用于医药经济精准营销的GBDT-Logistic回归融合模型的研究
2022-11-09王国金
王国金
(山东省食品药品检验研究院, 山东,济南 250101)
0 引言
近年来,经济形势的发展,促进了大数据技术的进步和突破,从而使得医药精准营销策略有了实现的前提[1]。随着不良的生活习惯和各种不健康饮食的出现,人们身体出现亚健康的情况屡见不鲜[2]。各种慢性病、心脑血管病、老年病等发病人群越来越年轻化、数量也越来越多[3]。
传统医学的发病后就医情况,治愈成本高、治疗效果差,已经逐渐不能满足当前人们健康的需求[4]。由于医疗资源有限、药品供应不及时等,医患矛盾加剧,“看病难,买药贵”成为老百姓的心头之痛[5]。通过大数据技术对人群的身体状态进行监控,对于易感人群进行药品推销,对于疾病传播做到精准防治,对医药经济的发展具有重要的意义[6]。
利用大数据技术,优化医疗资源分配,精准定位药品营销[7]。本文基于大数据技术,构建GBDT-Logistic回归融合模型,优化药品资源的分配,促进医药精准营销,对医疗疾病等信息领域的发展做出预测,对于提高人们生活的幸福指数具有重要的意义。
1 医药经济营销预测模型
1.1 医药大数据的研究意义
丰富的医疗数据资源可以为人们提供优质的信息服务,指导医药企业对处于亚健康状态的人群提供药品,不仅能够实现当前形势下的精准医疗,也能够使药品资源分配有的放矢,药品企业的利润也能得到有效保障[8]。
针对医疗大数据的研究,尤其是将其用于指导医药经济精准营销方面,具有如下重要意义:
(1) 有效了解亚健康人群的身体动态,并进行有针对性的疾病治疗和药品提供。
(2) 深度结合试验数据,做到高效用药、精准用药。
(3) 个性医疗,对于环境等进行精确分析,及时预防传染性疾病等的发生和传播。
1.2 Logistic回归模型
对于医疗数据进行分析,现有的主要分析方法包括BP神经网络、回归模型、层次分析等[9]。本文所研究的Logistic回归模型在医疗数据的分析方面实用性更强、预测效果更好[10]。
同时,本文采用的Logistic回归模型也是最常用的医学数据分析方法,相对于其他回归方法,亚健康预测的准确率方面远远优于决策树、最小二乘法等分析方法,预测准确度高、性能好。
该算法的函数表达式为
(1)
变换后,可以表示为
(2)
对式(2)进行求导,可得:
g′(z)=g(z)(1-g(z))
(3)
利用极大似然估计,该算法的单一样本概率可以表示为
p(y|x;θ)=(hθ(x))y(1-hθ(x))1-y
(4)
整个样本的概率为
(5)
式中,i=1,2,3,……,m,i表示样本的位置。
Logistic回归模型的意义在于寻找所有大数据样本中所有数据属性影响最大的那几个,从而对其进行有针对性的研究,找到该属性的影响及发病概率等,通过并发症等的研究,也可以提前对该病情做出有针对性的预防,降低疾病的危害。
1.3 GBDT回归模型
迭代决策树算法(gradient boosted decision trees,GBDT)模型为决策树模型的一种。整个模型的计算结果表示为T,T中的元素Tj表示该模型计算的前j-1棵树的预测结果残差,数据多次回归后,可以求得模型的预测结果。
对于疾病状态的预测过程,通过对目标的数据样本输入,对其做出相应赋值,通过所有决策树的预测和数据更正,所有决策树的计算结果累加后,可以获得该预测的数据结果。预测结果的表示式为
F(x)=F0+α1T1(X)+α2T2(X)+…+αmTm(X)
(6)
式中,α为每棵树的权重系数。
GBDT模型将每棵树的残差数据进行拟合,可以具有泛化能力强、不过拟合的特点,可以结合Logistic回归模型,用于药品营销的预测。
算法的流程如下。
输入医疗大数据训练集T:
T={(x1,y1),(x2,y2),…,(xN,yN)}
(7)
数据初始化:
(8)
在回归树所有的分量中,寻找其中结果最好的数据区域,并寻找数据结果最好的c点。
(9)
式中,J代表每棵树的叶子数量。输出结果为fm(x)。
1.4 GBDT-Logistic回归融合模型
Logistic回归模型虽然能够在一定程度上完成疾病预测的任务,但是该模型不具备很强的学习能力[11]。将其与GBDT模型深度融合,发挥GBDT模型学习能力强的特点,形成GBDT-Logistic回归融合模型[12]。
GBDT-Logistic模型可以从医疗大数据的数据库中精确总结出对应目标和对应区域的医疗特征,结合评估模型,总结出该目标和该区域的亚健康状态,预测精度更高、效果更好[13]。
回归模型的融合过程如下。
(1) 确定融合模型的目标函数:对于医疗大数据来说,目标的身体状态包括健康、不健康和亚健康等状态,确定其状态输出交叉熵为其优化目标。
(2) 总结数据区域特征:总结出亚健康人群目标的身体参数,如睡眠质量、身体状态等数据。结合医生的医疗诊断,总结出目标的身体特征,并进行数据训练。
(3) 训练模型选择:GBDT模型在总结目标的医疗特征方面具有明显的优势,利用决策树的残差优化,可以直接给Logistic回归模型提供输入数据,提高运行效率。经过辨识后的数据可以准确预测目标的身体状态,为医药数据精准营销提供条件。
本文设计的医药精准营销流程如图1所示。
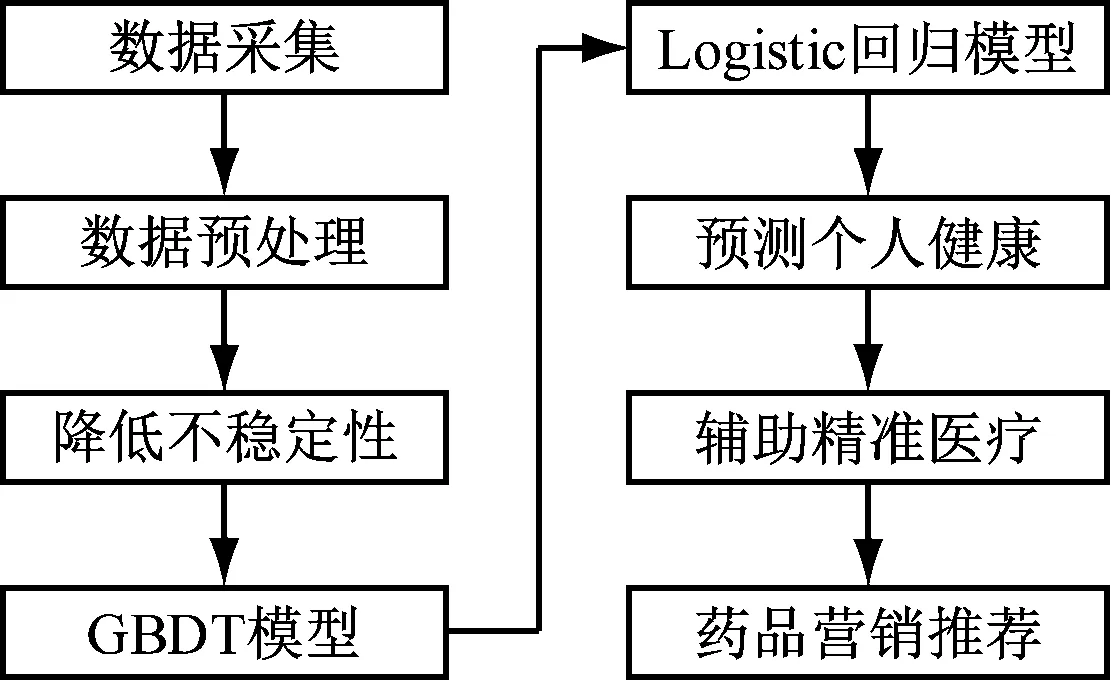
图1 医药精准营销流程
在整个药品推荐的流程中,将不同数据属性的药品和信息等进行数据集成,使其共存于一个动态图中。通过机器学习的方法,不断对目标身体健康状态和药品知识进行学习和分析,从而通过优化模型对其进行预测,发现数据之间的相关性,提取出样品数据中的异常数据,为药品精准营销提供更好的数据分析结果[14]。
对于医药大数据中的文本信息,也要进行分析处理,得到其内在规律。文本数据的医药实体抽取过程如图2所示。

