基于自适应主成分分析维度寻优的脑力负荷识别
2022-11-01曲洪权王飞月庞丽萍
曲洪权, 王飞月, 庞丽萍
(1.北方工业大学信息学院, 北京 100144; 2.北京航空航天大学航空科学与工程学院, 北京 100191)
脑力负荷是一个多维的概念,它涉及工作要求、时间压力、操作者的能力和努力程度、行为表现和其他许多因素[1]。研究表明,脑力负荷是影响作业绩效的重要因素,当作业人员脑力过高时,作业决策的错误率会增加,从而导致人因事故的发生[2]。因此,对作业人员进行脑力负荷识别对于提高作业效率,减少人因事故发生具有重要意义。
早期测量脑力负荷的方法主要有行为绩效法和主观评估法[3]。但是,在实际应用时二者都由于其局限性难以进行脑力负荷状态的实时评估[4]。随着生物信号检测技术的发展,诸多科学家尝试了使用生理信号进行脑力负荷识别,并且发现脑电(electroencephalogram, EEG)信号与脑力负荷状态具有很高的相关性[5-7]。因此,基于脑电信号的脑力负荷研究成为目前最广泛的脑力负荷研究方法。并且诸多研究表明,在不同的脑力负荷状态下,脑电信号在theta、alpha、beta和gamma这4个频段的功率谱变化敏感。因此,脑电信号在各个频段中的功率谱也成为近年来脑力负荷研究中最多常用的生理信号特征[8-10]。
然而,在脑电信号的处理中,采集得到的原始脑电信号在各个频段经过提取特征后会存在明显的冗余性和无关性。这是由于脑电信号是由多通道脑电帽采集的,采集得到的脑电信号中除了有用的脑电信息外还会存在一些通道之间的重复以及噪音,这会导致计算负荷过高以及准确性降低。特别是在样本数量较小时,样本在高维空间中分布会非常稀疏,会影响到分类结果的准确性以及有效性。因此,在特征提取之后,需要对高维特征进行特征选择或特征融合处理,降低特征空间维度,从而降低计算负荷并提高分类性能。Zhang等[11]比较了5种主要特征选择算法的脑电信号分类准确性,包括核谱回归,局部性保留投影,主成分分析,最小冗余最大相关性和Relief,以及4种不同的机器学习分类器,即K-最近邻、朴素贝叶斯、支持向量机和随机森林。姜月等[12]提取结合时-频-空域的初始特征向量, 用主成分分析(principal component analysis, PCA)降维并保留累积贡献率大于85%的主成分特征, 得到的主成分特征向量用支持向量机分类, 得到91.9%的识别率。Matin等[13]利用主成分分析和独立成分分析对脑电特征进行降维,然后使用支持向量机对脑电信号进行分类。
针对视觉和操作类任务,现提出一种自适应主成分分析维度寻优方法,并将该方法应用在脑力负荷识别中。由于目前应用主成分分析(PCA)[14]算法进行特征提取的脑电信号识别研究中,对于降维维度的确定大都是通过设定累计贡献率阈值来确定[12,15-16]。但是,对于同一实验下的多组数据,由于设备、误差等原因,数据分布有所差别,导致由相同的累计贡献率得到的降维维度不一致,在后续训练分类器时无法确定特征的统一降维维度。为了解决这一问题,本文研究借鉴K-means聚类算法中K值的确定方法[17-18],确定主成分分析的最佳降维维度。该方法考虑在同一种实验中得到N组实验数据,通过分析现有的N组实验数据特征通过主成分分析降维后在各个维度上的分类表现,得到该实验数据集的最优降维维度。通过该方法得到的最优降维维度可以应用在同实验的其他数据中,从而为该实验得到的脑电数据找到一个通用的降维维度,提高识别性能。
