基于雾计算的无线传感器网络联合入侵检测算法
2022-11-09朱梦圆陈卓刘鹏飞吕娜
朱梦圆 陈卓 刘鹏飞 吕娜
(1. 空军工程大学 信息与导航学院, 西安 710077; 2. 解放军 94619 部队, 六安 237000)
随着无线传感器网络在民用和军事领域日益广泛的应用,其网络安全问题渐趋突出,无线环境固有的特性使无线传感器网络的信息流量更易遭受假冒、窃取、伪造和篡改等攻击[1]。 及时检测隐藏于正常流量中的各种网络攻击,对安全、可靠的信息传输具有重要意义。
近年来,机器学习算法逐渐应用于入侵检测并取得了较好的效果,传统的机器学习方法大多针对地面有线网络,多使用集中式学习方法,将流量数据汇总集中处理分析。 文献[2]提出一种基于深度神经网络和K 近邻算法的集中式入侵检测方法,在公共数据集上进行评估,具有较高检测准确率。 文献[3]提出基于极限学习机的分层入侵检测方法,根据无线传感器网络的功能对节点进行聚类,提高了入侵检测精度,并且降低了检测时间,但是在网络中攻击流量占比很小,流量类别不均衡的情况下,算法的误报率较高。 文献[4]提出一种基于循环神经网络算法的集中式入侵检测算法,在软件定义网络(software defined network, SDN)环境中具有较好地入侵检测能力。但上述集中式学习属于传统方法,难以适用于无线传感器网络。 对于无线传感器网络信道不稳定的特征,集中式学习模式不仅会带来带宽资源紧张和网络流量数据传输的高时延、高损耗问题,而且在采集数据时易造成较高的通信成本和隐私泄露问题。
基于雾计算的分布式学习方法可以较好的解决这些问题[5]。 这种方法可以将计算任务卸载到网络的雾计算节点上,如基站、小型服务器等设备,模型更靠近数据终端,能够更快地进行检测报警等响应。 但是由于无法监管参与者在本地的训练行为,分布式学习容易遭受噪声数据、数据投毒、对抗样本的威胁[6]。 在多种分布式学习解决方案中,最初用来解决数据孤岛和数据隐私问题的联合学习在入侵检测领域展示出极大的优势[7]。 综上所述,针对无线传感器网络中流量类别不均衡、集中式学习方法不适用、分布式学习易受攻击的问题,本文提出一种新型分布式联合入侵检测算法Fed-XGB。 在3 个数据集上进行评估,结果显示,本文模型相比于其他集中式模型和分布式模型具有较高的检测分类性能,且通信成本较低。 同时,Fed-XGB 算法还能够有效地检测无线传感器网络所面临的各种网络威胁,如拒绝服务攻击、侦察攻击、黑洞攻击等,在中毒攻击和数据含有噪声时依然具有较为稳定的检测性能。
1 相关工作
雾计算作为新一代的分布式计算架构,将数据获取、处理和传输分散在网络终端设备,从而减少云端数据中心和终端设备间的交互次数和业务量,缓解链路带宽和中心节点能耗压力,缩短时延[8]。 近年来逐渐应用于入侵检测领域,文献[9]提出了一种基于改进卷积神经网络(improved convolutional neural network, ICNN)的雾计算入侵检测算法,使用KDD CUP99 数据集验证了该算法的有效性,但算法在面对不均衡数据时检测效果不理想。 文献[10]提出了一个新的分层分布式入侵检测系统(hierarchical distributed intrusion detection system, HD-IDS),可以基于雾计算模型来检测网络是否存在异常,收敛速度快但协同检测方案效率低,误报率高。
文献[11]引入联合学习算法并利用多个雾节点上的学习模型对全局模型进行优化,从而帮助参与者摆脱局部偏好,得到更准确的全局模型,证明了联合学习适用于雾计算架构。 但是在无线传感器网络中,由于各个设备上的数据是用户独立产生的,任何特定用户的本地数据集都不能代表总体分布,这造成联合学习的样本数据属于Non-IID 数据,这对联合学习算法的收敛性提出了考验。 因此,需要研究适用于无线传感器网络的联合学习算法。 针对Non-IID 数据,文献[12]创新性地提出了联邦平均算法(federated averaging algorithm, FedAvg)算法,该算法将每个客户端上的本地随机梯度下降(stochastic gradient descent, SGD)与执行模型平均的服务器相结合,在Non-IID 数据上取得了较为稳定的分类性能,并且与经典同步随机梯度下降算法相比,FedAvg 算法所需通信轮数降低了10 ~100 倍。 文献[13-15]证明了基于采用联合学习的入侵检测系统能够达到90%以上的检测准确率,每个节点使用最合适的学习模型,能够提高物联网环境下攻击检测的整体准确性。 这种并行式的训练算法适用大规模的用户量和数据总量场景,同时联合学习的模型参数交互大大地减少了网络通信开销。
本文在上述研究的基础上,采用雾计算架构,更好地利用位于无线传感器网络边缘的设备为就近的用户提供服务,从而减少云中心的计算压力,并提供低延时网络服务,提高入侵检测实时性。结合FedAvg 算法在Non-IID 数据处理上的优势,提出了Fed-XGB 算法。
2 算法设计
2.1 Fed-XGB 算法
本文的雾计算架构是一个3 层网络结构,顶层是云端服务器,具有最强的计算和存储能力,中间层为雾层,由计算能力稍弱的传感器、服务器或者基站作为雾节点,为云端分担计算和存储任务,底层为终端设备。 本文采用联合学习算法,雾节点聚合不同区域不同用户的数据,打破原来的数据资源孤岛,节点不需要传输原始数据,只需要传输较少的模型参数来协同训练模型,不仅保证数据隐私,同时适合于无线网络有限且不稳定的带宽。
如图1 所示,联合入侵检测算法的培训过程包括以下3 个步骤:


