基于微博大数据的经济不确定性测度及其对宏观经济的影响研究
2022-11-08何婧,邹潇
何 婧, 邹 潇
(西南财经大学 统计学院,四川 成都 611130)
一、研究意义和问题提出
经济不确定性是一个重要的经济参数,反映了经济的运行状态与经济参与者的评估与预期不一致的程度。经济不确定性与经济运行和经济政策之间存在密切联系。Bloom指出当经济发展较好时期,其不确定性相对较小;而当经济不景气时,经济不确定性普遍较高[1]。战争、石油价格上涨和金融危机等可能导致经济衰退的外部冲击通常也会增加不确定性。众多国内外学者的研究指出,经济不确定性的增加会影响经济政策的实施和微观主体的决策,对经济运行产生负面影响。例如Bloom等指出经济不确定性会影响公司层面的投资和就业,不确定性的增加将会导致GDP下降[2]。此外,不确定性的增加将会导致企业更加谨慎,这将使经济对刺激性政策的反应大幅下降。Jurado等发现宏观不确定性具有强烈的反周期性,不确定性的增加与实际经济活动的大幅下降直接相关[3]。王义中和宋敏研究了经济不确定性对资金需求和公司投资的影响,发现宏观经济不确定性的增加会影响资金需求渠道从而影响公司投资行为[4]。同时,对经济不确定性的预期将有利于流动性资金需求对公司投资的正向促进作用。因此,研究经济不确定性对理解经济运行中的波动、制定宏观调控政策、激发市场经济活力等具有重要的意义,量化测度经济不确定性就是其中最关键的一步。在新的宏观经济环境下,基于大数据的经济不确定性测量方法具有覆盖面广、经济参与者多和可以利用实时数据作预测等特点,具有广阔的发展空间。
随着互联网和信息技术的快速发展,普通民众可以通过各种自媒体平台发布自己的观点、事实和新闻等,形式丰富多样。新浪微博自2009年8月上线以来,已经成为我国最有影响力的自媒体平台之一。在微博平台上发布的有关经济的观点或评论可以直接反映经济参与者对经济的主观认知,覆盖面广,传播速度快。本文提出了一种基于微博大数据的经济不确定性指数构建方法,主要思想是利用人们实时发布的微博,判断其对经济运行的主观认知态度的不一致程度来衡量经济的不确定性。本文提出的方法能考虑到更多经济参与者对经济的主观看法,数据量巨大,更能实时地体现经济不确定性程度的变化,从一定程度上解决经典的经济不确定性测量方法中所不能解决的问题,为经济研究提供新的视角和新的发现。
二、文献回顾
李华杰等将现有文献中对经济不确定性的量化测度方法归纳为三类:代理指标替代法、主观感知截面数据偏差法和状态量估计法[5]。以国外研究文献为例,第一类代理指标替代法是指利用能反映经济状态的指标作为经济不确定性的替代指标。例如,Bloom利用由芝加哥期权交易所推出的股票市场波动率指数(VIX, Volatility Index)作为经济不确定性的替代指标,他发现在重大经济冲击事件后都会出现VIX指数的峰值,且该指数与其他经济不确定性代理指标之间存在很强的正相关性[6]。