现通过5个步骤实现脑力负荷的识别:首先对实验测量的各组脑电信号进行预处理,其次对预处理得到的脑电信号数据进行特征提取,得到脑电信号的功率谱密度特征,再通过主成分分析算法得到寻优维数范围各个维度的低维特征,之后利用自适应主成分分析维度寻优方法得到该实验数据集的最优降维维度,最后将得到的最优维度应用在同实验的其他数据中对其进行脑力负荷识别。使用该方法进行脑力负荷识别不仅可以提高识别效率,而且有利于同实验中多组数据的统一研究。
1 自适应主成分分析维度寻优
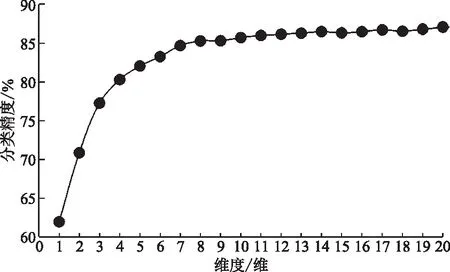
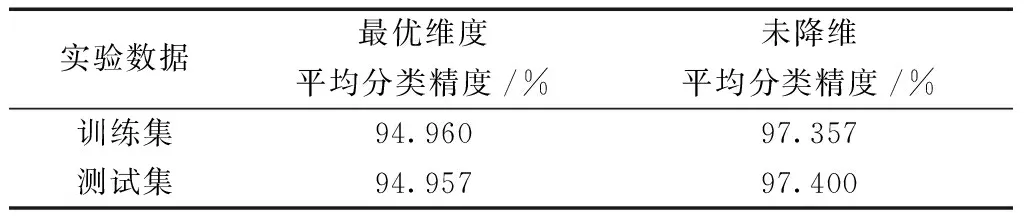
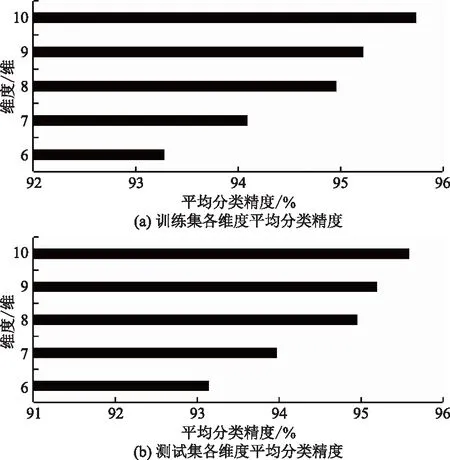
该方法可以利用实验数据集中所有实验数据的信息,在所需寻优维数范围内求出该实验数据集的最佳降维维度。需要解决的问题是,给出一个包含不同负荷状态下的多组实验脑电实验数据的数据集,并利用实验数据集中的N组实验数据在所需寻优维数范围[1,M](M 如图1所示,自适应主成分分析降维维度寻优共分两个步骤完成。第一步,通过对降维的特征数据训练分类器,得到寻优维数范围内各维度的分类精度集合。首先将实验数据集中的每组实验数据分别进行特征提取得到实验数据特征集并确定要查找的最优维度的范围[1,M],之后将每组数据的特征矩阵分别使用主成分分析算法降维至[1,M]的每个维度并归一化得到M个维度的实验归一化低维特征集,再将每组低维特征数据分别进行训练分类器并将该维度N组数据的自测试精度求和得到该维度的实验数据集维度特征分类精度,最后得到M个维度的实验数据集的分类精度集合W。第二步,根据实验数据集各维度特征的分类精度,自适应寻优得到实验数据集的最优降维维度p。首先将数据集的分类精度集合W进行尺度变换得到与其相对应的维度范围尺度相同的集合X,之后将集合X中的数据与其对应的维度封装成M个数据对并绘制出实验数据集维度-精度曲线,再通过计算各维度与其相邻两个维度连线之间夹角的正切值得到相邻维度夹角正切值集合T,集合T中最大正切值对应的维度便是该实验数据集的最佳降维维度p。 图1 自适应主成分分析维度寻优概述Fig.1 Overview of adaptive principal component analysis dimension optimization 特征数据降维至p维后进行分类识别,可以在保证分类精度损失较少的情况下,减少分类器的工作量,缩短工作时间,从而提高分类效率。 脑电信号分析可以采用不同的信号处理方法。本文使用已被证明在脑电信号识别中有效的功率谱密度(power spectral density,PSD)估计方法来提取原始信号中的有用特征[8-10]。许多功率谱密度(PSD)估计方法被研究人员用于信号分析。本文利用Thomson多窗谱估计(multitaper spectrum method,MTM)的方法进行功率谱密度估计[19]。