图1 联合入侵检测算法框架Fig.1 Federated intrusion detection algorithm framework

步骤3 全局模型聚合和更新。 所有K个客户共享并协同训练一个全局预测模型。
服务器对客户端模型参数进行平均以获得新的全局模型。

因为任何一方所拥有的有限数据都很容易陷入局部最优,所以上述Fed-XGB 算法的全局模型聚合和更新过程可以利用其他参与者学到的模型对局部模型参数进行优化,从而帮助参与者摆脱局部偏好,得到更加准确的模型。
在无线传感器网络中,希望尽量减少从传感器设备上传的数据总量,以减少通信负担。 文献[16]验证了大量针对于客户端的局部优化与协同训练的整体优化无关,将这些模型参数上传到中央服务器的作用很小,甚至会对全局模型的收敛造成损害。 本文为了避免传输不相关的局部更新,每个客户端都需要知道全局聚合中的协同优化趋势。 在每次学习迭代中,客户应该比较他们的局部更新和全局更新,以确定他们的更新是否相关。
为此,本文算法的优化目标是在保证学习算法收敛的同时最小化累积的通信次数,即

式中:Ct为在第t次迭代中,将本地更新上传到服务器的客户端数量;f(xt)为第t次学习到的模型;f(x*)为最优模型。
本文结合Top-K 梯度选择方法和CMFL[17]算法进行梯度更新选择。 具体来说,每次训练中用户计算得到模型参数gi、hi,根据其与服务器模型参数相差绝对值的大小排序,选择相差最小的K个梯度值,服务器将聚合这K个梯度值用于生成树和模型预测。
假设第j次全局模型更新中,Wj={h1,h2,…,hN}为本地模型参数更新,ˉWj为全局模型参数,计算相同符号参数的百分比作为相关性度量标准:

若Wj和ˉWj符号相同,则I(sign(Wj)=sign(ˉWj))= 1,否则为0。 将更新的相关性度量e(W,ˉW)进行排序,再选择排名最高的K个值上传,进行服务端的模型聚合,用于生成树和模型预测。 这样,聚合机制就能够加快模型收敛速度,并且有效防止不利于整体模型的参数上传,减少Ct,降低通信开销。
2.2 基于代价敏感函数的改进XGBoost 算法
本节针对不同雾节点上的不均衡数据样本,通过引入代价敏感函数对XGBoost 算法进行改进。
XGBoost 算法基于CART 回归树模型[18],对于给定的n个样本m个特征的数据集D= (xi,yi),CART 回归树会将输入的样本特征分配到各个叶子节点,其预测函数为

式中:f(x) =wj(x),wj(x)为叶子节点j的权重,fv(x)为其中第v棵回归树。 XGBoost 算法学习的过程就是通过加入fv函数来优化目标函数,减少预测结果与实际结果之间的误差。 定义的目标函数为

