基于遗传算法与BP_Adaboost的故障检测方法
2022-09-28付乐天
付乐天,李 鹏*,高 莲,沈 鑫
(1.云南大学信息学院,云南昆明650091;2.云南电网有限责任公司,云南昆明650011)
1 引言
当前,随着社会经济技术的发展,工业过程的技术和产品不断发生着更新,化工过程越来越复杂,化工过程的安全性和可靠性以及产品的质量需要得到保障,所以及时有效的故障检测方法具有重要意义[1-2]。
故障检测是一门目标明确、针对性强、应用范围广的交叉型技术学科,其目前主要分为三种类型[3]:基于解析模型的方法[4]、基于数据驱动的方法[5]、基于知识的方法[6]。其中,基于数据驱动方法因为不需要先验知识且现代化工过程复杂很难精确地建立数学机理模型,因此受到广泛地关注。在众多基于数据驱动的方法中,又以基于多元统计分析以及基于机器学习的方法应用广泛。文献[7]采用PCA对电潜泵实时数据进行分析,根据数据的线性组合进行特征提取,降低数据维度,创造新的主元空间。实验结果表明PCA可以有效监测ESP的健康状况。文献[8]提出了一种基于BP神经网络与小波函数的轴承故障检测模型。该模型首先利用小波函数对振动信号进行分解,然后构造特征向量作为BP网络的输入元素。实验表明,该模型能够准确地半段故障的类型。文献[9]提出基于BP_Adaboost的电子式电能表故障诊断模型。该模型把单一BP网络作为弱分类器,并利用Adaboost算法组合训练得到强分类器,然后应用电子式电能表的典型故障诊断中。仿真结果表明BP_Adaboost模型相较与单一BP网络能提高精度,显著减小误差。文献[10]利用NPE将原始空间划分为不相关的特征空间和数据残差空间,针对两个空间分别构造T2与SPE统计量,对环网柜进行故障检测。实验表明该模型改善了环网柜故障检测的效果。
上述研究方法虽然为故障检测提供了很好的思路,但将其应用于化工过程的故障检测中仍有不足。因为化工过程故障的影响因素种类众多,导致其模型建立复杂,检测精度不够。因此,本文提出了采用遗传算法对自变量进行降维并优化网络参数,再结合BP_Adaboost方法建立模型,并对TE过程进行故障检测。首先,采用遗传算法降维,能够极大提取数据间的特征关系,降低数据的输入维度,减小模型的复杂性,同时利用遗传算法对BP网络的权值和阈值进行参数优化能够提高网络的精度。然后,建立BP_Adaboost模型能进一步强化BP网络的精度,增强对故障的检测能力。最后,通过TE实验仿真,表明本文方法模型精度良好,能准确地对化工过程进行故障检测。
2 基本理论
2.1 遗传算法
