基于头脑风暴算法的多处理机组合生产批量调度问题
2022-10-25王全武徐震浩顾幸生
王全武,徐震浩,顾幸生
(华东理工大学能源化工过程智能制造教育部重点实验室,上海 200237)
批量调度问题是指将大批量的工件分成若干个子批进行生产,以获得较短的生产时间。这类优化问题由Reiter 等[1-2]提出并广泛应用,以提高生产效率。Huang 等[3]构建了多目标等子批作业车间调度问题的模型,并提出了一种混合蚁群优化算法进行求解。Andrzej 等[4]针对二阶段柔性作业车间问题,建立了二阶段柔性作业车间分批调度模型。Juan[5]针对柔性作业车间环境下的批量分割和批量调度问题,提出了一种新颖的约束编程方法,可以兼顾批次分割和工件调度,适用于多种生产系统。
多处理机组合生产问题是指工件在每个生产阶段需要多台机器同时协同加工。Drozdowski 等[6]对多处理机任务的调度问题进行了阐述,并进行了分类分析和研究。Jiang 等[7]对多目标分布式混合流水车间组合生产批量调度问题进行了研究。Chen 等[8]对该类问题进行了扩展,针对每道工序,引入了柔性加工机器集,得到最优的机器组合和生产顺序。吕媛媛等[9]提出了一种改进的多目标粒子群算法,引入了外部种群寻优机制,解决了多处理机任务的车间调度问题。Liu 等[10]以求解最小化完工时间为目标,研究了带有子模块惩罚的多处理机调度问题,并提出了基于Lovasz 扩展的近似算法。Moghaddam 等[11]提出了一种新型免疫遗传算法以及一种新型的编码机制。
头 脑 风 暴 优 化 算 法(Brain Storm Optimization Algorithm,BSO)是由Shi[12]提出的一种新颖的启发式算法。曹国刚等[13]将头脑风暴算法与单纯性搜索法相结合提出了一种新的配准方法,有效地提高了医学配准精度,同时缩短了配准时间。李怡敏等[14]将密集聚类算法与头脑风暴优化算法相结合,在综合考虑航迹长度和威胁环境的条件下,实现低空范围内的航线规划。李捷等[15]引入随机分组策略和群纵横交叉机制,加强了算法的收敛性,同时避免过早陷入局部最优。
到目前为止,已有许多学者对多处理机组合调度问题进行了研究,但是针对作业车间环境下多处理机任务组合的批量调度问题的研究成果较少。因此,本文针对作业车间环境下考虑机器的准备时间的问题,提出了基于机器负荷的可变分批方式,建立了作业车间的可变分批调度模型,并提出了改进的头脑风暴优化算法。
1 问题描述和数学模型
1.1 问题描述
多处理机组合生产的作业车间批量调度问题(Multiprocessor Combined Batch Scheduling Problem,MCBSP)是经典的作业车间批量调度问题的拓展。n种类型的工件,每种类型的工件有w个,每个阶段的加工过程需要同时占用多台处理机,一台处理机在某一时刻只能进行具有同批次任务的加工,且该批次的任务一旦开始,就不允许中断。只有整个子批都完成加工,才可以进行下一道工序的加工。针对以上问题,建立作业车间组合生产的非混排批量调度模型,使系统的最大流程时间最小。该问题需要满足如下假设:
(1)不考虑机器故障,机器在零时刻准备就绪;
(2)同一台机器的某一时刻只能加工一种类型的工件;
(3)同一批次内只能包含一种类型的工件;
(4)同一批次的工件一旦开始不得中断,且工序间不允许抢占加工;
(5)每种类型的工件的工艺路线固定;
(6)不考虑工件在不同机器上加工的运输时间。
1.2 数学模型
1.2.1 下标定义

1.2.2 参数定义

1.2.3 决策变量


1.2.4 调度目标与约束条件
任意一种工件的总数量都等于它任意一道工序所分的每一个子批所包含的工件数量之和,即

每个子批所包含的工件数,由该工序的所有机器的负荷最小值、以及剩余未加工工件数量共同决定:

