一种基于卷积神经网络的VVC去压缩伪影半盲方法
2022-10-24卿粼波何小海熊淑华陈洪刚
帅 鑫,卿粼波,何小海,熊淑华,陈洪刚
(四川大学 电子信息学院,四川 成都 610065)
0 引言
随着通信技术的高速发展,人们拥有越来越多的通信方式,除了对讲机、手机等语音通信方式外,诸如可视电话、视频会议等图像通信的方法应用越来越广泛。相比于语音信号,包含更多信息的图像信号以其生动、形象等特点更受人们青睐,而能够表现活动场景的连续图像——视频,也应用于各种场景,如保护城市的监控视频、辅助医学诊断的医学视频和休闲娱乐的直播视频等。由此可见,视频已经占据生活中不可或缺的地位。于是,视频技术迅速发展,视频逐渐拥有更大的分辨率,包含更多的信息,这也就造成了视频不可忽略的缺点,数据量大,所需带宽大,因此传输与储存困难。多功能视频编解码(Versatile Video Coding,VVC)[1]是新一代视频编解码标准,比起高效率视频编码标准(High Efficiency Video Coding,HEVC)[2],VVC拥有更强大的压缩性能,能够更有效地去除视频信号中大量存在的空间冗余与时间冗余信息,从而以极大的压缩比将视频编码为码流文件。在解码端,将码流文件解码可以重建视频,但由于编码过程中存在的量化、变换等操作,重建得到的解码视频部分信息损失,导致压缩伪影,降低视频质量及用户的观影体验。因此,解码视频的压缩伪影去除研究非常具有意义。
目前,许多学者在压缩伪影去除课题上进行了不少研究。Zhang等[3]提出了一种新的自适应环路滤波器,利用非局部先验信息对相似图像进行低秩约束去压缩伪影。徐艺菲等[4]提出了一种基于非局部低秩和自适应量化约束先验的后处理算法,该算法利用解码视频及其量化参数获取自适应量化约束信息,再利用split-Bregman迭代算法来优化最大后验概率框架从而去压缩伪影。上述2种算法都是传统算法。而近几年来,深度学习技术迅速发展,在图像增强[5]、目标检测[6-7]、图像/视频去噪[8-9]等计算机视觉研究中取得了巨大成果。不少研究人员受此启发,提出了许多基于深度学习的视频压缩伪影去除方法。Dong等[10]最早提出用卷积神经网络(Convolutional Neural Network,CNN)去图像压缩伪影,该方法通过四层卷积层分别实现特征提取、特征增强、特征映射及图像重建实现。该方法主要是针对图像,对视频而言,性能有限。Dai等[11]提出了一种可变滤波尺寸的残差学习CNN (VRCNN)用于HEVC视频编解码后处理,该方法主要利用不同尺寸的卷积核提取不同尺度的特征信息,用于视频去压缩伪影。Wang等[12]提出了一种深度CNN自适应解码方法(DCAD),其通过使用更多的CNN层来不断提取映射视频以获得更好的效果。但这些方法没有考虑到视频编码的特点,性能有限。视频编解码标准根据编码模式不同将视频帧分为I(Intra Frame)帧、P(Predicted Frame)/B(Bidiretional Prediction Pictures)帧。考虑到这种特性,Yang等[13]提出了一种可扩展的CNN,该网络以不同的卷积核尺寸以及卷积层深度组成2个模块,分别针对I,B/P帧,取得了不错的效果。但以上这些方法主要是利用视频中的空域信息恢复视频质量,视频中帧与帧之间还存在着时域信息,这些时域信息可能包含上一帧或下一帧损失的信息,对压缩伪影去除工作具有较大的作用。Yang等[14]最早提出了一种利用时域信息的多帧质量增强网络,该网络将视频帧划分为高质量帧与低质量帧,然后利用高质量帧去增强低质量帧,取得了较好的效果。为了更好地获取时域信息,Deng等[15]提出了一种空时域可变卷积网络,该网络通过精确到像素级的运动补偿获取更加精确的时域信息。
但以上这些基于CNN的方法是在预设置了量化参数(Quantization Parameter,QP)后进行训练,是非盲方法。在实际应用中,QP不一定能够获取,如电视机这类只获取了解码视频的设备。因此,这些方法不太合适此类无法获取QP的盲场景。众所周知,比起盲方法,非盲方法因为拥有已知信息,训练的模型会更有效果。因此,结合二者优势,提出了一种能够针对盲场景的半盲方法。首先,根据视频编码特性,提出一种QP预测网络来预测解码视频的QP;然后,提出一种多帧压缩伪影去除网络,并且预训练了几个不同QP的模型;最后,根据预测结果,对应QP训练的模型被用于增强解码视频的质量。
1 算法实现
1.1 QP预测网络
1.1.1 预处理
图1展示了本文方法的整体框架。直接预测解码视频的QP是困难的,因为在视频编码过程中,即使整个视频被设置了相同的QP,但由于每帧的预测模式不同以及每帧编码块的划分方式不同,QP会进行一定程度上的变动,导致具体的每个编码块以及每帧的QP可能不同。因此,直接对解码视频进行预测之前,针对上述情况,需要对解码视频进行预处理。本小节提出的预处理方式是通过提取能够代表视频压缩效应的样本块间接预测解码视频的QP。
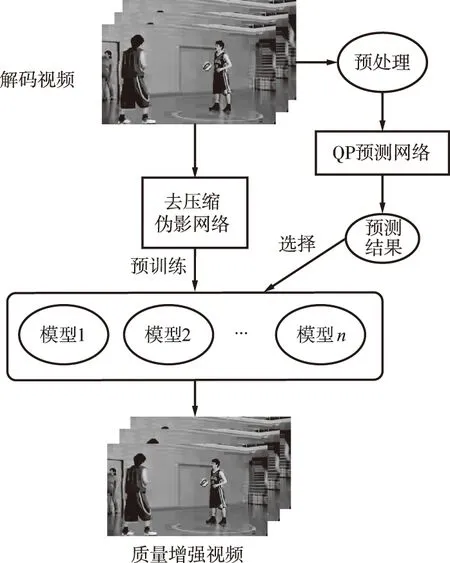
图1 VVC压缩伪影去除半盲方法的整体框架Fig.1 Overall framework of semi-blind method for VVC compression artifact reduction
图2所示是序列BasketballPass的第1帧,图3所示3张图是该帧分别在QP设置为32,37,42时的解码帧的某一区域放大图。由图3可以发现,对于纹理平滑区域,如背景墙壁区域,3张图并无太大差异,而对于纹理丰富的区域,如篮球、手和衣服上的字等,这些区域随着QP增大,越来越模糊,压缩效应逐渐严重。因此,视频帧中纹理丰富的区域更能代表一个解码视频的压缩特性,通过提取纹理丰富的区域作为特征块,从而间接预测解码视频的QP更为合理。