另一个常用的经济政策不确定性(EPU, Economic Policy Uncertainty)指数由Baker等[7]提出,利用与经济政策不确定性相关的报道文章数量作为经济不确定性的替代指标。Dzielinski则考虑利用Google上与经济相关的关键词搜索频率来构造经济不确定性指数[8]。这样做的好处在于Google关键词搜索频率远高于报纸上新闻报道的数量以及其中关键词出现的频率,且能反映公众个人的经济行为或对经济活动的看法。第二类主观感知截面数据偏差法则是利用微观截面数据(以调查数据为主)挖掘出经济参与者对经济的主观感受和预期,以个体差异的离散程度来衡量经济不确定性。例如Bachmann等[9]和Scotti[10]分别利用彭博调查数据和企业调查数据来构造经济不确定性指标。第三类状态量估计法则是将经济不确定性作为宏观经济的内部状态量,通过状态空间方程估计状态值来获得经济不确定性。这类方法依赖于模型和观测数据的选取,对数据的质量要求高,数据处理量大,计算复杂。
由于经济环境不同和数据的可得性受限,上述经典经济不确定性指数构建方法难以直接应用于中国经济不确定性指数的构建。为了适应于中国经济研究,近年来对我国经济不确定性对宏观经济影响的研究取得了很多成果。黄宁和郭平基于PVAR模型研究经济不确定性对我国宏观经济的影响和地区差异[11]。金雪军等运用FAVAR模型研究经济不确定性对宏观经济的影响[12]。欧阳志刚等建立了时变VAR模型分析了经济不确定性对经济增长的影响[13]。许志伟和王文甫利用基于最大份额识别方法的结构VAR模型分析经济不确定性对主要宏观经济变量的影响[14]。这些文献研究结果都发现经济不确定性的增加也会对我国经济增长、投资、消费、价格、出口等带来短期的负向影响。然而,这些文献采用的都是Baker等[7]基于中国香港《南华早报》(英文)每日新闻中相关报道文章数的比例所构建的EPU指数作为我国经济不确定性的替代指标。为了更好地衡量我国的经济不确定性,Huang和Luk选取了10种具有代表性的中文报纸,编制了新版中国经济政策不确定性指数,使其更符合我国的经济发展形势[15]。章上峰等用宏观经济景气指数作为我国经济不确定性的替代指标[16]。利用大数据时代的优势,还有很多文献构建了基于大数据的经济不确定性指数。马丹等收集了60个月度宏观经济指标和4个季度指标,运用含有潜变量的混频动态因子随机波动模型测算我国宏观经济的不确定性[17]。杜龙波提出利用谷歌检索趋势值和我国特有的百度检索指数值来衡量我国经济不确定性的方法[18]。这些方法都从不同角度衡量了我国经济不确定性的程度。