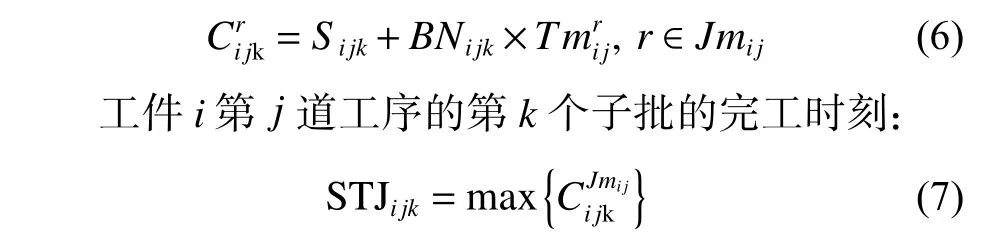
工序j第p个子批中的最后一个工件所对应的上一道工序的批次号s受限于上一道工序已经加工的工件数量和:

工件i第j道工序的第p个子批的开始加工时间,根据工件与机器的特性,存在以下4 种情况:
(1)当j> 1,时p=,1 工件 第ij道工序第一个子批的开始加工时间取决于机器集中的各台机器的释放时间和第j− 1道 工序上第s个子批完工时间的最大值。

2 具有贪婪思想的头脑风暴优化算法
2.1 BSO 算法
BSO 算法是一种全局优化的启发式算法,灵感来自于人类的头脑风暴过程,其中心思想是聚集一群具有不同背景的人进行头脑风暴,通过思想交流、观点融合来共同解决问题。每一次迭代过程类似于一次头脑风暴的过程,个体相当于是问题的解决方案。
2.2 BSO 算法的改进
基本BSO 算法存在着一些弊端,由于新想法的产生都是以原有的想法为线索,所以最优解的质量比较依赖于初始种群。为了提高初始种群的质量,在初始种群的产生过程中引入了贪婪思想。贪婪思想是受迭代贪婪算法的启发,寻找在插入工件加工序列中,时间增加最小的点作为插入点插入指定工件,直到所有工件的所有工序都考虑到。在分类方面,每次头脑风暴过程结束后,需要对个体进行评估,保证各组长是种群中最优秀的个体,每个组长按照能力来决定各自小组组员的数量,组员被随机分配到各小组中。在种群更新方面,为了解决基本BSO算法的弊端,引入动态组内组间讨论机制,组间讨论可以找到局部最优解,组内讨论则整合局部最优解,找出全局最优解。图1 示出了具有贪婪思想的头脑风暴优化算法(BrainStormOptimizationAlgorithm withGreedyThought,BSOGT)的流程图。