图2 序列BasketballPass的第1帧Fig.2 The first frame of “BasketballPass”

(a) QP32
一般,在视频帧中,图像的边缘部分往往是纹理丰富的区域。Kirsch算子是R.Kirsch提出的一种边缘检测算法,是一种非线性边缘检测器,其采用8个模板对图像中的每一个像素点进行卷积求导,而这8个模板代表8个方向,对图像中的8个边缘做出最大响应,从而提取图像的边缘。所以,预处理环节通过使Kirsch算子获取纹理丰富的区域从而获得特征块。考虑到VVC最大编码单元的尺寸为128 pixel×128 pixel,特征块尺寸也设置为128 pixel×128 pixel。
1.1.2 预测网络
提取出合适的特征块后,提出了一个网络来预测QP。网络的结构如图4所示。

图4 QP预测流程Fig.4 Process of QP prediction
整体而言,该网络采用了分类网络的思想。首先,使用卷积层初步提取图像块特征;然后,通过密集连接块中的激活函数“Leaky ReLU”与卷积层与BN(Batch Normalization)层的密集连接方式不断强化特征。平均池化层用于下采样与过渡密集连接块,最后,通过完全连接与softmax层进行回归分类,输出初步预测结果。虽然QP预测网络可以为每个特征块预测,但具体的每个编码块以及每帧的QP可能不同,导致预测出现偏差。为此,还提出了一种投票机制。即,对于同一解码视频的所有特征块,通过预测网络为全部特征块预测出QP之后,统计预测结果,选择结果中预测次数最多的QP作为当前解码视频的QP。
1.2 压缩伪影去除网络
该网络模型的架构如图5所示。该网络是一个多帧输入网络,除了需要输入待增强的目标帧Ft,还需要输入能够提供时域信息的上一帧Ft-1与下一帧Ft+1,最后输出增强后的帧Fe,其中,t表示视频序列的某一帧。该网络由运动补偿子网络和去伪影子网络两部分构成。

