视觉行人重识别研究方法分析及评价指标探讨
2022-10-31赵安新杨金桥史新国李学文
赵安新,杨金桥,史新国,刘 帅,师 文,李学文
(1.西安科技大学 通信与信息工程学院,陕西 西安 710054;2.山东博选矿物资源技术开发有限公司,山东 济宁 272073)
0 引 言
行人重识别(person re-identification,简称Re-ID)是利用计算机视觉,将多个摄像机拍摄的同一行人的图像关联起来,行人第一次被摄像机拍摄到的图像会被保存到一个图像库,当行人被另一个摄像机拍摄到时,当前图像会在图像库中进行匹配识别,识别出准确的身份信息,行人重识别根据其输入数据的不同可以分为2类,图像行人重识别和视频行人重识别。而相比图像行人重识别,视频行人重识别携带更多的信息,更接近真实应用,但相较图像而言更为复杂,计算量也更大[1]。
行人重识别任务可以追溯到多摄像机追踪的问题上,2006年在CVPR上第一次提出行人重识别的概念,从多摄像机追踪的问题中将行人重识别分离出来,使其作为一个独立的研究方向。2007年VIPeR数据集问世,对行人重识别具有重大的研究意义。此后,越来越多的学者进行行人重识别方面的研究。2012年ECCV会议上召开了行人重识别有关的第一个研讨会。早期的行人重识别主要由人来设计需要提取的特征,以颜色特征为主,常与梯度特征和纹理特征结合使用[2],但依赖于设计者的经验。随着工业中人工智能技术的引入,这些特征难以满足市场需求,2014年以后,深度学习的方法被广泛应用于行人重识别领域,极大地提高行人重识别的精度。2017年,ZHANG等提出AlignedReID模型,在行人重识别问题上首次超越人类的表现[3]。2020年HE等提出Fast ReID模型,增强了特征提取的鲁棒性[4]。深度学习虽然为行人重识别技术带来正收益,但深度学习技术需要大规模的行人重识别数据集的支撑,Market-1501, DukeMTMC-ReID等大型数据集就应运而生,既降低模型过拟合的风险,又能够提升模型的泛化能力。但目前的数据集面对日益扩大的监控网络仍显不足,需要进一步收集更大规模的数据集。除了数据集规模问题,现阶段的行人重识别领域还面临着如光照、遮挡、姿态变换等问题。针对行人重识别中的光照问题,龚云鹏等在模型训练时,随机选择训练的图像批组,该批组内所有的RGB图像均会选择一个矩形块,将所选矩形块的像素替换为相应的灰度图像像素,生成含有不同灰度区域的训练图像[5]。汤红忠等利用不同视图的特征表示中编码系数间的潜在关联,提出具有多级判别性的字典学习算法,该算法降低不同视图下光照和分辨率差异造成的影响[6]。为解决行人重识别中的遮挡和姿态变化问题,徐家臻等将最优局部特征和整体特征进行融合,得到新的特征,该特征提高行人重识别的精确度[7]。徐胜军等将行人的全局特征和局部特征整合到一起,通过多样化的局部注意力网络(DLAN)生成更全面的行人特征[8]。
