基于多任务学习的电子病历实体识别方法
2022-09-24陈钰枫徐金安张玉洁
于 鹏,陈钰枫,徐金安,张玉洁
(北京交通大学计算机与信息技术学院,北京 100044)
0 引 言
命名实体识别(Named Entity Recognition, NER)是信息抽取中最主要的子任务,其目的是从非结构化的文本句子或段落中识别出特定类型的实体词。命名实体识别的准确度往往对下游任务有很大影响,包括实体关系抽取、知识图谱构建等。近年来,由于社会各行业信息化的蓬勃发展,自然语言处理的研究也逐渐延伸到专业领域中,医疗领域的命名实体识别成为了业界的热门话题。医疗领域中又以电子病历(Electronic Medical Records, EMR)数据规模最大、数量最多,成为了医疗信息处理的重点。电子病历是患者就医过程中产生的有关个人病情、病机、既往病史等信息的整合,还包括就诊过程中接受的检查诊断、治疗等医疗过程的信息,是患者最重要的健康档案。电子病历对教学、科研及医疗机构管理都有着重要的作用,同时也广泛用于研究疾病规律,以及作为处理医疗纠纷的法律依据。电子病历中的信息往往以非结构化形式存在,对电子病历的实体识别任务主要包括从数据中抽取主诉症状、诊断信息、检查方法、药物信息、身体部位等关键性词语。本文主要研究中文电子病历文本的实体识别方法。
目前中文电子病历实体识别的难点主要体现在:
1)专有名词问题。电子病历数据中往往包含着大量的领域名词和专业术语,包括医学检查、疾病、解剖部位、医药等相关名词。例如“奥沙利铂200毫克,希罗达1.5日二次”中的“奥沙利铂”和“希罗达”均为药品名称。如果这些词尚未在数据集中出现或出现频次较少,则模型可能无法成功识别。
2)一词多义问题。同样的名词在不同领域中可能存在一词多义的现象。例如“腿部有小处淤青”中的“腿”为解剖学术语,应当作为实体词而被抽取,但数据中如果出现“鸡腿”或“鸭腿”,则“腿”字不需要做实体切分,因为它是普通名词而非解剖术语。
3)非结构化和用语规范问题。电子病历多为医生坐诊时的书写笔记,因此存在非结构化的特点,其表达、句式往往较为随意而缺乏严谨性。口语化表达较为普遍,同时存在大量的简写、缩写等形式。比如例句“伴轻度发烧,精神可,服烷胺片一日三次”中,“伴”“可”“服”分别代表“伴随”“尚可”和“口服”。这些非规范书写形式也为电子病历的实体识别带来了困难。
电子病历实体识别的另一个困难是语料库存在不同实体类别数量差距过大的情况,进而会造成模型效果的下降,因此需要解决样本不平衡问题。由于临床电子病历数据的特点,需要设计低偏差、样本类内分布均匀的算法。