式中:r为权重系数;Tt为叶子节占的个数;λ为正则化系数。
因为各个雾节点收集的流量数据类别不均衡,其中攻击类的异常流量属于小样本,所以,为了提高入侵检测模型对小样本的重视,设计每个雾节点中的代价敏感度函数为

在雾节点的模型寻找最优树结构的过程中,最重要的就是训练样本的gci和hci。 由于代价敏感函数的引入,按照Gain 进行最优分割点选择时会更加重视雾节点中的小样本类别,从而提高小样本类别的检测准确率,更适合流量数据类别不均衡的无线传感器网络。
2.3 近似算法改进
如2.2 节所述,训练XGBoost 的最优树模型需要计算增益分数Gain 来寻找分裂点。 这意味着对于每个数据样本和特征,需要计算对应的梯度gci和二阶导数hci。
大多数联合学习的梯度提升算法都允许参与训练的客户端将梯度或特征值分割候选者传输到聚合器,从而确定整体模型的最佳分裂点。 而常见搜索最佳分裂点的方法是使用精确贪婪算法,该算法枚举整个特征和值空间以找到最佳分裂点[19]。 若需要处理n个样本,d个特征,进行m轮,这种贪婪算法的复杂度就高达O(n×d×m×lgn),会增大雾节点的通信计算压力;为了弥补这一不足,本文使用基于直方图的近似算法来高效地选择最优特征[17]。
基于直方图的近似算法首先对该特征的所有切分点p(p=1,2,…,m)基于分位数分桶,得到一个候选切分集合Sp= {sp1,sp2,…,spl},然后将样本特征的值根据集合划分到桶中,对每个桶内的样本统计值的梯度和二阶导数进行累加统计得到Gpl和Hpl,最后在这些累计的统计量上寻找最佳分裂点。 分位点算法的核心思想是:根据特征的分布取其分位点,将分位点代替真实特征值,本质就是连续特征的分段离散,降低计算复杂度。但是,将这种近似算法直接应用于联合学习框架中可能会导致训练的模型无法适应各方数据的偏差,尤其是不均衡数据和Non-IID 数据中。
为了解决该问题,本文的改进算法不是以相同的比例对所有参与者的数据进行分桶,而是考虑参与者客户端上本地数据集的大小与其他参与者的大小相对比率来按比例(如百分位数)分桶。首先,定义Dp表示每个训练样本的第p维特征值和对应二阶导数:

3 实验验证
由于每个数据集都会有不同的模式和特征,如网络拓扑结构、流量特征、攻击方式等,本文使用多种基准数据集进行实验,这样可以综合验证入侵检测模型的适应性。 本文结合加拿大网络安全研究所提供的CICIDS 2017 数据集及无线网络的WSN-DS 数据集来评估模型。
实验平台为搭载了Core i9-9820x 和GTX 1080 Ti 的台式机,使用Anaconda 3 软件和联合学习框架Pysyft 进行仿真实验。 同时还使用NS-2软件仿真设计得到一个WSN-ids 数据集。 总节点规模数目为300,按照区域平均划分为30 个区域,每个区域设置一个雾节点,收集该区域中节点的数据用来训练本地模型,节点的信息通信覆盖半径设定为10 m,设置仿真时间为1 000 s,其中网络攻击时间设置为50 s。 实验共进行30 次模拟,获得总时长30 000 s 的原始流量数据。
仿真参数设定如表1 所示。
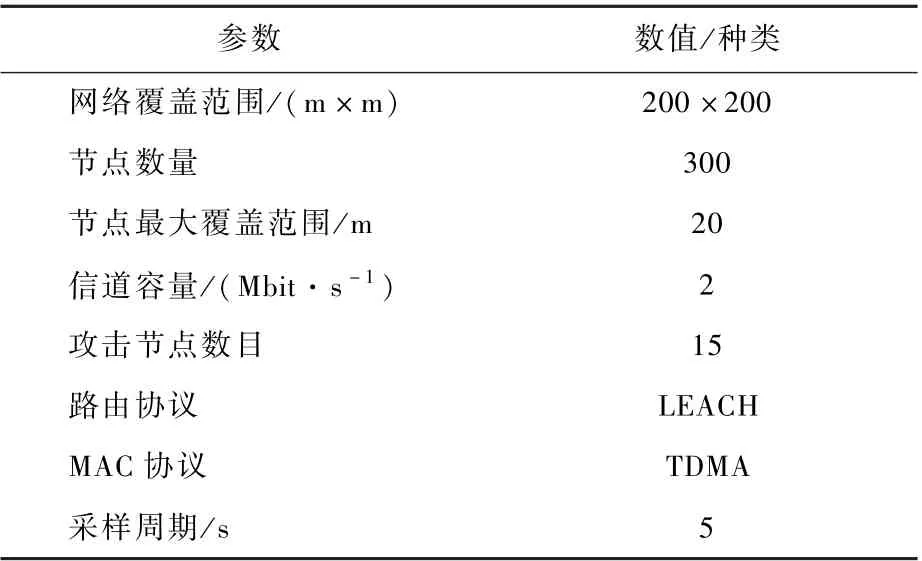
表1 仿真参数设置Table 1 Simulation parameter settings
网络攻击的模拟参照WSN-DS 数据集。 模拟了4 种攻击方式:Blackhole、Grayhole、Flooding、Scheduling。 3 个数据集的信息如表2 所示。