近年来,行人重识别技术作为计算机视觉领域的兴起的一种新型技术,在安防与工业领域内扮演者关键角色,如工人安全管控、小区安防、相册聚类和车站智能寻人等等。目前对行人重识别中的研究围绕着获得鲁棒性高、针对性强的行人描述特征。CHENG等将局部特征与全局特征在三元组网络框架下进行整合,设计出一个部分聚合的多通道深度网络模型[9]。谢琦彬等设计一种新的图像描述方法,该方法在结合全局特征和局部特征的同时引入一种新的注意力机制,增强图像特征与语义信息之间的映射[10]。提升鲁棒性和针对性之后的行人特征能够更加从容的应对复杂的工业场景。但在实际应用中的遮挡、姿态变换和光照等问题,会造成行人关键信息的缺失,影响行人重识别的准确率,因此,学术界将关注点放在优化行人特征表示方法和优化距离度量函数上。接下来将针对基于特征表示方法的行人重识别技术与基于度量学习的行人重识别技术两方面进行重点分析。
1 基于特征学习的行人重识别
基于特征学习的重识别方法着重于设计鲁棒性高的行人特征模型,包括传统手工特征提取和基于深度学习的特征提取。行人重识别技术的整体框架如图1所示。
1.1 传统特征提取算法
传统特征提取算法着重于发现描述行人外貌的图像特征,包括颜色特征、梯度特征和纹理特征。
颜色特征作为区分不同目标和背景的最直观有效的特征,通常使用颜色直方图进行统计描述。在行人重识别中,通常将行人图像分割为多个区域,对于每个区域,通过获取它的颜色直方图来获得行人不同部位的颜色特征,如图2所示。颜色特征可以于不同的颜色空间进行计算,如RGB,HSV,XYZ,LAB等均属于常用的颜色空间。颜色直方图具有旋转不变性并且能够高效的提取目标特征,但正是由于其计算简单,忽略了行人图像空间分布信息,在图像量化处理时会造成颜色误检现象,比如将视觉感官相近的颜色量化到不同区间、把视觉感官不同的颜色量化到同一区间等等。根据行人图像的主颜色构建颜色直方图,并采用图像增强算法提高行人图像的颜色对比度是解决上述问题的常用方法。
虽然颜色特征对于行人图片的尺寸和角度的依赖性很小,但是单靠颜色特征难以有效提升行人重识别的精度,为此学者们将纹理特征与颜色特征结合起来使用。纹理特征用于描述图像或图像区域所对应目标物体的表面性质,从物体的纹理角度反应物体的特征。纹理特征不同与颜色特征,通常并不基于像素点,而那时通过统计图像相邻像素点的差异得到特征。常用的纹理特征方法包括LBP,GMRF,SILTP等。LBP编码计算过程如图3所示,中心像素点的灰度值是12,以12作为阈值,将该值与其周围的其他像素值做比较,大于或者等于12,将其对应的像素值置为1,小于12则置为0,从而得到对应的二进制码用来表示纹理特征。纹理特征受到图像分辨率的影响,分辨率改变前后计算的纹理特征可能会出现较大偏差,并且由于纹理特征表现的是物体的表面性质,不能完全表示目标的本质,单一纹理特征难以获得更高层次的的图像内容。学者们通常将纹理特征与颜色特征结合起来使用,把行人图像划分成水平条带,计算每个条带的颜色和纹理直方图。
纹理特征通常用来描述行人的细节特征,比如人体腿的姿态容易改变,就适合采用LBP算子描述对该区域进行描述。当人体躯干处于相对稳定的情况时,梯度特征能够更好地描述该行人特征。梯度特征反映向量像素的变化差异,比如边、角点等特性。方向梯度直方图(histogram of oriented gridients,HOG)是计算机视觉领域中一种表征图像梯度特征的描述子,能够有效检测出行人。