基于密度划分的云数据分块存储方法仿真
2022-09-28潘文标元文浩
潘文标,元文浩
(温州医科大学信息技术中心,浙江 温州 325035)
1 引言
互联网技术与移动互联网业务迅速普及,使得在日常应用过程中产生了大量数据[1],给后续的数据存储、分析等均带来了极大的难度,因此,谢鹏等研究人员[2]在数据存储的探究课题中,结合HBase分布式存储系统,创建空间矢量数据存储模型,期望打破存储技术的探索瓶颈。
进入云计算时代后,云存储技术[3]迅猛发展,云端服务器应运而生,作为新型的存储方式,该存储形式在大数据时代得以广泛应用,不仅让用户体验到了极佳的数据存储服务,也为大规模数据存储减轻了不小的压力。随着云端服务器越来越普及,应用频率越来越高,其爆炸式的增长趋势使云数据的存储问题受到高度关注,相关存储方法应运出现,比如,刘福鑫设计的Kubernetes云原生海量数据存储系统[4],取得了较好的研究成果。
我国云数据存储技术的研究刚刚起步,仍存在很大的优化空间。本文基于密度划分算法,设计一种分块存储方法,缓解存储压力。根据细粒度云数据的密度不均匀属性,设计出低敏感度的密度划分算法,获取高集中性的数据类别,去除无效的冗余数据,缩减存储空间;根据密度分割点建立阶跃函数,避免密度阈值过高导致聚类不精确;基于伽罗华域完成云数据分块编码与解码的全部运算,利用范德蒙矩阵编码、解码,简化编解码复杂性,降低运算难度与复杂度,加快运算速度。
2 基于密度划分算法的细粒度云数据聚类
针对细粒度云数据,按照下列密度划分算法流程,聚类所有云数据:
1)输入细粒度云数据集合P,构建距离矩阵D;
2)明确自然特征值λ,以距离矩阵DN*N为依据,以r为搜索范围,遍历各云数据的近邻与逆近邻[5]数据,待反向邻域数据个数稳定时停止,获得的矩阵nb为全部云数据的逆近邻数量,此时有r=λ;
3)利用云数据及其近邻数据,建立局部邻域集LN;
4)通过式(1)求解云数据p的局部密度
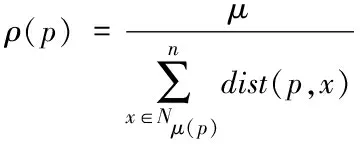
(1)
式中,Nμ(p)指代数据p的μ近邻数据集;dist(p,x)指代云数据p及其第μ个近邻数据x之间的欧几里得距离[6]。其中,μ=max{nb};
5)按局部密度值,降序排列云数据,密度值最大的云数据就是局部邻域集LN的局部核,划分剩下云数据至局部核的所属类别中;
6)取得比平均密度低的最大二阶导数,将该最大值对应的云数据密度作为密度阈值ρt,去除每个类别内比该阈值小的数据;
7)利用各云数据及其λ近邻点,建立全局邻域图;
8)假设类别Ci与Cj间的跨类别边缘数据是vi、vj,两数据间的边权重值为w(vi,vj),(vi,vj)表示数据vi、vj的偏导数,CE(Ci,Cj)表示两类别的联合密度,则采用下列计算公式求解类别Ci、Cj之间的关联度

(2)
若跨类别边缘数据是vi、vj的欧几里得距离是dist(vi,vj),则云数据边权重值w(vi,vj)的计算公式如下所示

(3)
通过下列公式计算类别Ci与Cj间的紧密度

(4)
求解类别间关联度与紧密度的乘积,即得到类别Ci与Cj的相似度,数学表达式如下所示
sim(Ci,Cj)=connect(Ci,Cj)*close(Ci,Cj)2
(5)
9)根据距离阈值η,判定跨类别数据的同类性与异类性,获取数量比例;
10)降序排列类别相似度,以类别相似度与跨类别数据的类别属性为依据,聚类所有云数据。当跨类别数据的同类数多于异类数时,符合聚类条件,将两类别整合在一起[7];获取新的相似度与聚类条件,待不符合聚类条件时,终止聚类操作,将未完成聚类的类别云数据整合成一类[8];
11)划分密度阈值较低的云数据至其局部核的所属类别。至此,实现所有云数据聚类。
密度划分算法的两个重要参数为聚合条件的判定矩阵ψ与距离阈值η[9,10]。假设集合P中含有M个云数据,其中,数据i及其第k个近邻点的间距是dik,则距离阈值η的计算公式如下所示

(6)
若类别Ci、Cj的跨类别数据共有ni,j对,则将下列表达式界定为聚合条件的判定矩阵ψ

(7)