上述方法大多是利用宏观经济指标或新闻报刊报道数比率来构建经济不确定性指数。本文利用微博大数据提出了一种新的经济不确定性指数构建方法,考虑了更多经济参与者的主观看法,比主观调查数据收集成本低、难度小,从新的角度量化了我国经济不确定性的程度。实证分析表明这种新的经济不确定性指数与已有文献中的经济不确定性指数具有较高的一致性,并且对重大事件的发生有更为即时的反映。
三、基于微博大数据的经济不确定性指数构建方法
本文的经济不确定性指数的构建主要基于微博大数据中人们对经济不确定性的看法的刻画。如前文所述,构建的经济不确定性指数的一类方法是基于新闻指数,即通过统计一些新闻媒体关于经济不确定性报道的文章数目或关键词出现频率来作为经济不确定性的测度。这类方法容易受到选取新闻媒体和关键词的主观性影响。而微博的受众群体广泛,利用微博大数据构造的经济不确定性指数能挖掘出更多经济参与者对我国经济的主观认知,可以在一定程度上改进这个问题。
同时,不同于通过调查问卷收集到的主观调查数据,微博文本数据中反映的公众对经济的主观认知是一个定性变量,无法通过计算其方差或标准差来构建经济不确定性指数。可将公众对我国经济的看法划分为“正向”“中立”和“负向”三种情感。考虑到每个月人们发布微博的数量不同,对第t个月,分别计算带有正向情感和负向情感的微博占当月含有经济不确定性关键词的微博总数的比例,并记为Rate+,t和Rate-,t。由不确定性的定义,公众对经济持乐观态度和悲观态度的比例差异越小,说明经济不确定性程度越大,反之则越小。基于上述分析,构建第t月的经济不确定性指数(EUI, Economic Uncertainty Index)如下:
EUIt=1-|Rate+,t-Rate-,t|
(1)
由式(1)定义的经济不确定性指数取值在[0,1]区间内,对不同月份直接可比。
为了计算每个月的经济不确定性指标EUI,需要分别统计每个月带有正向情感和负向情感的微博数量。由于微博数据量巨大,直接判断每条微博的情感倾向并计数的成本过高,实现困难。考虑到微博数据中可能存在用词不规范和经常诞生新词汇等特性,本文采用长短期记忆(LSTM,Long Short-Term Memory)网络模型来对每条微博进行情感分类。LSTM模型是循环神经网络模型的变体,具有良好的“记忆”能力,能学习并记忆上下文信息,在语言处理领域中具有独特的优势。对于情感分类问题,滕飞等[19]、於雯和周武能[20]等文献发现LSTM模型优于基于情感词典的分类方法和传统的机器学习分类方法。
LSTM模型具有链式结构,其中每个传输单元的结构如图1所示。

图1 LSTM模型的单元结构框图
其中:xt表示当前的输入数据,在本文中xt表示由微博短文本生成的词向量;ht表示当前的隐藏单元的取值;ct表示当前的记忆单元的取值。LSTM模型利用记忆单元ct用于保存信息,以及三种类型的门(gate)——输入门、遗忘门和输出门——来控制信息的记忆和流动。分别用符号i,f,o表示输入门、遗忘门和输出门,W和b表示权重矩阵和偏置项。σ表示sigmoid函数。由图1可知,每个门的作用及计算方式如下。
