油田剩余可采储量预测算法设计及性能测试
2022-09-28矫欣雨
郭 瑾,矫欣雨,孙 肖
(1. 山东石油化工学院油气工程学院,山东 东营 257061;2. 中国石油大学(北京)石油工程学院,北京 102249)
1 引言
油田剩余可采储量预测是油田开发的基础,同时也是评价油田开发效果的重要指标[1,2],具体的预测方法主要包括经验公式法和递减法等。但是大部分方法都比较适用于新开发的油田区,计算结果和真实结果存在一定的差异,经过较长时间的开发调整之后,各项指标逐渐趋于稳定,会获取固定的变化规律,但是老区的可采储量无法直接在当年展示出来,滞后性较强。
为了有效解决上述问题,相关专家针对油田剩余可采储量预测方面的内容进行了大量研究,例如孙科等人[3]针对油藏工程基本理论提出一种了全新的可采储量预测方法,分析采出程度和含水率之间的关联,同时采用两者之间的关系版图完成预测。贾林等人[4]优先通过地质储量和甲型水驱规律曲线斜率之间的关系,计算童式图斑系数的取值;然后根据改进的甲型水驱规律曲线,得到无水采收率和水驱规律曲线的积分常量,同时绘制改进的童式版图,最终将其应用于采收率的预测中。
在上述两种方法的基础上,本文提出了一种基于蒙特卡洛法的油田剩余可采储量预测算法,经实验测试证明,所提算法能够快速准确完成油田剩余可采储量预测。
2 油田剩余可采储量预测算法
2.1 油藏数据预处理
将信息熵应用到油藏数据预处理中,同时引入加权欧式距离理论来全面提升油藏数据聚类效果的准确性[5,6]。
1)设定一个样本集X,其由n个m维样本数据构成,对应矩阵的表达形式如下:

(1)
2)为了获取更加精准的聚类结果,需要对全部数据进行归一化处理。
3)计算数据集X中第i个样本对应第j列属性所占的比重Pij,具体的公式为
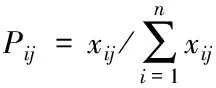
(2)
4)计算属性j对应的信息熵Ej,如式(3)所示

(3)
5)采用式(4)计算属性j的差异系数qj,即
qj=1-Ej
(4)
6)采用式(5)计算属性j的权重ωj,即:

(5)
当经过计算获取属性的权重后,给出数据对象a和b的加权欧式距离dist(xa,xb),具体的计算公式为

(6)
式中,xaj和xbj分别代表研究对象a和b对应的第j列属性值。
在油藏数据预处理中,需要进行异常检测的数据集通常包含正常和异常两种数据[7,8],选取一个初始中心,其应满足密度高于数据集平均密度,初始聚类中心选择算法详细的操作步骤如下所示
1)设定样本集X={x1,x2,…,xn},最近邻数据共包含t个点数,聚类中心数量为K,计算X中数据点xj的密度,具体的计算公式为
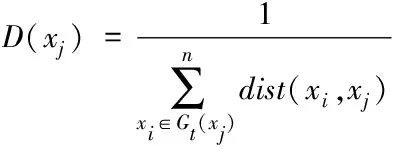
(7)
式中,Gt(xj)代表的是第t个最近邻数据点集合。
2)计算全部数据对象的平均密度D,通过D(xj)>D的数据点形成全新的数据集X′。
3)计算X′中各个样本和前i-1个初始聚类中心加权欧式距离的最小值,将其放入到对应的集合中,直至满足设定的约束条件。
设定数据集中各个数据对象的初始异常度为Fj,通过信息熵计算属性权重的方式获取数据集对应的属性权重。通过初始聚类中心选择方法确定初始聚类中心的数量,同时计算数据对象xj到不同簇中心的加权欧式距离,同时将xj划入到聚类中心所在的簇中。结合相关约束条件,重新形成各个簇的中心点。假设数据对象xj的异常度Fj≥η,则说明该油藏数据点为异常数据点,同时将其加入到异常点集合中,最终实现油藏数据预处理。
2.2 基于蒙特卡洛法的油田剩余可采储量预测模型
油田剩余可采储量预测是油田勘探和开发的重点内容,对油田的产量具有十分明显的影响,需要对不同影响因素进行非线性分析,本文根据油藏数据的特性,采用蒙特卡洛法估算油田剩余可采储量。蒙特卡洛法主要被应用在复杂且高维概率分布的试验函数评估中,主要是通过动态模拟实现估算,同时结合新的油井生产指标和油井的生产性能构建油田剩余可采储量预测模型。
在采用蒙特卡洛法进行模拟的过程中,除了需要考虑不同概率的相关性之外,同时还需要深入分析各个变量间的相关性。在模拟过程中,蒙特卡洛法估算油田剩余可采储量主要借助容积公式法,如式(8)和式(9)所示