图2 文本医药数据抽取
常用的医药实体抽取数据包括目标疾病信息、通常发病位置、常购药品规格、发病群体特征等信息。对其进行总结后,存入数据库中,用于对应药品的分析提供。
融合后的预测模型操作步骤如下。
(1) 综合个体和群体的属性特征,进行数据整理。
(2) 通过GBDT模型进行大数据机器学习,总结整理不同因素的影响权重ai。
(3) 通过Logistic回归模型确定不同目标属性bi的目标预测函数M。
(10)
其中,
(11)
权重关系ai也能反映出不同属性之间的关系比重。通过整体的权重关系比较后,可以预测目标个体的健康指标,并总结出其健康程度,进而进行相应药品推荐。
将生理亚健康数据代入整个模型中,可以总结出目标的亚健康状态。以某目标的健康状态为例:
(12)
该目标的高低血压状态、血糖状态、体重身高平分比、睡眠质量等均是衡量健康状态的指标,任何超过正常指标的数值均定义为危险状态,需要进行及时的药品信息和健康信息传递。
1.5 医药经济精准营销
医药经济的营销离不开医疗知识数据的出版,传统的医药知识数据具有如下特征[15]。
(1) 医药数据结构复杂,药品种类繁多,不同疾病、不同人体的禁忌情况也需要慎重考虑。
(2) 医药知识的特殊性。药品推荐需要综合考虑病例、习惯用药等,准确的症状分析处理是药品经济精准营销的前提。
(3) 文字特征描述,需要转化成可以总结的数据,并进行数据整理、分析。药品与药品之间的关联、疾病与药品之间的关系都是需要综合考虑的因素,进行对症药品推荐。
(4) 公共群体性特征。对于大范围传染性疾病特征,可以通过数据整理进行定点药物投放,提高社会群体的免疫力和抵抗力,从而提高人们的身体健康程度,也是药品经济发展的一个方面。
药品营销的策略主要包括线上药品提供、线下零售推销、针对性的一对一数据广告、创意健康用品推销等。这些策略的实施有助于推动药品精确营销的结果,提高百姓的认可程度,实现价值的互换。
2 实验结果与数据分析
2.1 实验数据
本文所采用的实验数据来源于东部某地区的常住人口健康状态图,对不同年龄、不同职业、不同性别、不同群体、不同层次的人口进行数据总结。实验中的数据来源于体检健康中心,通过对其进行数据整理得到其身体健康状态数据,建立区域性健康特征数据库。
医疗大数据的处理过程包括数据特征抽取、数据结果挖掘、数据关联性整理等方式,并与医生的体检健康指标确诊进行验证,从而建立出数学模型,用于药品推荐和居民健康情况预防。
2.2 实验结果
对于预测结果的准确性指标,主要考虑预测准确率指标、预测召回率指标和适用用户指标3个目标。将本文模型与其他常用的医药推荐方法相对比,如知识图谱法和购药行为分析法等,结果如下。
(1) 准确率指标
本文算法与其他算法的准确率对比结果如图3所示。在相同的环境下,数据采用60天的时间消费数据进行对比。