行人图像的HOG特征如图4所示,对于输入的图像,先计算该图像像素点的梯度特性,生成梯度直方图,再对图像的每一个子块(block)的特征进行拼接,得到图像的HOG特征。HOG对行人图像中的颜色和亮度变化不敏感,但其描述子生成速度慢会导致实时性差并且容易受到噪音的影响,针对这些问题,学者们通常将HOG算法与其他传统特征和支持向量机(support vector machines,SVM)结合使用,比如将HOG提取出来的信息和图像方差与单元均值等融合在一起,并于SVM算法结合使用,通过非极大抑制和多尺度检测等手段提升模型的泛化性。
从以上研究中可以发现,传统的手工特征,以颜色特征为主。由于只依靠颜色特征难以有效地提升行人重识别的精度,这些方法会将颜色特征与纹理特征或梯度特征结合使用,在一定程度减少了表观差异的问题,然而依赖特征设计者的设计经验,与度量学习算法也互相独立,无法解决光照和外部遮挡的问题。虽然传统算法占用的计算资源较小,但其检测性能难以满足如今市场需求。为此,越来越多的学者在行人重识别中使用了深度学习的方法。
1.2 基于深度学习的特征提取
以深度学习为基础的特征提取是通过卷积神经网络(convolutional neural network,CNN)提取目标特征,从而实现损失函数和距离度量的优化。基于深度学习的行人重识别特征提取主要分为4种:①提取全局特征;②提取局部特征;③提取语义属性特征;④提取时空特征。
基于全局特征的提取方法是直接利用CNN学习图片信息,获得行人的全局特征向量。早期的研究直接使用分类网络进行行人识别,分类网络通过全连接层提取出全局特征。虽然全局特征计算简单并且具有良好的不变性,但其特征维数高、计算量大,无法区分行人信息和背景信息,并且会产生无关背景的干扰现象。为此学者们设计出层数更深的卷积神经网络,比如VGG 16,GoogleNet,ResNet 50等等。后续的研究也基于这些深度卷积网络提取行人间更精细且具有强区分性的特征。
随着研究的不断深入,学者们开始对细小的特征进行学习,网络中也陆续增加了对局部特征的学习。行人图像中的局部特征数量丰富,特征之间的相关度小,不会因为遮挡问题影响其他特征点的检测和匹配。局部特征包括边缘、线和角点等。有学者将行人分割为数个水平条带,分别学习每个条带的局部特征,最后对局部特征进行整合。除了将图像分割成块,熊炜使用注意力机制关注人体骨架关键部位的特征,该文中提出行人的信息主要表现在躯干、肘、膝部、手腕、脚腕等部位,通过注意力机制获取到这些行人身体关键点的信息[11]。以上2种方法都没有考虑人体各个部位之间的关联性,人体每个部位之间的关系对于降低如遮挡、背景杂乱等影响有正向作用。为了解决该问题,有学者使用图卷积方法对关键点区域的局部特征进行整合,使用图匹配算法获取点与点之间的对应关系。
局部特征提取时可能存在行人图像划分后部分图像块中不包含行人特征信息的情况。仅仅使用局部特征进行行人重识别的工作不多,更多学者将局部特征与全局特征结合起来表示行人特征。HYUNJONG等在CVPR—2020上提出一种新的特征融合方法——全局对比池化方法(GCP)提取行人特征,增强了模型的特征鉴别能力[12]。该方法以ResNet50为骨干网络,将特征图在h的维度上均分成6块,分析每一块之间的关系并计算其GCP特征,整体流程如图5所示。
