和余弦距离的加权相似文本向量化融合策略。

图3 余弦相似度与欧氏距离关系
这里考虑用户输入的搜索文本Tu与各相关商品的其他用户提供的评价文本Tk={T(k,1),T(k,2),…,T(k,mk)}的相似性。对于物品k,分别计算xu和Xk=[xk(1),xk(2),…,xk(mk)]T各文本向量的欧氏距离和余弦距离。对于物品k的第i条评价文本,其与用户输入文本向量间的欧氏距离和余弦距离分别如式(1)和式(2)所示
k=1,2…n,i=1,2,…,mk
(1)

(2)

图4 双相似度加权融合策略
3.3 基于双相似度的多源文本向量化融合
基于客户端查询文本,往往有较多关联物品,而每个物品可能存在较多评价文本,对向量化后的文本进行融合时,除了需要考虑认知和偏好相似度外,还需同时考虑融合文本的贡献率和融合后向量的空间一致性,即使得融合向量在认知和偏好上与当前用户保持一致,才能有利于辅助用户精准找到满足其需求的物品。为此,本文提出基于双相似度贡献率的一致性融合策略。进行贡献率融合时,应使得与当前用户查询文本认知和偏好越相似的文本整体贡献率增强,反之,则削弱。为此,作者对欧氏距离的权值计算进行改进,提出如式(3)所示的欧氏距离加权策略
11.2.4 去势(间苗):从灵芝现蕾开始,要不间断地、多次进行间苗(去势),可采用切割法、烫烙法等。同一菌木只留一个生长在近中部、健壮、无畸形的菌蕾,去势时不要触摸菌蕾。

(3)
式中,min和max分别代表第k个物品中,其历史用户生成的多源文本与客户端查询文本的欧式距离最小值和最大值。
由式(3)知,dωk(i)越大,则用户u的查询文本与当前物品k的第i条评价文本的偏好相似度越大,则该文本在多源文本融合中所占权重亦越大。与之类似,进一步计算基于余弦相似度的评价文本重要性权重,因为余弦相似度取值范围为[-1,1],为保证权值计算的合理性,需将其变换为[0,1]。基于此,余弦相似度的重要性权重如式(4)所示

