基于亲和矩阵块对角性的子空间聚类
2022-10-17唐科威
唐科威, 林 栋, 张 楠
(辽宁师范大学 数学学院,辽宁 大连 116029)
进入“大数据”时代,各行业的数据量呈现爆炸式增长,如教育、医疗、交通、餐饮、电商等领域每天都有大量数据产生.为了有效地处理这些海量数据,数据的本质几何结构分析一致备受关注,文献[1]指出,一个人在不同光照下的人脸图像位于一个低维子空间中.由于实际问题中的数据往往包含多个类,子空间聚类问题被提出.子空间聚类是指将给定的取自多个子空间并集的数据点划分到各自对应的潜在子空间中.
在过去的20多年内,专家学者们提出了许多子空间聚类的算法[2],例如:迭代方法[3]、因子分解方法[4]、统计方法[5]和基于谱聚类的方法.其中,基于谱聚类的方法在近几年引起了广泛的讨论[6].这类方法首先是要构造一个亲和矩阵来表示数据点之间的相似性,然后利用谱聚类算法作用于亲和矩阵上得到子空间聚类结果.通常使用的谱聚类算法是Normalized Cut(NC)[7].因此,对于亲和矩阵,如果能将同类数据点间的相似性构建的相对大, 不同类数据点间的相似性构建的相对小,往往能获得更加准确的聚类结果.对于两个经典的基于谱聚类的算法,低秩表示Low-Rank Representation (LRR)[8]和稀疏子空间聚类Sparse Subspace Clustering(SSC)[9]都采用了原始数据自表示来提取数据之间的关系,即
X=XZ.
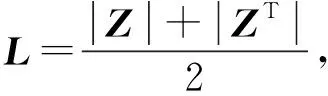
文献[10]详细地分析了上述块对角性质,给出了引入块对角惩罚的方法,同时提出了基于块对角划分的子空间聚类方法Block Diagonal Representation(BDR).BDR通过使用块对角正则项使得表示系数矩阵是块对角的.但是,为了便于求解,块对角正则项的使用有着一定的条件,即需要对施加块对角惩罚的矩阵加以非负与对称的限制.体现在BDR中,就是需要对表示系数矩阵加以非负与对称的限制.基于这类方法的原理和流程,不难发现这种做法会在一定程度上限制表示系数矩阵挖掘数据之间关系的能力,BDR文章中也承认了这一点.具体地说:一部分数据点被某一部分同类数据点线性表示时,表示系数必然是负的,如果限制表示系数矩阵非负将无法挖掘出它们之间的关系.下面用人造数据为例进行说明,在3维空间中,随机生成3条过原点的直线,并在每条直线上,任取了100个点进行试验,这是一个三类问题.发现BDR并不能正确聚类,结果如图1(a)所示.