遗传算法是1962年由Holland教授提出的一种模拟自然界遗传机制和生物进化论而形成的智能优化算法[11]。其原理主要依据大自然的‘优胜劣汰,适者生存’的竞争机制。算法首先需要将优化的参数引入到个体的基因编码中,然后根据适应度函数对编码的个体进行选择、交叉和变异操作。其中,保留适应度值高的个体,淘汰适应度值低的个体,不断地反复迭代优化,直至筛选出最优个体。其基本操作分为:
1)选择操作
选择操作是指以一定的概率将个体从旧群体选择到新群体中,适应度高的个体其选中的概率越大。
2)交叉操作
交叉操作是指从群体从选择两个个体,通过两个染色体的交叉组合产生新的优秀个体。其染色体的交叉方式可分为单点交叉和多点交叉。
3)变异操作
变异操作是指从群体中任意挑选一个个体,对其染色体中的一点进行变异,以产生更加优秀的个体。
2.2 Adaboost算法
Adaboost是一种迭代算法,本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。其核心思想是针对同一个训练集训练不同的分类器,然后把这些分类器集合起来,构成一个更强的最终分类器[12]。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类准则。
3 基于遗传算法自变量降维与BP_Adaboost的优化模型
遗传算法自变量降维与BP_Adaboost优化模型(本文称为GADR-BP_Adaboost模型)如图1和图2所示,模型包括2个部分:BP_Adaboost模型部分和遗传算法自变量降维与优化部分。BP_Adaboost模型主要是将单一的BP网络作为弱学习器,然后根据集成学习的思想把n个BP网络结合起来建立一个强学习器。其流程主要为先对数据进行预处理,再将预处理后的数据输入到单个的BP网络弱学习器中,然后根据弱学习器的输出来调整各个样本的权值,最后得到整个模型的输出。为了提高BP网络的精度,采用遗传算法先对自变量维度进行基因编码,然后根据遗传算法的全局迭代优化提取出最终参与建模的维度重新进行数据的组合,最后利用组合后的数据对BP网络进行权值和阈值的优化,从而建立BP网络。本部分通过降维以及权值和阈值的优化来提高单个的BP网络的精度,从而有效地提高了BP_Adaboost模型的精度。

图1 BP_Adaboost模型网络结构图
3.1 BP_Adaboost
模型依据Adaboost集成学习思想,将BP网络作为弱学习器从而建立一个更加强大的集成学习器,其主要步骤如下:
Step1:由样本数量确定初始分布权值为:
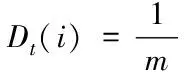
(1)
式中,Dt(i)表示第t轮第i个样本的分布权值,m表示样本数量。