输入门(input gate)用于决定当前时刻网络的输入xt有多少保存到单元状态ct,其计算公式为
it=σ(Wi·[ht-1,xt]+bi)
其中[ht-1,xt]表示把两个向量连接成一个更长的向量。
遗忘门(forget gate)用于决定上一时刻的单元状态ct-1有多少保留到当前时刻ct,其计算公式为
ft=σ(Wf·[ht-1,xt]+bf)
输出门(output gate)用于控制记忆单元值ct有多少输出到ht,其计算公式为
ot=σ(Wo·[ht-1,xt]+bo)
当前时刻下的ct和ht值则由以下公式计算:
ct=it⊙tanh(Wc·[ht-1,xt]+bc)+ft⊙ct-1,ht=ot⊙tanh(ct)
其中⊙表示对应元素相乘。
LSTM模型中的参数由反向传播算法迭代更新得到,最终输出微博短文本的情感分类。
四、实证分析
(一)数据采集
本文选取新浪微博2013年1月1日至2019年6月30日的数据用于构建我国月度经济不确定性指数EUI。以“中国经济”“国内经济”“我国经济”“我国GDP”为关键字进行搜索,利用Python爬取新浪微博全网中包含关键词的原始微博、微博文章和微博评论等数据,共计约170万条。与构建EPU指数方法用到的新闻报道文章不同,微博的参与者不仅限于官方媒体和新闻自媒体,更多的是普通民众,因此存在一些用语不规范或完全没有信息含量的微博短文本。本文旨在利用公众对经济形势的看法来构建经济不确定性指数,因此只去掉重复和无关内容,剩余有效数据共计超过150万条。将每月含有关键词的微博数量绘制折线图如图2所示。
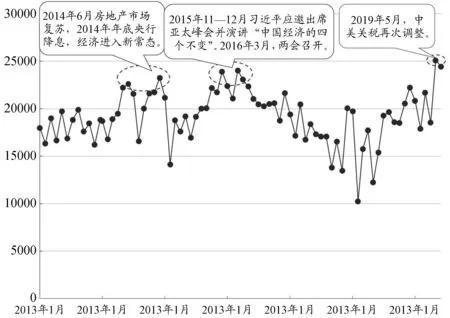
图2 每月含有关键词的微博数据总量的折线图
正如前文所言,微博是一个为人们提供发布自己的观点、事实和新闻等的平台,每当有重大事件发生或经济形势发生变化时,更多的人会在微博平台上发表自己的观点或转发自己支持的观点。由图2可以看出,微博数据量有三个明显的波峰。2014年6月起,住建部发布一系列限购松绑的新政策,全国房地产市场复苏。2014年底央行降息,中央经济工作会议指出中国经济进入新常态。这几个重大事件的发生引起了人们的热烈讨论,微博数量迅速上升至波峰位置。2015年11月,习近平总书记发表演讲,谈到中国经济四个“没有变”。12月4日,《人民日报》刊发了四位专家的文章,阐释“四个没有变”的深刻内涵。2016年3月,全国两会在北京召开,再次引发人们对中国经济的热烈讨论。2018年3月起,随着中美贸易争端的不断升级,微博评论和转发数量呈现明显上升趋势。2019年5月,中美关税再次调整,美国对华为实施技术限制,多家美国科技企业宣布中止为华为供应关键软件和零部件,国家发改委召开发布会回应当前经济热点,再次引发热议,微博数量达到最高峰。由此可见微博数据量与经济热点事件有直接联系,时效性非常强。正是考虑到这点,本文选取微博大数据用于构造经济不确定性指数。