针对电子病历实体识别的难点,本文设计一种联合实体识别和分词的多任务训练方法,并提出均衡样本过采样来扩充语料库。实验结果显示本文提出的模型和方法在电子病历数据上的实体识别性能较基线模型有了较大提升。
1 相关工作
1.1 命名实体识别
命名实体识别的研究已有数十年的历史,早期的命名实体识别方法是基于规则和词典匹配的方法,包括正向最大匹配、逆向最大匹配和双向匹配3种方法;后来出现了基于统计的实体识别方法,包括隐马尔科夫模型和条件随机场[1]。近几年,由于计算机的迅速普及和硬件成本的降低,基于深度学习的神经网络命名实体识别方法得到广泛应用[2],其中Bi-LSTM-CRF最具代表性[3-5]。Zhang等人[6]基于循环结构设计出了Lattice-LSTM结构用于实体识别。2018年出现了以Elmo[7]、BERT[8-9]为代表的预训练模型。通过在大规模语料上无监督学习,并微调到下游任务以提升性能。王得贤等人[10]联合字词级别信息利用注意力机制捕捉词语内部表示,在法律文书文本上取得较好效果。近年来出现很多迁移方法,例如迁移阅读理解任务来做实体识别的方法[11]以及利用变分编码器来捕捉低频次实体的方法[12]。
面向医疗电子病历的实体识别研究一直是近年来的热门话题,其包括术语抽取以及疾病、药物或症状抽取等任务。Jia等人[13]结合实体识别和无监督语言模型方法,实现医疗文本的跨领域NER任务,在BioNLP13PC、BioNLP13CG生物医疗语料库上效果显著。Schneider等人[14]利用多国语言BERT在临床记录和生物医学文献2类数据上做微调迁移训练,在小语种SemClinBr临床数据集上达到了更高的F1值。赵耀全等人[15]利用凝固度算法进行新词发现,使用Lattice-LSTM对字符和所有关联词联合编码,在自建数据集上取得了很好的效果。罗熹等人[16]结合一个包含多种临床实体的领域词典来抽取位置标签,性能表现出了明显的提升。张旭等人[17]融合外部词典构造词特征,取得了不错的效果。
1.2 多任务学习
多任务学习是同时具有多个损失函数的模型,在训练不同任务的过程中建立复杂的数学模型,并通过有效的归纳偏置(Inductive Bias)来搜索最优解。多任务学习将多个相似的任务并行训练,通过共享网络层捕捉不同任务的全局信息表示来提高泛化性,从而构建出更通用的向量空间。研究发现多任务的共享层可以有效地消除不同任务中的噪声信息,构建出更平滑的模型空间,这极大地缓解了模型的过拟合问题,增强了模型鲁棒性。