(4)
针对客户端当前查询文本,将与之对应的第k个物品的所有多源文本进行向量化融合,以获得对当前物品含历史用户多角度评价的向量表示,融合策略如图4所示。其中,作者提出如式(5)基于欧氏距离和余弦相似度的用户当前查询文本与评价文本相似度重要性的权重融合算法,以及式(6)基于重要性权重的文本融合后第k个物品的向量表示
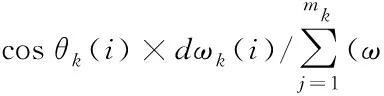
(5)
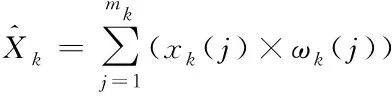
(6)
4 实例验证与分析
为了验证本文所提算法性能,将其应用于亚马逊含有用户评价的5类不同数据集[14],即数字音乐类、工业科学类、软件类、电子游戏类和户外运动类,对该数据集中所有物品的用户评价进行融合,将融合后的向量作为各物品的数字化表示,然后基于该向量表示,对5类物品进行分类,若分类准确率较高,则说明融合后的向量可精准表示各类别中的物品,进而可表明本文所提多源文本融合向量化表示的有效性。
4.1 实验背景及参数设置
由于本文选择的亚马逊产品数据库中的用户评价存在数据缺失和重复评价等问题,因此,首先对其进行清洗处理;此外,当某物品评价数量极少时,融合文本条数的不平衡将导致融合精度不准确,因此,实验中将评价数量少于10条的物品视为无效商品,并从中删除;最后,由于本文所提融合策略的可行性是基于多分类来评判,为了尽可能减少干扰信息,因此需要保持类别间的数据平衡性,即对每一类的样本数据随机筛选50000条评论,并确保评论对应的产品数量能相差不大。表1给出了经过预处理后的数据集中所包含的有效物品及相应评价数量等基本信息。
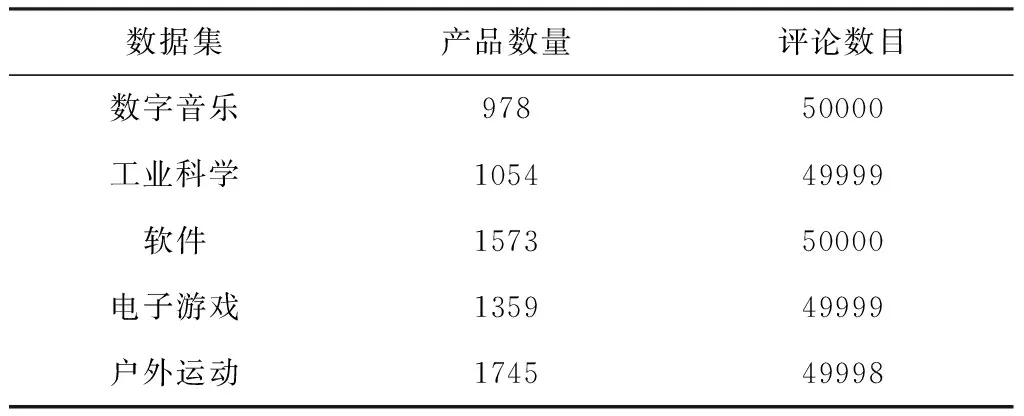
表1 亚马逊数据基本信息统计
实验环境采用基于Python的Anaconda平台以及相应的gensim3.7.1、nltk3.4库。对于Doc2vec模型,根据经验和文献[8]本文使用PV-DM模型,训练参数设置如下:文本滑动窗口为15,字典截断阈值为1,高频词汇的随机降采样的配置阈值为1e-5,用于控制训练的并行数为1,使用负采样,噪声词设置为5,初始学习率设为0.01并随迭代次数线性减少,使其在迭代训练结束时值为0。
为了说明本文所提方法的有效性,共设计3组实验:1)面向用户评价短文本向量化表示的Doc2vec关键参数确定,即研究向量维度和训练迭代次数对融合和向量化表示的影响;2)比较5种不同相似度设置下,不同数量的文本融合后与用户查询文本间的欧氏和余弦相似度,以说明不同相似度和融合文本数量对表示精准性的影响;3)衡量融合算法的整体性能,比较各物品评价文本的向量化表示在不进行融合处理与使用本文所提融合算法时的分类精度,说明融合的必要性和有效性。
4.2 面向短文本向量化表示的Doc2vec参数确定
为了尽可能获得评价文本的精准向量化表示,需通过实验先确定Doc2vec模型的关键参数。影响Doc2vec性能的关键参数主要是语料库大小、输出层向量维度,以及模型迭代训练次数[7]。这里语料库大小为各物品真实的用户评价数量,而输出层向量维度和模型迭代训练次数则需要通过反复实验确定。为此,本文考虑6种向量维度和6种迭代次数的匹配关系,通过对本文所用5类数据的平均分类准确率确定合适的向量维度和迭代次数。首先,针对各数据集,分别随机选择90%作为训练样本训练Doc2vec,然后,将剩余10%样本的文本进行向量化表示后作为测试样本,采用逻辑回归分类器对其进行分类测试(未对文本进行融合,即一条评价文本为一个分类样本),比较分类精度和所需时间的变化,选择分类精度相对较高且计算复杂度相对较小的参数设置。实验结果如表2所示。
从表2可以看出,1) 输出向量维度:在固定的训练迭代次数下,随着输出向量维度的增加,基于文本评价向量化表示的物品分类精度逐渐增加,如迭代次数为5时,分类精度从50维时的65.99%提升到维度为300时的70.12%,提升了近5%;不难看出,在维度从50变化到500时,分类准确率提升相对明显,而从500增加到900时,精度提升幅度相对减小,表明对于本文所考虑的用户评价短文本,Doc2vec输出向量维度并非越高越好,300维至500维即可;2) 训练迭代次数:在固定维度下,如300维时,随着迭代次数从1、5、10增加到20,分类精度逐渐提高,从61.27%提升到80.37%,提升了20%,说明迭代次数增加对于Doc2vec输出表示影响较大;但是,当迭代次数进一步从20变化到50和100时,基于文本向量化表示的分类精度则开始减小,说明迭代次数过大反而导致模型局部收敛,影响了输出向量化的精准性和泛化性,因此,本文选择迭代次数为20;3) 综合比较输出向量维度、迭代次数以及算法运行时间,可进一步看出随着维度和迭代次数增加,算法运行时间大幅度增加,为此,为兼顾向量精准化和计算复杂度,本文设定Doc2vec输出向量维度为300,模型训练迭代次数为20。