表2 数据集相关信息Table 2 Related information of datasets
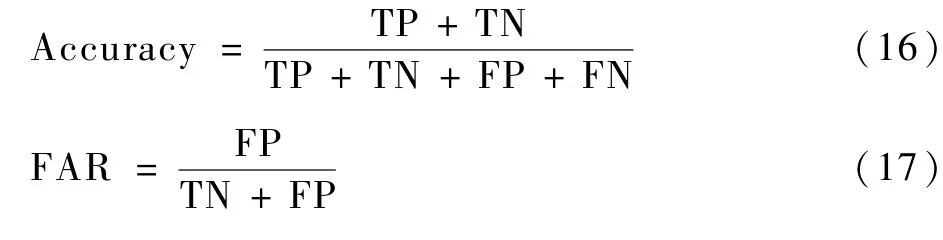
采用准确率Accuracy 和误报率FAR 作为评估指标:式中:TP 为正确分类的正样本数目;FN 为错误分类的正样本数目;FP 为错误分类为正样本的负样本数目; TN 为正确分类的负样本数目。
3.1 算法比较
本文通过准确率Accuracy 和误报率FAR 评估不同算法在WSN-DS 和CICIDS 2017 数据集中的性能,数据集按照80%:20% 的比例划分训练集和测试集。
对比的集中式学习方法选择了入侵检测领域流行的RF(random forest)[21]、GRU-SVM[22]、ICNN[23]、VAE[24]和XGBoost[25]算法。 这几种算法采用集中式的方法进行训练,设备将数据上传给服务器进行集中训练。 选择FedSGD 作为分布式学习(联合学习)的比较算法,为了更好地比较本文算法的优势,FedSGD 的训练模型统一使用XGBoost算法。 所有算法重复独立运行15 次,并计算相同的测试集上的检测准确率和误报率的平均值,结果如表3 所示。
从表3 可以看出,Fed-XGB 和本地模型VAE的检测准确率最高,误报率最低,Fed-XGB 的检测分类性能相比于集中式的XGBoost 分类准确率提高了3%左右,误报率降低了10%左右,证明了联合学习这种分布式学习也可以达到集中式学习的训练效果。 并且本文的Fed-XGB 算法相比FedSGD 联合学习算法具有更好的检测性能。