图5 压缩伪影去除网络的框架Fig.5 Framework of compressed artifact reduction network
1.2.1 运动补偿子网络
一般,多帧输入网络的性能会比单帧输入网络的性能更好一点,这是因为相邻帧可能拥有目标帧中缺少或者损失的细节,引入相邻帧作为目标帧的参考帧,可获得更多时域信息。但是,由于帧与帧之间存在的运动误差,直接使用相邻帧可能会导致负面效果。通过对相邻帧进行运动补偿,可以有效解决这种问题。Caballero等[16]提出了一种空间变换运动补偿(Spatial Transformer Motion Compensation,STMC)网络,其思想是用一条粗路径尺度与一条细路径尺度预测从相邻帧到目标帧的运动光流,从而补偿相邻帧,其架构如图6所示。

图6 运动补偿子网络的框架Fig.6 Framework of motion compensation subnetwork
其中,“Conv”表示卷积层,后面的“n×n”表示卷积核的尺寸为n,“Concate”表示特征融合的操作,“Wrap”表示扭曲特征的操作。该小节使用STMC作为运动补偿子网络。其过程为:
F′t-1=Nmc(Ft,Ft-1),
(1)
式中,Nmc(·)表示运动补偿子网络;F′t-1表示补偿后的上一帧。
1.2.2 去压缩伪影子网络
通过运动补偿子网络,可以获得补偿后的相邻帧F′t-1与F′t+1,其与目标帧一起输入到去伪影子网络。该子网络框架如图7所示。
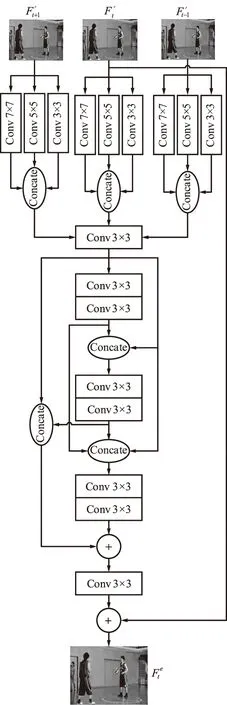
图7 去压缩伪影子网络的框架Fig.7 Framework of compressed artifact reduction subnetwork

(2)
式中,Nar(·)表示去伪影子网络。
因此,整个压缩伪影去除网络为:
(3)
1.3 训练策略
本小节分别提出了QP预测网络与压缩伪影去除网络,这2个网络采用不同的方式训练。
1.3.1 QP预测网络训练策略
对于QP预测网络,采用交叉熵损失函数训练,如下:
(4)
式中,M代表类别;N代表样本总数;yic代表符号函数(0或1),如果样本i的真实类别等于c,则取1,否则取0;pic代表样本i属于类别c的预测概率。
1.3.2 压缩伪影去除网络训练策略
对于压缩伪影去除网络,其由运动补偿子网络与去伪影子网络2个子网络组成,所以采用联合训练的方式。
运动补偿子网络的目的是尽可能地使补偿后的相邻帧接近目标帧,因此,在监督下采用最小均方误差函数训练,即:
(5)
去伪影子网络的目的是使增强帧尽可能接近原始帧,因此需要在原始帧的监督下训练。考虑到L2正则化损失函数可能会导致输出过于平滑,选用L1正则化损失函数,即:
(6)
则,整个压缩伪影去除网络的联合损失函数为:
L去伪=a×Lar+b×Lmc,
(7)
式中,参数a与b作为权衡参数。在实验中,a设置为0.99,b设置为0.01。
2 实验结果
2.1 实验设置
实验过程中,数据集Vimeo-90K[17]包含大量416 pixel×224 pixel的7帧序列,本文采用该数据集作为训练集。VVC标准测试集被用于测试本文所提的算法。为证明实验的科学性,训练与测试之前,所有数据集都需要用一样的编码配置进行编码。实验过程中,选择用VVC标准参考软件VTM9.0,在LDP(Low Dealy P)配置下进行编码。因为QP越大,解码视频的质量越低,而QP越小,解码视频的质量越接近原始视频,所以,对大QP编码的视频进行去压缩伪影工作更具有意义。因此,实验中设置QP为32,37,42。除此之外,2个网络的输入尺寸设置为64 pixel×64 pixel,这是从训练集中随机裁剪的。ADAM优化器用来加速网络训练,其参数β1,β2和ε分别设置为0.9,0.999和10-8。2个网络的初始学习率都设置为10-4,每迭代50次减半。实验设备是Inter Corei7-8700 CPU 和 Nvidia GeForce GTX1080Ti GPU,实验平台是Pytorchv1.6。
2.2 实验结果
2.2.1 QP预测结果
为了验证1.1节所提QP预测算法的有效性,将16个VVC标准测试序列用于实验,包含1 920 pixel×1 080 pixel(B类)、832 pixel×480 pixel(C类)、416 pixel×240 pixel(D类)、1 280 pixel×720 pixel(E类)等分辨率序列,这些测试视频全部在QP为32,37,42下采用LDP配置编码。然后用所提出的算法进行预测,结果如表1所示。