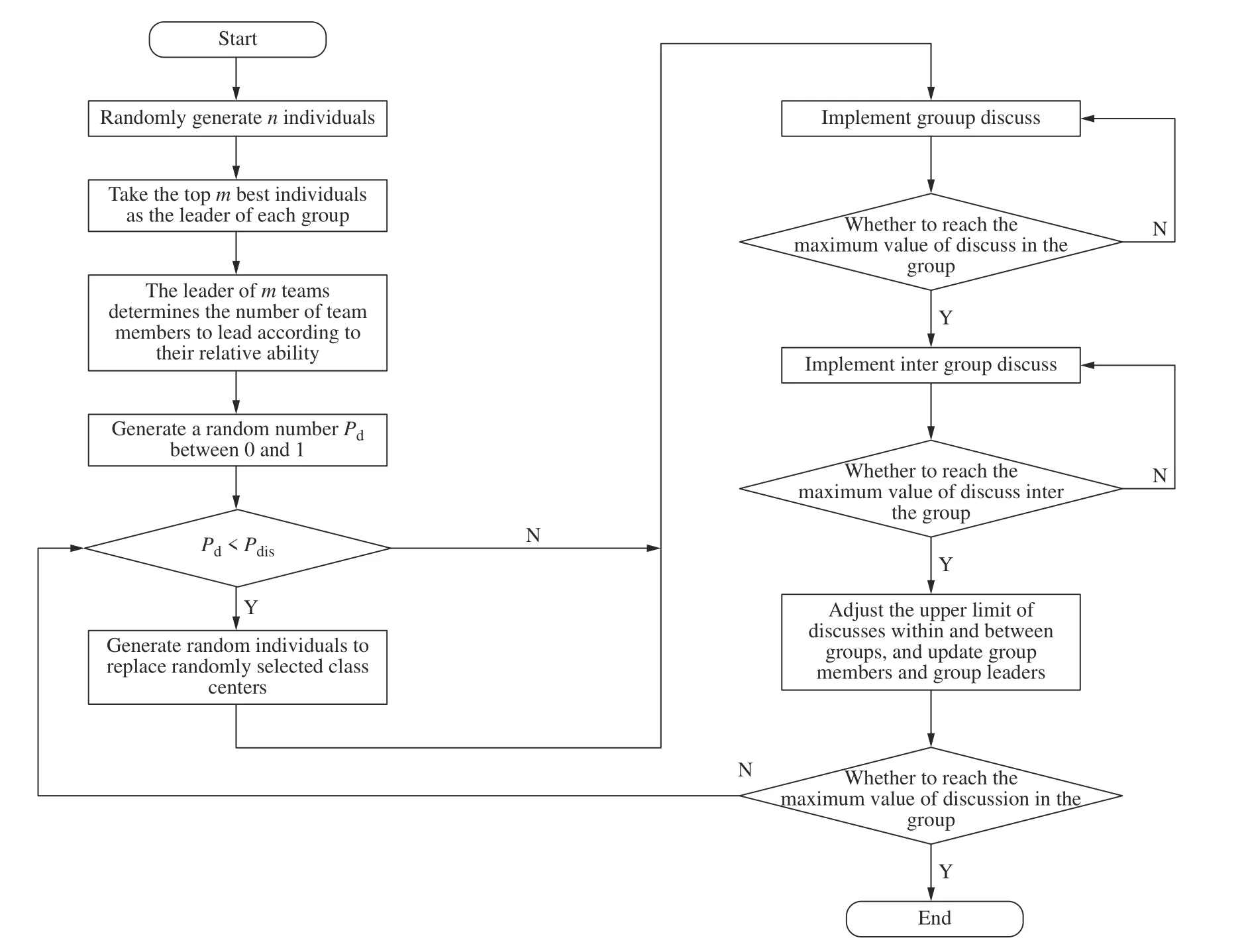
图1 BSOGT 算法流程图Fig.1 FlowchartofBSOGT
2.2.1 逆序POX 交叉重组操作 交叉操作是指两个父代个体经过迭代更新后使得染色体基因发生了互换,产生两个新个体的过程。张超勇等[16]描述了基本POX 交叉重组操作的规则,并基于改进POX 交叉操作的遗传算法解决了经典的作业车间调度问题。交叉操作可以产生尽可能多的新个体,提高算法的搜索能力。本文在基本POX 交叉操作的基础上增加了染色体逆序的操作,提出了逆序POX 交叉重组操作(ReversePrecedenceOperationCrossover,RPOX),操作步骤如图2 所示。图中数字分别表示工件和工序的编码,编码长度与每种工件的工序数量有关,是所有工件所需要的加工工序数量之和。其中,编码序列中的数字代表每种类型工件的编号,出现的次数代表着该类型工件的工序编号。

图2 逆序交叉重组操作Fig.2 Reverseprecedenceoperationcrossover
2.2.2 环 变 异 操 作 环 变 异 操 作(Ring Mutation Operation,RMO)是将个体围成一个环,保证每个基因作为变异起点的概率相等。该操作清除了传统的变异方式所产生的变异盲区,加强了个体中首尾基因的联系,增加产生优质个体的概率。环变异操作示意图如图3 所示。操作步骤如下:

图3 环变异操作Fig.3 Ringmutationoperation
(1)将待变异的染色体的首尾相接连成一个环;