表2 不同向量维度和训练次数对向量化精度的影响
4.3 融合策略与融合文本数量对向量化表示的影响
根据4.1和4.2节参数设置,本部分实验进一步研究不同融合策略以及参与融合文本数量对用户生成评价文本向量化表示的影响。关于融合策略的有效性,这里考虑5种文本融合方法,分别记为:1#:无向量融合;2#:多源文本向量直接相加融合,取其均值作为融合向量;3#:直接采用式(3)欧氏距离作为权重,对多源文本向量进行加权融合;4#:仅利用式(4)余弦距离作为权重,对多源文本向量进行加权融合;5#:采用本文所提双相似度方法,即式(5)对评价文本进行加权融合。通过对比不同融合文本数目设定下,上述5种方法所得物品多源文本融合向量与用户查询文本向量之间的欧氏距离和余弦相似度指标(1#取相似度均值),以说明本文所提融合策略的有效性。

表3 随机选择的搜索物品和用户评价信息
从各类各物品中随机选择参与融合的多源文本,数量分别取为2条、8条、14条、20条、26条、32条、38条、41条和50条。针对5类数据集,随机选择其中的一条用户评价作为用户查询输入,并将其从数据集中删除,重复实验10次,计算所得相似性指标的平均值;由于文章篇幅限制,本文分别从5类数据集中随机选择一个物品作为说明对象,所选物品信息和用户评价对应的物品编号信息如表3所示,相应实验结果如图5~9所示。

