基于SVM算法的藏文微博情感分析研究
2022-09-28朱亚军
朱亚军,次 曲,拥 措
(西藏大学信息科学技术学院,西藏拉萨850000)
1 引言
微博作为一种轻量级的自媒体平台,自由灵活。它是一种基于用户关系,进行信息分享、传播以及获取的,通过关注机制分享简短实时信息的社交媒体、网络平台。人们每天通过微博了解世界上每个角落发生的事情,还可以通过微博分享自己的经历和感受,在浏览微博的时候,可以发表自己的评论,所以微博包含非常丰富的表达情感的内容。对微博进行情感分析能够发现博主对社会事件、时事热点的态度,从中挖掘商业价值,也可以帮助政府机关分析事件的社会影响。目前对中文微博的情感分类已经相对成熟,但是因为语法的差别,在对藏文微博进行情感分类时,直接迁移中文微博情感分类的方法,效果较差,所以需要针对藏文微博进行专门的研究。
对藏文文本情感分类已经有不少相关的研究。首先西藏大学拥措[1]教授对短文本情感分析的研究现状进行了比较全面的总结和综述。M. Srividya[2],Wan-qiu Cui[3]分别使用了复合分类器和基于语义的哈希图对短文本进行了分类。H. M. Keerthi Kumar[4],曹鲁慧[5]通过优化短文本的特征选择方法提高了短文本的分类效果。范国风[6]基于语义依存关系通过图网络对文本进行了分类。余本功[7]基于改进SVM对网络上的短文本分类,取得不错的效果。杨朝强[8],施瑞朗[9]通过新的大量数据对原有的分类模型进行了验证。西北民族大学李海刚[2],采用了信息增益的特征选择方法,提高了特征对类别的代表性。Xiao Sun[11],HüseyinFidan[12]对小说文本的情感进行了分析,有效地抽取了文本中表达情感的句子。张俊[13],杨志[14],孙本旺[2]均基于藏文微博情感词典对藏文微博情感分类进行了研究,其中孙本旺提出的基于SSTSD情感词典的方法具有较优的分类效果,但是情感词典的构造具有一定的困难,通常需要手工建立基础的情感词典,因此具有较大的建设成本和规模限制。江涛[16]在其多特征藏文微博情感分析的研究中,考虑了汉语,表情符号等,取得了较好的成果,但是对纯藏文微博情感极性的识别仍有待改进。袁斌[17]的基于语义空间的藏文微博情感分析方法提出的语义空间+TF-IDF方法在特征空间的基础上提供了语义的内容,通过语义进行聚类发现类别,形成特征空间,较大程度地挖掘了单条微博的信息量,所以分类效果较好。
本文针对从新浪微博上收集的藏文微博进行实验,数据具有一般性和代表性,能够有效地评价情感分析结果。引入核函数和容差值的SVM算法对小样本数据的分类效果较好,因此使用SVM算法对藏文微博进行情感分析。SVM算法将分析微博文本所蕴含的情感,将微博划分为积极、客观和消极三类,细化了情感分析的类别。
