融合多特征的海内外复杂车牌识别技术的对比研究
2022-11-11韩浦霞
韩浦霞
(天津商务职业学院 天津市 300350)
1 国内车牌识别技术
随着近几年人工智能技术的发展与普及,机器学习算法越来越多的被应用于车牌识别开发技术中,且识别率较高。车牌识别技术作为提升国家智慧建设中的一部分,是智能交通管理中的重要一环。有效识别车牌不仅仅可用于安防排查,也有益于提升人们的生活质量,为推动社会智能化贡献了卓著的力量。
国内车牌识别技术比较成熟,常见的车牌均为蓝底白字,此种车牌规律性强,排版统一,便于识别。国内车牌分为大陆版本和港澳台版本,大陆版本的车牌结构规则单一,字符间距、字符个数、字符位置固定,因此识别较为容易。港澳的车牌类型则比较多样,常见为英式车牌格式,单牌车牌居多,但也有双牌车牌,且两个车牌位置相对靠近,为车牌识别时的车牌定位工作增加了难度。中国台湾车牌常见为英文和数字的组合,与国外的普通车牌类型接近,如图三所示,其车牌识别方法可参考国外的成熟算法。国内目前的商用车牌识别的场景一般是处于相对固定的角度,以及相对稳定的环境下进行拍摄识别的,因此摄像头拍照的清晰度以及光照强度均满足识别要求,常见的是社区商用车牌识别系统、交通道路车牌识别系统等。中国大陆车牌与港澳台车牌样例如图1所示。

图1:内地与港澳台车牌图片
我国积极推动新能源汽车的普及,因此越来越多的绿牌出现在我们的视野里。新能源车牌又细分为小型新能源汽车车牌和大型新能源汽车号牌,这两种在配色上稍有不同,前者为绿色渐变底色,黑字车牌,后者为黄绿拼色,黑字车牌。车牌底色的多样化,也为识别算法的准确性增加了难度。
我国车牌系统特有的汉字特点也是有别于国外的车牌系统的,需要创建合适的训练模型来识别车牌上的汉字。由于整套汉字识别与数字字母的识别不同,需要创建两套独立的训练字符模型,以免互相混合训练影响识别的精确度。
国内成熟的商用车牌识别算法,多借鉴国外优秀的研究技术,但由于国内外车牌编码的区别,又开发出我国特有的识别模式。在常规环境场景下,车牌的识别率往往能达到95%以上,对于污损车牌或者环境较为复杂的车牌识别率则有所降低。
2 国外车牌识别的难点
国外车牌识别技术研究较早,有比较成熟的字符识别算法,但是对于车牌识别领域却存在很多难点。相较于国内车牌而言,海外车牌存在编码结构不规则的情况,例如字符间距、字符个数、字符间距位置等不固定,这就无法应用国内这种结构化车牌算法的模型进行套用,而需要开发动态字符间距的模型。
泰国车牌识别的难点在于泰文的识别部分。泰国车牌编码格式为数字与泰文的组合,数字部分识别可以参考成熟的识别算法,但是泰文部分则需要利用深度学习框架,获取泰文的详细特征。许多泰文存在相似性,并且出现在泰国车牌上的辅音泰文有37种,这些结构相似且种类繁多的特点为字符识别带来了很大的困难。如图2所示的泰国车牌的泰文种类表,从图2中可以看到,如果用这些泰文图片进行模型训练的话,高度相似的泰文则存在很大识别难度,因此泰文的识别率会有所下降。