(3)将劣环进行逆序操作,并且将其首尾相接连成一个环,即逆序劣环;
(4)在优环中,随机选择一个点作为变异基因的插入点,并且随机在逆序劣环上选择一个点将其拆开;
(5)将拆开的逆序劣环插入到优环中去,形成一个新的个体。
2.2.3 生成初始种群的方法(IEG) 针对初始种群的生成采用半随机生成、半引入贪婪思想的方式,取前半部分基因作为随机生成的基因,对后半部分基因引入贪婪思想,一次插入到可能的位置中,取插入该基因后生产周期增加的最小的点作为基因最后的插入点,直到完成所有工件的调度。

2.2.5 组间讨论 组间讨论的次数随着进化代数的增加而减小,如式(13)所示:

其中:Ntex为当前组间讨论次数;Nmi为算法的最多迭代次数;Nci为当前算法迭代次数。
组间讨论有3 种个体更新的方式:
(1)组长革命(LeaderRevolution,LR)。随机生成一条染色体,将其与每个小组的组长进行比较,如果新生成的染色体比组长好,则用来替换组长。
(2) 组 长 交 流( Team Leader Communication,TLC)。随机选取两个组,将两个组长进行RPOX 操作,如果子代个体质量优于父代,则替换之。
(3)组 员 交 流(Team Member Communication,TMC)。随机选择两个小组,在其中各随机选择一个个体,将这两个个体进行RPOX 操作,保留质量好的那个子代,再将其与父代染色体进行比较,如果优于父代染色体,则替换之。
2.2.6 组内讨论(In-groupDiscussion,IND) 组内讨论的次数随着算法迭代次数的增加而增加,即动态改变,如式(14)所示:

其中:Nt_in为当前组内讨论次数;Nm_t为组内讨论次数的上限;Nc_i为当前迭代次数;Nm_i为总的迭代次数。这样可以在搜索后期着重细致搜索,找到更加优质的解。
更新种群的方式有如下3 种:
(1)组长革命(LR)。将组长通过RMO 操作生成新个体,若其质量比原个体好,则替换之。
(2)组员革命(TMR)。在本组中随机选择一个组员,采用RMO 操作产生新个体,如果新个体优于该组员以及组长,则用其替换组员与组长。
(3)组员交流(TMC)。在本组中随机选择两个成员,进行RPOX 操作产生两个新个体,取最优个体,分别与父代个体进行比较,将质量差的个体替换掉。若最优子代个体比组长的质量好,则用最优子代个体替代组长。
头脑风暴优化算法具有新颖、参数少等特点,且应用在其他种类优化问题中都得到了较好的效果,故本文采用该算法探索其在批量调度问题中的应用。
3 仿真实验
以一个具体的6 种工件、4 道工序的生产系统为例,表1 和表2 分别示出了工件与机器的信息。其中,BH表示该种类型工件的总数,Jm表示工件的机器集合,PTm与Tm分别表示准备时间与加工时间。Oi表示第道i工序,Pmax表示机器的最大负荷。图4示出了调度方案的甘特图,其中浅灰色方块代表了各台机器加工不同类型工件的准备时间,其他颜色方块表示了不同种类工件在各台机器的加工时间,方块上面的JP-Q-k表示工件P的第Q个阶段的第k个子批。

表1 工件加工的信息Table1 Informationofjobprocessing

表2 机器的最大负荷Table2 Maximumloadsofthemachines
由图4 可知,该系统有6 个工件、4 个加工阶段,按照参与某个工件的所有机器的负荷的最小值与当前未加工工件的剩余数量进行分批操作。Job1 有3 个加工阶段,第1 个阶段由M4 和M5 组合加工,按照生产计划,Job1 的第1 个阶段从250 时刻开始分成3 个子批进行加工。第1 个子批在M4 和M5 上的加工完成时间分别为370 和394,所以该子批的第1 个阶段完工时刻为394。同理,第2 个子批和第3 个子批的完工时间分别为538 和610。第2 个加工阶段只有M3 参与,由于M3 的机器负载大于第1 个阶段的最小机器负载,所以必须在538 时刻才可以开始第2 个阶段的加工。同上,每个阶段每个子批的批量以及加工开始时间都要考虑机器约束和工件约束。

