基于虚拟现实的大视差图像背景拼接改进
2022-09-28李云鹏刘小燕
李云鹏,刘小燕
(上海工程技术大学环境设计系,上海 201600)
1 引言
由不同相机经过多角度采集的图像,会存在较大程度的视差,单张图像背景面积相对较小,不能够显示完整的图像信息,为了还原真实场景、扩大三维视觉感知视野,就需要对大视差的背景图像进行精准拼接,来完成对场景的还原。
杨春德等人[1]研究出一种快速拼接算法,利用尺度不变原则提取变换特征点,经过动态规划完成自适应拼接,并通过边缘检测算法对原始图像进行矫直,使之形成一个全新的全景图,降低图像的扭曲程度;杨刘涛等人[2]研究了双视点图像拼接法,基于卷积网络模型建立历史数据库,根据数据库内手势特征,对不同视点下的图像进行剪切和拼接。但是经过上述方法进行图像背景拼接后通常会出现重影、模糊、图像扭曲变形等情况,视觉效果并不理想,具有一定的局限性。
针对上述问题,本文提出一种基于虚拟现实的大视差图像背景拼接优化算法。虚拟现实通过计算机仿真技术,以三维模型建立仿真虚拟环境,凭借人机互动形式呈现给体验者,使体验者在视觉感官内获得身临其境的沉浸式体验。以虚拟现实技术为基础,计算不同俯仰夹角图像下所产生重叠区域,利用网格表示单应性矩阵划分图像,在重叠区域网格内搜索图像特征点,经过二轮划分避免拼接后重影问题,利用信息熵和互信息值确定图像及特征点相似程度,筛选匹配点对进行排错处理,得到正确配点,最终完成图像背景拼接。拼接后图像背景没有明显缝隙,说明该方法具有有效性。
2 大视差图像背景重叠区域检测
大视差图像是在同一位置用不同角度对相同物体的描述,因角度不同导致成像效果也不相同,但图像中的物体都是相同的,这就会使多个待拼接图像背景中存在重叠区域。为了更好地拼接图像背景,首先计算图像间的背景重合区域。通过遍历全局的方式寻找图像中的匹配点,通常耗时较长且重复性高,误匹配的几率大,因此本文采用对图像间重叠区域进行计算和预估的方式实现重叠区域检测[3]。
为了降低后续特征点的检测和匹配工作复杂度、避免全图搜索耗时较长的问题,对不同图像序列之间的重叠区域进行预估,步骤如下:
1)首先根据拍摄设备参数,获得设备在水平方向的拍摄角度范围α。
2)根据各拍摄设备的排列结构,确定设备组的安装结构,在半径为r的圆面上排列设备组,测量出相邻两个拍摄设备之间的水平夹角β。
3)根据摄影中心、物点以及虚拟像点三点共线的原则,得出像点在图像上的坐标。
4)依据步骤1)和2)获取的参数,计算出图像在水平方向上的重叠区域,在没有相对俯仰夹角的情况下[4],相邻两个拍摄设备之间的几何关系可以用式(1)来表示
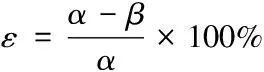
(1)
式中:ε表示相邻两幅图像重叠区域在整张图像中的占比。
通过以上步骤,能够确定两幅待拼接图像的重叠区域与它们边界值的关系,b1、b2分别代表两幅图像之间各自重叠区域的边界值,d表示图像水平方向长度,待拼接图像1的重叠区域分布在(b1,d)长度区间,待拼接图像2的重叠区域则分布在(0,b2)长度区间。
经过对上述重叠区域及边界值的计算,可以得出相邻两个拍摄设备所采集的图像在水平方向上的重叠区域。考虑到相邻设备间的相对俯仰夹角情况,设定设备间存在俯仰夹角θ,然后进一步估计两幅图像间垂直方向的重叠区域[5],计算过程如下所示
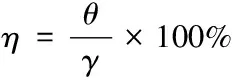
(2)
b=img.rowsη
(3)
式中:γ表示拍摄设备在垂直方向上的视角,η表示图像非重叠区域在整幅图像上的占比,img.rows表示拍摄设备上显示的图像垂直方向宽度,b表示图像非重叠区域的长度。测量出b值后,可根据b值计算出两幅图像在垂直方向上的重叠区域。将得出的垂直方向重叠区域与水平方向垂直区域相结合,可以得出存在水平和俯仰夹角的相邻拍摄设备所采集图像间的重叠区域。
为了使特征点的检测能够针对图像的特定区域进行,不至于重复搜索或搜索无意义区域,提出掩模处理方法[6]。在搜索特征点之前,对待搜索图像进行区域遮挡,控制图像搜索区域,对于两幅图像来说,非重叠区域没有相同特征点,不具备特征点搜索价值,掩模处理方法将计算出的待拼接图像重叠区域进行屏蔽处理,这样后续的特征点搜索就只针对屏蔽区域进行,大大节省了搜索时间,减少了全局搜索带来的麻烦。
3 拼接匹配点配对
利用网格划分大视差目标图像,将其分为多个网格,用单应性矩阵表示网格,网格和矩阵一一对应,在每个单应性矩阵内检测生成匹配点,再进行初始匹配。
将两幅待拼接图像分别用I和I′来表示,在两幅图像中搜索出的与之相对应的匹配点分别为p=[x,y,1]T、p′=[x′,y′,1],这时匹配点间的关系可变换为p′=h(p),它们的横纵坐标关系如下
