数据点位置低延时智能挖掘方法与仿真
2022-09-28唐雯炜李志敏
唐雯炜,李志敏
(浙江中医药大学信息技术中心,浙江 杭州 310053)
1 引言
信息化进程脚步的加快,使得数据库技术也取得突飞猛进的发展,同时信息系统的存储压力和计算压力也随之增加。面对数据库中的海量数据,从中获取部分有价值的信息难度较大,且当前的信息提取方法步骤较为繁琐。因此,如何在数量巨大的数据中快速找到数据点所在的位置、挖掘其隐含的信息已经成为了日后重点研究方向。
针对数据点位置的挖掘问题,相关领域研究学家们也对此展开了深入研究。文献[1]利用人工智能裁决机制对网络的挖掘宽度、网络环境以及节点存储大小等多方面因素进行综合考虑,确定这些因素对挖掘效果产生的影响程度,以此获得数据挖掘的难易程度。然后,通过所得结果采取强化措施来提高算法的挖掘效率,但是挖掘精度有待提高;文献[2]利用智能网络系统对低匹配度的数据进行了研究。首先,对数据进行预处理,使其转换为便于挖掘的规约形式,在一定程度上确保算法具有更高的挖掘效率;然后,对算法的挖掘规则利用神经网络模型进行更新,同时剔除掉其中包含的冗余连接节点;最后,通过I/O输出完成挖掘的数据。该方法对低匹配度的数据具有较为理想的效果,但并不适合处理高维或多模态数据。
为解决以上传统方法的缺陷,提出基于并行FP-Growth算法的数据点位置智能挖掘算法。结合并行FP-Growth算法与MAP/Reduce并行编程模型,形成新的FPPM算法。该算法通过计算与之对应的局部频繁项目集,整合在一起得到全局频繁项目集,并计算每个项目集属性,利用增量分类的方法找出最佳属性,同时统计每个属性出现的次数,利用构建的决策分支树实现对数据点位置地准确挖掘。在仿真中,本文方法较传统方法相比在CPU占用率、挖掘时延、信息熵方面均取得了理想的结果,并且具有理想的可扩展性。
2 FPPM算法优化建立
2.1 并行FP-Growth算法
利用并行FP-Growth算法实现数据挖掘主要是通过频繁模式增长的方式来实现的。首先,算法扫描待识别的事务数据集D,得到一个紧凑且包含事务集中所有频繁模式信息的频繁模式树[3],完成数据点的位置挖掘。
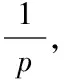
频繁模式树的建立过程主要通过以下四个步骤完成:
1)对处理器的每个处理过程都分配与之个数相等的事务集;
2)每个处理过程计算局部频繁项集的计数;
3)将所有局部频繁项集的计数[6]整合在一起,得到全局频繁1-项集;
4)根据全局频繁1-项集对所有处理过程进行扫描,并将全局频繁1-项集中的节点与局部频繁项集中的节点连接在一起,形成频繁模式树。
全局频繁1-项集与局部频繁模式树在连接的过程中,形成了一种连接网络,这个网络就是FP-tree,同时也是实现数据点位置挖掘的有力保障。
2.2 FP-tree建立