MTM方法通过将数据乘上一组正交的窗口函数,计算出一组相互独立的功率谱估计,可以最小化半带宽外的频谱泄露,其中最常用的正交窗为一组相互正交的离散椭球序列(discrete prolate spheroidal sequences,DPSS)。由于脑电信号序列长度为12 min,为了减少随机起伏,在对脑电信号的各个频带特征提取时,首先把信号序列分为若干个2 s的片段,对每段分别使用MTM法计算其在各个频带的功率谱密度,然后将频带中各个片段的功率谱密度取平均,作为该频带完整脑电信号序列的功率谱密度特征。 由于一组脑电信号数据中包含多个电极的脑电信号序列,导致在提取了4种节律的功率谱密度特征后得到的特征矩阵维度过高,导致后续识别模型复杂度过高,因此需要对高维的特征矩阵进行降维处理,本文选用的降维算法是主成分分析算法[14]。主成分分析算法通过线性映射的方法将原始的N维数据降至k维(k 另外,为了将降维后的功率谱密度特征归一化处理,采用Z-score方法[20]。并使用归一化后的特征用来作为分类器的输入。 假设实验数据集提取出来的功率谱密度特征经过主成分分析算法降维并归一化后在最优维度的范围[1,M]内的分类精度集合为W={w1,w2,…,wM}。将各个维度与其对应的分类精度封装成M个数据对绘制成实验数据集的维度—分类精度曲线,如图2所示,可以发现该曲线是一个“手肘型”曲线,随着维度的增加,数据特征所保留的信息不断增多,分类精度逐渐增加,并且在“肘部”分类精度骤然变大,曲线相邻三点之间连线的夹角更接近直角。这与K-means算法的手肘法求解最优K值十分相似,曲线的“肘部”为最优的降维维度。 图2 维度-分类精度曲线Fig.2 Dimension-classification accuracy curves 为了准确找到曲线的“肘部”,需要将由分类精度集合W绘制的曲线的横纵坐标调整为相同的尺度,经过尺度变换后的集合X={x1,x2,…,xM}可由式(1)求得。 (1) 式(1)中:Wmin为集合W的最小值;Wmax为集合W的最大值;M为集合W中数据个数。 曲线上维度与其相邻两个维度连线之间夹角的正切值tanθi可由正切公式求得,计算公式为 (2) 式(2)中:i=2,3,…,M-1;ki,i+1=xi+1-xi为维度xi与xi+1两点连线的斜率;ki-1,i=xi-xi-1为维度xi-1与xi两点连线的斜率,因此式(2)又可表示为 (3) 式(3)中:i=2,3,…,M-1。 两连线之间夹角越接近直角,其角度的正切值越大。因此,找到最大正切值对应的维度,则找到了该曲线的“肘部”,也就是最佳维度。 自适应维度寻优具体方法实现如下。 输入:实验数据集在最优维度的范围[1,M]内的分类精度集合W={w1,w2,…,wM}。 输出:最优降维维度p。 (1)根据式(1)将集合W进行尺度变换得到集合X。 (2)将集合X内M个变换后的数据与其对应的维数封装成M个数据对。 (3)根据式(3)计算[2,M-1]维度与其相邻两个维度连线之间夹角的正切值得到集合T={tanθ2,tanθ3,…,tanθM-1}。 (4)获取集合T中最大值对应的维数赋值给变量p。 (5)返回p值。 本实验被试为同专业的10名研究生,其年龄在22~24岁,身体健康且为右利手,视力或矫正视力正常。