图2:泰国车牌上的泰文种类
澳大利亚车牌的特点比较鲜明,车牌编码规则多且极具个性化。常见的普通车牌是由6位字符组成的,包括3位字母与3位数字,一般都是连在一起,前后顺序根据各个州而有多差别,当然也有“4+2”的编码格式,或者5位字符的车牌。除了单层字符组合的车牌之外,也有双层字符的车牌组合。2019年澳大利亚出现的车牌新规中表明,可在车牌背景处添加emoji图片,实行个性化定制。这一举措无疑又增加了车牌字符分割的难度,很容易将emoji图片作为合法字符进行分割并识别,或者进行车牌背景二值化时无法将emoji图片去除,以上均会导致车牌识别准确率下降。
日本车牌识别的难点在于车牌字符内容过多,且分为上下双层。日本的车牌号码由四部分组成,从上到下,从左到右依次为地名、分类号码、平假名和车牌号码。识别过程中,首先需要确定车牌的上下层,并对上下层字符分别进行分割和识别,最终将结果组合在一起,形成最终的识别结果。那么正确确定上下层的位次,并正确识别多种类的数字与日文字符就十分关键。
美国车牌识别的难点则在于不同州之间车牌背景具有很大的差异性。美国车牌属于极具个性化的车牌之一,每个州的车牌设计添加了独有的图案作为背景,各个州之间车牌的使用规则也不尽相同。例如伊利诺亚州的车牌,为纪念亚伯拉罕•林肯,在背景处添加了林肯的画像。缅因州则是将其州鸟作为车牌的背景图。犹他州将美国最著名地标之一的“玲珑拱门”作为其车牌背景。多种多样的背景图案,为扣取字符、去除背景时增添难度。多样性的背景图案使得车牌图像进行二值化操作后出现混淆字符的情况。海外车牌图片样例如图3所示。

图3:海外车牌图片样例
3 国外车牌识别算法框架
国外车牌识别系统采用高度模块化的集成设计,将整个车牌识别的流程中的各个环节作为相对独立的模块。本文的海外车牌识别系统将整个框架分为八大模块,分别为车牌定位模块、字符获取模块、字符识别与融合模块、获取字符链模块、图像矫正模块、字符链灰度投影模块、模型匹配模块、字符训练模块。各个模块之间相互独立且紧密联系,算法框架流程图如图4所示。
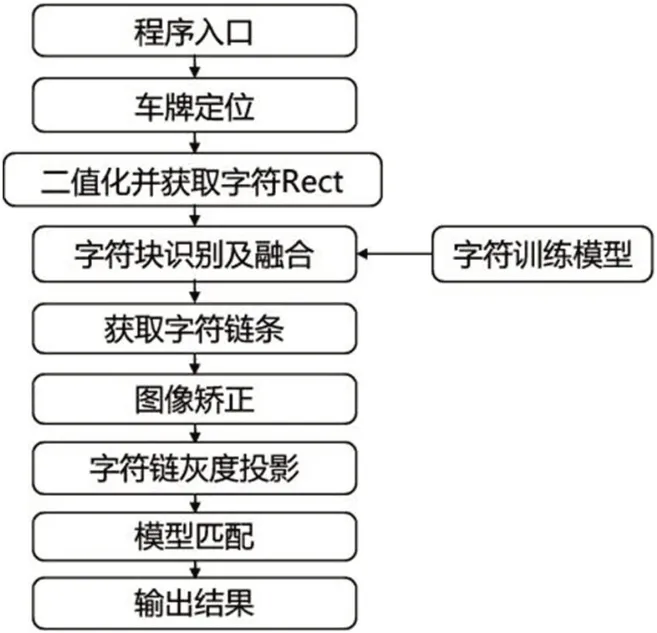
图4:算法框架流程图
3.1 车牌定位模块
车牌定位模块主要是将所有可能车牌的区域找出,依据车牌图片的颜色特征、纹理特征和梯度信息进行框选。颜色特征主要是通过强烈的色差对比性进行分割。字体颜色与背景颜色往往存在较大色差,且国外车牌背景多较为复杂,因此不采用彩色图像进行定位,而是通过对车牌图片进行灰度转换,将深色底与浅色字进行区分。纹理特征一般是依据车牌内固定的字符规则,形成较为特殊的纹理性,利用车辆图片的扫描线,其灰度值会有规律性跳变。梯度信息是根据车牌规则的矩形形状或因拍照角度问题导致的类四边形形状提取的,宽高比一般会设定基准范围,标准车牌的宽高比是3.14,那么选择可能为车牌的图形比例则在该值附近。将三个特征综合考虑,分别匹配不同的权重,获取不同置信度的可能车牌,将置信度低于0.5的可能车牌过滤,保留高置信度车牌,并将其排序,后续按照可能车牌的置信度由高到低进行识别。
3.2 字符获取模块
车牌定位后,需要将框选的车牌进行字符分割,基本的分割思想为将框选车牌图片进行二值化操作,设置5个能量及局部灰度阈值,依据国家不同而选择不同。本研究是采用基于边缘轮廓的字符分割方法,车牌图像二值化后,通过边缘检测进行字符框选,实现各个字符的分割。同时应对因拍摄角度或者车牌自身问题导致的图片变形问题,增加垂直投影。由于可能将非正常字符误判而进行框选,通过字符的宽高比进行限制,例如某些车辆图片前端具有栅格,可能会进行误判,但是框选出的字符极窄,这类字符则可依据宽高比进行限制。或者车牌字符存在粘连,导致框选时将两个字符误判为1个,此时字符呈现宽扁状,也可依据标准字符宽高比进行限制。实验结果如图5所示。