图4 多处理机组合生产的甘特图Fig.4 GanttchartofMCBSP
3.1 实验设置
由于本文研究的调度问题是随着生产系统的改变而新出现的,没有标准的Benchmark 算例库,故采用随机生成算例。机器准备时间的范围为(1,10),单位加工时间为(5,25)。机器数量(m)、准备时间(Setuptime)、工件加工时间(Processtime)、相同种类工件数量( Pi ec)e以及总工序数量(Totalprocess)的选取范围如表3 所示,其中 Total pr ocess=n×m× Piece,n和stage 分别为工件的类型和阶段数量。
由于此类批量调度问题不同于传统的作业车间调度问题,不同种类的工件数量不尽相同,从而会导致总的工序数量极速增大。即使针对只有6 种类型工件的生产系统(如表3 中 6× 4规模),需要调度的总工序数量也会达到360 个。

表3 不同规模算例工序总数统计表Table3 Statisticaltableofthetotalprocessfordifferentscalecalculationexamples
3.2 参数分析
BSOGT 算法的参数设置对于算法的寻优效果、收敛性以及运算速度有着很大的影响,本文采用响应面分析方法来确定其参数。以3.1 节算例库中的10×10 算例为例进行实验,每组实验独立运行5 次,取5 次运行Makespan 的平均值(AVG)作为响应值。利用Design-Expert10.0 软件,以AVG 作为评价指标,其二次多项式模型的方差分析结果如表4 所示。表中VS(VarianceSource)表示方差来源,MS(Main Square)表示均方,FD(FreedomDegree)表示自由度,SS(SumSquare)表示平方和P。<0 .0 5,说明回归模型高度显著;P> 0.05,说明模型失拟性不显著,回归模型拟合程度高。

表4 AVG 的二次多项式模型的方差分析Table4 ANOVAofquadraticpolynomialmodelforAVG
由3 种因素的P值可判断3 个实验因素对AVG有着显著的影响;该模型的决定系数与校正决定系数均接近1,说明该拟合回归模型具有较高的可靠性。拟合的残差正态概率分布图、预测与实际的对比图分别如图5 和图6 所示。由拟合结果可知,残差值较为均匀地分布在直线两侧,实际数据较为均匀地分布在拟合直线上下两侧,说明拟合效果很好。

图5 残差正态概率分布图Fig.5 Externallystudentizedresiduals

图6 模型预测值和实际值比较Fig.6 Comparison between predicted and actual value of the model
根据回归模型分析结果,选取种群规模population size=100,组长个数Nldr=,6 相对变异步P长mut=0 .2。
3.3 初始种群质量分析
2.2.3 节中提出了嵌入贪婪机制的IEG。为了说明其性能,将IEG 与随机的方式(RandomlyGenerate,RG)、基于反向学习机制(OppositionBasedLearning,OBL)的方式进行了比较。采用3.1 节中的数据集,使用BSOGT 算法,取所有初始种群的makespan 的平均值(AVG)作为目标。AVG 值越小,说明初始种群的质量越高。AVG 计算公式如式(15)所示。

其中:Ii表示第i个个体的质量;p为种群规模。表5示出了不同方式下的初始种群的质量。
由表5 可以看出,针对数据集中的算例,IEG 方式得到的AVG 比其他两种方式的AVG 要小。在IEG 中,个体当中有一半的基因是随机生成的,有一半的基因是引入贪婪思想后生成的,因此当有新基因插入到当前序列中时,应该选择所有可能的插入位置中使生产周期增量最小的插入位置。即在一半随机生成的基因中,每增加一个基因,该基因插入到个体中的位置,对于整个系统的影响都是最小的,所以相对于RG、OBL 方式,IEG 方式可以大大改善初始种群的质量。