2 SVM分类算法
SVM主要是通过对训练数据的学习,找到类别边缘上的点,这些点被称作“支持向量”,通过这些支持向量找到一个超平面,这个超平面可以较好地将样本数据空间分离,并最大化类别边缘上的点(支持向量)到超平面的距离,从而获得最优的分类效果。
超平面(w,b)关于T中所有样本点的几何间隔最小值(也即是离得最近的点的距离)为
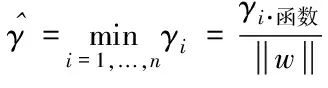
(1)
在尽可能地保证分类正确又使得类别之间的距离足够大的情况下,可得

(2)
训练过程就是最优化超平面的过程,并将最优化超平面问题转化为凸优化问题。引入拉格朗日乘子αi> 0,i=1,2,…,n,定义拉格朗日函数
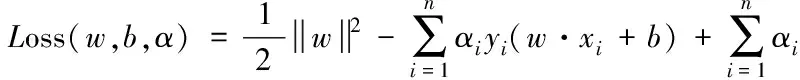
(3)
对上式中的w和b分别求一阶偏导,并令它们等于0,即可求得w和b,并最终获得最优分类超平面。
看上去支持向量机的超平面原理只能使用于二分类问题,但是经过改进的支持向量机分类算法同样可用于多分类问题,而且在小样本数据集上支持向量机拥有更加优秀的文本分类能力。
3 实验数据
目前没有公开的藏文微博语料本文使用的语料是人工从微博上收集的,选择微博长度在10词到100词之间的,包含较少或不包含非藏文字符的微博,共计17000余条微博。数据预处理使用厦门大学在线分词系统进行分词,并对微博进行实义词语的抽取。人工进行微博情感的标注,标注分为三类。标注规则和标注示例如表1和表2。

表1 标注规则

表2 标注示例
数据集被分为3部分,其中包括: 60%用于训练,得到算法相应的分类模型;20%用于验证,验证模型的正确性;20%用于测试,测试模型在微博情感分类中的实际效果。
4 特征选择
对文本分类来说,特征就是文本中表达了文本类别属性的词语,因此特征的选择较大程度上决定了文本分类效果的好坏。随着机器学习算法的深入研究,提出了很多特征提取方法,其中包括TF(Term Frequency),IDF(Inverse Document Frequency),TF-IDF等。这些特征选择方法使得选择的特征尽可能多地包含文本信息。
TF(Term Frequency):即词频,也叫绝对词频。指的是一个词语在文本中出现的频率。
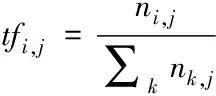
(4)
其中分子ni,j指的是该词在文本中出现的次数,而分母∑knk,j指的是文本中所有字词出现的次数总和。