行人语义属性特征,就是按照人类语言意义使用计算机语言描述行人特征,判断2张图像中的行人是否为同一人,例如头发长短,衣服和颜色等信息。杨晓宇等结合行人语义特征与行人重识别技术,提出了一种新的行人重识别框架,在Market-1501和DukeMTMC-ReID数据集上的表现均处于领先水平[13]。此外,还有学者根据行人属性特征,利用GAN(generative adversarial network)网络生成新的行人图片,增加数据集的数量。
因行人图像不包含时间信息,遇到遮挡或拍摄角度变化等情况会影响识别效果,因此学者们通过视频中多帧行人序列表示行人时序和外观信息。图6展示了使用视频帧提取行人外观和时空信息。早期研究者直接提取每一帧信息,再通过最大池化或者平均池化获取视频特征。为了能够使用视频中的时间与空间信息,有学者基于LSTM(long short time memory)提出了一种视频行人重识别跨膜态匹配框架,该网络使用一个分支学习空间特征,其他分支学习帧与帧之间的关系。
当视频过长时,消耗的计算资源庞大,为了对不同长度的视频进行处理,通常将长视频分成多个短视频,聚集排名靠前的短视频,对共同关注的视频片段特征进行学习。为了更有效地提取视频帧中关键信息,蒋玉芳等使用帧间分差法提取关键帧信息[14]。针对视频中的异常帧,李自强等提出一种孪生网络模型,该网络均采用同样的自编码器结构,能够同时捕捉动作和外观信息[15]。
在行人重识别技术中使用深度学习算法进行特征提取,能够在无监督的情况下学习到行人的深层特征,解决行人监控视频中无标签数据多的问题,是行人重识别领域的重大飞跃,但同时存在由于数据集规模小而产生的过拟合问题,学者们针对该问题制作规模更大的数据集。此外,与传统手工特征相同,将多种深度特征组合使用往往能够优化识别结果,现阶段的研究主要将局部特征与全局特征相结合使用,在此基础上融入其他深度特征成为该领域中新的研究热点。
2 基于度量学习的行人重识别
行人重识别中为计算不同数据点间的距离,传统做法是根据行人识别领域的先验知识选择标准的度量距离如巴氏距离,欧式距离等等。但由于不同摄像机拍摄视角不同,分辨率不同且同时存在光线、遮挡、行人衣着以及姿态的变化,使用标准的度量距离来度量行人特征的相似度得到的重识别效果并不好,因此,学者们提出使用度量学习的方法进行行人重识别。基于度量学习的算法着重于找到行人特征之间有效的度量准则,拉近同类特征之间的距离,加大不同类特征之间的距离。最为经典的距离为马氏距离,使用标签相同的样本组成正样本对,标签不相同的样本组成负样本对,以此为约束建立马氏矩阵,在拉近相同人员的特征距离的同时增大了不同人员的特征距离。
基于马氏距离,学者们提出KISSME,XQDA,LMNN和LMNN-R等度量方法。保持简单直接的度量方法(keep it simple and straightforward MEtric,KISSME)以马氏距离作为其度量距离,通过样本对之间的似然比来检验它们是否为同一样本。交叉视角的二次判别方法(cross-view quadratic discriminant analysis,XQDA)是KISSME算法的推广,通过对多个场景的数据进行学习,将原样本的一个子空间,同时使用KISSME学习与子空间对应的距离函数。