基于深度学习的网络媒体情感分析
2022-10-18周凯李晖刘桐
周凯,李晖,刘桐
(沈阳工业大学信息科学与工程学院,沈阳 110870)
1 引言
情感分析也称为意见挖掘[1],它是利用计算机技术对文本的观点、情感倾向进行挖掘与分析,并利用人工智能的神经网络对文本情感倾向进行分类判定。文本情感分析技术主要可划分为基于人工和机器学习的传统分类方法[2-3]和基于深度学习的分类方法两种。基于人工的分类方法很大程度上取决于情感词典的构建,主要是通过对标注情感词典的极性和强度标注来实现文本的情感分类。由于构建的词典通常只针对特定领域的固定短文本,对于长文本和跨领域的情感分析任务来说,该方法费时、费力且迁移能力较差。基于机器学习的方法,先对文本的语料库进行标记,利用特征提取的方法提取特征,再在分类器中输入所提取的特征,计算概率分布达到情感分类的目的,这类方法成功的关键在于选择出大量高质量的标注样本、最佳的特征组合和分类器,机器学习的准备工作需要耗费大量精力,模型泛化能力差。与此同时,机器学习的算法对复杂语境下的表达能力有限,不能捕捉文本隐藏语义之间的关联性,从而影响分类的准确率。本研究针对上述问题,提出一种基于深度学习的情感分析模型。
2 文本向量化及神经网络搭建
2.1 BERT预训练语言模型
BERT(Bidirectional Encoder Representation fromTransformer)[4]是根据Transformer中衍生出来的预训练语言模型,能实现文本的向量化。BERT作为一种预训练语言模型,预训练过程是最为核心的部分,其中包括MLM、NSP两个预训练任务。
MLM训练任务可以看作是完形填空的形式,每当输入一句话,模型会随机地遮住一些要预测的词,使用[MASK]特殊符号统一表示。这个选取的概率是每个句中15%的词。例如:疫情严峻→疫情严[MASK]。此处将“峻”字进行了特别的MASK处理,再利用无监督学习的方法,来预测MASK位置的词语。BERT模型对随机选取的15%的词汇做出如下三种处理,使模型更加合理。
1)80%的时间是采用[MASK]处理:疫情严峻疫情严[MASK]。
2)10%的时间是随机取一个词来代替MASK的词:疫情严峻→疫情严酷。
3)10%的时间保持不变:疫情严峻→疫情严峻。
NSP训练任务可以看作是段落重排序。当输入句子A和B时,判断二者是否前后句。在此基础上,从语料库中随机选取了50%的B作为A的背景句,其余50%的B是在语料库中随机匹配的。引入NSP训练任务可以更好地让BERT学习到连续的文本片段之间的相关性,并且把其相关性保存在[CLS]符号中。预训练任务流程如图1所示。