TF无法避免停用词带来的影响,比如:“我”、“的”、“但是”等。与情感词相比,这些词在各类情感文本中的使用频率都比较高,但是对微博文本情感的分类贡献不大。
IDF(Inverse Document Frequency):逆文本频率。逆文本频率的计算为:文本总数除以包含词条的文本数再取对数。
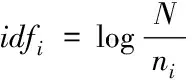
(5)
其中分子N表示总文本数,ni表示包含词语i的文本数。
IDF降低了各类文本中都会出现的常用词的影响,使得那些在各类情感文本中均会使用的常用词的权重减小,而提高了在某一情感分类文本中出现频率较高的词的权重。
TF-IDF:指词频和逆文本频率的乘积:
tf-idf=tfi,j·idfi
(6)
通常情况下,在文本中会大量存在这样的词,不管文本的主题是什么,总会用到这些词,比如:“我”、“我们”、“的”、“个”。这些词和文本的情感表达关系不是很密切,对于文本的情感分类没有帮助,并且这些频繁出现的词,还会掩盖那些词频很低但是却有力地表达了作者的想法和态度的词或短语,比如网络流行词。
如果一个词或短语在一篇或一类文章中出现的频率很高(TF较大),并且在其他类别的文章中出现的频率又较低(IDF较大),则认为这个词或短语具有很好的类别区分能力,而其在文本分类中做出的贡献也越大,使得文本的类别识别率较高。TF-IDF的优点是能够很好地避免各类文本中都会出现的常用词带来的影响。
5 实验结果
本文主要针对SVM分类算法进行实验分析。考察实验结果的三个指标:准确率P(Precision)、召回率R(Recall)和F1(F1_Score)。
通常情况下,精确率和召回率是相互矛盾的,精确率较高时,相应地,召回率就较低,所以引入F1作为参考,在精确率较高,而F1值也相对较高时,训练出来的模型在分类的时候才具有比较优秀的表现。
由通过实验找到SVM算法最优的惩罚系数C和gamma值对。
图1和图2可得,模型在gamma=1.667和C=1.320时达到最优分类效果。分类精确率为58.3%,召回率为48.3%,F1值为48.1%。
最后,实验设置SVM分类算法与贝叶斯分类算法(MB)的对比实验,并分别在对微博文本进行简单分词(segment)和在分词后对实义词语进行抽取(keywords)的两种数据样本上进行实验,分别采用TF,TF-IDF两种特征选择方法进行特征空间的建设,考察其精确率、召回率、F1值及模型训练的用时,实验结果如表3所示。
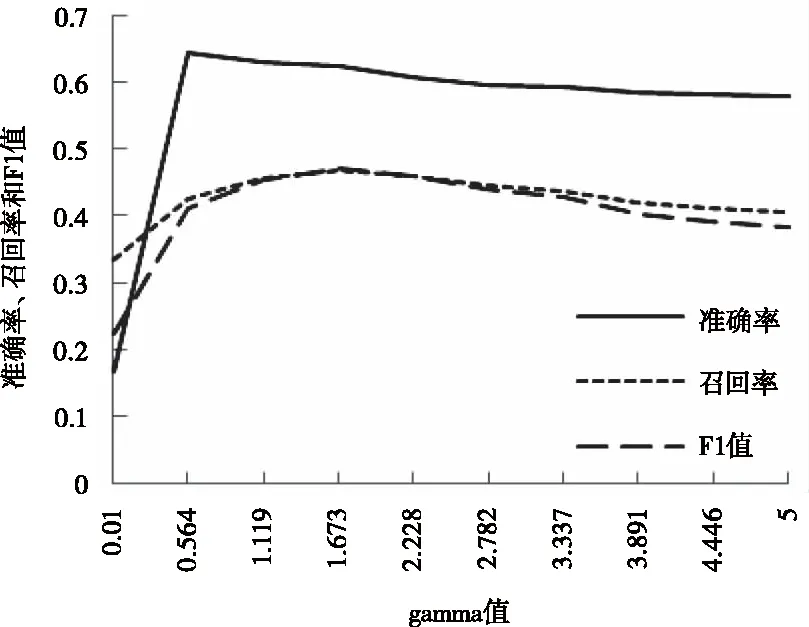