图1 利用人造数据,分别在BDR和本文的方法进行实验(a)BDR的聚类效果图;(b)本文的方法的聚类效果图;(c) BDR的亲和矩阵图;(d)本文方法的亲和矩阵图Fig.1 The experimental results of our method and BDR on synthetic data(a) The clustering result of BDR;(b) The clustering result of our method;(c) The affinity matrix of BDR;(d) The affinity matrix of our method
BDR不能正确聚类的原因如下:在原点两侧,同一条直线上的数据点在互相线性表示时表示系数必然是负的,而BDR对表示系数矩阵有着非负的限制,这使得BDR无法挖掘出它们之间的关系,这从BDR的亲和矩阵上可以看出,图1(c)中的亲和矩阵有6个对角块而不是3个.其实,从这类方法的流程和原理上可以发现,对表示系数矩阵块对角性的追求无非是为了保证亲和矩阵的块对角性,而亲和矩阵必然是非负和对称的.为了解决BDR中的问题,对亲和矩阵考虑块对角先验提出基于亲和矩阵块对角性的子空间聚类方法.该方法对亲和矩阵进行了块对角惩罚,相对于BDR,这里的方法不仅能避免限制表示系数矩阵的表示能力,而且能同样保证亲和矩阵的块对角性,从而提高聚类性能.图1(b)和图1(d)说明了该方法思路的正确性.但是亲和矩阵与表示系数矩阵具有非线性的运算关系,在目标函数中对亲和矩阵进行惩罚会带来模型求解上的困难.幸运的是,发现使用交替方向迭代法Alternating Direction Method(ADM)可以有效地求解模型.最后,在多个数据集上的大量实验表明了方法的有效性.总之,本文的贡献如下:
(1)提出了基于亲和矩阵块对角性的子空间聚类方法,该方法可以在一定程度上克服BDR方法的局限性.
(2)以往工作都是在目标函数中对表示系数矩阵进行惩罚,而本文则是采用了对亲和矩阵进行惩罚的策略,这是一种全新的尝试.虽然这种做法会带来求解上的一些困难,但是给出了有效的数值算法.
(3)在多个数据集上的实验证实了本文方法是一个有效的子空间聚类方法.
1 相关工作
1.1 符号说明
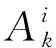
1.2 回顾BDR
表示系数矩阵块对角性对于子空间聚类起着不可或缺的作用,为了便于对下文理解,本文首先回顾BDR子空间聚类中的以下定义.
定义1[10](k块对角矩阵) 对于任意的B∈n×n如果它有k个连通块,那么就称它为k块对角矩阵.
例如:图1(c)中,它有6个连通块,则称它为6块对角矩阵,同理,图1(d)称为3块对角矩阵.
如果B是一个满足B≥0且B=BT的矩阵,则对应的拉普拉斯矩阵LB定义为
LB=diag(B1)-B.
这里LB是一个半正定矩阵.
引理1[10]对于任意矩阵B,如果满足B≥0且B=BT,则拉普拉斯矩阵LB特征值0的重数k等于B中连通块的数量.
那么对于任意的矩阵B∈n×n,如果满足B≥0且B=BT,根据引理1,B是k块对角矩阵当且仅当
其中,λi(LB),i=1,…,n.为LB从大到小的n个特征值.基于这样的性质,可以定义k块对角正则项如下:
定义2(k块对角正则项)[10]对于任意满足非负和对称的矩阵B∈n×n,k块对角正则项定义为LB最小k个特征值的和,即
当矩阵B是k块对角的,则‖B‖k=0.相反,如果‖B‖k=0,矩阵B至少有k个连通块.因此,‖B‖k可以看作是块对角矩阵结构诱导的正则项.所以BDR子空间聚类的模型:
(1)
其中,X∈d×n是从k个子空间的并集中提取的数据矩阵,X的每一列代表一个数据点.B∈n×n是表示系数矩阵,γ是平衡不同项的参数.为了诱导块对角结构,模型(1)不得不对表示系数矩阵B加了非负且对称的限制条件,这会限制表示系数矩阵挖掘数据之间关系的能力.BDR文章中也说明了该局限性.
2 模型求解
2.1 本文模型
对表示系数矩阵诱导块对角结构本质上是为了对亲和矩阵诱导块对角结构,而亲和矩阵必然是对称和非负的.为了克服BDR的局限性.这里做出一次大胆的尝试,选择对亲和矩阵使用k块对角正则项.
(2)
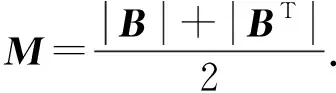
2.2 数值算法
使用ADM方法求解模型,为此,引入辅助变量Z则有:
则模型(2)的增广拉格朗日函数为
(3)
下面利用BDR中的引理处理‖M‖k.
引理2(1)http:∥meboo.convexoptimization.com/Meboo.html如果L∈n×n并且L0那么
根据式(3),最终模型的求解可以归结为3个子问题的讨论:
对于变量B:
通过推导得出
〈LM,W〉=tr((diag(M1)-M)W)=tr(MT(diag(W)1T-W)).
(4)

(5)
注意模型(5)无法直接使用软阈值算子,因为矩阵V中的元素可能是负的,通过推导得到该问题更新方案为
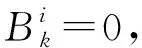