(8)
针对比平均密度小的密度曲线,取得离散的最大二阶导数,获得聚合条件判定矩阵ψ与距离阈值η的最优值。
3 基于里所码的细粒度云数据分块存储
将完成聚类的细粒度云数据划分为规格相同的数据块,任意类别中的数据块集合为B={b0,b1,…,bm-1},各数据块经里所码分块后,得到K个规格相同的云数据分块集F={f0,f1,…,fK-1},其中,m-1与K-1各指代里所码分块前后的云数据块数量。为简化编码复杂性,利用范德蒙矩阵A编码,获得校验块集G={g0,g1,…,gM-K-1},该集合中含有M-K个校验块。编码处理通过下列矩阵方程实现

(9)
式中,范德蒙矩阵A的界定式如下所示

(10)
经范德蒙矩阵编码处理,储存编码后的细粒度云数据。为避免主节点产生大量冗余云数据,选取的节点只存储一个云数据块,根据两者间的相关性,获取分块存储的元数据。每完成一个节点的云数据块存储,元数据都将直接更新至各节点。综上所述,设计出下列细粒度云数据分块存储算法流程:
1)假设待输入的细粒度云数据是data,其文件名是src,通过用户端把云数据data输入流中;
2)数据分块,得到B={b0,b1,…,bm-1};
3)在主节点选取的节点上存储云数据块;
4)利用范德蒙矩阵进行编码,二次分块细粒度云数据;
5)在所选节点上储存编码后的云数据;
6)基于各云数据块,获取新的元数据。迭代循环整个流程,直到没有新的元数据生成,此时,即可实现所有云数据的分块存储。
迭代分块存储过程中,需要调度节点来执行云数据块的处理任务,这就涉及到一个重要的步骤,即细粒度云数据的解码处理。
假设待处理云数据块为bα,任务执行的节点为nodeα,搜寻所有储存数据块bα的节点,形成列表listα,针对其前φ个有效节点,取得云数据块及其元数据,将范德蒙矩阵A与有效节点上储存的云数据块集F″={f″0,f″1,…,f″K-1,f″K}相结合,得到矩阵L及其逆矩阵L-1,建立L-1与新分块集F′={f′0,f′1,…,f′K-1,f′K}的乘积形式,即完成云数据块解码处理。该解码处理通过下列矩阵方程实现

(11)
式中,逆矩阵L-1的界定公式如下所示

(12)
综上所述,构建出下列细粒度云数据块的解码操作流程:
1)假设云数据的路由信息与缓冲大小各是path与size;
2)创建系统文件,根据文件名搜索元数据;
3)基于存储待处理云数据块的节点列表,完成解码处理;
4)更新云数据块,利用用户端取得经过解码处理的云数据块;
5)迭代循环上列步骤,直到分块存储完所有云数据。
本文基于伽罗华域完成云数据分块编码与解码的全部运算,且在不改变范德蒙矩阵形式的前提下,执行编码与解码处理,二者均能够在一定程度上降低运算难度与复杂度,加快运算速度。
4 细粒度云数据分块存储仿真研究
为增加实验可靠性,设定仿真环节为三个阶段:明确里所码编码比例的最优参数;分析密度划分算法的可用性;探究分块存储方法的完整性、压缩性。
4.1 基于分块存储的里所码编码比例设置
令里所码编码比例按等差数列取值,分析不同编码比例下分块存储细粒度云数据时的开销与带宽,根据实验结果,择优设置里所码编码比例参数。

图1 编码比例参数相关性
从不同编码比例参数值下分块存储的开销与带宽情况可知(见图1),当里所码编码比例参数取值为0.5时,存储开销最小,且随着运行时间的增加呈持续大幅下降趋势;同时带宽一直保持最高数值,且随着运行时间的增加呈平缓上升趋势。因此,设定里所码编码比例参数为0.5,能够以最佳状态展开方法验证试验,减小该参数对存储效果的影响。
4.2 密度划分算法可用性分析
选取细粒度云数据量不同的三个集合,分别采用正相关的纯度、互相关信息熵、F1综合指标,评估密度划分算法的聚类效果。各评估指标的取值范围均为0到1,计算方式如下所示

(13)