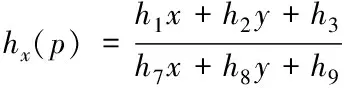
(4)
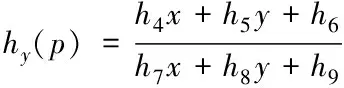
(5)
在齐次坐标下,p=[x,y,1]T和p′=[x′,y′,1]所对应的变换关系为:p′~Hp,其中,H表示单应性矩阵,H∈R3×3。鉴于p′和p属于同一方向,那么p′~Hp就满足03×1=p′×Hp这一条件,展开H矩阵可得下式
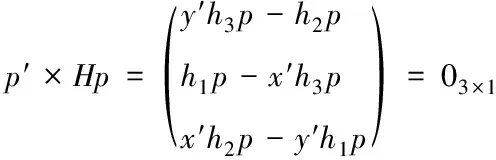
(6)
用Ah=0转换上式得出
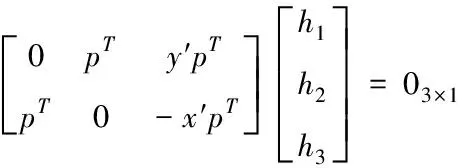
(7)
此时对于I和I′两幅图像而言,共有N组互相对应的匹配点,矩阵h可表示为
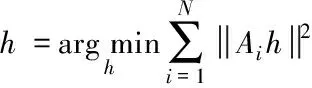
(8)
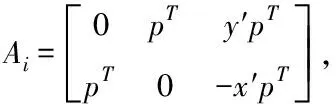
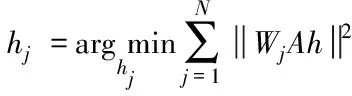
(9)
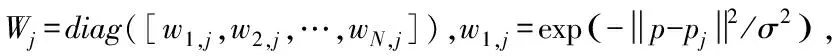
对在网格内搜索得到的特征点数据进行初始匹配,初始匹配中,图像中每个特征点的数量分布与其在网格中纹理的复杂度呈正相关[7]。假设将图像分成C1×C2个网格,计算出与每个网格相对应的单应性矩阵Hn,1,n∈{1,2,…C1×C2}。但由于网格密度不够紧凑,若待拼接图像纹理过于复杂,两幅图像重叠区域,很可能会出现虚化、重影现象。
在目标图像重叠区域内,网格中图像特征点数量为m,若m≥η,这时需要对网格进行第二轮详细划分,其中,η表示需要第二轮详细划分网格的匹配点最少对数,将网格第二轮详细划分为c1×c2个,计算二次网格的形变单应性矩阵为Hn,m,其中,n∈{1,2,…,C1×C2},m∈{1,2,…,c1×c2}。
4 图像背景拼接优化
根据图像背景特征点,利用特征点邻近算法对已经搜索出的特征点进行初始匹配后,初始匹配结果不可避免地存在些许错误匹配情况,因此优化的步骤首先是监测图像间的相似度情况,在相似度很高的情况下,筛选和校准匹配,去除掉错误匹配对[8]。
信息熵是对信息源所包容信息量的度量和量化指标,图像信息熵描述的是图像中所包含的信息量,熵值也能够反映出图像信息的复杂程度和不确定性,通过判断图像灰度值的分散程度,确定图像的熵值大小,灰度越分散,代表灰度值的不确定性越高,这时图像中熵值也就越大,信息熵表示如下
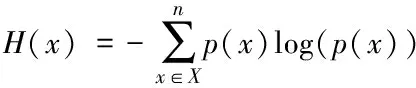
(10)
式中,x表示图像灰度值,p(x)表示灰度值为x发生的概率。
互信息可以表示两幅图像之间存在的信息关系,也就是其中一幅图像中所包含的另一幅图像的信息总量,通过图像信息熵可以判断和度量两幅图像之间的相似程度,其表达式为
V(A,B)=H(I)+H(I′)-H(I,I′)
(11)
式中,H(I)、H(I′)表示I、I′两幅图像的信息熵,H(I,I′)表示I、I′两幅图像的联合熵。对两幅待拼接图像的灰度值分布情况进行统计,计算它们之间的相关概率,其联合熵用下式来表达
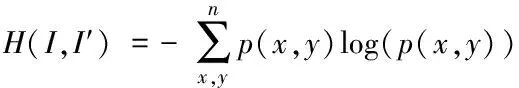
(12)
两幅图像中联合熵数值越小,表明两幅图像间互信息值越大,那么这两幅图像间的信息相关性越大,图像相似度越高。通过计算判断熵值和互信息,能够在很大程度上减少噪声对图像的干扰,还可以在减少计算量的同时实现对特征点的实时筛选匹配。
下面是具体的图像背景拼接优化流程:
步骤一:在图像中任意选取一对特征点,根据得出的图像间重叠区域,对这对特征点进行区域判断,若这对特征点不在得出的重叠区域内,则放弃该特征点对再随机选择下一对特征点,若在重叠区域内则进一步判断是否是正确点对。
步骤二:利用邻近算法,计算出与特征点相邻最近点和次近点的比值,若比值是小于0.6的,判定两个特征点是正确的匹配对,若比值在0.6到0.9之间,这时应利用图像信息熵和互信息值这两个因素,对特征点对作进一步判断,看是否是正确匹配点对,若比值大于0.9,则不符合条件,直接跳过判断下一对特征点。
步骤三:在图像的灰度坐标上,根据图像中特征点的坐标位置,截取相邻区域,利用信息熵和互信息这两个度量值,计算特征点之间的互信息数值,若互信息数值大于0.4,则将这对特征点认定为正确匹配对,由此实现图像背景拼接。
5 仿真研究
为验证所提方法对大视差图像背景拼接的有效性,本文在开源数据库内随机选取两幅大视差图像作为目标,进行拼接仿真,将这两幅图像分别命名为图像A和图像B,如图1所示。