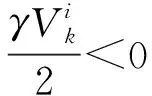
其中,i,k=1,…,n.
(6)
对于变量W:
利用式(4),将求解W的问题转化为求解下式

利用BDR中对W的处理方式,知道该子问题有解W=QQT,其中,Q是diag(M1)-M的k个最小的特征值的特征向量.
对于变量Z:
解为
Z=(XTX+μI)-1(XTX+μB-Y).
(7)
最后,文章的算法总结如下:

算法 1 利用ADM算法求解模型(2)输入:数据矩阵X和参数γ,k.输出:表示系数矩阵B.初始化:B=Z=0,W=0,Y=0,μ=10-6,tol=10-4.步骤1:固定其他参数按照式(7)更新Z.步骤2:固定其他参数更新B, 当i=k时,则Bik=0,如果i≠k,则按照式(6)更新Bik.步骤3:固定其他参数更新W,即W=QQT,这里Q是diag(M1)-M的k个最小的特征值的特征向量,其中,M=B+BT2.步骤4:更新乘子Y=Y+μ(Z-B).步骤5:更新μ=min(1.1μ,1030).步骤6:检验收敛条件:‖Z-B‖∞ 在本节中,在人造数据、COIL-100(2)http://www1.cs.columbia.edu/CAVE/software/softlib/coil-100.php、USC SIPI 纹理库、MNIST数据库[11]上进行了几组实验来证明方法(记为OUR)的有效性.并与SCC[12]、SSC[9]、LRR[8]、LSR[13]、BDR-B和BDR-Z[8]方法进行比较.在以上3个数据库中,分别针对不同的聚类方法调整参数,为每种方法在其3个数据库中找到最优的参数.为了降低数据的维度,采取预处理的方式对数据进行有效的降维. 为了直观的对比本文方法的优越性,在3维空间中,随机生成3条过原点的直线,并在每条直线上,任取了100个点进行实验.实验结果如图1,发现由于BDR对表示系数矩阵加了非负和对称的惩罚,所以在原点两侧它并不能得出正确的聚类结果,如图1(a).并且通过观察亲和矩阵的图1(c)也可以看出,它的分类数是6而不是3,显然错误.而本文的方法是利用亲和矩阵的非负和对称性,通过图1(b)和图1(d)可以看出本文的方法能得到正确的聚类. 该数据集包含了100个不同物体的7 200张灰度图像, 其中,每个物体包含72幅图像.每幅图像的大小是128×128.从中选取10类图形,每类取50张进行实验.正确率见表1. 表1 每种方法在 COIL-100上的正确率Table 1 The accuracy for each method on coil-100 % 本文的方法对于 USC SIPI 纹理库的实验也可以得到比较好的结果.USC-SIPI 纹理库包含13种纹理,每种纹理又包含7种不同角度状态.实验中随机选取了5类纹理,每类纹理全部图像在所有角度下的数据,所以共有560幅图像.正确率见表2. 表2 每种方法在USC SIPI纹理库上的正确率Table 2 The accuracy for each method on USC SIPI % 旋转的MNIST数据库包含大小为28×28像素的手写数字的灰度图像.图像最初取自文献[14]中引入的MNIST数据集,并通过几种方式进行了转换,以产生更具挑战性的分类问题.本文选取后三类作为实验对象,每类200张. 表3 每种方法在MNIST数据库上的正确率Table 3 The accuracy for each method on MNIST % 本文提出了基于亲和矩阵块对角性的子空间聚类方法,在原有BDR子空间聚类模型的基础上做了改进,本文的方法不需要限制表示系数矩阵非负或者对称.同时本文的方法直接对亲和矩阵进行块对角惩罚,这也是一种全新的尝试,具有重要意义.最后,各种基准数据库上的大量实验结果表明了本文算法的有效性.3 实 验
3.1 人造数据
3.2 COIL-100

3.3 USC SIPI 纹理库

3.4 MNIST数据库

4 结 论