表3 不同算法整体性能对比Table 3 Comparison of overall performance of each algorithm
3.2 联合学习参数的影响
使用WSN-DS 数据集进行实验,分析联合学习参数B(训练批次大小)和E(训练代数)对通信成本即上传次数的影响,比较FedSGD 算法和Fed-XGB 算法不同的B和E下模型的分类准确率达到98%时所需的上传次数,可以看出增加E和设置较小的B会降低通信成本。
由表4 可以看出,本文的Fed-XGB 算法在参数E=20 和B设置较小时,上传次数最小,在相对于基线算法FedSGD 减少了大约21 倍的通信成本。 通常,通过将B设置为一个小数目,增加客户端的训练轮数,即将更多的计算推给客户端,即充分利用无线传感器网络中雾节点的计算资源。
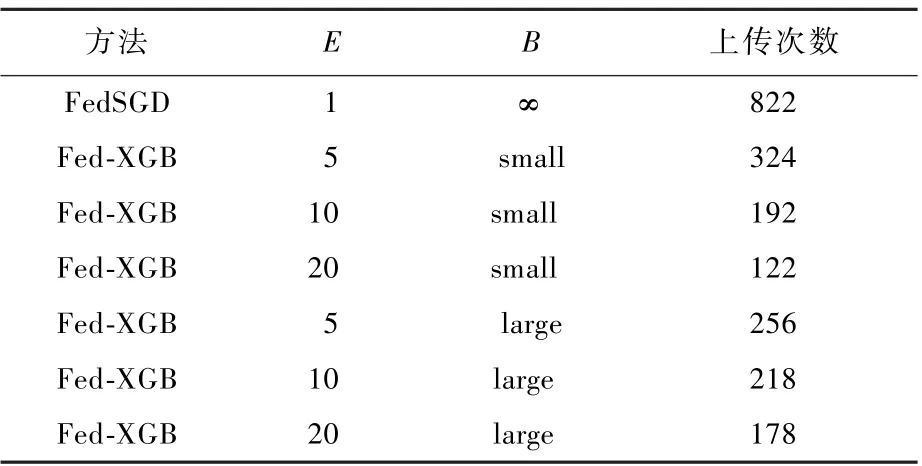
表4 不同联合学习参数对上传次数的影响Table 4 Influence of different federated learning parameters on communication rounds
3.3 不同恶意节点数量下的性能比较
使用WSN-ids 数据集进行实验,探究了不同恶意节点数目对入侵检测模型的影响。 参照文献[5]的方式模拟中毒攻击,恶意节点随机分配在划分的30 个区域中,对周围节点进行网络攻击,并且上传错误的数据信息。 相同仿真环境下,得到不同算法的检测准确率如图2所示。 由图2 可知,恶意节点数量增加会对入侵检测模型的性能有不利影响。 原因是:恶意节点数目的增加会使检测模型难以建立正确的判断,使得联合学习模型难以执行正确模型参数信息的聚合,导致雾节点的参数上传对全局模型产生不利影响。 研究中发现,对于训练过程中受到中毒污染的客户端,其梯度更新相较服务端相差较大,而Fed-XGB 由于算法的设计避免传输不相关的局部更新,全局聚合的协同优化趋势下避免了中毒节点的不利影响,确保对模型性能有利地更新才会聚合,保证了模型训练的可靠性。
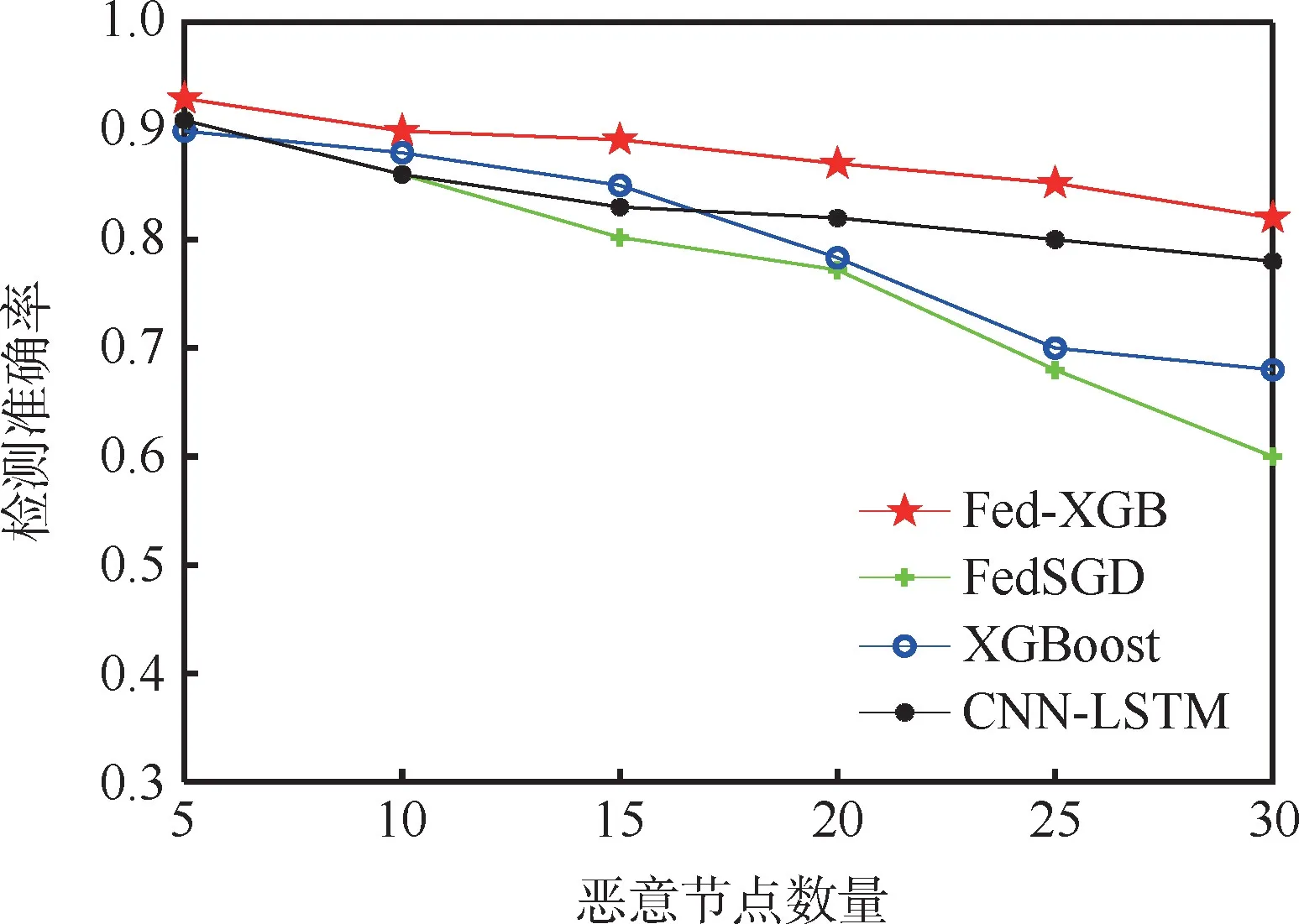
图2 不同恶意节点数量下的性能比较Fig.2 Performance comparison of different malicious nodes
3.4 模型鲁棒性测试
由于无线传感器网络具有无线连接不稳定、设备容易故障、容易受到外界干扰的特点,造成其网络传输过程中的丢包率较高,而且数据传输过程中不可避免地会收集故障数据和噪声数据。 低质量带噪声数据导致检测系统较低的鲁棒性,因此抗噪声能力对于无线传感器网络的入侵检测模型至关重要。
本文进行了模型鲁棒性测试:从30 个区域中随机选择10 个节点,参考文献[26]的方法,引入的噪声为掩蔽噪声,将其加入训练样本中,将干净的原始流量数据以一定噪声比例(10% 的比例)随机置零,以最大化学习分类器的错误,使用低质量的带噪声数据来检验系统的鲁棒性。 如图3 和图4 所示,图3(a)和图4(a)为模型正常训练后的分类结果混淆矩阵图,图3(b)和图4(b)为注入噪声的分类结果混淆矩阵图。