图5:灰度图与能量图二值化字符分割结果
3.3 字符识别与融合模块
字符识别依据实验训练的字符模型进行识别,通过深度学习框架,对大量的字符进行模型训练,不同训练字符分为不同的单字符模型,例如泰国车牌的字符训练模型包括47种字符,根据字符在各个单字符模型中的识别置信度进行判断,选取最大置信度的所属字符模型,将该模型标签认定为该字符的识别结果。相近字符的识别结果容易混淆,出现误判,解决此情况的最优方法即增大训练样本,优化训练模型,如果后续仍出现字符误判,则可根据车牌规则进行强转。
字符融合是依据字符块的位置、字符块面积以及字符识别置信度进行的。位置相近且高置信度识别结果的字符块,可将其融合为一个字符块,如图6所示。字符融合可以尽可能的减少字符块冗余,去除非车牌区域的字符块,降低后续识别成本。

图6:字符块融合
3.4 获取字符链模块
针对海外车牌经常存在上下层字符的情况,需要确定所获取的字符块是否为同一链条上。本研究将处于某个斜率范围内的一组字符块进行判断,选取斜率绝对值最低的4组。正确选取字符块链条,可以进一步计算出图片的倾斜角度,并为后续的图形矫正提供依据。如图7所示,为双层牌寻找到的两条字符链,并确定出底层主链。

图7:字符链结果运行图
3.5 图像矫正模块
实际环境下拍摄的车牌图像并不能保证绝对水平,由于车牌自身污损情况或者拍摄角度不佳,常常会导致车牌图像存在偏转。依据字符链模块的结果,可以对其进行矫正。主字符链的倾斜斜率可以作为矫正的主要参考,计算当前字符链的最佳上下边缘,去掉最大值与最小值,计算其平均值,矫正后及时更新原字符块的位置信息,避免矫正前后字符块差异较大。矫正时分别进行水平方向与竖直方向的矫正。完成矫正之后,可以再次对低置信度的字符块进行识别。车牌图形矫正结果如图8所示。

图8:车牌矫正结果
3.6 字符链灰度投影模块
实现车牌图像字符块分割时,可能会出现正确字符未正常分割的情况,此时则依赖字符链灰度投影进行二次分割。本研究使用的灰度投影方法是从最初始的字符块开始,从左向右依次查找其它可能字符块,查找完成后将最左值与最右值保存下来,并且记录字符块个数。然后进行灰度投影,并统计字符块的梯度平均值。同时计算字符块的上升点与下降点,寻找最佳位置。然后再利用间隙进行填补,如果发现间隙较大,则插入新的字符块。将每条字符链如此投影一次,补全字符链缺少的字符块信息。字符链灰度投影结果如图9所示。

图9:字符链灰度投影
3.7 模型匹配模块
模型匹配模块是整个车牌识别项目较为复杂的模块之一,需要依据车牌编码进行模型设置。首先车牌编码可以按照单双层进行分类,双层车牌则按照单层车牌的识别方法逐行识别,最终将两个识别结果进行结合。由此可见,无论单层车牌还是双层车牌,均可按照单层的模型进行匹配。本研究进行模型设置时,依据车牌字符之间的间距设置不同的动态模型,例如“2+3”模型,即为共5个字符,分为两个部分,一部分为2字符,另一部分为3字符,两部分之间的间距较大,但字符之间的间距满足动态变化。该模块程序执行的伪代码如图10所示。