近年来多任务学习在很多研究领域都表现出了较好的性能[18-20]。Peng等人[21]利用多任务学习方法实现领域迁移序列标注,验证了多任务学习的有效性。Chen等人[22]设计出融合对抗机制的多任务学习框架来实现多标准分词,在8个不同标准的分词语料中取得较好的效果。多任务学习用于生物医学的跨领域实体识别也涌现了很多成果。Zhao等人[23]提出了一种融合显式回传策略(Explicit Feedback Strategies)的多任务学习框架,将医学实体识别和实体标准化进行联合训练,在BC5CDR任务语料和NCBI疾病语料上的实验取得了较好的结果。Li等人[24]提出基于笔画的Elmo预训练模型生成上下文向量表示,使用多任务学习在CCKS17和CCKS18数据集上取得了更高的F1值。
虽然目前在电子病历NER任务上已经涌现出很多成果,并取得不错的实验结果,但由于电子病历语料的特点,已有模型依然不能很好地识别数据中的领域术语,在多义词和表达不规范的情况下也难以正确判断实体类型。造成这一问题的原因是模型在电子病历NER中容易受噪声、错误标注样本等因素影响,难以收敛到最优值。因此如何构建出泛化性强、鲁棒性高的模型成为解决这些问题的关键。
对此本文提出联合电子病历实体识别和中文分词的多任务学习方法,利用分词作为辅助任务提升实体识别的性能。本文中的分词语料库也来自医疗领域,因此与电子病历存在较强的相关性,适合用作辅助任务。本文为2项任务分别设置私有层来捕捉任务局部信息,同时加入共享层捕捉它们的全局信息。在训练时共享层可以编码各任务的局部特征表示,同时提取不依赖任务的通用特征,降低对噪声等负面因子的关注度,以达到优化任务性能的目的。
1.3 样本不平衡解决方法
样本不平衡会给模型训练以及预测带来很大影响,尤其在文本分类、情感分类、实体识别等任务中。传统样本不平衡的解决方法有欠采样(Under-sampling)、过采样(Over-sampling)和人工少样本过采样(Synthetic Minority Over-sampling Technique, SMOTE)方法。欠采样方法通过删除样本来缩减数量多的类别以均衡样本分布;过采样则是增加数量少类别的样本数缓解问题;SMOTE方法通过生成小类别的近邻样本来产生新数据,增加数量的同时也能保持样本的均匀分布。Han等人[25]提出了改进的SMOTE方法,通过限定生成样本的空间来解决样本重叠问题。
由于本文数据具有领域性强、无结构和无规范等特点,上述方法可能无法提升效果。因此本文提出均衡过采样数据增强方法,使用K近邻算法优先选择较远样本过采样,以防止样本分布偏差过大。本文将在第3章通过实验验证算法的有效性。