图5 数字音乐数据集

图6 工业科学数据集
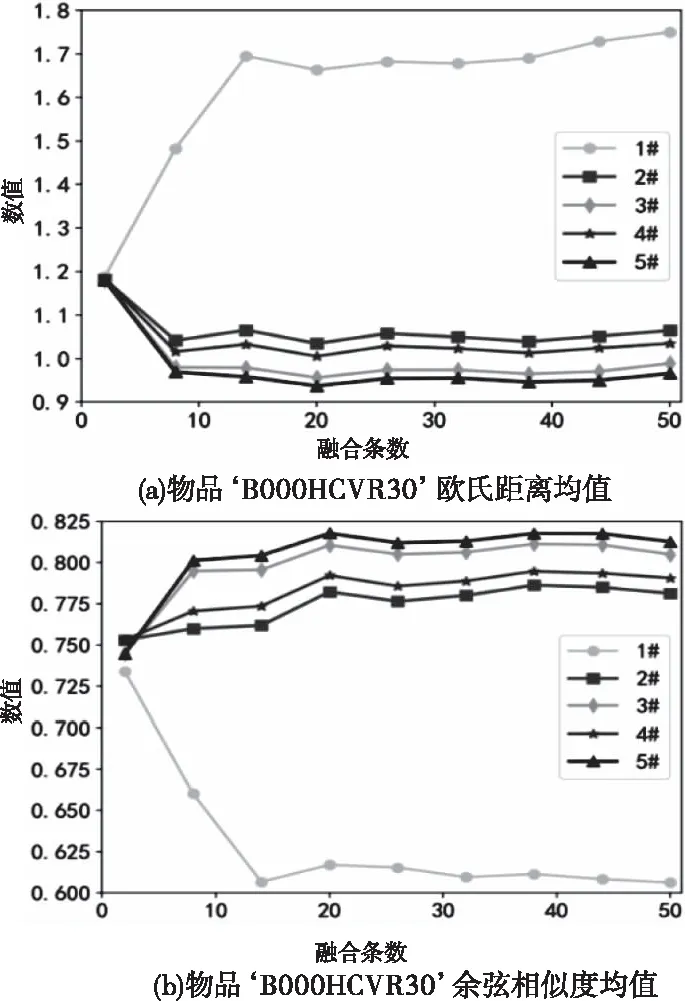
图7 软件数据集
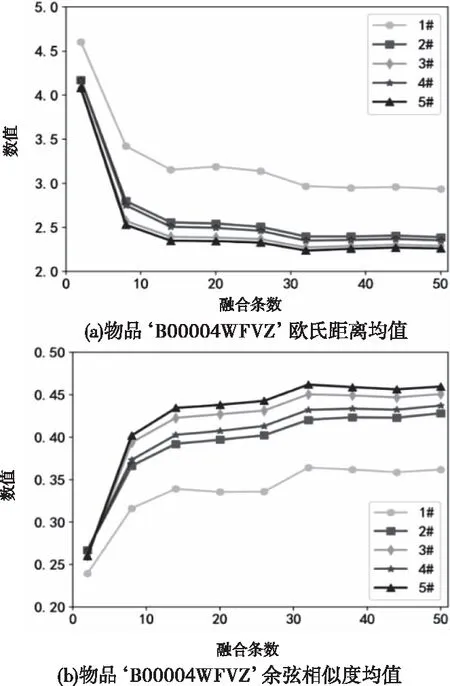
图8 电子游戏数据集
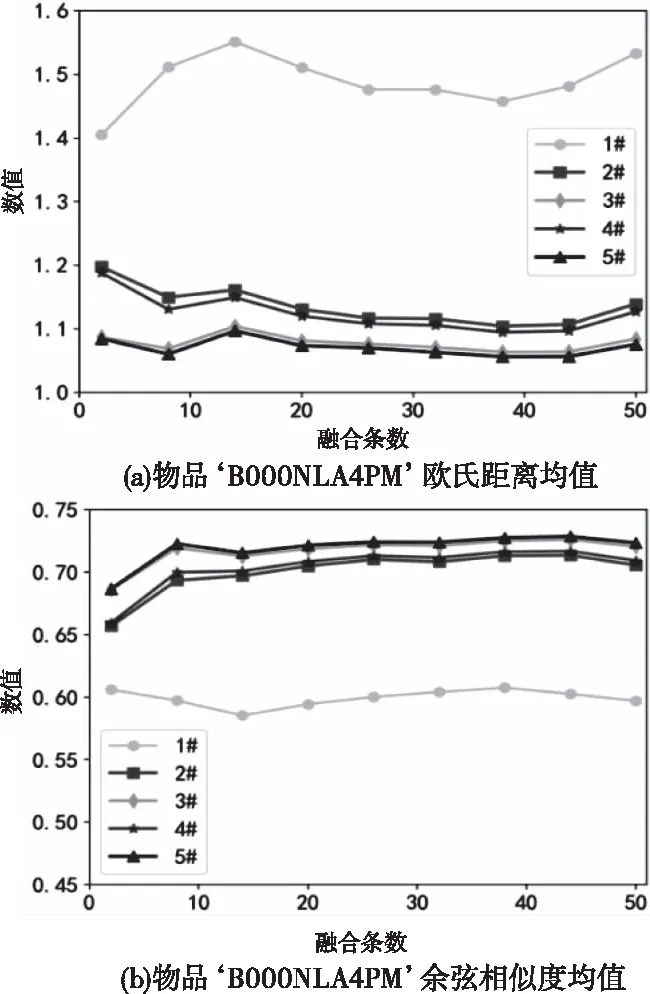
图9 户外运动数据集