Step2: 训练第t组弱学习器时,用训练数据训练神经网络并且预测训练数据的输出,根据输出得到神经网络的预测误差和为
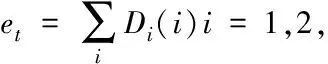
(2)
式中,g(t)为预测输出;y为期望输出。
Step3: 根据预测误差和计算序列权重
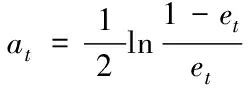
(3)

图2 遗传算法自变量降维与优化流程图
Step4: 根据序列权重计算下一轮训练样本权重
(4)
式中,Bt是归一化因子。
Step5: 由弱学习器得到的函数计算得到强学习器函数
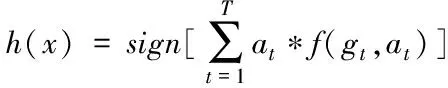
(5)
式中,f(gt,at)为弱学习器训练得到的函数。
3.2 遗传算法自变量降维与优化模型
遗传算法自变量降维与优化模型是基于遗传算法能将解空间映射到编码空间,使每个编码对应于一个问题的解,其算法步骤如下:
Step1:输入数据,建立BP模型,使染色体编码的每一位对应于一个输入自变量维度。每一位只能取0、1两种情况。
Step2:对每一个个体计算个体适应度值,提取并纪录最优个体适应度值。
Step3:计算种群中所有个体的适应度和
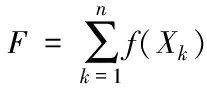
(6)
式中,f(Xk)是个体适应度。
计算种群中个体的相对适应度,并以此作为遗传概率
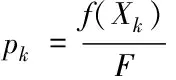
(7)
Step4: 对染色体进行选择和交叉操作,然后进行网络的迭代优化,提取输出种群中染色体值为1的所对应的自变量维度,即筛选出最具代表的自变量维度。
Step5: 依据提取的自变量维度对输入数据进行重新组合,将组合后的数据作为网络的输入进行权值和阈值的优化。根据优化后的权值和阈值以及经过降维后的数据进行创建网络。
4 GADR-BP_Adaboost模型应用于故障检测
本文将提出的遗传算法自变量降维与优化BP_Adaboost(GADR-BP_Adaboost)模型应用于故障检测中,其建模流程图如图2所示,主要分为以下几个部分:
1)数据预处理;
2)遗传算法模型参数选取;
3)建立GADR-BP_Adaboost的故障检测模型;
4.1 数据预处理
为了使不同量纲的数据具有可比性,本文对数据进行归一化处理,将数据归一化到[-1,1]之间,以提高模型的精度
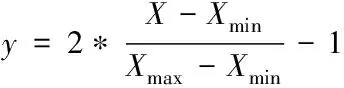
(8)
