基于改进混合采样和XGBoost算法的信用卡欺诈检测方法
2022-09-24施炜利饶兰香孟莎莎郭晓明李逸伦
孙 丹,施炜利,饶兰香,孟莎莎,郭晓明,李逸伦
(1.江西省科技基础条件平台中心,江西 南昌 330003; 2.中国广电江西网络有限公司,江西 南昌 330006)
0 引 言
信用卡欺诈是指故意使用伪造、作废的信用卡,冒用他人的信用卡骗取财物,或用本人信用卡进行恶意透支的行为,常见的信用卡欺诈主要包括失卡冒用、假冒申请、伪造信用卡[1]。随着在线支付交易的日益增多,与借记卡、预付卡和信用卡相关的欺诈是企业、金融业和消费者共同面临的一个日益严峻的问题。常规解决信用卡欺诈检测问题是通过传统的数据统计分析对比来对用户消费信誉进行评分,信用评分低就有可能成为信用卡欺诈用户[2]。这种传统统计数据分析方法需要耗费大量的人力、物力和时间成本,检测的准确度也不高。随着机器学习技术的不断发展,国内外学者开始从数据挖掘角度去解决信用卡欺诈检测问题。不过利用机器学习方法解决信用卡欺诈问题同样面临很多挑战。如信用卡交易数据涉及用户敏感隐私数据,很多研究学者很难拿到准确有效的信用卡交易特征数据;同时信用卡交易数据通常是分布非常不平衡的数据,正常交易数据远远大于异常交易数据,数据不平衡分布问题会对分类精确度产生很大的影响[3]。
近年来,国内外研究学者提出了各种各样的机器学习模型来建立信用卡欺诈检测模型,如支持向量机、决策树、神经网络、集成学习等信用卡检测方法。Zhang等人[4]研究了基于加权支持向量机的信用卡欺诈检测方法,引入了加权支持向量机SVM算法,极大地提高了检测性能。李梦涛等人[5]重点从数据本身出发,利用数据挖掘技术,挖掘数据背后相关的欺诈信息,提出了一种基于数据挖掘的随机森林的信用卡检测方法,其精确率和召回率得到较好的检测结果。Prasetiyo等人[6]采用随机森林算法模型对合成数据集进行训练检测,识别效果比简单的机器学习算法效果更好。Asha等人[7]研究了基于多种机器学习算法进行信用卡欺诈检测方法,对比了多种机器学习算法,提出了一种人工神经网络(ANN)算法进行信用卡欺诈行为检测,其准确度接近100%,比无监督学习算法具有更高的准确性。Lebichot等人[8]研究了评估增量学习策略,设计了一种基于评估增量学习策略的信用卡欺诈行为检测系统。通过集成学习、多样性迁移学习提高检测系统准确性。这些检测模型提出的研究者们都只注重方法和算法的研究,往往忽略了前期特征数据的预处理工作和信用卡交易数据的极度不平衡数据的预处理工作。