(二)微博数据情感分类
为了计算由式(1)定义的经济不确定性指数EUI,需要计算每月带有正向和负向情感的微博比例。由于数据量巨大,由人工标注每条微博的情感分类成本非常高,且耗时长,不利于实时预测。因此本文利用LSTM模型对微博数据的情感分类进行学习和预测。首先对15万条数据进行情感分类标注,将正向、中立和负向情感分别标记为1, 0, -1。利用这15万条有标签的数据进行模型训练和测试,然后将训练得到的模型应用于余下的135万条数据,从而得到所有微博数据的情感分类标签。表1展示了部分爬取到的微博数据及其情感分类。

表1 微博数据及其情感分类示例
如表1所示,微博内容都以短文本的形式为主。我们首先需要将微博的短文本数据转化成可用于训练LSTM模型的数值型数据。本文采用常用的文本数据预处理方法,主要包括以下四个步骤。
(1)提取文字信息:去掉微博内容中常常包含的符号、网址、表情等无用信息,仅保留文字。本文通过用正则化表达式制定的规则提取文字信息。
(2)进行中文分词:把句子中的词进行独立划分,便于让计算机“理解”其含义。本文选用BosonNLP进行中文分词,它是目前中文分词工具中准确率最高的一种,对微博数据的分词准确率达到93%。
(3)去停用词:去掉短文本中的停用词,例如文本中使用过于频繁的词“我”“今天”“是”等和没有实际语义的词如语气词“啊”“吧”“呢”,助词“着”“了”“过”,连接词“那么”“下面”“之后”等。本文采用的停用词表来源于哈工大停用词表、四川大学机器智能停用词库和百度停用词表等,通过去除重复词汇,选用了约1 800个停用词。
(4)词向量化:将第3步中分好的词转化成词向量,作为LSTM模型的输入向量。本文采用目前最常用的由Google公司开发的词向量化工具Word2vec。
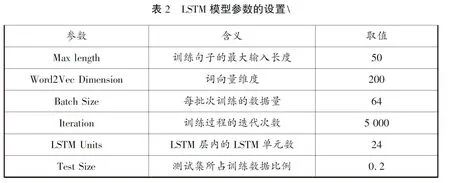
上述数据预处理的4个步骤中均用Python软件予以实现。然后训练LSTM模型进行情感分类。本文共有15万条有情感标签的数据,用其中的12万条数据训练模型,3万条数据用于测试,以选定合适的参数。最终,模型中的主要参数设定如表2所示。
利用上述训练好的模型,将其余的135万条无标签数据代入,即可得到每条微博的情感分类。利用LSTM模型对微博数据的情感进行分类的方法有利于实时计算和预测经济不确定性指数。
(三)基于微博数据的经济不确定性指数EUI