图3 不同算法的数据药品推荐准确率对比
从图3可以看到:常用的药品推荐准确率只有20%~30%,准确率并不高;而本文采用的方法,准确率达到约50%,远远超过其他2种方法。
采用相同的方法,利用线下销售推荐数据准确率进行对比,实验结果如图4所示。

图4 线下销售准确率对比
由图4可以看到,对于药店的推荐,用户目标具有一定的排斥,推荐准确率相比实验环境更低,但是本文算法准确率依然到达40%,高于其他2种方法。
(2) 召回率指标
召回率指标主要用来衡量在所有的待推荐药品中有多少被正确推荐出来。召回率的实验对比结果如图5所示。
从图5可以看到,对于召回率指标知识图谱方法和购药推荐方式的召回率均在10%~20%。其中,知识图谱的方式要优于购药行为推荐,但本文的模型召回率超过30%,明显优于其他2种方法。

图5 召回率计算数据对比
同理,对于召回率指标,依然需要采用线下零售的推荐数据进行对比,结果如图6所示。
从图6中可以看到,对于线下零售的召回率指标,知识图谱的方式召回率约30%,要远远优于基于购药行为推荐的约20%。主要原因在于线下销售的数据基数大,推荐次数多,成功的效率就高。但本文的方法召回率接近45%,从结果上依然优于其他2种方式,证明本文方法的有效性。

图6 召回率线下销售数据对比
(3) 适用用户指标
适用用户指标反映推荐合适的用户与总推荐人数的比值,反映了不同推荐方式的效果。适用用户指标如图7所示。

图7 适用用户情况对比结果
从图7可以看到,基于用户购药的推荐技术,利用购药行为推荐标准的用户占比为19%,而基于知识图谱的推荐技术用户为31%,基于本文方法的用户占比为50%,证明本文算法在上述3种推荐方法中是表现效果最好的。
2.3 实验结果分析
对于预测结果不准确的情况,主要原因包括:
(1) 新用户数据推荐。对于没有相关数据的用户,无法套用本文的算法,需要根据实际情况来进行推荐。
(2) 非传统疾病推荐。对于存在慢性疾病的目标患者,其突发疾病的推荐准确率会明显降低。但对于药品营销来说,突发性疾病及健康人群的药品推荐本身就是缺乏规律性的。
从实验结果上看,本文的算法均优于其他2种方法,主要原因在于本文算法充分考虑了推荐对象的各个数据属性,可以更全面地了解患者目标状态,并可以有效辅助目标对于自身亚健康状态的改进,针对不同人群属性的亚健康状态进行细致分析,并不断修正案例库,以提高对于医药推荐的精确性。
3 总结
针对医药经济发展所需要的精准营销模型算法,本文采用了经过大量实例验证过的多维数据算法。利用GBDT模型与Logistic回归模型结合,充分利用两者的优势;利用GBDT模型的输出结果作为Logistic回归模型的输入,提高回归模型的学习能力,使其预测结果更精确。通过区域性医疗大数据作为实验样本,进行药品推荐预测,从实验结果上看,本文的回归融合模型,无论是预测准确率,还是推荐的召回率等指标均是最佳,体现了本文算法的优越性,可以用于指导医药经济的营销推荐,具有一定的市场价值。