为了解决数据极度不平衡分布问题,研究者们已经研究了许多方法来消除数据不平衡所带来的影响,张菲菲等人[9]提出了基于过采样的不平衡数据集分类算法(SDPDBoost),该方法使用SMOTE进行样本合成,并且把新样本加入到数据集中。Liu等人[10]提出了随机欠采样提升算法(RUSBoost),该方法采用欠采样方法,随机删除一些多数类样本,然后使用处理后的数据构造弱分类器。研究者们开始研究过采样和欠采样来解决信用卡欺诈检测中信用卡交易数据不平衡数据的处理。王一明[11]通过多次欠采样方法,构造多个均衡数据集,建立多个Logistic回归模型,最后将多个Logistic回归进行集成,构建最终的检测模型,减少了真实数据信息量的丧失;张艺豪等人[1]为了解决数据不平衡分布问题,利用合成少数类过采样技术SMOTE算法生成新的样本使得数据平衡分布,再利用加权随机森林算法训练平衡数据,较好地解决了过拟合问题;琚春华等人[12]克服了SMOTE算法在生成新样本时的盲目性和局限性,提出了基于kNN-Smote-LSTM的信用卡欺诈检测网络模型,大大改善了误分类问题。研究者们在不平衡数据处理问题的研究中只单纯的采用单种采样方法进行数据处理,或者是对单种采样方法进行改进,未结合过采样和欠采样方法对不平衡数据处理进行过多的研究。为了使合成的样本更具有多样性,本文提出一种改进的混合采样技术。通过多种过采样和多种欠采样进行多种方式组合,选择最优的组合采样方式处理不平衡数据集。
本文首先对3种不平衡数据处理方法进行分析,提出一种基于改进的SMOTE+ENN混合采样和XGBoost算法的信用卡欺诈检测方法,最后通过未进行不平衡数据数量实验、6种不平衡数据处理组合采样方法实验、基于改进的SMOTE+ENN混合采样下的5种分类算法实验从准确率、精准率、召回率、F1值、AUC值5项评价指标对3类实验结果进行分析验证。结果表明基于改进的SMOTE+ENN混合采样和XGBoost算法的信用卡检测方法在不平衡数据处理上不仅提高了信用卡欺诈行为数据的区分度,而且提高了特征提取的计算性能和准确性,同时能够准确有效地检测出信用卡欺诈行为,提高了信用卡欺诈行为检测准确性。
1 本文方法
1.1 数据选择及处理
1.1.1 数据选择
测试数据来自Kaggle上Credit Card Fraud Detection数据集,如图1所示。该数据集记录了2013年9月欧洲信用卡交易数据,总共包括2天的交易数据。在284807次交易中包含了492例诈骗,数据集极其不平衡,诈骗频率只占了交易频次的0.172%[13]。
图1 Credit Card Fraud Detection数据集主页
如图2所示,Credit Card Fraud Detection数据集为了避免泄露用户隐私,将原始数据做了脱敏等处理,最后使用28维向量描述,分别对应V1~V28,该笔交易发生时间定义为Time,该笔交易涉及的金额定义为Amount,该笔交易是否为欺诈定义为Class字段,其中1表示为欺诈,0表示为正常交易[14]。