统计所有当月情感分类为“1”和“-1”的微博数据占当月(含有关键词的)微博总数的比例,代入式(1)计算EUI。将计算得到的2013年1月至2019年6月的EUI绘制折线图(图3)。
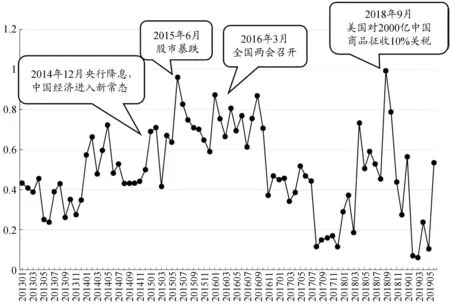
图3 经济不确定性指数EUI的折线图
对比图2和图3,可以看出EUI的趋势和峰值位置与微博数量有相似之处。例如,2014年年中和年末房地产市场限购限贷松绑政策的发布,中央经济工作会议指出中国经济进入新常态、2015年6月股市暴跌、2016年年初全国两会召开,在这些经济大事件发生的时点附近,EUI均处于波峰位置。2017年全国经济处于平稳时期,因此EUI值相对较低。2018年3月起,随着中美贸易摩擦的不断升级,EUI值连续攀升。同年9月美国对价值2 000亿美元的中国输美商品征收10%的关税,中美贸易顺差达到历史最高值,有可能进一步加剧中美之间的贸易摩擦,EUI达到峰值。同时,也有一些引起微博热议的事件,对应的EUI值并不高,例如2015年11月,习近平总书记发表演讲中国经济四个“没有变”和2019年5月中美贸易争端的再次升级。这是因为对这些事件的微博评论的情感极性大多相同。因此,利用微博数据的情感分类构造经济不确定性指数比直接用微博数量更能反映经济不确定性的定义。
(四)与其他经济不确定性指数的相关性分析
现有文献中最常用的经济不确定性指数为Baker等[7]编制的中国经济政策不确定性(EPU)指数。中国EPU指数由网站http://www.policyuncertainty.com/提供。为了比较EUI与EPU指数,本文将EPU指数以1995年1月为基准转化为定基指数。将2013年1月至2019年6月的EUI和定基EPU指数绘制成折线图,如图4所示。
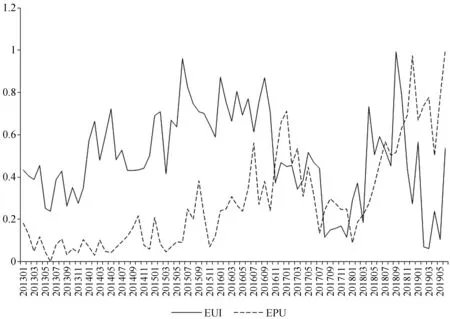
图4 经济不确定性指数EUI与经济政策不确定性指数EPU的对比图
由图4显示,EUI和EPU指数的变化趋势基本相似,且在重大经济事件发生的时点附近都会出现峰值。这说明EUI能够较好地反映经济的变化趋势。如图3中显示出的2014年年中和年末、2015年6月、2016年年初和2018年9月。相比而言,EPU指数普遍会比EUI的峰值滞后2~3个月。这与两种指数的定义直接相关。EPU指数是通过报纸上的新闻报道收集的与“经济”“政策”和“不确定性”相关的信息,而EUI是通过微博这种新兴的网络自媒体平台收集的相关信息。因此相比于EPU指数,EUI更具有时效性。
为进一步说明本文所构造的EUI指数的合理性,参考杜龙波[18]的做法,将EUI与其他衡量经济不确定性的指数进行比较。其中应用最广泛的经济不确定性指数是芝加哥期权期货交易所使用的市场波动性指数(VIX)和股票收益率的方差(VP),以及通过问卷调查的方式来直接表示公众对经济形势的态度构造的消费者信心指数(CCI)和基金经理信心指数(FMI)。表3中总结了各个指数的均值、方差和相关系数。VIX指数来自网站https://stockcharts.com/,VP和FMI来自RESSET金融研究数据库,CCI来源于国家统计局网站。