(14)
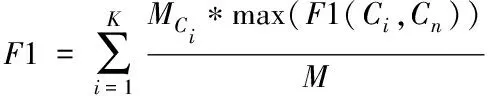
(15)
其中,Cn为类别n的真实聚类;θ(Cn,Ci)指代聚类结果是Ci,但实际类别是Cn的几率,θ(Cn)与θ(Ci)各指代真实聚类为Cn的几率与聚类结果是Ci的几率,MCn与MCi各指代两类别数量;F1(Ci,Cn)指代两类别的F1综合指标值,计算公式如下
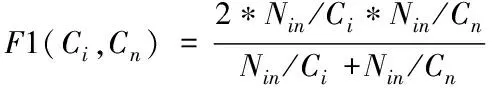
(16)
根据图2所示的各集合评价指标结果可以看出,对于不同大小数据量的实验样本,密度划分算法始终具有较好的聚类效果,即便面对海量细粒度云数据,该算法通过深入探讨判定矩阵与距离阈值两个关键参数,凭借近邻与逆近邻数据构成的局部邻域集与全局邻域图优势,精准完成聚类,具备良好的可用性,对分块存储的干扰几乎可以忽略不计。
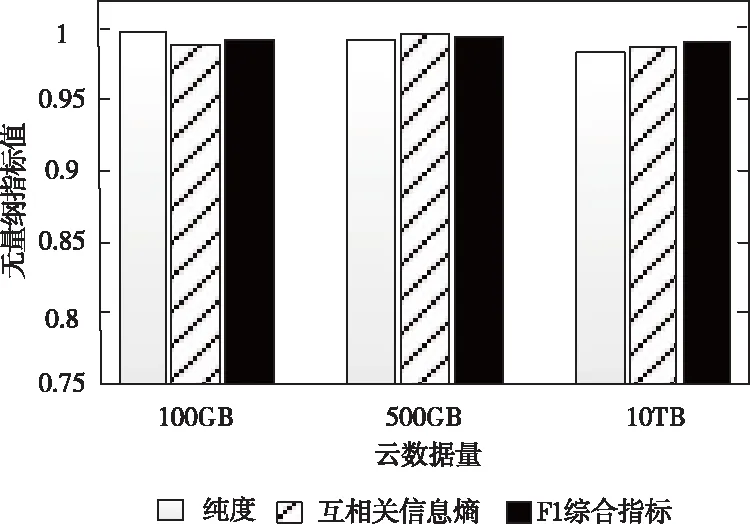
图2 不同数据量的聚类效果示意图
4.3 细粒度云数据分块存储效果分析
利用本文方法分块存储某细粒度云数据集,将得到的实验结果分别与HBase模型及Kubernetes系统的存储效果作比较,验证本文方法的优越性与实践性。
4.3.1 分块存储完整性
以500GB的云数据量集为检验对象,设定主节点所选节点的存储量为50个数据块,待完成所有云数据块存储后,根据各节点上存储的数据块数量,分析不同方法在存储数据过程中发生的数据丢失情况。任意选取其中十个节点,其数据块存储结果如图3所示。
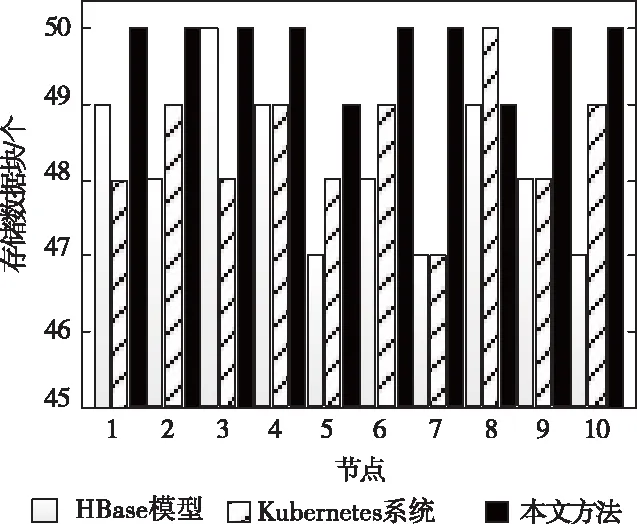
图3 数据块存储数量示意图
由十个节点的数据块存储量可以看出,本文方法结合密度划分算法与里所码技术,大幅提升细粒度云数据块的聚类与划分精度,确保各云数据都得到分类处理,尽可能不遗漏数据块,因此,仅有节点5、8各丢失一个数据块,相较于文献方法的多次、多块丢失情况,具有更理想的存储完整性。
4.3.2 分块存储压缩性
就分块存储压缩性能,利用输入、输出数据的大小比值(即压缩因子指标)客观评估,该指标值与压缩效果呈正相关性。三种存储方法的压缩因子指标数值如表1所示。

表1 不同存储方法的压缩因子数值
根据表1中的压缩因子参数值可以看出,本文方法的压缩因子值几乎是文献方法的二倍,压缩优势显著,实现了分块存储目标。这是因为该方法根据类别相似度,准确聚类所有云数据,为数据分块奠定基础,利用多个适配度较高的节点,分块存储云数据,极大程度减缓存储压力,令压缩性能得到更好发挥。
5 结论
大数据与云时代的来临,在为用户提供便利的同时,导致云数据规模暴增,这一发展趋势对存储技术提出了巨大挑战,其中,以细粒度数据的存储难度最大。为此,针对细粒度云数据,提出分块存储方法,通过实验证明,方法取得较好效果。所以,在接下来研究中,为拓展方法应用领域,进一步提升存储效果,将以下几点作为重点研究方向:数据类型多种多样,应就多元化的数据种类,不断检验本文方法的存储效果;针对编码语义的可扩展性,验证复杂情况下能否实现数据的统一编码;需利用经典的加密算法,提升分析存储安全性;改进密度划分算法的离线处理局限性,令其对实时的数据流也具备较好的处理能力;应在真实场景中开展实验活动,令方法更契合实际应用。