(8)
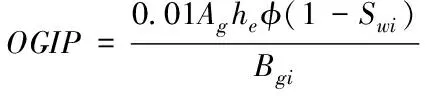
(9)
式中,OOIP和OGIP分别代表原始油田的质量和天然气地质储量;Ag和A0代表油田的含油比例;he代表油田的平均厚度;φ代表地表孔隙密度;Swi代表任意常数;Boi和Bgi代表油田的体积系数。
结合上述计算公式,采用蒙特卡洛法构建油田剩余可采储量预测模型,具体的操作步骤如下所示:
1)将全部对估算结果产生影响的因素进行排队,选取核心要素纳入到系统中。
2)确定目标函数。
3)通过任意一组随机变量获取对应的参数取值。
4)将随机一组参数代入到式(8)和式(9)中,求解目标函数值。
5)引入油田生产指标和生产性能,以此为基础建立油田剩余可采储量预测模型。
2.3 油田剩余可采储量预测模型优化
为了提升预测模型的性能,采用粒子群算法对预测模型进行进一步优化。粒子群算法主要是受到鸟群觅食行为的启发提出的一种优化算法。设定鸟群在随机寻找食物,整个区域内只含有一个食物,而鸟群的位置是不固定的[9,10]。设定目标搜索空间是D维的,在迭代过程中各个重新计算鸟群的位置和速度,具体的计算公式为

(10)
惯性因子的计算公式为

(11)
式中,wmax和wmin分别代表最大和最小惯性因子取值。
为了更好地实现寻优,需要在寻优的过程中不断对惯性因子wi进行调整,直至获取最佳适应度取值,则停止寻优[11,12],具体的计算公式如下
wi=wmax-(wmax-wmin)*f(a,b)
(12)
式中,f(a,b)代表粒子经过当前迭代获取的适应度变化趋势。
在粒子群优化算法中,需要在整个求解空间中获取全局最优解。以下在迭代过程中加入加速因子实时调整迭代次数,具体的计算公式为

(13)
粒子群算法将目标函数设定适应值寻找全局最优解,能够全面提升预测结果的适应性和稳定性,同时该算法还具有较好的全局搜索能力。其中,粒子群的适应度计算过程如式(14)所示
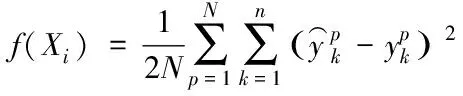
(14)