表3中的结果显示,EUI与VIX和VP都呈正相关关系(相关系数分别为0.49和0.35)。但它们也有显著的不同,VIX和VP更多地反映了金融市场的波动,EUI则更多地反映了经济参与者们对宏观经济的主观认知。将EUI与CCI和FMI相比,它们的相关系数均为负。CCI和FMI均反映的是经济参与者对当前经济的评价和对未来经济的预期,是预测经济走势和股票市场运行方向的重要先行指标,值越大表示预期越乐观。当经济不确定性高时,CCI和FMI相对较低,符合实际经济意义。

表3 其他衡量经济不确定性指数的描述性统计
(五)经济不确定性对宏观经济的影响分析
本节利用构建的经济不确定性指标EUI,建立向量自回归(VAR)模型来分析经济不确定性对宏观经济的影响。选择投资、消费、进出口以及物价水平作为主要宏观变量的代表,变量含义和符号由表4具体给出。数据均来自于我国国家统计局数据网站,时间跨度从2013年1月至2019年6月,共计78条月度数据。

表4 变量符号表示及其含义
利用ADF检验对表4中的五个变量进行平稳性检验,结果说明EUI、IR和IER均为平稳序列,CR和CPIR为趋势平稳序列。将去掉CR和CPIR序列中的固定时间趋势后得到的序列分别记为CR_dt和CPIR_dt,重新检验得知均为平稳序列。
为了探究宏观经济变量之间的相互影响关系,首先对上述变量进行格兰杰(Granger)因果关系检验。从表5中的结果可以看出,在10%的显著性水平下,经济不确定性指数EUI是社会消费品零售总额增长率的格兰杰原因,并且和进出口总值增长率互为格兰杰原因。
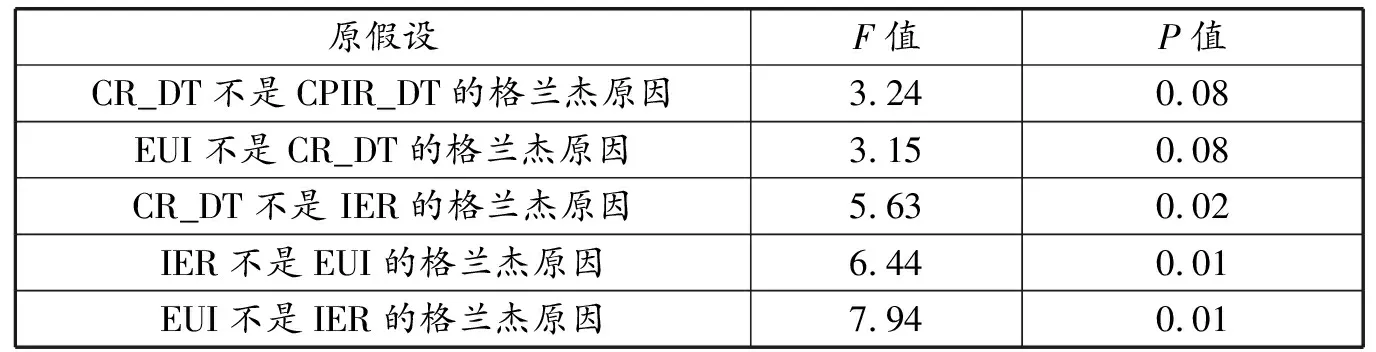
表5 格兰杰因果检验结果
根据AIC、BIC信息准则和对模型结果的综合评价,选择滞后期为1的向量自回归模型VAR(1)。根据模型的估计结果,得到特征方程的特征根均位于单位圆内,说明所构建的VAR(1)模型稳定,由此进一步进行脉冲响应分析。给经济不确定性指数EUI一个标准差单位的正向冲击,可以得到图5中的脉冲响应函数。
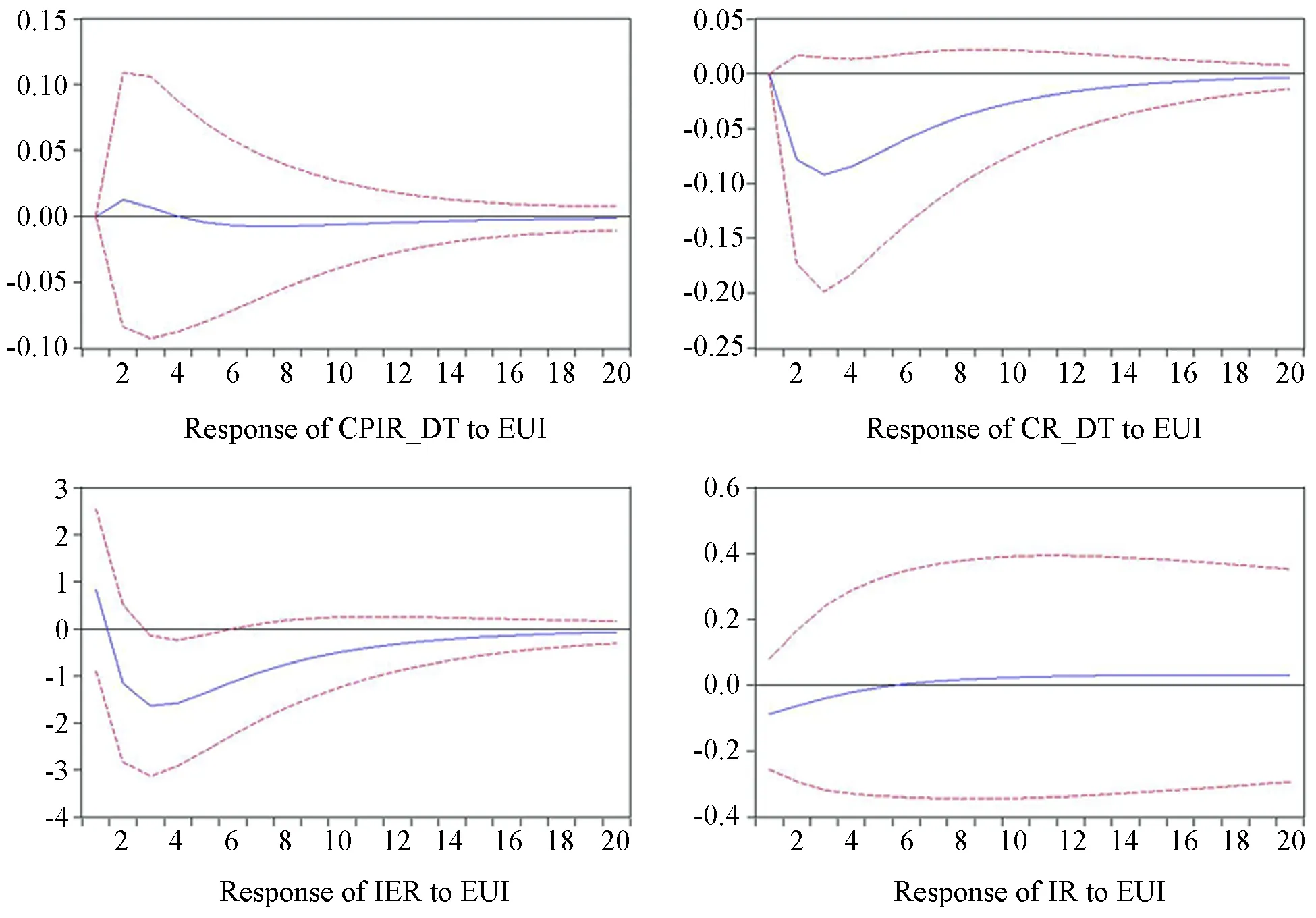
图5 经济不确定性指数对宏观经济变量的脉冲响应函数