式中,y为归一化后的数据;Xmin为样本数据最小值;Xmax为样本数据最大值。
4.2 遗传算法模型参数选择
为了提高模型建立的精度,本文采用遗传算法对输入的自变量进行降维和对网络的权值阈值进行优化。遗传算法相关参数设置如表1所示。

表1 模型参数设置
其中,选取测试集数据误差平方和的倒数作为适应度函数
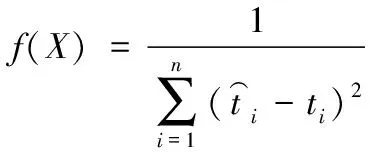
(9)
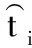
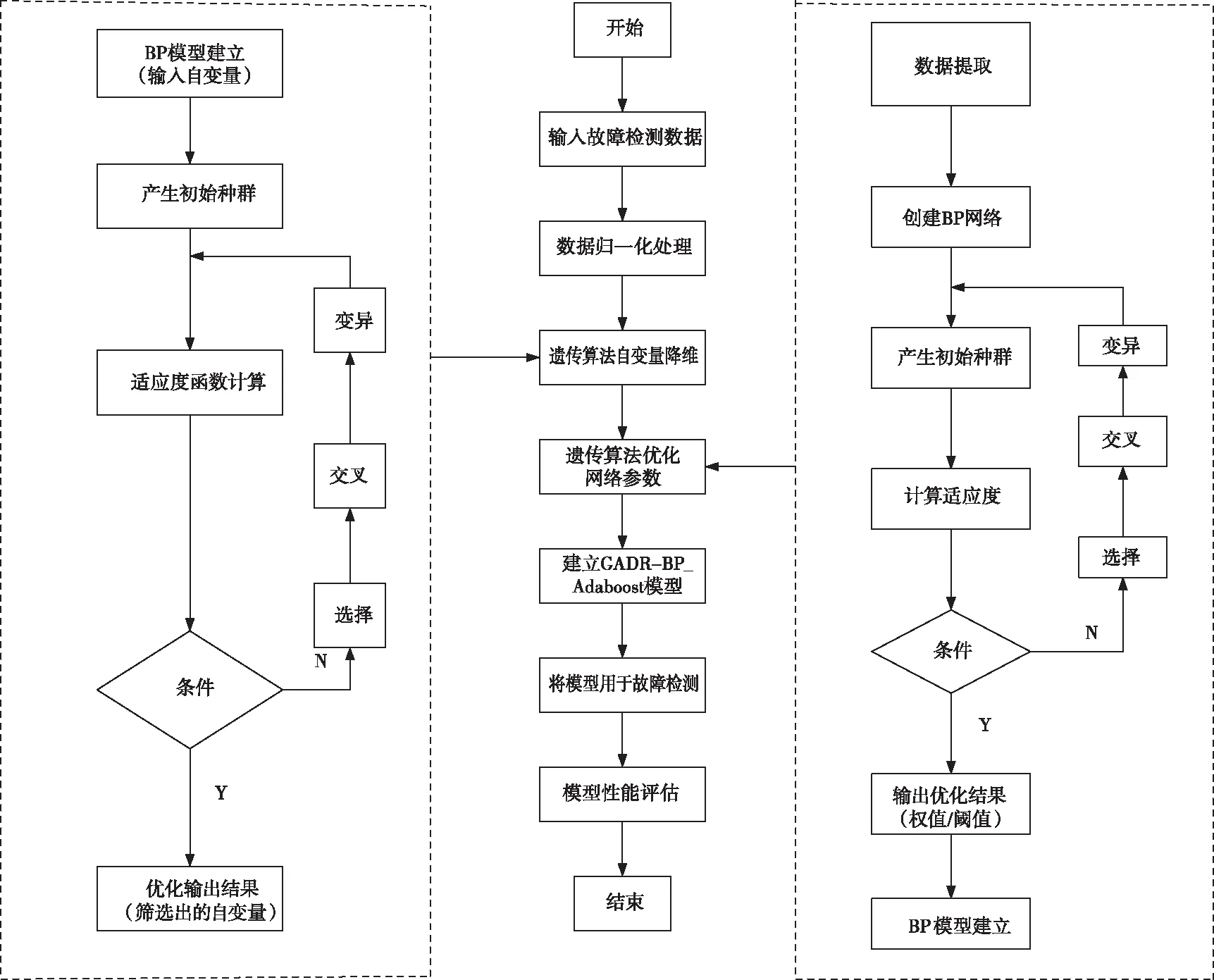
图3 基于GADR-BP_Adaboost模型的故障检测流程图
4.3 建立GADR-BP_Adaboost的故障检测模型
本文建立基于遗传算法自变量降维与优化BP_Adaboost的故障检测模型具体步骤如下:
Step1:对故障检测输入数据进行数据归一化处理,将处理好的数据作为模型的输入。对输入数据的自变量维度进行基因编码,使用遗传算法对自变量进行降维。
Step2:提取经过遗传算法进行降维后维度,然后重新组合新的故障检测输入数据。以新的输入数据作为模型的输入,利用遗传算法优化BP网络的权值阈值。
Step3:利用优化好的权值和阈值以及新的故障检测输入数据,创建BP网络模型。将创建的BP网络作为弱学习器,根据Adaboost集成思想,建立BP_Adaboost强学习器。最后,将建立好的模型应用于故障检测。
5 算例分析
5.1 数据来源
本文数据采用的是TE化工过程数据,其是由J. J. Downs和E. F. Vogel[13]根据伊士曼化学公司的实际化学过程开发的标准测试平台。
TE过程数据包括41个过程测量变量和12个过程控制变量[14]。由于最后一个控制变量保持不变,本文选取前52个变量作为输入自变量。TE过程的故障共有21种,其中已知故障种类16个,为故障1-15、21;未知故障种类5个,为故障16-20。
TE过程数据分为21组数据,每组数据的样本数量为960个,数据维度为52维。其中,每组前160个数据为正常数据,后800个数据为故障数据。本文将在每组数据的前后各添加480个正常样本数据,以模拟系统故障被修复后的运动状态。因此,本文采用的每组数据长度为1920个,取前1280个数据作为训练集,后640个数据作为测试集。其中,训练集中前640个正常样本数据,后640个为故障样本数据;测试集中故障数据为160个,正常数据为480个。
5.2 评价指标
本文采取的模型性能评价指标为检测率FDR和误报率FAR,其公式如下:
5.3 效果分析