2 基于多任务学习的实体识别模型
2.1 序列标注定义
在本文中,命名实体识别和分词任务都使用序列标注来处理,给定长度为N的输入序列I=(i1,i2,i3,…,iN),输出等长的序列O=(o1,o2,o3,…,oN)。其中输出序列为规定的标签序列。一般是将待识别的文本指定为输入序列,将句子中每个字符的实体标签指定为输出序列。序列标注方法广泛应用于分词、实体识别、词性标注、语义角色标注等任务中。标签格式方面,在命名实体识别中标签采用(B,I,O)类型,其中B代表实体的起始字符,I代表实体词内除起始字符外的其它字符,O代表不属于任何实体词的字符。在分词中标签采用(B,I)类型,其中B代表词的起始字符,I代表除起始字符外该词的其它字符。神经网络模型接收输入序列,通过编码器生成向量表示,再通过解码器解码后输出标签序列。
2.2 模型框架和算法
本文的模型整体框架如图1所示,该模型使用Bi-LSTM网络作为多任务的私有层来实现局部特征编码,基于自注意力机制(Self-Attention Mechanism)[26]设计共享层全局编码器,并借助注意力机制在Seq-to-Seq翻译模型中的原理,提出通用特征增强机制来准确地捕获通用特征中有用的信息,同时使用均衡样本过采样方法来解决实体不平衡问题。
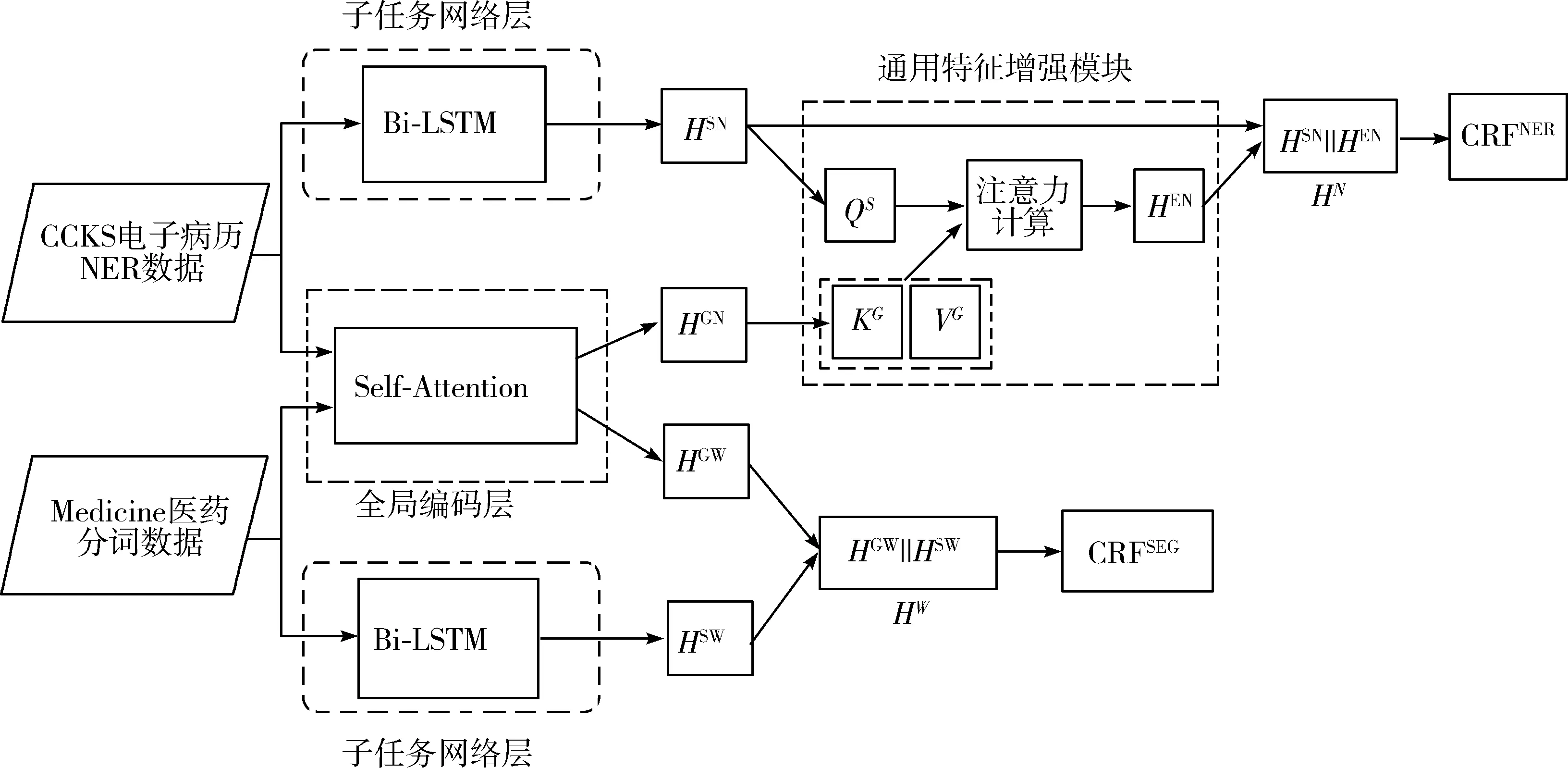
图1 多任务学习系统整体框架
2.3 子任务网络层
子任务网络层相当于一个独立的模型,其作用是构建特征子空间,是多任务模型的私有层。子任务层具备较强的针对当前任务编码的能力,能够在当前任务下生成深层语义关系表示。每个子任务层都具有相同的模型结构,分别以不同任务的语料作为输入。首先通过Embedding映射来实现字符级别的向量表示,随后使用Bi-LSTM对输入向量做上下文编码以获取长短期记忆表示,最后将双向隐层特征拼接后输出得到子任务编码。
2.3.1 字符Embedding模块
数据集中的内容都是文字文本,无法直接被计算机处理。因此设计出字符Embedding模块,将文本中的字符首先转换为高维One-Hot向量表示,随后映射到一个低维、稠密的向量空间中。
2.3.2 融合上下文信息的Bi-LSTM网络
在医疗领域数据中存在很多专有名词,这些专有名词需要深层理解上下文语义才能准确识别。且部分未登录实体需要依赖前后距离较远的信息才能准确预测,一词多义情况也需要借助上下文来准确推测。因此如何有效地编码上下文信息就变得较为重要。LSTM网络的长短时记忆特性可以帮助有效地获取文本句子中的长距离依赖信息,在过去很多研究成果中扮演着重要角色。LSTM的前向计算过程如下:
ft=σ(Wf·[ht-1;xt]+bf)
(1)
it=σ(Wi·[ht-1;xt]+bi)
(2)
ot=σ(Wo·[ht-1;xt]+bo)
(3)
(4)
(5)
ht=ot·tanh(Ct)
(6)
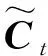
本文采用双向LSTM神经网络来进行任务内局部编码,对于每个方向的LSTM都使用上述公式计算,将双向的隐层输出拼接,并做线性变换和激活得到子任务向量表示。具体过程如下:
(7)
(8)
ht=[htf;htb]
(9)
(10)
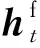
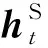
2.4 基于自注意力机制的全局编码器
注意力机制通过权重分配策略,使模型对信息的不同方面给予不同关注度,因而可以有效地捕捉特征。多头自注意力机制[26]将向量映射到多个不同的子空间,可以有效地从不同方面对序列编码。本文提出多头自注意力机制全局编码器作为多任务模型的共享层,将所有任务的语料作为输入,在训练的过程中可以从不同领域数据中提取出它们潜在的共有信息,并消除噪声等信息。
全局编码器的输入为字符Embedding与其位置编码(Positional Encoding)[8]的向量和,得到融合位置编码信息的输入序列E={e1,e2,e3,…,eN}。将E按注意力头切分,通过线性变换映射为查询矩阵Q,键矩阵K和值矩阵V。使用多头自注意力机制计算注意力加权和,如公式(11):
(11)
其中,d为单个注意力头向量的维度。
将多个注意力头的结果拼接得到全局编码器的最终输出zn,如公式(12):
(12)
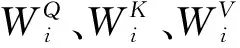
最后使用前馈神经网络将多头注意力输出做线性变换和激活,具体过程如公式(13):
(13)
其中,W1、W2、b1、b2为可学习参数,ReLU是激活函数。
2.5 通用特征增强机制