图1 BERT预训练任务流程示意图
2.2 TextCNN神经网络
TextCNN的网络结构如图2所示。与传统的CNN[5]相比,TextCNN的结构并无显著差异,它仅包含一层卷积层和一层最大层池化层[6]。
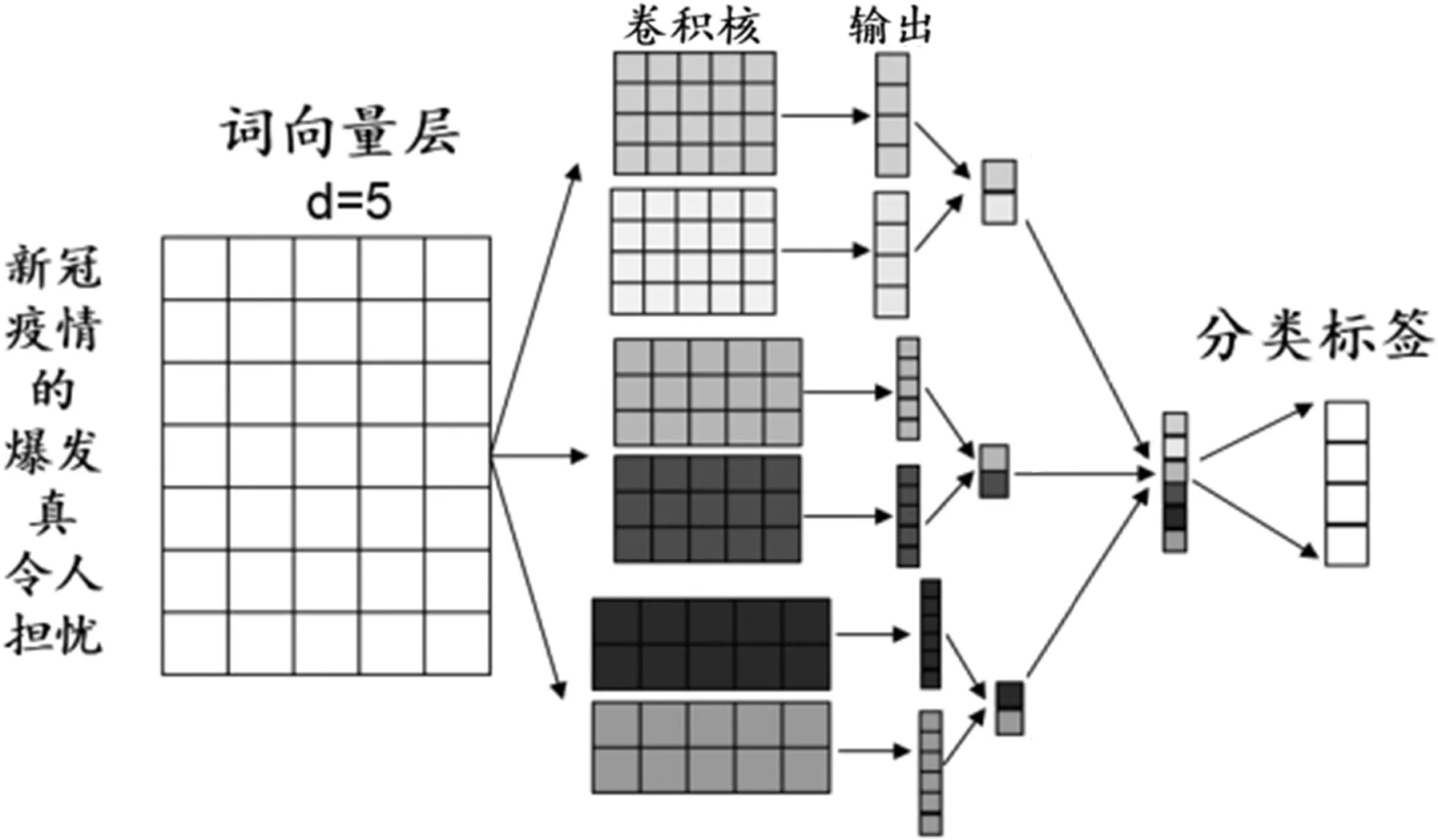
图2 TextCNN网络结构
TextCNN网络主要通过卷积层提取语句的不同特征,池化层提取其中最重要的特征,再加上全连接和softmax层,最后输出情感分类结果。
局部特征的获取是CNN的关键。在文本中,局部特征一般由一个或多个字构成,类似于N-gram。CNN的优势在于可以自动地结合、筛选出各种抽象层次的语义信息。
TextCNN的输入层是一个n×d的矩阵,其中n表示句子的字数,d表示每个单词对应的向量维度。因此,输入的每一层就是一个单词对应的d维的词向量。此外,本研究还对语句进行填充处理,以保证词向量的长度一致。
对文本的卷积运算和图像的卷积运算是完全不同的。在图像处理中,通常采用正方形核,例如3×3的卷积核,卷积核沿着整个图像的高、宽,按步长进行卷积运算。而TextCNN的卷积层[7-8]是一维卷积,它的卷积核尺寸是固定的,即词向量维度d。卷积核仅沿高度方向运动,而卷积核的高度也就是该窗口内文字的数目。当设置kernel_size=(2,3,4)时,即为一个窗口中分别可以包含2、3、4个单词。由于矩阵的一行代表的是一个单词,所以确保了词作为语言中的最小粒度。
2.3 DPCNN神经网络
2017年腾讯提出用于文本分类的模型DPCNN(Deep Pyramid Convolutional Neural Networks)[9],其网络结构如图3所示。该模型比TextCNN更加深入,并且增加了残差网络,能够更好地捕捉长文本之间的相关性,从而弥补了TextCNN在实现文本的分类任务时,由于本身网络深度太浅而无法获得长距离文本信息的缺陷。