图2 Credit Card Fraud Detection数据集数据结构
1.1.2 数据处理
针对Credit Card Fraud Detection数据集最简单的处理过程是对数据特征提取方式进行标准化,V1~V28已经是归一化处理过了,剩下仅Amount字段是原始的交易数据,需要进行归一化处理。最简单的标准化方式是将数据集的字段控制在0~1之间或者-1~1之间[15]。首先使用pandas从文件中加载数据,然后定义新的字段nomAmount,nomAmount用于记录标准化后的Amount字段。
数据标准化处理流程为:
1)使用pandas函数加载creditcard.csv数据集数据。
2)使用StandardScaler标准化函数将Amount字段值进行归一化处理。
3)将class字段值赋予标记字段y。
4)将数据集中V1~V28字段值及nomAmount值赋予数据集x。
5)将数据集x和标记字段y随机分配成训练数据集和测试数据集。
1.2 基于改进的SMOTE+ENN混合采样的不平衡数据处理
1.2.1 降采样
之前遇到的机器学习问题,使用的数据集中黑白样本基本都是一个数量级,常见的分类算法都可以在这种情况下正常工作。但是也有一类问题,黑白样本的比例完全失衡,反欺诈领域的数据就是这样,黑样本甚至不到白样本的1%。这个时候常见的分类算法会偏向数据量占绝对优势的一方。为了避免这种情况发生,人们提出了降采样。所谓的降采样,就是从数据量占优势的数据集中随机选取一定数量的样本,通常选择的数量与数据量小的样本数量相当。在这次选取的数据集中,欺诈数据属于黑样本,数量非常稀少,仅有数百个;正常交易的数据属于白样本,数量达到了近30万,本文随机从白样本选择与黑样本数量相同的白样本,这样就得到了黑白样本均衡的数据集[16]。降采样获得黑白样本均衡的数据集流程为:
1)获取黑样本的数量以及对应的索引。
2)获取白样本对应的索引,并随机选取与黑样本数量相同的白样本索引。
3)使用ENN降采样技术从整数或一维数组里选取内容,作为新的白样本。
4)将黑样本和随机选择的白样本重新组合成新的样本集合。
5)从新的样本随机分配成训练数据集和测试数据集。
1.2.2 过采样
解决黑白样本不均衡的问题还有一种方式叫做过采样。与劫富济贫的降采样相反,过采用保留数量占优势的样本,通过一定的算法,在数量较少样本的基础上生成新样本。在这次数据处理中,保留白样本,通过一定的算法,在原有黑样本的基础上生成新的黑样本,最终形成的样本同样可以达到黑白样本均衡[17]。过采样获得黑白样本均衡的数据集流程为:
1)随机选定n个少类的样本A。
2)使用SMOTE过采样技术对少类样本A再找出最靠近它的m个少类样本B。
3)任选最邻近样本B中的m个少类样本C,在样本B和样本C上任选一点,这点就是新增的数据黑样本。
4)将黑样本和白样本重新组合成新的样本集合。
5)从新的样本随机分配成训练数据集和测试数据集。
1.2.3 基于改进的SMOTE+ENN混合采样
对于不平衡数据的处理方法主要通过降采样和过采样来对数据进行平衡。过采样方法会增加冗余数据,可能存在过拟合问题,会导致数据分布不合理甚至会脱离真实情况。降采样方法会导致数据集中有用的数据信息可能丢失。本文将2种采样方法结合起来,利用各自的优点提出一种基于改进的SMOTE+ENN的混合采样方法。使用SMOTE过采样方法通过增加随机噪声方式来改善过拟合问题,但该方法没有考虑周边样本的情况,很容易造成无用的信息或者噪声,导致类内重叠增大。因此本文引入KB-mean聚类算法对SMOTE方法进行改进,提升其对少数类样本的采样性能。通过将过采样和降采样两者结合起来,首先使用ENN降采样对多数类进行降采样,然后使用改进后的SMOTE过采样对少数类进行过采样,可以有效地在均衡数据的同时消除掉过多的类间重叠样本[18]。基于改进的SMOTE+ENN混合采样流程如图3所示。
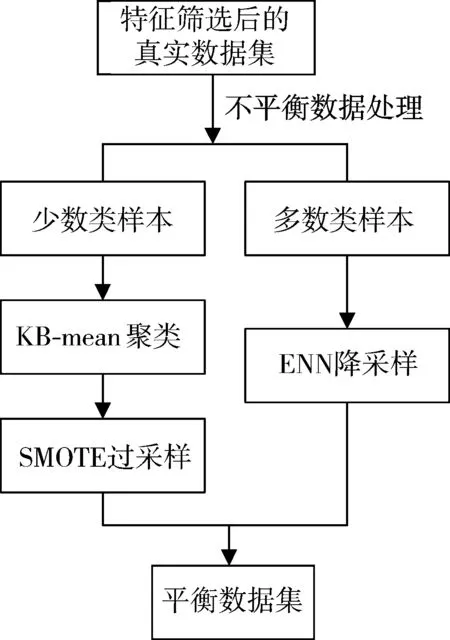
图3 基于改进的SMOTE+ENN混合采样算法流程图
基于KB-mean聚类算法的SMOTE过采样算法方法,首先使用KB-mean聚类算法对少数类样本进行聚类处理,然后根据聚类的区域进行相关数据的插入来增加样本数据,这样可以很好地解决边界模糊问题。主要处理步骤如下:
1)采用KB-mean聚类算法对少数类样本进行聚类处理,获得少数类样本数据中各簇的分布情况。
2)计算每个簇的簇心,每一个聚类的簇心为{a1,a2,…,an}。
3)在簇心与簇内样本的连线上进行人工样本生成。新插入数据公式为:
Xnew=ai+rand(0,1)×(X-ai) ,i=1,2,…,N,X∈ai
(1)
其中,Xnew为新插入的样本,ai为簇心,X是以ai为簇心聚类的原始样本;rand(0,1)表示0与1之间的随机数。
1.3 基于改进的SMOTE+ENN混合采样和XGBoost算法的信用卡欺诈检测模型
1.3.1 XGBoost分类算法
XGBoost分类算法是梯度提升决策树(Gradient Boost Decision Treet, GBDT)算法的一种串行集成算法。其基学习器通常选择决策树模型,通过不断迭代生成新树学习真实值与当前所有树预测值的残差,将所有树的结果累加作为最终结果,以此获取尽可能高的分类准确率[19]。