全局编码器可以有效地提取不依赖于任务的全局特征,然而全局特征中并非所有的信息都是必要的,不相关的信息会造成模型负迁移。由于在共享层中同时混入了多个任务的数据,特征信息会十分冗杂,模型搜索空间也随之变大,模型会更难以收敛到最优解。为解决这一问题,本文尝试利用注意力机制帮助模型选取对实体识别作用大的信息并过滤无关信息。通过调整权重帮助模型关注重要的部分,忽略不重要的部分,使模型更快、更有效地收敛,进一步增强模型的泛化能力。具体做法是,将实体识别子任务隐层编码输出HSN按注意力头切分,并通过线性变换得到QS矩阵;同时将全局编码器的输出HGN按注意力头切分,并通过线性变换得到KG、VG矩阵,将上述矩阵进行注意力计算,过程如下:
(14)
其中,d为单个注意力头向量的维度。
将多个注意力头的结果拼接得到注意力编码输出,如公式(15):
(15)
使用前馈神经网络做线性变换和激活,得到通用特征增强表示HEN。将HEN与子任务输出向量HSN拼接得出融合通用特征的实体识别任务编码输出HN。
对于不使用通用特征增强机制的分词任务,通过将全局编码器的隐层输出HGW与分词子任务的隐层输出HSW拼接,得到分词任务编码输出HW。
2.6 CRF解码层
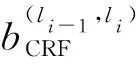
(16)
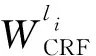
(17)
则公式(16)变为:
(18)
对等式两边取对数,则似然函数的计算公式为:
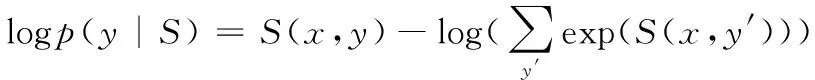
(19)
由于本文使用实体识别和分词任务联合训练,因此设置2个目标函数优化模型,实体识别目标函数如公式(20)所示,分词目标函数如公式(21)所示。
(20)
(21)
其中,ΘGLB代表全局编码器的参数,ΘNER代表NER子任务相关的参数,ΘSEG代表分词子任务相关的参数。
模型训练时的损失需要包含2个任务的对数似然损失以及L2正则化损失,并设置权重因子α、β权衡不同的损失项,模型总体损失公式为:
L=αINER+(1-α)ISEG+βLL2_Loss
(22)
其中,INER和ISEG分别代表实体识别和分词任务的对数似然损失,分别使用公式(20)、公式(21)来计算,IL2_Loss为相对于参数的L2正则化损失。
2.7 均衡过采样数据增强方法
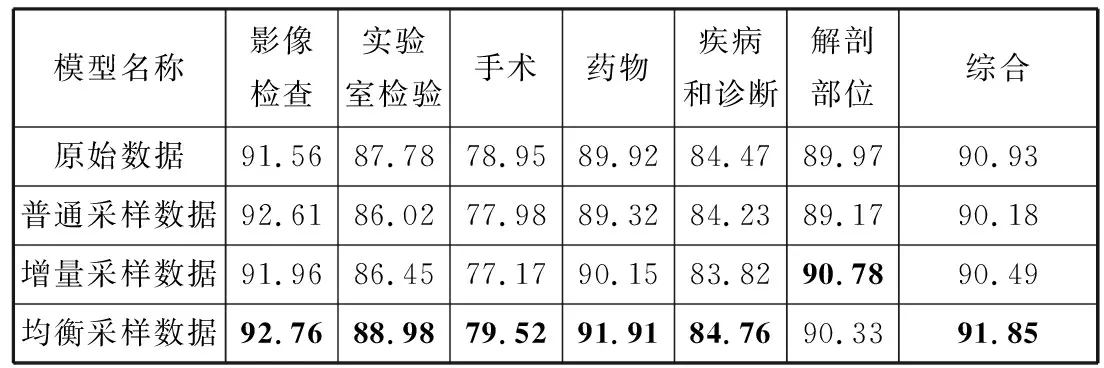
针对临床电子病历数据领域名词多、多义词普遍和缺乏规范性等特点,本文提出均衡样本过采样方法。该方法基于“远距离样本优先采样”思想,认为远距离样本包含语料中频次低的词语或语法表达,因此对这些样本过采样会提升模型对它们的识别能力。具体做法是,首先使用GloVe[27]在数据集中训练字符向量,Glove融入了字的局部上下文特征和全局统计信息,比Word2Vec[28]更能够生成语义更丰富的向量表示;将样本的字符向量做加和得到样本向量,并使用K近邻法(K-Nearest Neighbor, KNN)[29]计算到其它样本的最小距离,最后对最小距离值较大的样本做上采样。本方法既能扩充少样本同时也能防止类内样本分布偏差过大对模型造成影响。具体过程如算法1所示。