KISSME算法虽然并不需要迭代就可以找到闭合解,但是如果特征向量具有较高的维度时,会影响算法运行速度。齐美彬等使用学习好的交叉视图映射模型变换行人特征,消除了因摄像机拍摄区域不同造成的特征差异[16]。为增加子空间的判别性,黄新宇等使用Null Foley-Sammon方法对零空间内的总体散度矩阵和类内散度矩阵增量学习,获得了区分性较强的子空间[17]。为减少KISSME方法计算的复杂度,有学者使用PCCA(paired constraint component analysis)方法替代KISSME算法的降维步骤,降低计算的复杂度。包括大间隔最近邻方法(large margin nearest neighbor,LMNN)根据KNN训练样本得到同类的近邻样本,并根据样本的位置设置一个距离,距离之内的同类样本为目标近邻,反之则为伪装者。LMNN在最小化样本与其目标近邻距离的同时使样本与伪装者的距离最大化。LMNN-R为增加样本间的约束效果,使用全部样本的平均近邻边界替代LMNN中样本的各自近邻边界。
在度量学习中,常常由于正样本对数量有限,会受到大规模的负样本对的影响。针对该问题,通常做法是将度量学习视为逻辑归回问题,使得正负样本对分类概率最大化。由于单度量学习方法在使用过程中容易过拟合,学者们将多种度量学习方法结合使用。在实际应用中,度量学习常与特征提取网络结合起来构建出度量损失函数,用于增强特征描述与重识别模型的鲁棒性。常用的损失函数除了分类损失之外,还有对比损失,三元组损失等。
分类损失将行人重识别的训练过程直接视为多分类过程,利用行人ID作为训练的标签进行网络训练,每个行人的ID就是一个类别。对比损失主要用于训练孪生网络,通过降维拉近相同类别的样本点。基于三元组的度量学习将三元组间相对距离设置为约束条件,使得同类样本间距小于不同类样本间距。当输入2个相似图片,三元组损失(Triplet Loss)能够更好地对细节建模,进行细节区分,从而学习到更好的输入表示。与对比损失函数相比,通常给定一个三元组,包含一个相同目标的正样本,一个不同目标的负样本,和一个目标样例,通过网络训练拉近正样本距离,加大负样本间距离。三元组损失函数在选择样本对的时候会遍历全部样本,选择相差不大的正样本和相差很大的负样本得到的网络模型的识别能力弱,为降低这个问题的影响,有学者将每次训练中的最难正、负样本对挖掘出来,设计一种新的Triplet Loss。此外,潘玥等将三元组损失函数应用于行人重识别中,并进行了优化[18]。三元组是近年来使用最多的度量损失,以三元组损失为例,基于度量学习方法的行人重识别原理如图7所示。
包括三元组损失和分类损失在内的大多数损失函数对每个相似性分数的惩罚强度都相同,这种优化方式灵活性不高。圆损失作为一种新的损失函数,对需要优化的相似性分数进行加权,当相似性分数远离中心时,获得更强的惩罚。基于圆损失的行人重识别模型如图8所示,将行人重识别的总任务分解成多个子任务,模型通过每个子任务不断学习如何处理新的任务,在模型的学习过程中,使用圆损失约束行人的特征向量。FastReID模型中使用Circle Loss,该模型在行人重识别,车辆重识别等领域取得优异的成果。