表1 QP分别设置为32,37,42的解码视频序列的QP预测结果Tab.1 Quantization parameter prediction results of decoded video sequences with quantization parameters set as 32,37 and 42 respectively
观察实验结果可以发现,所提的量化预测算法效果较好,QP为32的序列预测正确率达到了87.5%,QP为37的序列预测正确率达到了62.5%,QP为42的序列预测正确率达到了75%。
在这些测试序列中,“Kimono1”序列是一种运动较为缓慢的序列,呈现出一种静态感觉,并且该序列的背景区域充斥着大量树叶、光斑等,这对预处理与QP预测带来了困难,因此这类视频的预测结果不太准确。对于大部分视频序列,所提的预测算法是有效的。
2.2.2 压缩伪影去除结果
为了证明1.2节中所提去压缩伪影算法的有效性,本小节用2.2.1节中提到的16个VVC标准测试序列在盲场景与非盲场景下进行实验,并以VTM9.0编码的视频序列的峰值信噪比(Peak Signal to Noise Ratio,PSNR)提升的分贝作为衡量标准,并且对比其他非盲方法[11-12,14],结果如表2所示。其中,所提算法(非盲)是指在非盲场景下,QP已知,直接用压缩伪影去除网络达到的实验结果;所提算法(盲)是指在盲场景下,不知道QP,先通过QP预测网络获取,再通过压缩伪影去除网络达到的实验结果。

表2 不同方法在QP设置为32与37时提升的PSNR比较结果Tab.2 Comparison of improved PSNR between different methods with QP set as 32,37 单位:dB
观察表2可以发现,在非盲场景下,QP为37时,这些VVC标准测试序列的平均PSNR达到了0.238 6 dB,在QP为32时,平均PSNR达到了0.203 3 dB,均优于其他算法;而在盲场景下,因为某些序列的QP预测有误,导致没有选择对应的模型,所以该序列提升的PSNR略微下降。QP为37时,平均PSNR为0.224 6 dB,QP为32时,平均PSNR为0.200 5 dB。即使是在盲场景下,所提的方法依旧优于其他非盲方法,能够有效提升PSNR。
虽然存在部分序列的PSNR未能超过其他方法,如“ParkScene”,这是因为该序列运动剧烈,压缩伪影较大,而文献[14]提出的用高质量的帧作为目标帧的参考帧的方法能够有效针对该序列。而对于多数序列,依旧是本文所提算法提升的PSNR更优。实验结果可以证明所提算法的性能良好,即使是针对不知道QP的半盲方法,其性能依旧不低于非盲方法。
3 结束语
尽管基于神经网络的视频压缩伪影去除技术相关研究已有不少,但目前大多都是要根据QP预训练去伪影模型。本文提出的VVC压缩伪影去除半盲方法旨在应用于无法获取解码视频QP的场景下增强解码视频的质量。该方法首先通过一个预测方法来预测解码视频的QP,为了获得更好的预测结果,该方法对视频进行了预处理,并提出了一种QP预测网络,用投票机制输出结果。然后,提出一种压缩伪影去除网络并训练去压缩模型,再根据预测结果,选择对应QP预训练的模型对视频去压缩。这个过程结合了非盲训练方法针对盲场景,所以称为半盲方法。而实验的结果也证明所提方法的有效性。
本文提供了一种在不知道QP场景下去压缩伪影的研究,该研究还有更深的探索空间:
① 解码视频的压缩特性,不止是体现在压缩伪影上,还表现在人眼主观质量、客观评价指标等,可以进一步探索这些特性以预测解码视频的QP以及其他相关的编码参数。
② 去伪影相关工作是增强视频质量的重点,尽管该方面的相关技术已有不少,但依旧拥有广大研究空间,更精确的运动补偿、更多帧与帧之间相关性的研究等,都能进一步提升去伪影的性能。