实验前对被试进行培训,充分熟悉任务操作。实验平台为基于多任务航空情境操作的 MATBⅡ平台,被试需要在规定时间内对随机出现的4个子任务(系统监控任务、追踪监控任务、通信监控任务和资源管理任务)做出反应操作。实验设置了两个实验水平:低负荷和高负荷。不同实验水平通过子任务呈现不同频次实现,其中低负荷的任务出现频次为1次,高负荷任务出现频次为24次。本实验脑电采集系统为32电极通道的Neuroscan Neuamps 系 统 (Syn-amps2,Scan4. 3,EI Paso,USA),其中A1和A2电极被设置为参考电极,分别位于左耳和右耳后面。脑电的采样频率为1 024 Hz。 本实验中每名被试均分别在连续9 d的白天及夜晚进行实验,在每次实验时需要分别完成两种负荷下12 min的任务(在完成不同负荷任务中间经过充分休息),并在每次实验后使用NASA-TLX量表评价该次实验的合理性,最终共得到180组实验数据。在数据分析前对每组数据进行预处理,首先将A1和A2的平均值作为参考,并利用0~45 Hz带通滤波器进行滤波,之后利用重叠滑窗的方式对数据进行切分(切分长度为30 s,重叠长度为15 s)每条数据可以得到47个片段,两种负荷状态共94个片段。由于一组脑电数据共有30个通道,采用标准的4个频带对每个片段进行特征提取,得到每组数据的特征总维数为120维,寻优维度范围确定为[1,20]。 本实验选择支持向量机[21-22]分类器作为分类方法对脑力负荷进行分类,将两种负荷脑电信号提取得到的4个节律的功率谱密度特征作为支持向量机的输入,选取线性核为核函数。为了得到最优模型参数,对每组数据采用网格搜索法进行筛选,惩罚系数C的搜索范围为[0.01,1,10]。并且为了确保模型的鲁棒性和减少过拟合,在分类算法中进行了交叉验证分析。 本实验随机选择脑电实验数据集中的70%的实验数据(共126组)作为训练集进行实验数据集自适应主成分分析维度寻优,并将剩余30%实验数据(共54组)作为测试集进行后续性能测试。训练集实验数据自适应主成分分析维数寻优结果如图3所示,分别展示了训练集实验数据在[1,20]维度上的维度-精度曲线图以及每个维度与其相邻两个维度连线之间夹角的正切值柱状图,从图3可以看出8维对应的点为维度-精度曲线的“肘部”,并且在正切值柱状图3中8维时正切值最大,因此经过维度寻优得到的最优维度为8维。 将得到的最优维度分别应用在训练集以及测试集的实验数据上,即将脑电实验数据提取的4种功率谱密度特征降维至8维并利用支持向量机分类器进行脑力负荷识别。脑电数据特征降维至最优维度与未降维的平均分类精度对比如表1所示。 由表1可知,在训练集实验数据中,虽然脑电信号特征从120维降至8维,但分类结果相差并不大,平均分类精度仅丢失2.397%;在测试集实验数据中,降维至最优维度前后的平均分类精度损失也仅只有2.443%。由此可见,该自适应维度寻优方法可以实现在降低脑电数据特征维度的情况下以较少的分类精度损失降低特征数据维度,降低后续识别模型复杂度,提高识别效率。 