表5 初始种群质量分析Table5 Qualityanalysisofinitialindividual
3.4 分批方式的影响
考虑到机器容量的限制,针对一致分批(CM),工件分批时需考虑参与其加工的所有机器的容量。针对不分批和等量分批的方式,由于机器容量的限制,需要对工件进行分批处理;由于某些工件的总数会导致无法对工件进行等量分批,如某种类型工件数量为15 个,而机器负载容量为2 个,实际上无法采用等量分批。该情况下的等量分批实质就是一致分批。因此本文只对可变分批(VM)与一致分批的影响进行分析。独立进行10 次实验,取最小值。同时,采用机器空置率的平均值(AverageMachineVacancy Rate,AMVR)来衡量机器的运行效率。AMVR 的计算如式(16)所示:

其中:PTj为机器的j实际生产时间;ET j、S Tj分别为机器j的加工过程结束时间、开始时间。实验结果如表6 所示,部分算例不同分批方式的甘特图如图7 所示。
由表6 可以看出,以 6× 4算例为例,一致分批比可变分批的生产周期平均多出11.00%。并且针对大多数的算例,可变分批相比于一致分批可以缩短生产周期。这是因为可变分批方式可以使工件在生产过程中灵活地进行分批,减少了待加工工件的等待时间和机器的空闲时间,进而缩短了生产周期。因此,本文提出的可变分批相比于一致分批更有优势。

表6 不同分批方式的对比Table6 Comparisonofdifferentbatchmodes
3.5 算法性能测试
取不同规模的算例进行测试。将BSOGT 与MA[17]、ICA[18]以及BSO[12]进行比较,每种算例独立运行10 次,分别以相对百分比偏差(RPD)、最优相对误差(BRE)、最差相对误差(WRE)作为性能指标,如式(17)~式(19)所示。

式中:MAX、MIN、AVG、Best 分别表示最大值、最小值、平均值和最优值。对比结果如表7 所示。
从表7 可以看出,针对 15× 7 、5 0× 15算例,所有算法的性能指标都接近0,说明当算例规模较小时,所有算法均可以找到最优解,性能差别不大。随着规模的增大,ICA、MA、BSO3 种算法的RPD、BRE、WRE 指标都在变大。RPD 增大,说明算法的寻优能力减弱,而BRE 和WRE 的增大反映了算法的稳定性变差。BSOGT 算法在大部分算例中的RPD、BRE、WRE 都小于其他3 种算法,且随着算例规模的增大,BSOGT 算法的优势更明显。图7 示出了两组不同规模算例的算法收敛曲线。由于BSOGT引入了动态的组内、组间讨论机制,故BSOGT 在算法进化的初期有着较快的收敛速度,注重全局搜索,而在算法迭代后期,注重局部搜索,有着较好的寻优能力。

表7 算法性能对比表Table7 Performancecomparisonofalgorithms

图7 不同算法的收敛曲线Fig.7 Convergencesofdifferentalgorithms
综上所述,引入贪婪思想来生成初始种群,动态的组内、组间讨论策略以及改进的变异操作使得BSOGT算法无论是初始种群的质量,还是收敛速度以及寻优质量都优于其他算法。
4 结 论
本文针对作业车间环境下多处理机组合生产的批量调度问题,考虑了机器的准备时间以及机器的加工负载,提出了可变分批方式,建立了调度模型。针对基本头脑风暴算法收敛速度慢,容易陷入局部最优的缺陷,提出了改进的头脑风暴算法,优化建立的数学模型。为了提高初始种群的质量,引入了贪婪思想。将BSOGT 进化过程分为组内讨论和组间讨论两个阶段。组内讨论通过组员与组员、组员与组长的相互交流来更新高质量的个体;组间讨论通过组长与组长、不同组的组员之间的交流来更新高质量的个体。每次迭代中组内讨论次数随着迭代次数的增加而增多,组间讨论次数随着迭代次数的增加而减少。使得在搜索开始阶段,加强广泛搜索,充分发现潜在的全局最优;而在搜索后期,着重细致搜索,加速收敛。