图10 欧氏、余弦和融合权重
由图5~9可知:1) 所比较的5种用户评价方法中,本文所提基于双相似度的加权融合策略即5#效果最好;本文所给式(3)基于欧氏距离的加权融合方法3#略差于双准则融合机制。2) 进行多源文本融合后的物品向量化表示与用户期望物品向量相似度都明显优于1#方法,说明进行多源文本融合可有效增加对物品描述的全面性,从而真实表达出更符合用户搜索需求的物品信息;3) 评价文本融合条数从2条到8条时,融合后物品描述文本和搜索文本的欧氏距离急速减小,余弦相似度明显增大,说明随着融合条数的增加,融合后向量包含的物品特征逐渐丰富,可以更加细致的描述物品特性。4) 而随着融合文本数量进一步增加,向量特征逐渐饱和,即对该物品的描述已趋于全面,则样本融合后性能开始趋于稳定;当融合文本数量超过一定数值,如本实验中,文本数量超过30条后,融合信息和期望查询文本间的相似性反而呈现下降趋势,原因在于当融合信息已较完善时,再有其它信息加入时可能造成信息冗余甚至引入噪声,从而影响了物品描述的真实特征分布。考虑资源利用与时间效率,对于短文本评价最优融合条数可不高于30。5) 随着融合文本数量的增加,本文所提融合策略5#与基于欧氏距离的加权融合策略3#所得融合向量相似度逐渐增加,其原因正是由于余弦相似度反映用户的认知一致性,而欧氏距离反映不同用户的评价偏好,显然,对于同一物品,不同用户的认知差异会随着融合信息增加逐渐减小,因此余弦相似度在文本数量增加时,其作用逐渐减小;而用户偏好往往具有较大差异,随着越来越多用户参与,融合向量与期望向量的差异将主要由欧氏距离决定,从而使得此情况下本文方法与欧氏距离加权所得物品用户评价向量更接近。
为了直观理解本文所提融合策略的有效性,本文进一步以数字音乐数据集融合评论文本条数为50时为例,随机选取一次实验中多源文本和查询文本的欧氏距离权重、余弦相似度权重,以及融合权重的变化曲线进行可视化,结果如图10所示。其中,搜索文本内容为 “The anthemic title track begins quot; The Memory of Trees…”,融合的评价文本主要是用户对歌手恩雅第四张CD某些歌曲的评价。
从图10可以看出:1) 本文所定义余弦相似度、欧氏距离,以及融合权重的取值变化范围在0.01~0.035,具有同等量级大小;2) 由于Doc2vec获得的文本向量为300维,较小的取值范围不会导致向量波动过大,有助于抑制噪声;3) 余弦相似度和欧氏距离两者权重值的波动趋势大致相同,当融合文本为第15条,即 “quot; Wouldn’t It Be Nice quot;-lyrics are sophomoric,but it’s still a good one! quot…” 三个权重值都比较高,这是因为第15条评价的歌曲与用户查询歌曲相同,同时评价情感方向都是对歌曲的赞美。而对于第21条文本,即 “At the time of this writing Amazon lists 365 reviews of PET SOUNDS under one or another CD release (and I won′t be offended if you choose to read some of them…” 欧氏距离权重相较于余弦相似度出现明显的波动,这是因为第21条评论是关于宠物音乐创作的由来以及对其中几首有名歌曲的赏析评价,虽然相较于搜索文本都是对歌曲的赏析评价,但其特征内容出现明显差别,因此欧氏距离权重值较低。4) 融合权重波动性更大,主要是基于双相似度的加权处理,进一步区分了用户认知和偏好的差异度,从而使得评价越相似,在融合中的作用越强,反之,具有较低相似度的评价文本信息则被削弱,可使得融合后的物品信息更符合用户的查询需求。
4.4 基于分类准确率和查询结果的融合性能测试
为了进一步说明融合后向量的可信性,这里针对表1所列5类亚马逊数据集中所有物品的用户生成多源评价文本进行融合,然后利用相同的分类器对向量化表示的物品进行分类,比较融合效果较优的3#、4#和本文所提融合策略5#得到的融合文本向量所表示物品的分类准确率,分类准确率越高,说明融合向量对物品描述越准确。这里,实验中每个物品融合条数设定为4、6、8、10,并采用逻辑回归分类器对所得融合向量进行分类,实验结果如表4所示,其中最后一列为未进行文本融合情况下的分类结果。