XGBoost算法将模型的表现与运算速度的平衡引入目标函数,在求解目标函数时对其做二阶泰勒展开,以此加快求解速度,减少模型运行时间;同时引入正则化控制模型复杂度,避免过拟合[20]。
假设有n个样本和m个特征的样本集D={(xi,yi|xi∈Rm,yi∈R)},其模型预测值为:
(2)
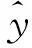
检测模型的目标函数为:
(3)
其中,θ={f1,f2,…,fk};l指损失函数;Ω指正则化项。
目标函数包含2个部分,即损失函数和正则化项。第1部分的自身损失函数使用泰勒式展开,使用一阶导数和二阶导数进行优化,以提高速度和准确率[21]。在第t步迭代优化目标函数时,在现有t-1棵树的基础上添加1棵最优化的ft,损失函数变为:
(4)
其中,gi为损失函数的一阶导数;hi为损失函数的二阶导数。
第2部分是正则化函数,通过正则化惩罚项来降低过拟合的风险[20]。正则化函数为:
(5)
其中,T为每棵树叶子节点的个数;w为叶子权重;Υ与λ为惩罚系数。
1.3.2 信用卡欺诈检测模型构建
基于改进的SMOTE+ENN混合采样和XGBoost算法的信用卡欺诈检测模型是一种混合采样的XGBoost信用卡欺诈检测模型,并通过对XGBoost算法中的参数进行优化来提升检测模型的性能,模型的检测过程如图4所示。
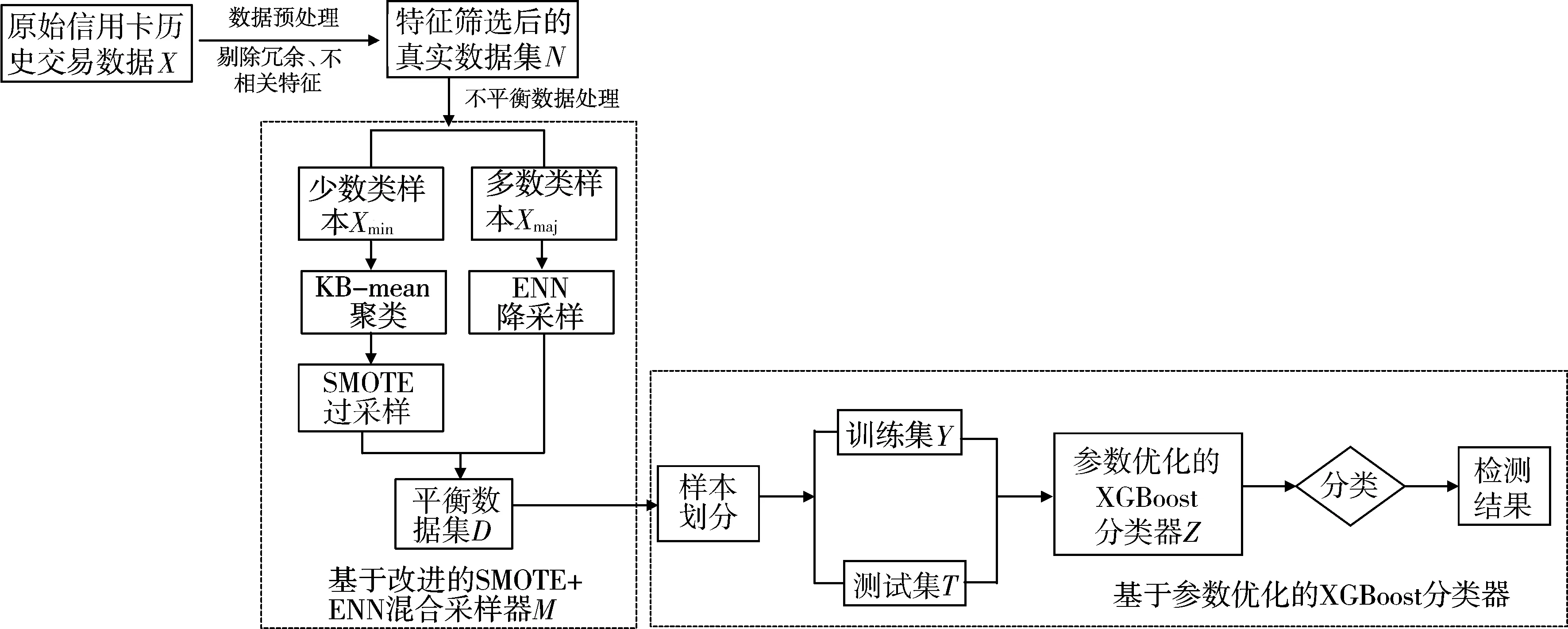
图4 基于改进的SMOTE+ENN混合采用和XGBoost分类算法的信用卡欺诈检测流程
针对信用卡欺诈检测效率低、准确度不高情况,本文采用基于XGBoost的信用卡欺诈检测模型进行分类。XGBoost是一种集成学习方法,其基本思想是将多个具有较低分类准确率的树模型进行组合得到一个准确率很高的模型。XGBoost在代价函数中增加了用于控制模型复杂度的正则项,可以防止信用卡交易欺诈检测时过拟合问题[12]。同时为了使XGBoost预测模型能够达到很好的检测效果,采用网格调参的方式对XGBoost算法中各参数进行优化。针对信用卡交易数据黑白样本极不平衡情况,本文选用改进的SMOTE+ENN混合采样模型对不平衡数据进行处理,来解决由不平衡数据带来的过拟合及噪声问题。
假定原始Credit Card Fraud Detection数据集数据集为X,其中通过标准化数据预处理的真实数据集为N,多数类的正常交易样本集为Xmaj,少数类的欺诈交易样本集为Xmin,经过改进的SMOTE+ENN混合采样器为M,混合采样处理后的平衡数据集为D,训练集为Y,测试集为T,优化后的XGBoost分类器Z。基于改进的SMOTE+ENN混合采样和XGBoost算法的信用卡欺诈检测模型的算法步骤为:
1)通过对原始数据集X进行数据标准化预处理,剔除冗余不相关特征,得到特征筛选后的真实数据集N。
2)将真实数据集N按照样本类型分成少数类样本Xmin,多数类样本Xmaj。
3)使用KB-mean聚类算法对少数类样本Xmin进行聚类处理,得到聚类样本Xminkb。
4)使用SMOTE过采样对聚类样本Xminkb进行过采样处理,得到过采样样本Xminkbsmote。
5)使用ENN降采样对多数类样本Xmaj进行降采样处理,得到降采样样本Xmajenn;
6)将以上混合采样的降采样Xmajenn和过采样Xminkbsmote数据进行组合得到平衡数据集。
7)对平衡数据集D进行样本划分,随机划分成训练集Y和测试集T。
8)采用网格调参的方式对XGBoost算法中各参数进行优化,得到分类器Z。
9)使用分类器Z在训练集Y上训练,获得模型数据。
10)使用模型数据在测试集T上进行预测,得到预测结果。
2 实验与结果分析
2.1 实验数据集
实验选取了从Credit Card Fraud Detection数据集中284807条交易数据(其中492条欺诈数据)作为实验数据来源[23]。将样本集按照随机分配因子从0.1~0.9分配训练样本集和测试样本集共9份。采用九折交叉验证法重复实验验证9次,最后对9次实验结果采用计算平均值来评估检测模型的检测能力,具体如表1所示。
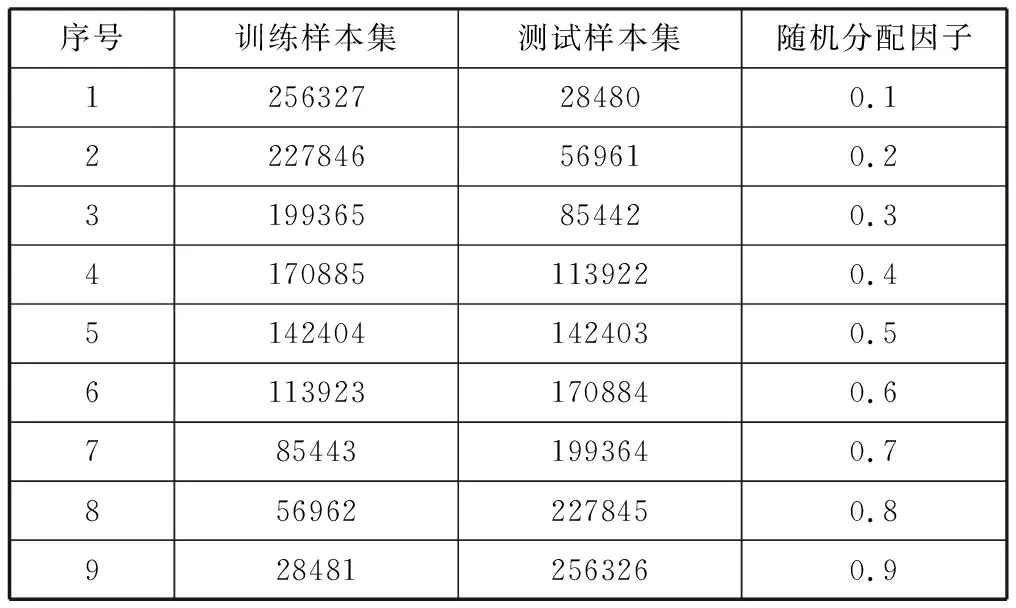
表1 训练数据、测试数据样本数
2.2 评价指标
在对信用卡欺诈行为进行检测时,可能出现以下4种情况,如表2所示。在实验中,T表示信用卡正常使用行为,M表示信用卡欺诈行为[24]。
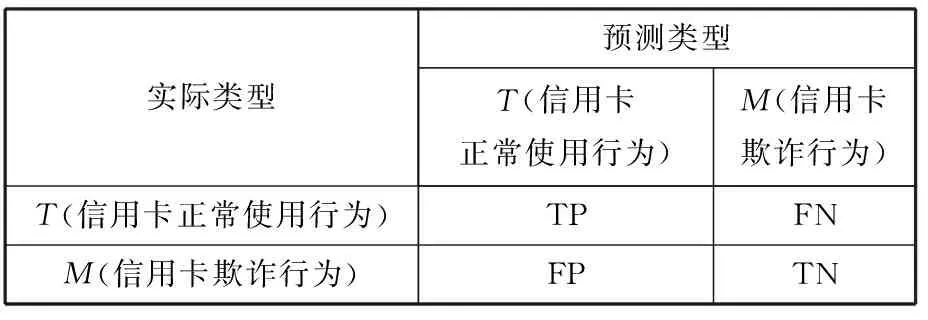
表2 信用卡欺诈检测判别表
在表2中,TP表示预测当前是信用卡正常使用行为,实际上也是信用卡正常使用行为;FN表示预测当前是信用卡欺诈行为,实际上是信用卡正常使用行为;FP表示预测当前是信用卡正常使用行为,实际上是信用卡欺诈行为;TN表示预测当前是信用卡欺诈行为,实际上是信用卡欺诈行为。
对于传统的分类算法,一般采用特定度、灵敏度作为评价指标,然而对于不平衡数据集,用特定度、灵敏度、准确度来评价分类器的性能是不准确的。本实验中对于不平衡数据分类采用准确率、精准率、召回率、F1和AUC作为分类器性能好坏的评价指标[25]。
1)准确率:
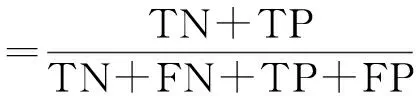
2)精准率:
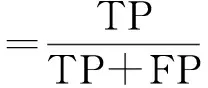
3)召回率:
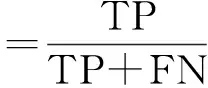
4)F1:表示一种综合考虑信用卡欺诈行为检测的查全率和查准率的指标,综合衡量信用卡欺诈分类性能指标[26],即:
5)AUC:表示不平衡数据分类问题中最经常采用的度量指标,在衡量XGBoost算法在不平衡数据上的整体分类性能。本次实验中采用量化的AUC指标来衡量,AUC指标越接近于1,则反映出分类器的分类效果越好[27]。
2.3 实验结果与分析
2.3.1 未进行不平衡数据处理实验分析
将不平衡数据集进行标准化处理后未采用任何不平衡数据处理技术进行输出,直接使用XGBoost分类算法、朴素贝叶斯分类算法、多层感知机、随机森林算法、极限学习机这5种分类算法对上述随机分配的9类训练集进行训练生成分类器,最后对随机分配的9类测试集进行检测[28],整个检测系统的TP、FP、TN、FN、准确率、精准率、召回率、F1值、AUC值实验结果如表3所示。

表3 未进行不平衡数据处理下不同分类算法实验结果
由表3可知,在没有对不平衡数据进行任何处理的情况下,5种分类算法对信用卡欺诈数据检测出来的5个评价指标准确率、精准率、召回率、F1值、ACU值表现的性能也有所不同。因正向数据偏多,准确识别正向数据的概率都能准确识别出来,因此准确率都相差不大。但从精准率、召回率、F1值、AUC值4个评价指标综合考虑,XGBoost算法的信用卡欺诈检测方法要明显优于其他4种分类算法检测方法,精准率约为0.93,召回率约为0.77,F1值约为0.84,AUC值约为0.88。结果表明,使用XGBoost算法相对其他2种分类算法更能够准确检测出信用卡欺诈行为。
2.3.2 多种不平衡数据处理方法实验分析
表3实验结果为对不平衡数据未进行任何处理得到的实验结果,从实验结果可以看出,召回率、F1值、ACU值性能不是很理想。因此对不平衡数据进行降采样、过采样、SMOTE+ENN、SMOTE+Tomeklink、改进的SMOTE+Tomeklink、改进的SMOTE+ENN这6种不平衡数据处理方法进行数据不平衡处理,然后使用XGBoost分类算法对上述随机分配的9类训练集进行训练生成分类器,最后对随机分配的9类测试集进行检测,整个检测系统的TP、FP、TN、FN、准确率、精准率、召回率、F1值、AUC值实验结果如表4所示。
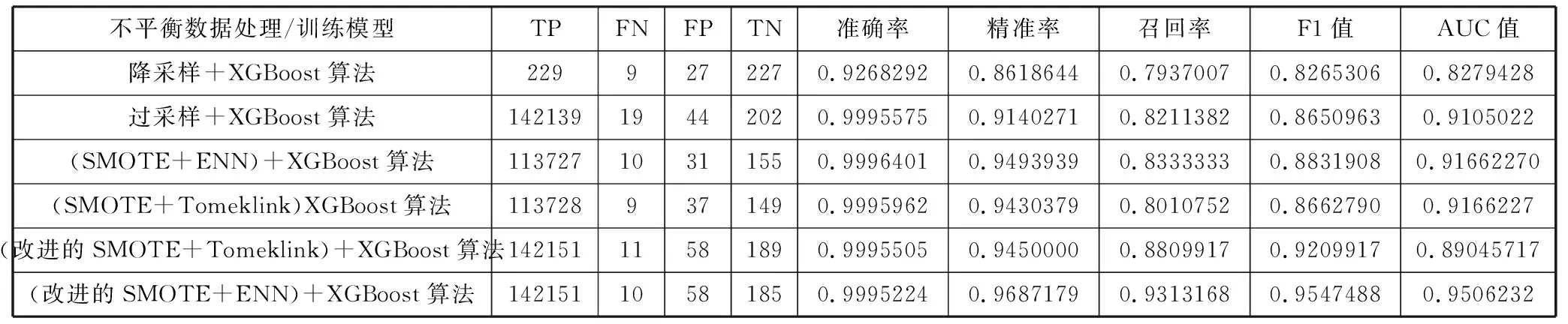
表4 不同不平衡数据处理方法下XGBoost分类算法实验结果