图3 DPCNN网络结构
DPCNN采用每个卷积块包含两层等长卷积的方式提高词位的丰富性。等长卷积意味着输出序列的长度与输入序列长度相等。将输入输出序列的第n个词向量称为第n个词位,此时尺寸为m的卷积核所生成的等长卷积就是将该词位和它附近(m-1)/2个字的上下文信息进行压缩后的词向量。与此同时,DPCNN使用两层等长卷积累加会让每个词位的词向量语义更加丰富准确。
在DPCNN中采取了与ResNet网络不同的方式,将feature map的数量进行了固定。该方法通过对词向量空间的维数进行约束,使相邻词在原空间或类似于原空间的情况下进行融合。同时,DPCNN在整个网络结构上看是深层的,但是从语义空间的角度上观察是扁平的。
当DPCNN为池化提供了恰当的合并条件后,就可以用1/2池化操作进行合并信息。同样大小的卷积核,每经过一个1/2池化层,所能感知到的文本语义范围就会增加一倍。
2.4 情感分析模型设计
首先在语料S={w1,w2,…,wn}输入到BERT模型时,将在文字的开头加上[cls]特别的标签,含义是分类,并将[sep]标签添加到文字的结尾。BERT将一连串上下文序列作为输入,经过多层transformer编码层处理,BERT为每个输入标记生成对应的隐藏状态向量,并输出隐藏向量序列E={H[CLS],H1,H2,…,Hn,H[SEP]}。在此基础上,利用H[CLS]作为文本输入序列的聚合向量表达,它包含上下文信息,可直接用于一步任务模型的输入,实现情感分类。BERT-DPCNN情感分析模型如图4所示。

图4 BERT-DPCNN情感分析模型
3 实验与结果分析
3.1 数据集介绍
实验在网络媒体平台爬取[10]评论数据10万条,在数据清洗过程中,删除无任何情感倾向的错乱语句和仅由符号构成的评论,保留文本评论98270条。将其中80%的评论文本作为训练集数据,10%设置为测试数据集,剩余10%作为实验验证集,每个数据集包含10个情感标签。其中10种情感标签分别对应开心、喜爱、惊讶、悲伤、厌恶、生气、同情、羡慕和失望。
3.2 实验设置和评估指标
实验基于矩池云服务器Python3.7编程语言实现,选用Pytorch框架搭建神经网络。实验数据设置4400个epoch进行训练。
实验选取了准确率、损失函数值、召回率,作为评估指标,评估情感分析模型的性能。通过与其他模型对比,验证本模型的有效性。实验结果对比如表1。

表1 实验结果对照表
可见,实验搭建的深度学习情感分析模型在准确率这一指标上都有着不错的表现,因此基于BERT-TextCNN和BERT-DPCNN的模型都适合于应用在情感分析任务上。具体来看,BERT-DPCNN在情感分析任务上有着更加突出的表现;同时,DPCNN可以更好的捕捉长文本之间的相关性,这一点也得到了验证。
在损失函数值这一指标上,实验搭建模型符合理论预期。基于BERT-TextCNN和BERT-DPCNN的模型都适合于应用在情感分析任务上。
3.3 实验结果分析
实验得到的准确率曲线如图5所示。从单条曲线上看,无论是基于TextCNN还是DPCNN网络,其准确率都随着epoch次数的增加,先快速提高,然后逐渐趋于平稳,曲线整体平滑。两种模型的准确率曲线与情感分析任务相吻合。随着迭代次数的增加,词表内的语料被逐渐加载,模型准确率也随之增加。对比之下,基于BERT-DPCNN模型的准确率更优。

图5 准确率百分比曲线
实验得到损失函数值曲线如图6所示。通过实验数据曲线可见,所有网络模型的损失函数值都随着epoch次数的增加,先快速收敛,然后趋于平稳,最后达到模型最优时停止迭代。曲线整体平滑,起伏较小。损失函数值可以很好地反映模型与实际数据的差距,其中,基于BERT-DPCNN模型的损失函数收敛速度最快,损失函数的值最小。结合DPCNN模型的优势,分析可知,基于BERT-DPCNN模型的情感分析系统在情感分析领域有着一定的优势。

图6 损失函数值曲线
4 结束语
针对目前情感分析技术在复杂语境中表达能力有限、语义关联性困难、模型分类准确率低等问题,优化改进情感分析模型。通过在BERT语言模型上结合DPCNN神经网络分类器,提高了模型效率和计算效果,使模型具有泛化性。通过比较精确率度、损失函数指标,对该方法的性能进行了评价。模型的准确率达到了92.09%的准确率,损失函数值为0.38,结果表明,改进后的模型可以更好兼容情感分析任务。