FP-tree中,通常以“null”作为树的根节点。随机选取一个节点a,在从根节点延伸出的路径中,将不包含a所在的部分路径称之为a的前缀路径,a则是该条路径的后缀项。前缀路径不断延伸,始终都有a的存在,当这些路径在某个节点相交时,即可得到a的条件模式基。由条件模式基可以构建条件模式树[7],在条件模式树下再进行数据点位置的挖掘,可以快速得到频繁模式下的数据。
将事务数据集定义为D、最小支持度设置为2,通过表1的事务集建立如图1所示的FP-tree。
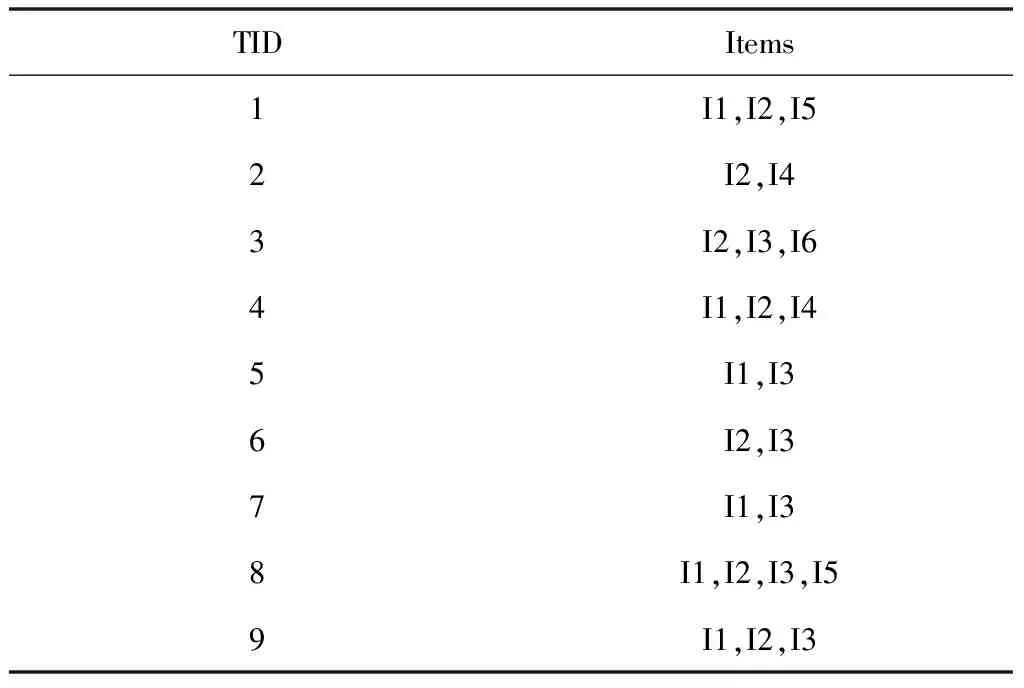
表1 事务数据集D
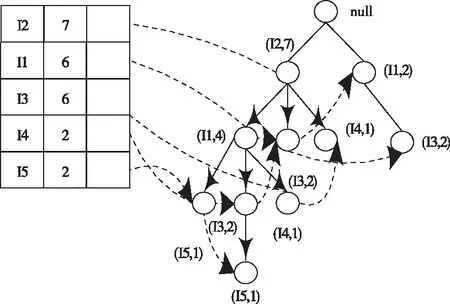
图1 构建的FP-tree
2.3 Map/Reduce并行编程模型
Map/Reduce在处理数量巨大的挖掘工作时,会分配给每一个主节点以及其下一层的各个分节点来共同完成工作,最后将各个分节点的数据整合在一起,即为最终的挖掘结果。换句话说,Map/Reduce的主要工作是分配任务与汇总结果。将分配任务与汇总结果用函数表示为:Map和Reduce。这两个函数的主要任务就是处理输入键值对。
在Map函数中,数据的格式发生改变,以分片的形式存在,而Mapper存在于每一个分片上。首先,在Map函数中输入键值对为
在Reducer这个阶段中,Reducer将从不同Mapper传送来的元组整合在一起,利用reducer函数处理
2.4 FPPM算法框架
将并行FP-Growth算法与Map/Reduce并行编程模型整合在一起,得到FPPM算法。
FPPM算法实现过程为:
1)对D中1-项集的支持数进行具体数值的计算:初始化一个统计频繁项目集的Map/Reduce job,将输出结果存储在分布式缓存模块中;

3)筛选候选全局频繁项目集,并对其进行统计运算:重新初始化一个Map/Reduce job,将步骤2)中存储在分布式文件内的元组进行支持度的计算,最终得到最小支持度下的频繁项目集,在全局频繁项集中进行汇总。
步骤2)和步骤3)所得计算结果即为数据点位置的全局频繁项目集。
3 数据点位置智能挖掘
3.1 选取候选属性子集
将t定义为时间。随机选定一个时刻t,将D中的全部数据传输至reducer函数中,传输过程如式(1)所示
Dt=[Xt,Yt]
(1)
式中,X、Y分别表示数据集中数据的属性[10]。设定一段时长为T的时间段,选取其中某个时刻并将其标记为t=1,2,…,T,将这个时间段以内的数据标记为DT,算法如下

(2)
用H(.)来表示并行FP-Growth算法的功能,通过运用贪婪算法实现最优FP-tree的构建。算法中,H(.)的主要作用为计算数据点位置的信息增量[11],并且按照由高到低的顺序对每个分支点的边界输入相应的标签信息,然后选取分类的最佳属性Xi。对于所选取的最佳属性Xi,检索i(i≤M)和j(j≤N),其中,M表示属性个数的最大值,N表示接收实例个数的最大值,也可以看作是xij的分支值。因此,从xi1到xij的分支值中选取满足xij=arg maxH(xij)条件的功能属性Xi。