从表4实验结果可以看出,采用改进的SMOTE+ENN混合采样的不平衡数据处理方法得到的数据集输入到XGBoost分类器中得到的检测效果要比其他单一采样或者组合采样的检测效果更佳,该采样方法的实验结果准确率约为0.99,精准率约为0.97,召回率约为0.93,F1值约为0.95,AUC值约为0.95。通过对不同不平衡数据处理方法的数据集进行各项检测评价指标对比分析,基于改进的SMOTE+ENN采样的不平衡数据处理技术比传统的单一降采样、过采样及单纯的组合采样下的不平衡数据处理方法在检测信用卡欺诈行为中更能体现优势。基于改进的SMOTE+ENN混合采样不平衡数据处理技术不仅提高了信用卡欺诈行为不平衡数据的区分度,还提高了不平衡数据的计算性能和准确性。
2.3.3 基于改进的SMOTE+ENN混合采样的不同分类算法实验分析
从表4中可以看出采样改进的SMOTE+ENN混合采样的不平衡数据处理方法对于信用卡欺诈行为的检测效果更佳。本文再将其处理后的平衡数据集输入到XGBoost分类算法、朴素贝叶斯分类算法、多层感知机、随机森林算法、极限学习机不同分类器中训练,验证本文提出的基于改进的SMOTE+ENN混合采样的XGoost算法的有效性和准确性,实验结果如表5所示。

表5 改进的SMOTE+ENN混合采样下不同分类算法实验结果
从表5实验结果可以看出,基于改进的SMOTE+ENN混合采样和XGoost算法的信用卡欺诈检测方法比其他4种分类算法在准确率、精准率、召回率、F1值、AUC值5种评价指标上表现的更佳。验证了本文提出的基于改进的SMOTE+ENN混合采样的XGoost算法的有效性和准确性,更能准确有效地检测出信用卡欺诈行为,能为用户提供很好的监测预警服务。
3 结束语
本文主要聚焦在信用卡欺诈行为检测这一非常具有挑战性的机器学习问题上,对不平衡数据处理技术、机器学习分类技术等方面研究。以Credit Card Fraud Detection为数据集,针对信用卡欺诈的检测技术,使用特征提取方法为标准化,以及基于标准化基础上的降采样、过采样、SMOTE+ENN、SMOTE+Tomeklink、改进的SMOTE+Tomeklink、改进的SMOTE+ENN对不平衡数据进行处理,后将数据集输入到XGBoost算法、多层感知机、朴素贝叶斯算法、随机森林算法、极限学习机进行训练。经过对比发现,当使用相同的特征提取方式时,基于改进的SMOTE+ENN混合采样的XGBoost算法的信用卡欺诈检测模型总体表现优于其他4种分类算法和5种采样方法,检测模型的准确率约为0.99,精准率约为0.97,召回率约为0.93,F1值约为0.95,AUC值约为0.95。此检测方法可显著提高金融机构对信用卡欺诈行为的检测效率,同时给用户和金融机构提供很好的预警效果。