上述损失中,三元组是应用最多的度量损失,圆损失作为度量损失的新秀,被认为是表现最好的损失。在多任务学习中,由于任务性质存在差异,需要多种损失函数联合使用实现网络优化。
综合来看目前基于度量学习的行人重识别方法大都从样本间距离出发,涉及投影子空间、特征对齐等多个方面。但基于样本特征向量之间的距离度量设计的行人重识别模型在行人关键信息缺失时准确率会大幅度降低,为此将特征提取和度量学习结合起来,提取到行人更加全面的外观和运动特征,能够降低该问题带来影响。其次,基于度量学习的行人重识别模型同样存在着数据集的问题。目前的大多数基于度量学习的模型需要使用提前标注好的数据集提升模型的鲁棒性,在数据集的建立中,不只是完整的行人样本难以收集,对大量的样本的进行标注也是一项巨大的工程。为此,度量学习需要考虑如何使用未标注的数据建立鲁棒性高模型。
3 应用分析
3.1 常用数据集
在行人重识别中,数据集包括图像数据集和视频数据集,图像数据集包括CUHK03,Market-1501,DukeMTMC-ReID,MSMT17;视频数据集包括iLIDS-VID,PRID2011,MARS,Duck-Video。相关统计信息见表1和表2。

表1 常用图像数据集统计信息
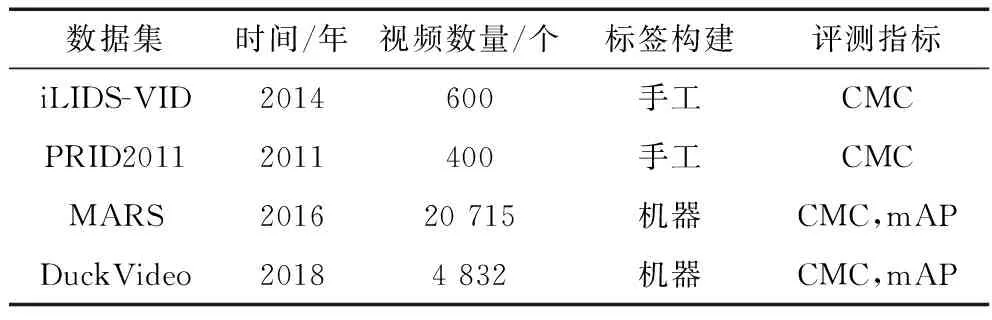
表2 常用视频数据集统计信息
随着学者们在行人重识别中引入深度学习的方法,规模小的数据集已经不能满足研究需求。表1和表2中的图像与视频数量变化表明了,随着年份的增长,数据集的规模在不断扩大,比如图像数据集中的MSMT 17和视频数据集中的MARS在规模上都有显著提升。为得到规模更大的数据集,标签构建方式由以往的手工标记逐渐改变为机器智能标记,评价指标也变得多样化,不再是单一的CMC指标。
将IDE,TriNet,Aligned ReID,MLFN,HA-CNN和FastReID等最新的研究方法在Market-1501数据集上的性能进行比较,见表3。
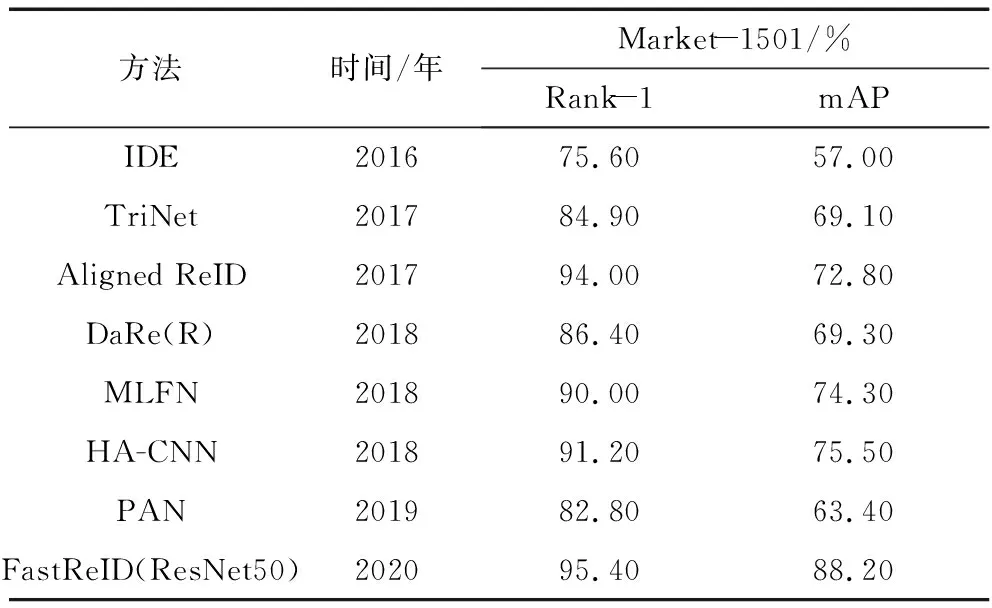
表3 ReID方法在Market-1501数据集上的性能比较
在上述研究方法中,IDE被学者们广泛用来当作深度学习方法的测评基准,后续提出的研究方法与IDE相比,其Rank-1与mAP值都有不同程度的提升,这是由于这些研究方法中都将多种特征提取方法与度量学习方法结合使用,其中2020年提出的FastReID方法的Rank-1与mAP值更是分别达到了95.40%和88.20%。
3.2 评价指标
为评估行人重识别算法在公开数据集上的效果,通常使用评价指标对算法模型进行量化比较,常用的评价指标主要有准确率(Precision)、召回率(Recall)、累计匹配曲线(cumulative matching characteristics,CMC)和平均精度均值(mean average precision,mAP)。
3.2.1 准确率和召回率
一般来说,Precision表示预测结果的准确率。
(1)