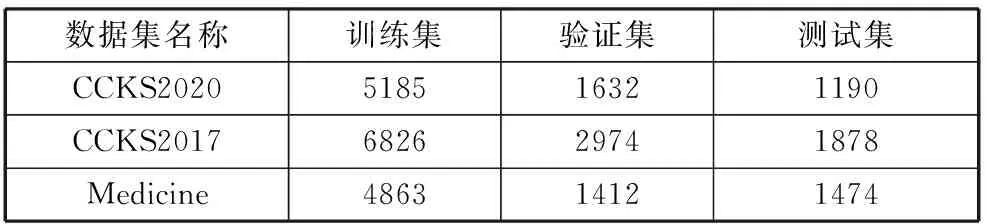
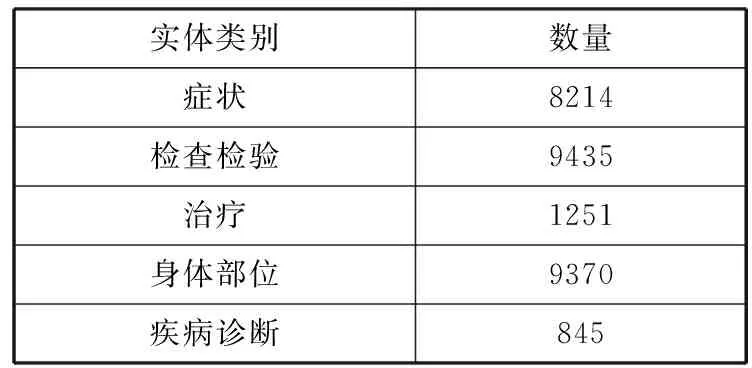
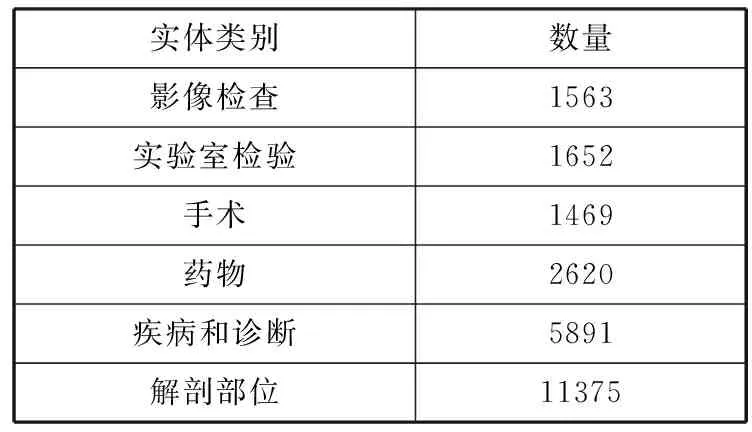
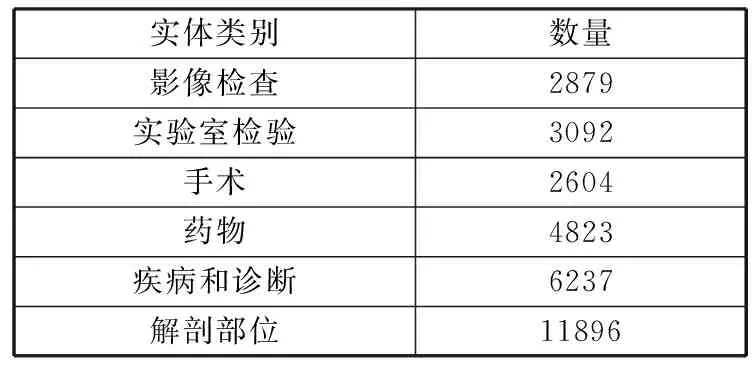
算法1均衡类内样本过采样算法
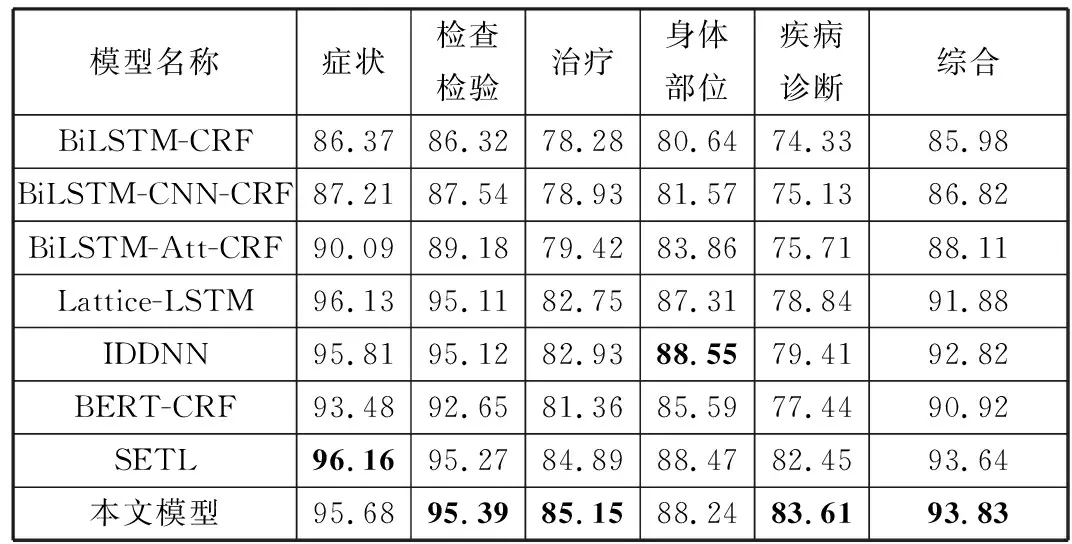
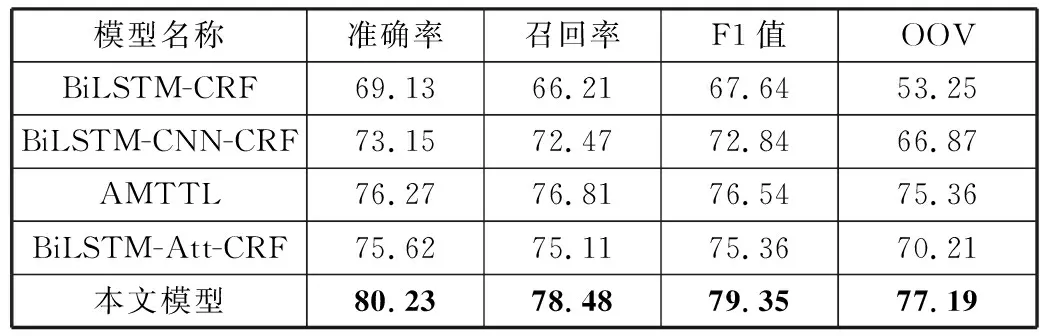
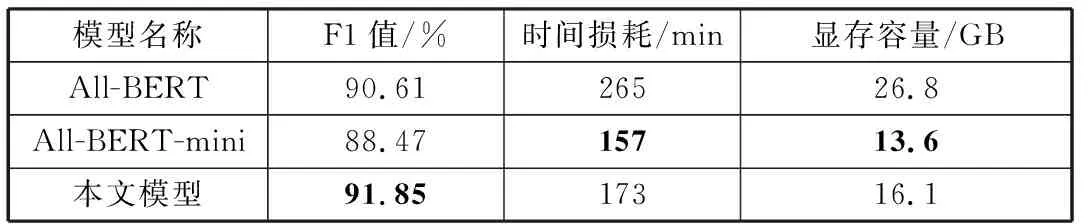
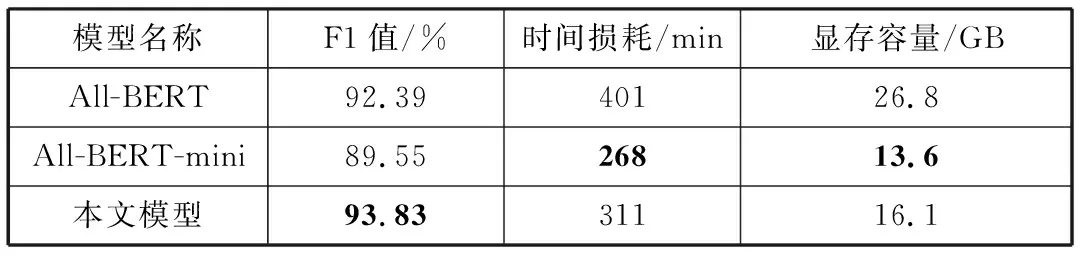
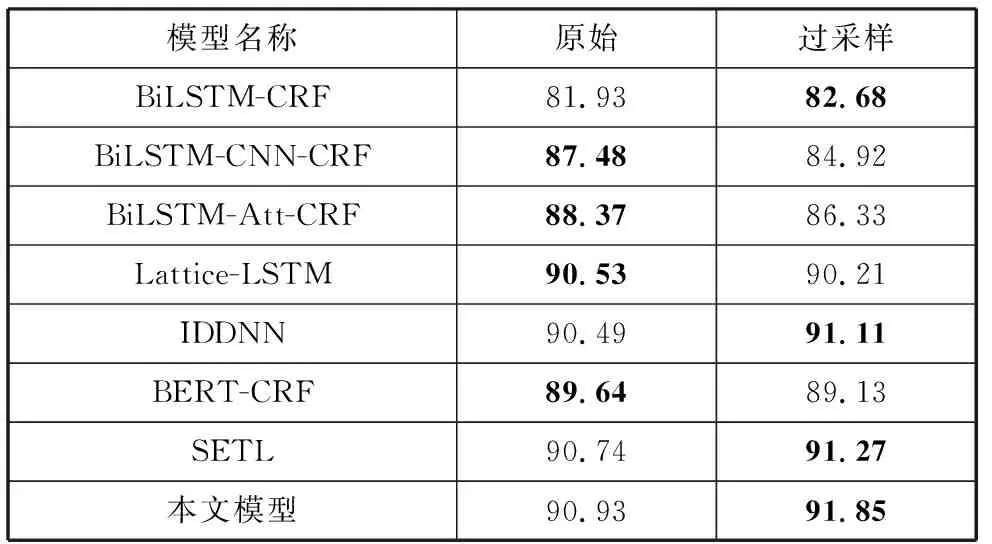
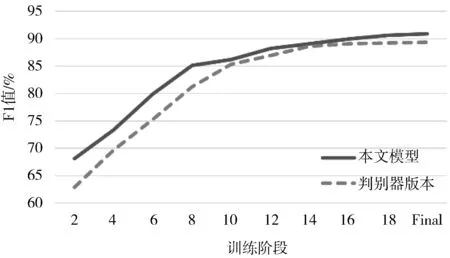
输入:同属实体类型t的样本集合D={d1,d2,d3,…,dT},GloVe语言模型,样本增量N(N 输出:均衡过采样后的样本集合S 在D上训练Glove语言模型得到GLM V←GLM(D) #将所有样本映射为向量,并输出到集合V fori←1 toTdo disi←Euclidean-distance(vi,KNN(vi,V)) #KNN算法输出V中距离与vi最近的向量(vi除外),Euclidean-distance计算向量的欧几里得距离 将disi加入到列表DIS中 end for forj←1 toNdo 取DIS中最大值并在D中找到对应样本aj 置DIS中最大值为0 将aj加入到列表A中 end for 对A中的所有样本过采样,得到A′ 将A′同D合并,得到S并输出 本文使用CCKS2017、CCKS2020和Medicine这3个语料库进行实验。其中CCKS2017和CCKS2020都是全国知识图谱与语义计算大会提供的电子病历实体识别评测数据集;Medicine医药分词数据集来自“好大夫在线”医疗平台的医学论坛,采用具有丰富从医经验的领域内专家按照严格规范进行人工标注。本文对数据集进行了统计,结果如表1所示。 