表1 维度寻优前后平均分类精度对比Table 1 Comparison of average classification accuracy before and after dimension optimization 为了验证降维至最优维度的分类性能,分别对比了训练集实验数据以及测试集实验数据的脑电数据特征分别降维至最优维度以及其相邻4个维度的脑力负荷识别分类精度,即将脑电实验数据提取的4种功率谱密度特征分别降维至6维、7维、8维、9维与10维后进行脑力负荷识别,脑电实验数据特征降维至最优特征与其相邻维度后的分类精度对比如图4所示。 由图4可知,在训练集实验数据中,当实验数据特征维度由10维降至9维时平均分类精度下降了0.515%,由9维降至8维时平均分类精度下降了0.262%,当维度由8维降至7维时平均分类精度损失开始激增,下降了0.869%,由7维降至6维时平均分类精度下降了0.811%;测试集实验数据中同样体现了相同的规律,当实验数据特征维度由10维降至9维时平均分类精度下降了0.394%,由9维降至8维时平均分类精度下降了0.236%,当维度由8维降至7维时平均分类精度损失开始激增,下降了0.985%,由7维降至6维时平均分类精度下降了0.828%。由此可见,自适应维度寻优方法可以实现在目标寻优范围区间中找到分类精度激增的维度阈值,从而实现找到保证分类精度的情况下的最低维度,提高识别效率。 图4 降维至最优维度与其相邻维度平均分类精度对比Fig.4 Comparison of the average classification accuracy of dimensionality reduction to the optimal dimension and its neighboring dimensions 针对视觉和操作类任务,提出了一种自适应主成分分析维度寻优方法,该方法通过分析现有实验数据特征通过主成分分析算法降维后在各个维度上的分类表现,得到该实验数据集的最优降维维度。将该方法应用在脑力负荷识别中,得到如下结论。 (1)该方法可以准确寻优得到实验数据集的最佳降维维数,整个寻优过程全自动无需用户交互,应用在脑力负荷识别上实现94.960%平均分类准确率。与未降维数据相比,在数据维度减小了112维的情况下平均准确率仅减少了2.397%。因此,提出的基于自适应主成分分析维度寻优的脑力负荷识别可以有效提高脑力负荷识别的识别效率。 (2)将自适应主成分分析维度寻优方法寻优得到的最优维度应用到同实验的其他实验数据上进行脑力负荷识别,发现由该方法寻优得到的最优维度可以有效应用在同实验的其他实验数据上,在同实验其他数据的脑力负荷识别上实现94.957%平均分类准确率。与未降维数据相比,在数据维度减小了112维的情况下平均准确率仅减少了2.443%。因此,提出的基于自适应主成分分析维度寻优的脑力负荷识别可得到同实验数据集上通用降维维数。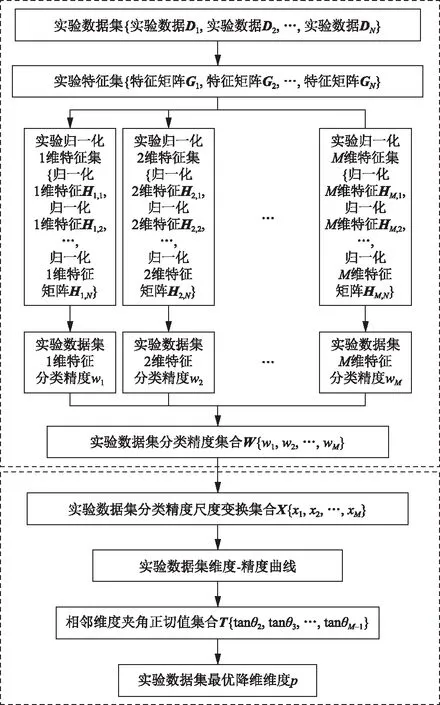
1.1 特征提取及主成分分析
1.2 自适应维度寻优
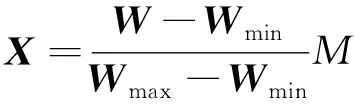
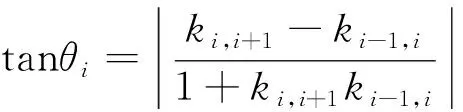
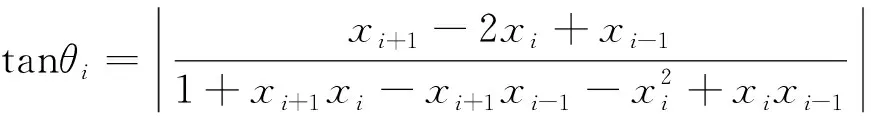
2 实验与分析
2.1 实验与数据预处理
2.2 实验结果
3 结论