式中TP(true positives)为将样本中的正类判别为正类;FP(false positives)为将样本中的负类判别为正类。
Recall是指原始样本的中的正类被正确预测为正类的概率,称为召回率。
(2)
FN(false negatives)为将样本中的正类判定为负类。Precision和Recall都是针对同一类别的目标,并且只在检索到当前类别时进行计算。实际工程中,我们希望得到较高的Precision和Recall,但常在某种情况下难以实现。比如有100个正类,100个负类,预测结果均为正,那他的Precision为0.5,而Recall却为1,为此产生了F1-score。
3.2.2 F1得分
一般情况下,我们在保证Recall的前提下,尽可能的提升Precision,这就需要对2个指标进行综合权衡。F1得分(F1-score)结合了Precision和Recall的特点,表示Precision和Recall调和后的平均评估指标。
(3)
3.2.3 累计匹配曲线
CMC(cumulative matching characteristics)称为累计匹配曲线,在行人重识别领域有着广泛的应用。该曲线反映出分类器的性能,是Rank-k关于识别率的曲线。Rank-k表示按照某种相似度匹配规则,在前k个匹配结果中匹配正确的概率,如Rank 1是第1张结果平均匹配正确率。通常k取值为1,5,10,20。当匹配结果中只有一个匹配目标时,CMC能够取得极好的效果。但当存在多个目标时,CMC无法全面反映出分类器的性能。
3.2.4 平均精度均值
为解决多个匹配目标的测评问题,学者们提出平均精度均值mAP(mean average precision)。平均精度AP(average precision)是指Recall在0~1之间的全部值对应的精确度的平均值。假设库中某一目标行人的图片数量为n张,通过图像匹配的结果中,n张图片的位置分别为k1,k2,k3,…,kn,则AP为
(4)
AP的值越大表明目标图片在匹配列表中的排名越靠前,匹配的准备率越高。当所有的匹配图像均在不匹配的图像之前时,AP的值为1。mAP就是对多次输入的AP结果求和后再取均值
(5)
3.3 应用场景分析
智能视觉监控(intelligent visual surveillance,IVS)是通过机器学习以及深度学习等算法自动分析图像序列,实现监控场景中目标的识别、定位与跟踪,并对场景进行理解分析等,响应国家提出的”安全城市”与”智慧城市”建设。行人重识别作为智能视觉的子任务之一,主要应用场景如下。
1)工厂人员安全管控。如洗煤厂、炼钢厂等工厂中大型设备较多,工作环境差,容易发生安全事故。传统的视频监控会因工作人员视觉疲劳或疏忽等原因无法及时察觉危险。将ReID技术应用到该场景中,建立智能监控系统,当工人出现在任一摄像头中,系统及时与图像库中的工人图像进行匹配,并精准识别到工人的具体身份,确定工人的行动轨迹,从而避免工人进入危险区域。
2)矿井人员定位。与工厂人员安全管控类似,将ReID技术应用到该场景中能够准确的匹配识别到井下每一位人员,从而预判并规避风险。
3)商业ReID。为更好地了解用户需求,在大型商场中通过ReID技术来实时跟踪用户,为管理者优化用户购物体验提供便利。