利用图1给出粒子群算法优化油田剩余可采储量预测模型的详细流程:
1)确定网络的拓扑结构,同时还需要确定不同的参数取值。
2)设定种群的规模,同时更新各个粒子的位置和速度。
3)分别计算不同粒子的适应度取值。
4)更新各个粒子的惯性因子,进而实现粒子的位置和速度更新。
5)假设满足迭代条件,则结束迭代;反之,则返回步骤3),重新执行以上步骤。
6)将通过粒子群算法获取的全局最优解设定为网络中的取值和阈值,对预测模型进行训练,直至满足设定的误差需求为止。
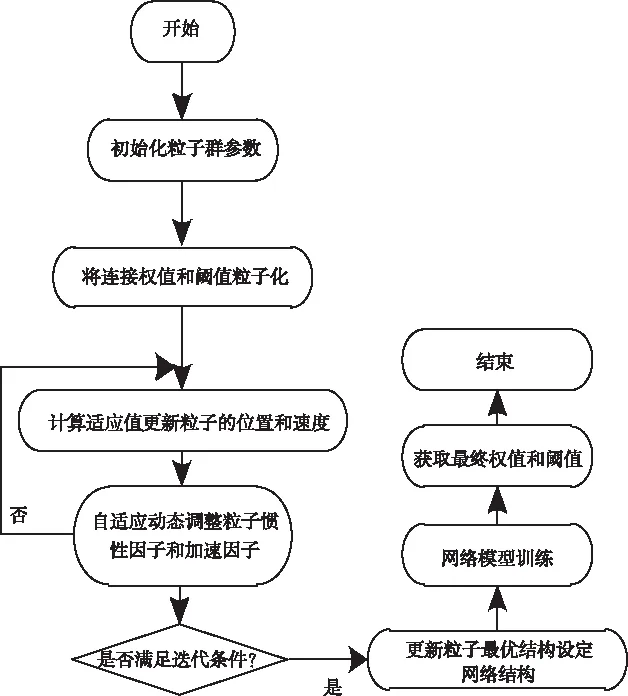
图1 PSO优化流程图
在上述分析的基础上,实现粒子群算法的并行化处理,详细的操作步骤如下所示:
1)将数据集和种群进行初始化处理。
2)分别对不同的种群进行划分,即将数据和种群划分为M份。
3)计算各个粒子的适应度取值,获取自身最优值。
4)将各个节点进行通信,进而获取全局最优的适应值。
在上述分析的基础上,结合粒子群算法,实现对基于蒙特卡洛法的油田剩余可采储量预测模型优化,通过优化后的模型实现预测。
3 仿真研究
为了验证所提基于蒙特卡洛法的油田剩余可采储量预测算法的有效性,实验选取H城市油田开发区作为研究对象,选取200亩典型的油田构建样本空间,其中训练样本和测试样本各占一半。选取文献[3]和文献[4]作为对比算法,进行对比验证。
1)时间/s
利用图2给出三种不同算法的时间复杂度对比结果:

图2 不同算法的预测时间对比结果
从图2能够看出,各个算法的预测时间会随着测试样本的增加而增加。但是和另外两种算法相比,所提算法的预测时间明显更低一些,说明所提算法能够在较短的时间内实现对油田剩余可采储量的预测,预测效率较高,充分证实了所提算法的优越性。
2)预测结果分析
将油田剩余可采储量预测指标之一的油藏饱和度作为测试对象,三种不同算法的具体实验对比结果如图3所示。