表4 分类精度对比(%)
由表4可以看出:1) 不对用户评价进行任何融合,只对用户评价向量化的分类准确率为80.37%,而采用本文所提融合策略,随着融合数量的增加,分类准确率不断增加,即使仅融合4条用户评价,本文所提融合策略所得向量的分类准确率也能提升11.16%,而当融合8条时,分类准确率提升了13.37%。2) 当多源文本的融合样本数大于8条时,模型分类精度增长变得缓慢,原因在于此时融合向量已包含了物品较丰富信息,其向量表达随着融合文本数量增加变化不大,结合4.3小节实验结果,再次表明样本融合样本数为8条时融合效果较好。3) 比较四种融合策略,可以看出,本文所提融合策略相较于其它三种融合策略能取得较好的分类效果,而5#与3#分类精度差距较小,随着融合文本条数增加,四种融合方法的分类精度差距逐渐减小,当融合条数为10条时,5#和3#几乎能达到相同的分类效果,这是因为当融合样本数量较少时,四种融合方法关注的特征向量会有较大差别,而随着融合样本数量增加,导致特征向量增加,从而使得被加权的特征向量之间差异性逐渐减小。
为了更直观的说明本文所提基于个性化查询和双相似度的用户生成多源文本融合算法的有效性,本文进一步探究了对物品多源文本不进行融合,以及采用本文所提融合策略5#对物品描述向量化后的K-means聚类实验,对二者进行PCA降维至二维空间后的可视化结果如图11和12所示。

图11 无融合的评价向量化物品聚类图12 多源文本融合向量化物品聚类(融合条数为8)
比较图11和图12可以看出,对多源文本进行向量融合后不同物品具有更加明显的类别特性,融合策略5#与无融合策略1#相比,聚类后的轮廓系数提高了约0.14,进一步表明本文所提融合策略的有效性;此外,融合前向量空间中样本总数为249996个样本向量,融合后向量空间中样本总数为6709个向量点,说明对多源文本进行融合有效集成了同一物品的多源特性,使得对物品描述更准确更全面,减少了冗余信息的噪声干扰,从而可使得基于用户评价的物品向量化描述更精准,可为用户个性化搜索提供更加精准的信息。
此外,针对融合前后评价文本向量与客户端搜索内容的匹配程度也能进一步表明本文所提融合策略5#的有效性。实验中,以数字音乐为例,随机选取两条用户评价文本“This is the absolute peak of Petra’s rock career. This CD defines John Schlit’s highest level of achievement as the band’s lead singer. Jekyl and Hyde is a harder rockin CD,but ON FIRE! sets the pace.”、“This is Alison Krauss at her best. This CD is full of killer songs played wonderfully by great musicians. Her voice soars! The music is more bluegrass than her recent CDs that are filled with ballads. But this still has a great mix of fast & slow songs.”作为客户端搜索查询内容,并将这两条文本数据从数据库中删除,其所对应的产品编号分别为′7901622466′、′B0000002JR′。同时,随机选取数字音乐数据集中的12个产品,其所对应的产品图片描述信息如图13所示,图中所展示的物品从左到右的产品编号依次是′5555991584′,′7901622466′,′B0000000ZW′,′B00000016T′,′B00000016W′,′B00000017R′,′B0000001BA′,′B0000001P4′,′B0000001VZ′,′B0000002HZ′,′B0000002J9′,′B0000002JR′。计算这12个产品各自的评价文本融合前后与客户端搜索文本的余弦相似度,从而找出根据搜索内容模型给出的推荐产品,实验结果如图14所示。