为确保输入结果是全局最优解[12],在以上计算过程中,就要使所有数据点的位置都在DT中,计算公式如式(3)所示

(3)
在任意时刻t下,将Xt定义为将要筛选的全部新数据集,在集合{Ytk}中整合数据点位置信息。{Ytk}中,k为在可能集合K中的任意一个可能集合序列号。
根据当前所筛选的频繁项目集,本文将FPPM算法按照最优分类的原则计算,计算过程如式(4)所示
(4)
在时间t内,数据点位置信息已经全部汇总在DT内,并在全局频繁项目集中以良好的形式在集合TRGLOBAL中展现出来。在时间t+1内,数据点位置信息更新到新的集合TRGLOBAL内,通过式(3)和式(4)实现自我更新,更新时间随着t和DT的上升而不断延长。每更新一次,所有数据点位置信息都要重新载入DT的历史数据。
3.2 数据点位置挖掘计算
在利用FPPM算法对数据点位置挖掘时,所采集到的数据量是非常巨大的,并且伴随着新数据点位置信息的产生处理起来也是非常繁琐的。因此,在处理此类数据时,本文利用增量分类的方法确保算法具有理想的挖掘效果。
增量分类的方法就是在所有候选属性数据集中,找出可靠度最佳的数据集,将这些最佳数据集整合在一起,即可得到最佳候选属性集。在利用增量分类方法提取数据点位置的过程中,只需要操作一次,无需重复操作,因此该方法也被称为任意算法。通过统计每个属性值出现的次数,来构建决策分支树。在计算过程中,Xi出现的频率、与Xi的类Yk都通过(5)Hoffding计算得到
(5)
式中,R用来约束分类属性,n表示同一数据集合中的个数,δ表示约束系数。在该算法中,通过两组高值集合项推荐得到。对于任意时刻t下,Xi具有两个最大集合值项检测Xi,检测结果分别为xin和xib,这两个值均满足条件xin=arg maxH(xij)和xib=arg maxH(xij)。通过上述的计算过程,即可完成对数据点位置的挖掘。
4 仿真研究
为验证本文提出的基于并行FP-Growth算法的数据点位置智能挖掘算法的有效性,与文献[1]提出的基于人工智能裁决机制的数据点位置挖掘方法、文献[2]提出的基于智能网络系统的数据点位置挖掘方法进行了对比仿真。仿真中所用到的数据均来自于IBM DataGen,其中包含了多达1000个种类的数据类型,所有数据的记录长度均保持在10。
4.1 CPU占用率测试
为了验证三种方法在挖掘数据点位置过程中的CPU占用率,在上述实验环境中,依照实验设定的参数,展开对比仿真,仿真结果如图2所示。
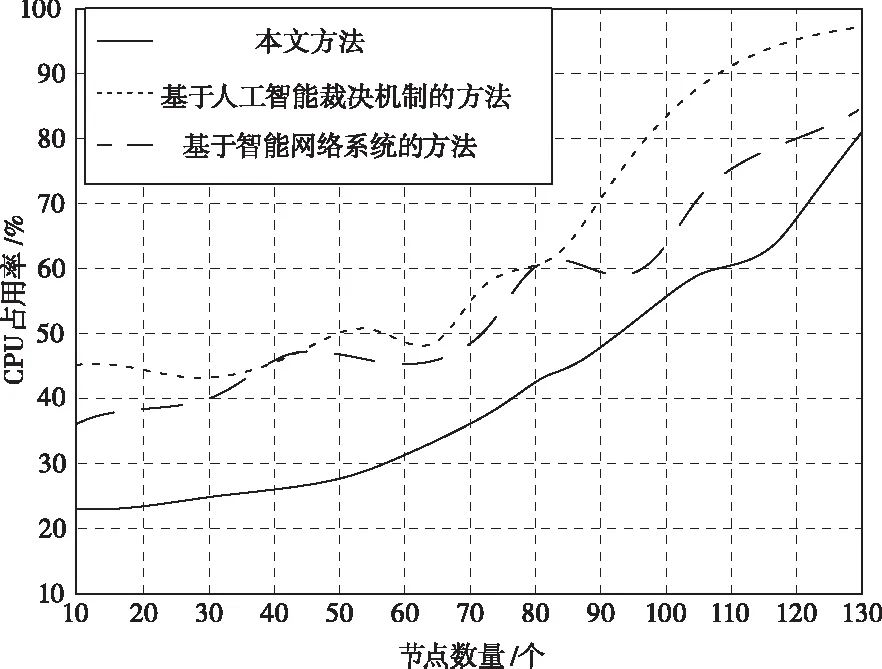
图2 三种方法CPU占用率对比