4)手机相册聚类。在手机电子相册中,将单一照片视为查询图像,整个相册的图像视为图像检索库,使用ReID技术对图像进行匹配查询,可以将同一人的照片聚集在一起,方便用户进行相册管理。
5)小区安防。居民小区与其他场所不同,日常出入的行人多为小区常驻居民,将ReID技术应用到小区安防当中,既能够有效识别常驻居民,又能够在小区盗窃等犯罪活动中追踪犯罪嫌疑人。
6)公共场所智能寻人。如在火车站、游乐场、超市等人流量较大的大型公共场中,如果不慎与家人或朋友走散,常用寻人方式是通过广播寻人。而对于失散者是年龄较小的孩子或是听力不佳的残疾人等便难以起效。将ReID技术应用到该情景下,只需提供一张失散者的照片,系统就会在监控视频中进行实时搜寻匹配。
此外ReID技术的使用还可与人脸识别技术进行结合使用,但无论用于那种场景,都会面临光照变化和遮挡问题。
3.3.1 光照变化
某一时刻光照突然发生改变,会严重影响行人重识别模型识别的准确率,现阶段的研究方法以颜色特征为主,而光照的改变会导致行人图像颜色发生变化。
为降低光照对识别结果的影响,徐同文等对人体轮廓进行水平垂直分割,考虑不同光照时人体不同分割部位的颜色特征分布,使特征具有颜色不变性[19]。表4记录该算法与其他主流算法在CUHK01上的识别精度,可以看出该算法的精度一直高于其他的算法。除了建立具有颜色不变性的特征,处理光照变化的另一种方法是利用图像增强等方法对图像进行预处理,如Retinex 算法,之后提取出对光照变化更具鲁棒性的特征。
3.3.2 遮挡问题
在以上场景中,目标行人身体的任何部位随时都可能会被其他行人或者建筑物遮挡,这会导致行人外观信息发生改变。针对遮挡问题,学者们使用注意力机制引导网络学习图片中需要关注的区域,主要可以分为空间注意力机制、通道注意力机制和结合空间域和通道域的混合注意力机制[20]。表5记录文献[20]提出的行人重识别算法与其他主流算法的在Market 1501数据集和DukeMTMC-ReID数据集上的对比结果。从表5可以看出,融合注意力机制的行人重识别算法在不同数据集上的表现均优于其他的主流算法。
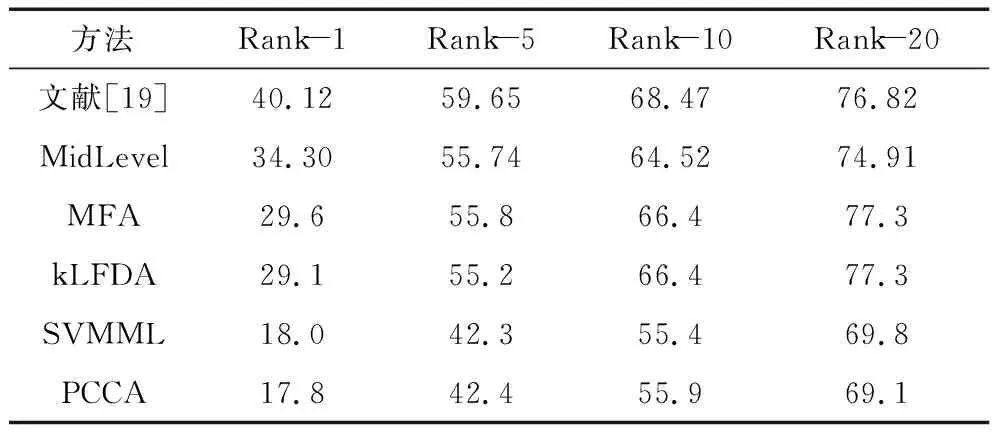
表4 光照对比实验
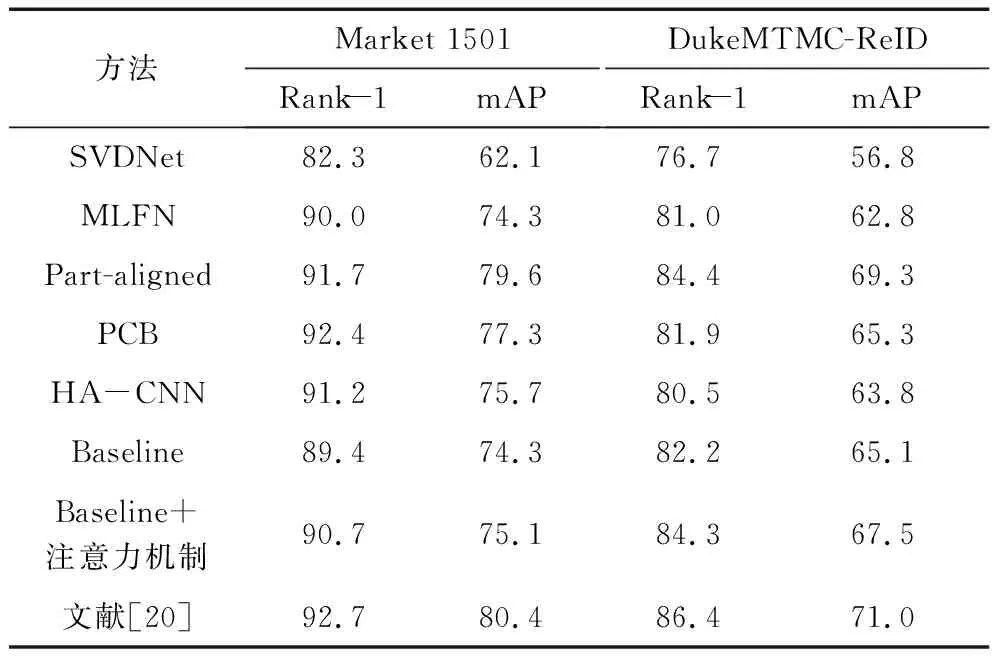
表5 遮挡对比实验
4 结 论
1)现阶段的行人重识别技术引入深度学习的方法,主要围绕特征学习和度量学习两方面展开,通过多种特征相互结合获取鲁棒性高、针对性强的行人特征,以应对遮挡、光照等多种因素带来的负面影响。但使用深度学习技术设计算法模型时,受制于现有的数据集的规模,相较于传统方法并未有重大的突破。所以在行人重识别今后的发展中,依旧需要收集规模更大的数据集,使数据集的数量接近实际应用的规模。
2)行人重识别技术可以理解为一种识别任务,但目前行人重识别模型的识别精度仍然不高,并且在实际应用需要同时保证识别精度与速度。因此,行人重识别未来的发展不但需要提高识别速率,追求网络的实时性,将无监督学习,跨模态学习以及轻量化技术应用到算法当中,还要注重与行人检测和行人追踪技术的联合使用,这将会有利于行人重识别技术在实际中的高效使用。