图3 Fed-XGB 算法加噪声前后的性能对比Fig.3 Performance comparison of Fed-XGB algorithm under adding noise

图4 FedSGD 算法加噪前后的性能比较Fig.4 Performance comparison of FedSGD algorithm under adding noise
可以看出FedSGD 算法受到噪声的影响很大,导致所有类别的准确率都大幅下降,Blackhole类的准确率下降了6%,Grayhole 类的准确率下降了3%,Flooding 类的准确率下降13%, scheduling类的准确率下降了32%,大部分预测成为了Grayhole。 而本文的Fed-XGB 算法很好的抑制了噪声对全局分类性能的影响,各个类别的准确率下降在3%以内。 证明了算法具有较好的鲁棒性。
4 结 论
针对无线传感器网络的信道特点和集中式、分布式学习方法的缺陷,本文提出联合入侵检测算法Fed-XGB,降低了数据传输带来的带宽占用和隐私泄露风险。 在不同数据集上的实验表明:
1) Fed-XGB 的检测准确率在0.97 以上,误报率在0.036 以下,优于其他对比算法。
2) Fed-XGB 在数据含有噪声和恶意节点数目增加时依然保持稳定的检测性能。
下一步将针对模型参数的保密性和压缩进行更深的研究,提高联合学习的隐私性和高效性。