图13 数字音乐数据集中12个产品的图片信息
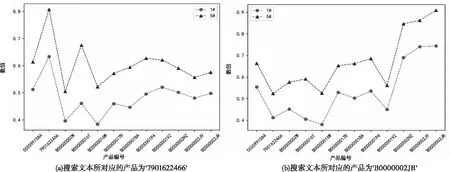
图14 融合前1#与融合后5#查询出的文本信息
对于搜索文本“This is the absolute peak of Petra’s rock career. This CD defines John Schlit’s highest level of achievement as the band’s lead singer. Jekyl and Hyde is a harder rockin CD,but ON FIRE! sets the pace.”融合前后查询出来的文本信息如图14(a)所示,可以看到融合前后模型最优查询产品都是′7901622466′,而次优推荐的产品却不相同,1#模型查询的结果是′5555991584′,5#模型查询的结果是′B00000016T′。虽然次优查询结果都是关于摇滚音乐,但是′5555991584′历史评价更多描述的是“New Age”、“Meditation”等词,而产品′ B00000016T ′ 的评价文本较多是“Alternative Rock”、“New Wave & Post-Punk”、“Album-Oriented Rock (AOR)”等词,更偏向于硬摇滚的风格。
对于搜索文本“This is Alison Krauss at her best. This CD is full of killer songs played wonderfully by great musicians. Her voice soars! The music is more bluegrass than her recent CDs that are filled with ballads. But this still has a great mix of fast & slow songs.”融合前后查询出来的文本信息如图14(b)所示,可以看到5#的最优推荐是′B0000002JR′,与搜索文本所对应的产品编号是一致的。而1#的最优推荐是产品′B0000002J9′和′B0000002JR′,这是因为′B0000002JR′和′B0000002J9′都是Alison Krauss创作的歌曲,且属于bluegrass系列。而′B0000002JR′专辑的音乐更注重乐调和声音的变化、如历史评价“…and her voice still has most of that thin,reedy quality that you associate with bluegrass. But if you listen,it’s just beginning to warm up some and lose that young-girl quality…”、“…that have made her famous with her angelically emotive voice…”、“…It’s amazing how strong her voice was at such a young age…”等,这与搜索文本中所出现的关键词“voice soars”、“mix of fast & slow songs”所对应,′B0000002J9′评价文本则更多的强调的是“fiddle”、“band”、“Jeff White”、“young”等信息,与搜索文本有所差别。
从上面的融合前后查询例子中可以分析,本文所提基于双相似度加权的用户生成多源文本融合策略能够更明确的捕捉到客户端查询内容和产品数据库的实际关联程度,经过加权融合处理的评价文本向量化表示能更加全方位的展示产品真实信息,这为后期的个性化搜索推荐系统的精准性奠定了基础。
5 结论
用户生成内容已成为当前面向用户个性化服务的重要数据组成,对其价值的充分挖掘和应用正逐渐成为当前大数据领域研究的热点之一。本文针对用户生成的历史文本评价信息,考虑基于用户查询内容的文本融合表示,提出了面向用户认知和偏好双相似度的多源文本融合策略。算法首先利用Doc2vec将与用户查询文本相关物品的多源文本向量化,然后计算各评价文本和查询文本的余弦相似度和欧氏距离,进而给出基于上述相似准则的相似度权重,以及权重融合策略。所提算法在亚马逊数据集的应用表明了其融合的精准性和可靠性。如何充分利用融合后的物品文本向量化表示将是未来工作所需进一步考虑的问题。