从图2中可以看出,不论节点数量怎样变化,本文方法较其它两种方法相比,均展现出了明显的优势,一直保持在较低的水平下,并且波动幅度也较其它两种方法相比要小。这是由于本文方法引入了增量分类方法,快速处理各类数据巨大且复杂的数据,实现高效挖掘,同时,使算法整体保持在平稳的状态下,避免出现较大的波动。
4.2 挖掘时延测试
随着节点数量的不断增加,挖掘时延也发生了改变。本文方法与其它两种方法相比,在挖掘时延方面的测试结果如图3所示。
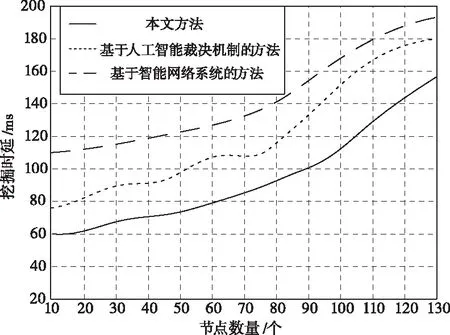
图3 三种方法挖掘时延对比
从图3中可以看出,虽然节点数量在不断的增加,但是本文方法的挖掘时延一直比其它两种方法要低,并且波动的幅度也较其它两种方法相比要缓一些。这是由于本文方法在挖掘数据点位置的过程中,将挖掘的带宽、数据集的存储大小以及多种因素综合考虑在内,在节点数量不断增加的同时进行快速的运算,有效降低挖掘时延。
4.3 数据点位置信息熵
随着挖掘得出节点位置数量不断增加,为了验证其位置结果是否存在有效信息和数据,通过信息熵指标判断。信息熵能够描述挖掘结果内信息量的大小,设定大于0.5的位置信息为挖掘有效数据。图4为分别运用三种方法挖掘信息熵结果对比图。
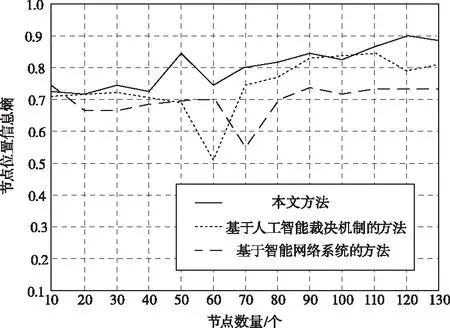
图4 挖掘信息熵对比
从图4中可以看出,三种方法挖掘结果均大于0.5,都符合要求,但是相对于文献方法来说,本文方法的位置信息熵值更高、曲线更加平稳,没有出现较大的波动。这是由于本文方法充分考虑到了数据点的属性信息,只需要在计算过程中输入与之对应的标签信息即可,减少了计算步骤,因此可有效降低挖掘出现异常情况的概率。
4.4 可扩展性测试
可扩展性指的是当节点数量按照一定的比例增加时,计算此时的算法性能。可扩展性scaleup的计算公式如式(6)所示
scaleup(D,m)=t1*D/tm*m*D
(6)
式中,t1*DB表示1个节点在D中所花费的计算时间;tm*m*D表示当节点数量为m时,在规模大小为m*D的项目集上运行所花费的时间。
在评判过程中,当scaleup的值在0.65以上,说明该算法具有优秀的可扩展性。图5为本文方法在支持度大小分别为5%、10%、15%的情况下,所得的可扩展性结果。
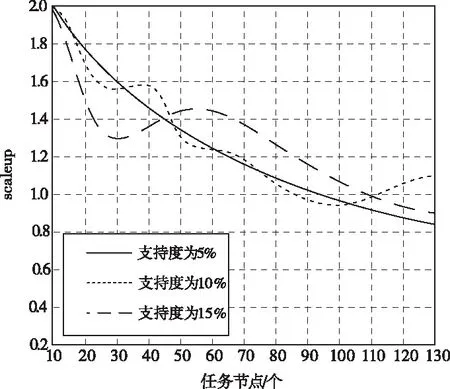
图5 支持度不同的情况下本文方法可扩展性
从图5中可以看出,本文方法在支持度不同的情况下,所得scaleup的计算结果均在0.65以上,说明本文方法具有优秀的可扩展性。
5 结论
本文通过并行FP-Growth算法与Map/Reduce并行编程模型的结合,使得FP-tree在挖掘迭代的过程中具有更为理想的效率。通过设置仿真,在CPU占用率、挖掘时延、信息熵方面与传统方法展开对比,验证了本文方法在挖掘时延较少的前提下实现了对数据点位置的高效率挖掘。最后在支持度不同的情况下对本文方法的可扩展性完成了实验验证,结果表明本文方法具有优秀的可扩展性。