图1 待拼接大视差图像
从图1中可以看出,图像A的右侧部分与图像B左侧部分具有重叠区域,两幅图像属于同一风景原型图像,在大视差拍摄角度下形成了横向与纵向不同程度的错位情况,仿真将针对上述两个图像进行图像背景拼接。为优化拼接效果,需计算两幅待拼接图像的重叠区域,再确定存在的重叠区域内标记背景特征点,有助于后期拼接操作。
图2为不同方法的图像特征点提取结果。

图2 不同方法的图像特征点提取结果
根据图2可知,本文方法标记图A特征点13个,图B特征点10个;利用快速图像拼接法得出图像A特征点16个,图像B特征点18个;利用双视点图像拼接法得出图像A特征点10个,图像B特征点14个。
三种方法各自获取到不同数量的特征点,将图像A和图像B上的特征点一一匹配。本文方法得到10对匹配点,如图3所示;经过快速图像拼接法匹配得到7对匹配点,如图4所示;经过双视点图像拼接法,最终得到6对匹配点,如图5所示。

图3 本文特征点匹配结果

图4 快速图像拼接法特征点匹配结果

图5 双视点图像拼接法特征点匹配结果
对上述3、4、5三幅图进行对比可以看出,快速图像拼接法搜索到的特征点虽然较多,但一部分特征点分布在全局,而并非重叠区域,导致一部分特征点无法进行配对;双视点图像拼接法提取特征点相对较少,所能配对的特征点相对更少;本文在重叠区域搜索特征点,得到的特征点均在有效区域内,通过信息熵和互信息两个值,对特征点和目标图像相似度进行判断,确认正确匹配点,同时筛除掉错误匹配,所得到的正确匹配点对相对更多,最终得到的匹配对也较其它两种方法多,配准性能较好。
经过以上步骤图像背景最终拼接完成,三种方法下拼接完成的图像分别如下图6、7、8所示。从图中可以看出图6拼接效果完整无明显接缝,呈现效果过渡自然,图像还原度较高;而图7和8呈现的拼接效果,在横向和纵向上均出现不同程度的错位情况,且都存在较为明显的拼接缝隙,图像还原并不完整,还原度较低。实验证明本文方法对图像背景的拼接优化可行性更高,拼接效果好。

图6 本文方法最终拼接结果

图7 快速图像拼接法最终拼接结果

图8 双视点图像拼接法最终拼接结果
6 结论
本文经过对待拼接图像重叠区域的估计运算,锁定特征点搜索区域,不仅省去了全局搜索的麻烦,同时提高了特征点搜索速度和匹配准确度。经过对图像中信息熵和互信息两个值的计算,能够确定图像以及特征点相似度,进一步筛选特征点对,得到正确的匹配点对,经过对图像背景的拼接得到完整的背景图像。实验证明本文所提方法特征点搜索准确迅速,正确匹配点对更多,对图像背景拼接效果较好,没有明显缝隙,可适用性高,鲁棒性好,能够实时、高效、准确地实现图像背景拼接。