图1 参数gamma对分类性能的影响
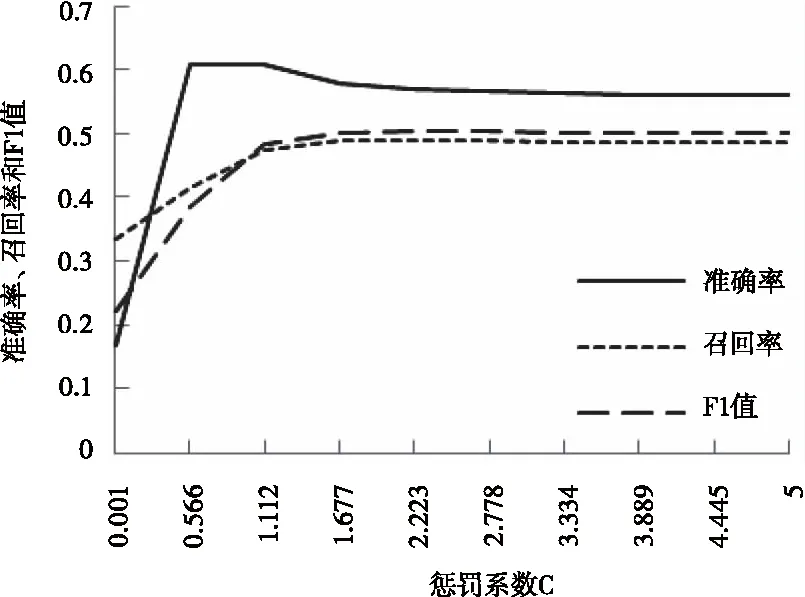
图2 惩罚系数C对分类性能的影响
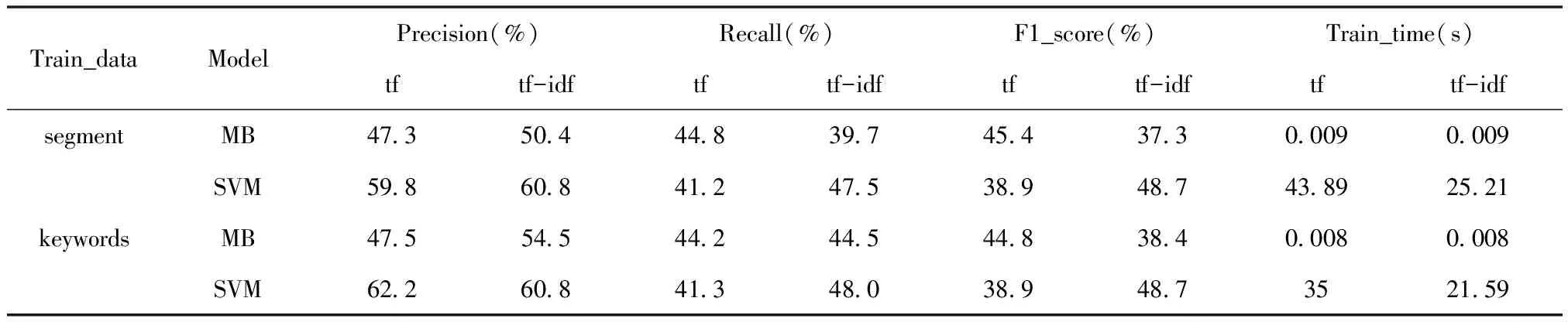
表3 不同数据集和不同特征选取方法下MB和SVM的实验结果对比
首先,从模型的训练时间上看,SVM的复杂度比MB的复杂度大。非线性可分样本集的复杂度为O(dn2),其中n为训练样本集的大小,d为特征向量的维度,而MB复杂度为O(dn),因为训练数据量较大,所以SVM的训练时间比MB的训练时间大得多;其次,在SVM进行训练时可以看到,TF的训练用时比TF-IDF训练用时多。因为TF选择的特征空间大,特征向量维度更大,所以在模型训练时需要更多的训练时间;再次,在分类模型为MB时,相比TF,TF-IDF对召回率(Recall)影响不是很大,但是却能够在一定程度上提高准确率(Precision),这样就降低了F1的得分。在分类模型为SVM时,相比TF,TF-IDF虽然对准确率的影响不是很大,但是却能够明显提高召回率的值,从而提高F1的得分;最后,在对微博进行实义词语的抽取之后,可以发现在保证准确率和F1值的情况下,可以提高模型的训练效率,其中TF下大概提高20%,TF-IDF下仍能提高大概15%。
SVM分类算法的优秀表现应该归因于两个方面,第一,SVM使用了核函数技术。通过引入核函数,将训练数据映射到更高维的空间中去,这样就能更容易地找到决策面,也即是SVM的超平面。第二,松弛变量和惩罚项的引入。通过引入松弛变量和惩罚项,再加上前面的核函数使得SVM具有了对非线性问题处理的能力。另外与贝叶斯分类算法依赖于全样本数据不同,SVM通过寻找样本中的支持向量,并通过支持向量来建立超平面。所以SVM分类算法的实验结果优于贝叶斯分类算法。
6 结论
相比TF,TF-IDF的特征空间小,文本向量维度小,可以加快模型的训练速度。并且TF-IDF构建的特征空间具有更加突出的类别表征能力,有利于提高藏文微博情感分类的效果;SVM相比MB具有更加优秀的分类效果。相比单一的特征显现概率来讲,SVM求解一个超平面,这个超平面能够将样本集较好地分离开;对实义词语进行抽取能够在保留足够多的文本信息的基础上提高模型的训练效率。
目前深度学习在人工智能领域成为研究热点,但是仍然不能忽视对传统机器学习算法的研究,因为在深度学习算法中仍然可以看到那些经典的传统机器学习算法的存在,对传统机器学习算法的研究的意义在于它可以为深度学习的方法提供较好的实验对比基线,从而为深度学习方法的选择提供有价值的参考。