其中横轴表示各经济变量对不确定性冲击的响应的滞后期数(单位:月),纵轴表示响应的数值大小。实线表示各宏观经济变量在不同滞后期数响应的程度,虚线表示正负两倍的标准差偏离范围。由图5中的结果可知,当经济不确定性受到一个标准差单位的正向冲击后,进出口和消费的响应程度是最大的,价格和固定资产投资的响应程度较小。并且,经济不确定性对进出口和消费都造成了负面的影响。进出口对不确定性冲击的响应在第一个月就出现,小幅度上升后从第二个月开始迅速下降,到第三个月达到最低值后持续缓慢地回升,在20个月后逐渐趋于零。这说明不确定性对进出口贸易的负面影响在前三个月最明显,这样的负面影响大概将持续两年。这与鲁晓东和刘京军[21]等文献中得到的结论一致。而消费对不确定性冲击的响应有一个月的滞后,从第二个月开始迅速下降,同样到第三个月达到最低值后,经过两年左右逐渐回归至正常水平。
进一步地,我们利用方差分解分析由经济不确定性冲击而引起的宏观经济变量变动的贡献程度,结果如表6所示。除了各宏观经济变量自身变化的贡献外,经济不确定性对各宏观经济变量变动的贡献程度最大的是进出口,截至第十二个月,方差贡献率超过了12%;对消费的贡献程度次之,大约为8.2%。经济不确定性对价格和固定资产投资的贡献最小,均不超过1%。这与脉冲响应分析的结果一致。
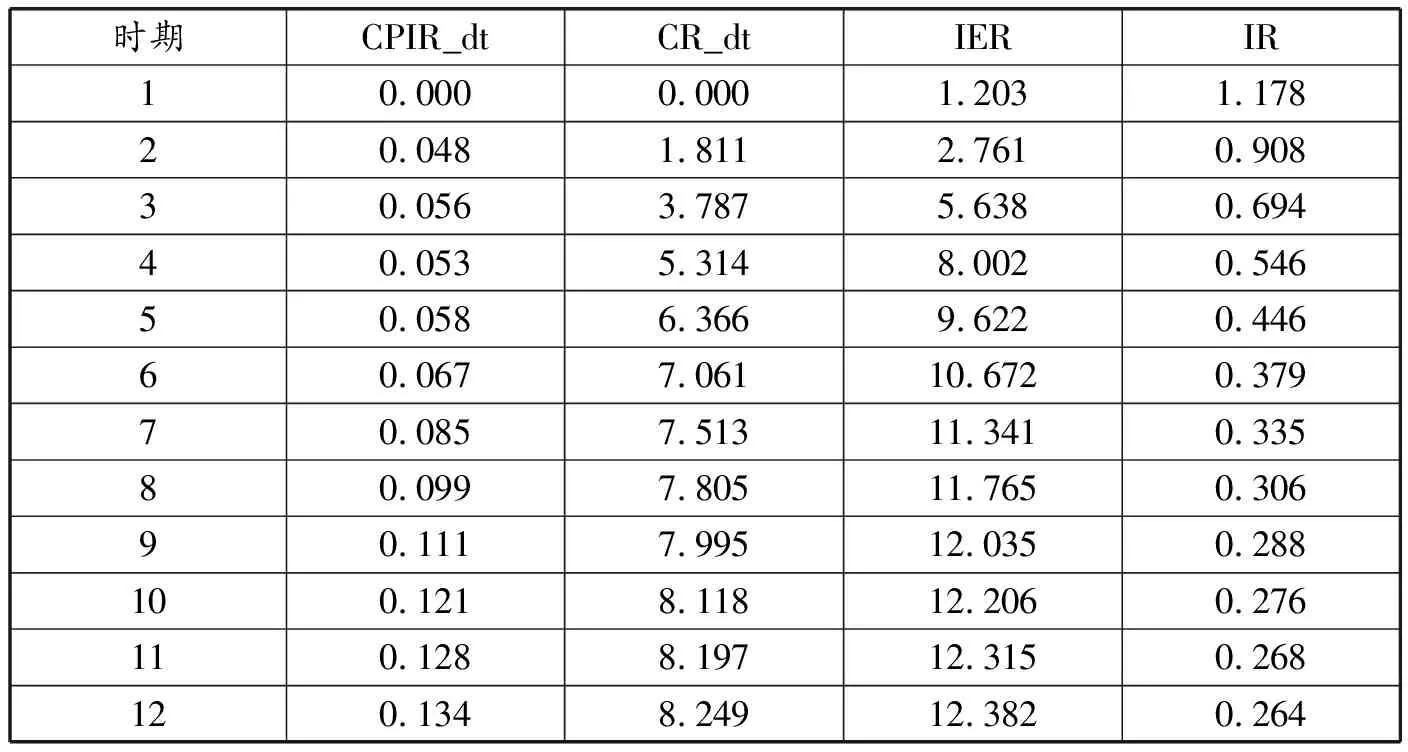
表6 不确定性对各宏观经济变量变动的贡献度
五、结论与启示
本文提出一种基于微博大数据的我国经济不确定性指数构建方法,主要思想是利用人们对经济形势的主观认知态度的不一致程度来衡量经济的不确定性。考虑到微博是我国最有影响力的自媒体平台之一,微博观点或评论可以直接反映经济参与者对经济的主观认知,覆盖面广,传播速度快,本文构建的经济不确定性指数能考虑到更多经济参与者对经济的主观看法,更能实时地体现经济不确定性程度的变化,为经济研究提供新的视角和新的发现。由于数据量巨大,本文采用了LSTM模型对微博数据的情感倾向进行判断,有利于经济不确定性指数的实时计算和预测。
从结果来看,对于重大事件的发生,本文构建的经济不确定性指数EUI都有即时的反映,如2014年年中和年末房地产市场限购限贷松绑政策的发布,中央经济工作会议指出中国经济进入新常态、2015年6月股市暴跌、2016年年初全国两会召开,和2018年9月中美贸易摩擦加剧,这些大事件的发生引发人们在微博上的热烈讨论,基于微博评论数据构建的EUI在时间发生的同月达到峰值。将EUI与其他常用的经济不确定性指数进行对比,发现其与不确定性代理指数VIX、VP具有较强的正相关性,与经济政策不确定指数EPU具有较强的一致性,且EUI的时效性更强。最后,本文通过建立向量自回归模型,研究了基于EUI衡量的经济不确定性对我国宏观经济的影响。结果表明,经济不确定性对进出口和消费有显著的负向影响。进出口对不确定性的响应在第一个月就出现,小幅度上升后迅速下降,到第三个月达到最低值后,大约持续两年时间。消费对不确定性冲击的响应有一个月的滞后,从第二个月开始迅速下降,同样到第三个月达到最低值后持续两年左右逐渐回归至正常水平。