图3 不同算法的油藏饱和度预测结果对比
从图3中能够看出,所提算法的油藏饱和度和真实值更加接近,而文献[3]算法与文献[4]算法与真实值之间的差距较大。产生这种差距的主要原因为:所提算法对油藏数据进行了预处理,及时发现异常,有效提升了预测结果的准确性。
为了进一步验证所提方法的预测性能,以下实验测试油田剩余可采储量,分别采用三种不同的算法进行预测,具体的实验结果如图4所示。
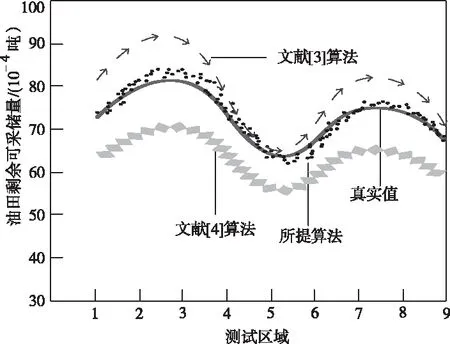
图4 不同算法的油田剩余可采储量对比结果
从图4能够看出,所提方法能够获取更加精准的预测结果,其预测得到的油田剩余可采储量与真实值之间的差距较小,而传统文献[3]算法与文献[4]算法与真实值之间的差距较大,充分验证了所提算法的优越性和有效性。
以下实验测试将均方根误差设定为测试指标,分析各个预测算法的预测性能,其中均方根误差取值越低,则说明预测效果越好,利用表1给出详细的实验对比结果:
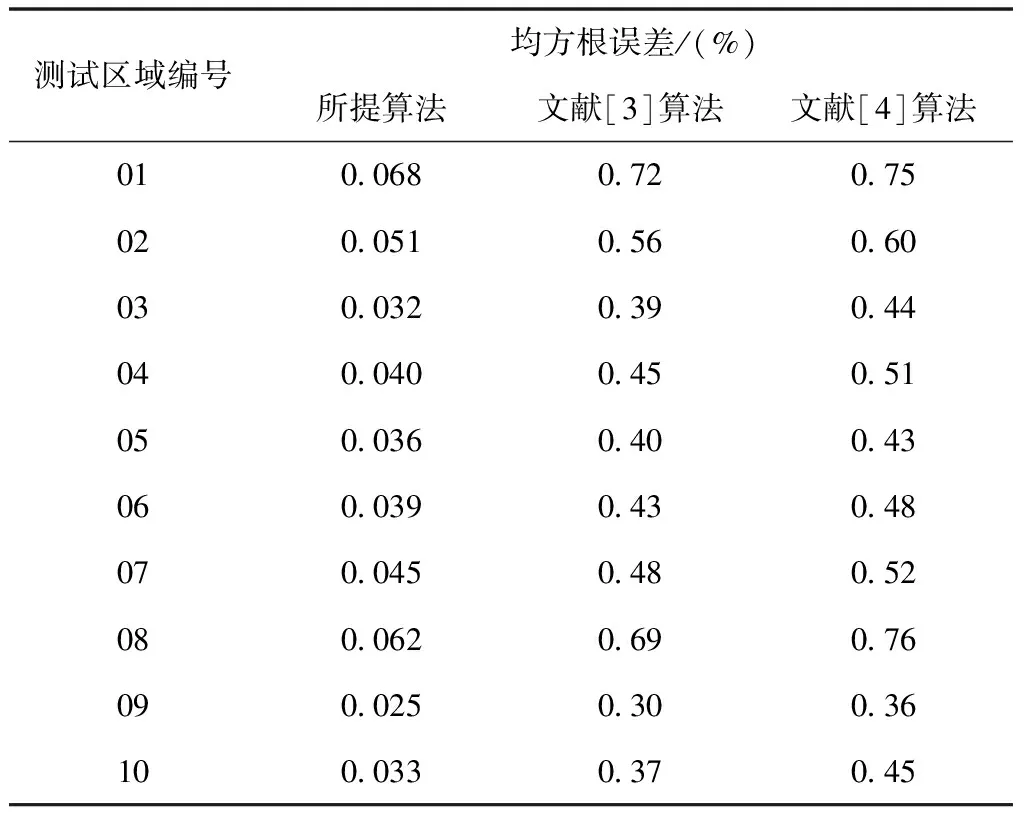
表1 不同算法的均方根误差对比结果
从表1能够看出,相比文献[3]算法和文献[4]算法,所提算法的均方根误差取值明显更低,且与传统算法之间的差距较为明显,进一步验证了所提算法预测结果的准确性,说明所提算法的预测结果具有可靠性。
4 结束语
针对传统算法存在的不足,结合蒙特卡洛法,提出一种全新的油田剩余可采储量预测算法。经实验测试证明,所提算法能够精准预测油田剩余可采储量,同时还能够有效降低预测时间,通过实验结果充分验证了所提算法的有效性与应用价值。所提算法现阶段仍然处于初步研究阶段,还需要进一步研究,例如提升自身的泛化能力以及增强模型的多样性等,接下来将以上述内容为重点,进一步提升所提算法的应用效果。