在对于化工过程的故障检测采用本文方法,能够有效地提高模型的精度,相较于单一的BP网络模型、单一的BP_Adaboost模型和NPE模型,本文方法不论是在检测率,还是在误报率方面都具有良好的表现,其具体见表2所示。其中,经过多次实验,网络隐藏层节点数为15。
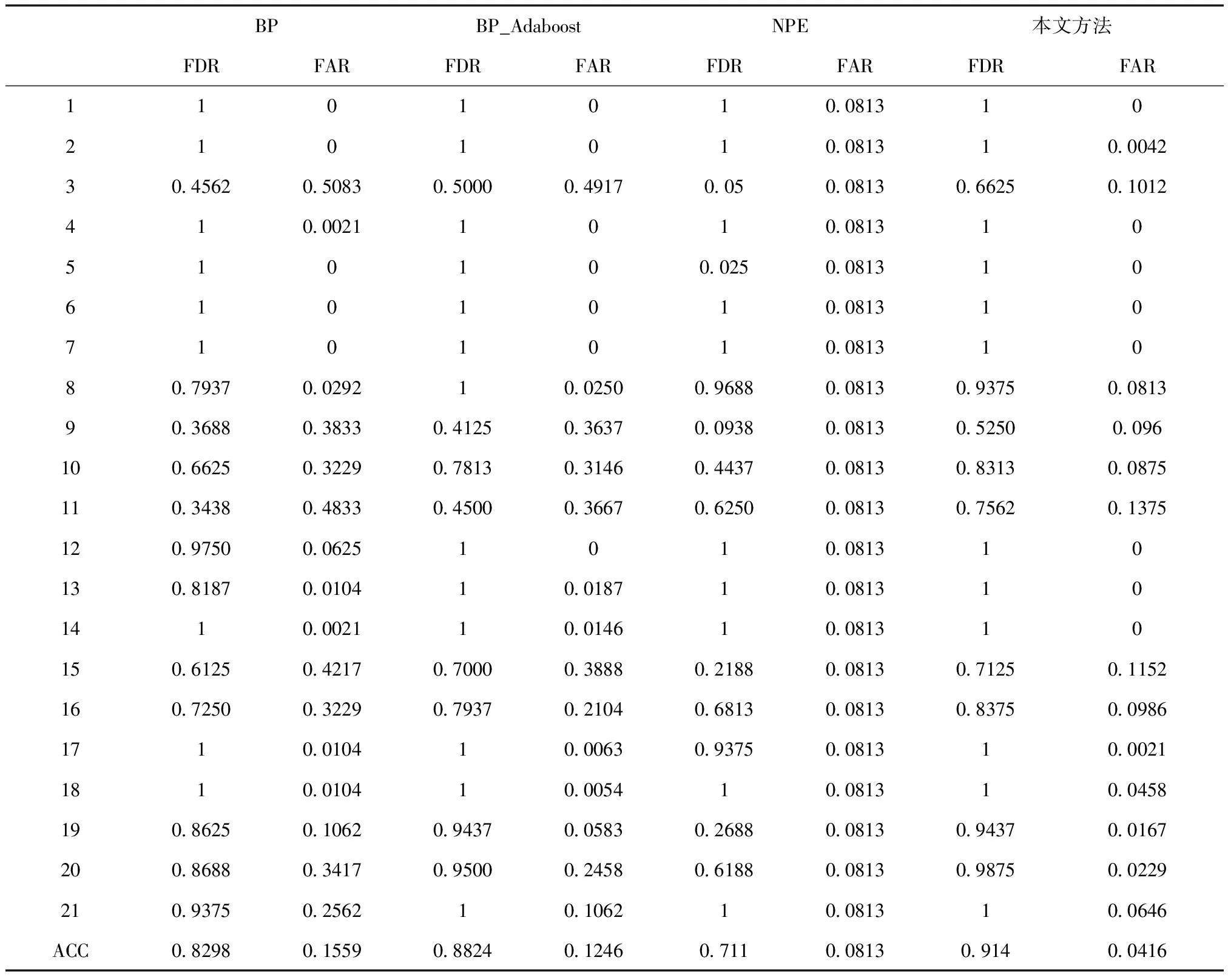
表2 4种模型性能指标对比
其中,ACC表示的是21种故障的平均值,其公式如下

(10)
式中,Xi为21种故障情况所对应的各个指标的值。用来衡量模型对化工过程中故障检测的整体性能。
由表2可以看出,BP_Adaboost模型因为依据Adabooost思想将BP作为弱学习器从而构建强学习器,有效地提高了模型的精度。在故障检测率方面,相对于BP整体平均提高了6%,在故障误报率方面,平均降低了3%,尤其是对于故障种类为17、18、21的表现要比BP网络更加突出。但是,对于故障类型为3、9、10、11、15、16、20进行故障检测时,检测率和误报率表现均有欠缺,还需要提高。而本文模型在4种模型的比较中表现最好。其因为在BP_Adabooost模型的基础上采用遗传算法对自变量进行降维处理并对网络参数进行优化,提高了模型的精度,相较于BP_Adaboost模型,检测率整体提高了4%,误报率降低了8%。同时在单独针对于某一种故障类型时,其也在4种模型中表现最好。而本文方法与NPE进行比较时,其模型的表现也均好过NPE方法。
本文模型在BP_Adaboost模型基础上采取遗传算法对自变量进行降维,降低了计算的时间耗费,其时间计算公式如下:
T=T训练+T测试
(11)
式中,T为总的计算时间耗费;T训练为训练模型所需时间;T测试为模型测试所需时间。
其时间耗费如表3所示。

表3 模型时间耗费
由表3可知,本文模型对于21种故障类型的平均计算时间耗费比BP_Adaboost模型少40多秒,并且每种故障类型的时间耗费都要低。因为采用了遗传算法对自变量进行降维,其不仅提高了建模的精度,同时还降低了模型计算的时间耗费,能有效地对化工过程进行故障检测。
6 总结
本文针对化工过程中故障检测模型精度不够,提出了一种基于遗传算法自变量降维与优化BP_Adaboost的故障检测方法,有效地提高了模型的建模精度,能准确地对化工故障进行检测。经过TE过程的验证,其结论如下:
1)采用遗传算法进行自变量降维不仅提高了模型的精度,同时还降低了计算的时间耗费,能有效对化工过程进行故障检测。
2)基于遗传算法对BP网络的权值和阈值进行参数的优化,可以避免网络陷入局部最小值,提高模型的精度。
3)建立基于Adaboost集成学习思想的BP_Adaboost强学习器能够有效的提高模型的精度。