图10:模型匹配模块伪代码
模型匹配时,选择起始匹配字符块,对应到预设模型的位置,计算下个字符块节点的匹配,最终实现将所有字符块匹配到模型里,获取当前字符链对所有预设模型的匹配结果,然后依据结果置信度,选择出最优的几个匹配结果。
当模型匹配后存在多个匹配结果时,需进行模型评价。对获取到的多个匹配结果进行置信度评价,通过winnertake-all竞争方法,获得每个预设模型的最佳匹配结果。单链模型匹配结果图如图11所示。

图11:单链模型匹配结果图
3.8 字符训练模块
由于Gabor变化在图像局部频率和方向上具有很大优势,因此本研究对训练集图片进行Gabor变换,提取字符块的Gabor特征,再利用ANN算法实现字符模型训练。模型的优劣性很大程度上依赖训练集的图像品质与数量,数量越多,模型训练将越准确。本研究对4026幅实际环境中车牌的泰文字符块图片进行训练,模型识别正确率为94.75%。
4 海外车牌识别算法框架对国内车牌识别的影响
海外车牌识别算法框架所解决的主要受体是复杂情况下的车牌识别问题,这对于我国国内的车牌识别也有很大帮助。国内经常出现污损车牌的情况,这类车牌在识别过程中容易效果不佳。常见有车牌字符模糊、车牌背景噪点、车牌弯折等情况。
4.1 车牌字符模糊的情况
针对此种车牌污损,主要可充分借鉴该海外车牌识别框架中的字符识别与融合模块以及模型匹配模块。首先需将同一字符进行多次分割,提取该字符块的较高置信度的切割块,融入字符训练模型,增强该字符的识别冗余度。同时结合预设模型的基本结构,可以进行后期的识别干预。例如预设模型该位为数字,即可排除将该位识别为字母的情况,也可依据模型规则,将字符识别结果进行强转。
4.2 车牌背景噪点的情况
针对车牌背景噪点较多的情况,可以充分结合该海外车牌识别框架中的车牌定位模块。通常情况下,车牌噪点与车牌背景颜色或者纹理差异较大,那么此时依据灰度信息或者纹理信息可以提取出正常车牌字符以及噪点图像,但是噪点图像的宽高比或者宽度和高度数值往往与正常车牌字符差异较大,因此可通过字符宽高信息加以限制,过滤无效噪点。同时也可参考切割的字符块的置信度,因噪点字符块并未加入模型进行训练,那么一般识别的字符置信度较低,可直接排除。如果该噪点为车牌的常见噪点,例如车牌的螺丝连接处,可将该噪点图片进行分割提取,加入字符训练模型,将该字符训练结果设置为无效字符,那么再遇到此类噪点,便可通过字符识别结果将其排除,真正实现多重过滤。
4.3 车牌弯折的情况
车牌若本身存在弯折,则可能会导致车牌字符拍摄不全或者拍摄车牌弯曲。如果出现车牌拍摄不全的情况,则无法通过算法框架进行优化。如果拍摄的车牌出现弯曲,则可结合该海外车牌识别框架中的图像矫正模块以及字符链灰度投影模块。图像矫正模块可以充分考虑水平方向与竖直方向的弯曲程度,进行初步矫正。字符链灰度投影模块则可进一步根据字符链的倾斜方向进行矫正。双重矫正可以有效将拍摄到的弯曲车牌转为正向车牌再进行识别。
海外车牌识别框架不仅仅可以提高海外复杂车牌的识别率,对于我国国内的污损车牌识别效果也有很大优化,可有效地提升我国污损车牌的识别效率,积极促进我国进一步构建智慧化交通系统。
5 结束语
海外车牌识别相较于国内车牌识别存在许多困难,车牌规则多样,车牌背景多变,设计出鲁棒性强的海外车牌识别框架就显得十分重要。将整个框架细分为八个模块,不同国家可依据不同的匹配模型进行细微调整。针对双层车牌可先将其按照单层车牌对待,后依据预设模型进行字符链外扩,增加上层字符识别。海外车牌识别系统的实现,进一步提升了复杂场景下车牌识别的效果,促进车辆管理的效率。同时也可提升我国国内污损车牌的识别效果,加速国内智能交通系统的建设。