表1 数据集统计 其中CCKS2017和CCKS2020数据集标签为(B,I,O)类型。CCKS2017包含了5种实体,分别是“症状”“身体部位”“治疗”“疾病诊断”和“检查检验”。CCKS2020包含了6种实体,分别是“影像检查”“实验室检验”“手术”“药物”“疾病和诊断”以及“解剖部位”。Medicine的标签为(B,I)类型。本文分别对CCKS2017和CCKS2020中不同类别的实体数量进行了统计,统计结果如表2和表3所示。不难看出,CCKS2020数据集中不同类别的实体数量差异较大,例如“解剖部位”类别实体明显居多,而“影像检查”和“实验室检验”等类别实体则较为缺乏。同样CCKS2017中“疾病诊断”和“治疗”样本数量缺乏严重。因此需要使用2.7节中的均衡样本过采样方法对这2种语料库做数据增强。通过将包含“影像检查”“实验室检验”“手术”和“药物”类别的样本进行扩充,最终实体数量分布如表4所示。不难发现“影像检查”等少样本类别均扩充到2500以上。同时也对CCKS2017做过采样,“疾病诊断”和“治疗”等少样本类型数量均得到扩充。 表2 CCKS2017数据集实体数量分布 表3 CCKS2020数据集实体数量分布 表4 增强后的实体数量分布(CCKS2020) 经过对均衡过采样后的CCKS2020数据集检验,可以发现由于采用了样本向量远距离优先的过采样方法,增加了更多包含如“腹腔镜上dixon术”“贝伐珠单抗”“肝转移瘤rfa术”等出现频率较少的样本,而“胸部ct”“布洛芬”等使用频率高的样本不再增加。验证了均衡过采样方法的有效性。 实验采用准确率(Precision)、召回率(Recall)和F1值(F1-Measure)作为评测指标。实体识别和分词有不同的判定标准,具体计算方法分别由公式(23)、公式(24)给出: (23) (24) 其中,t代表实体类别,实体识别需要对每个类别进行F1值评估。分词只需评价模型能否正确地预测出词边界即可(即准确找出所有的“B”标签)。 首先将CCKS2020和Medicine分词数据集用于训练多任务模型,实验超参数设置如表5所示。梯度下降优化方法使用Adam方法,并采用L2正则化来防止模型过拟合。注意力机制方面,用于全局编码的注意力机制层数设置为4,并且采用4头注意力结构,通用特征增强机制也采用4头注意力。 表5 超参数设置 权重因子方面,本文通过微调不同的权重因子以测试模型性能表现。图2和图3分别展示了α和β在不同取值时的性能对比。 图2 不同α取值性能对比图 图3 不同β取值性能对比图 由图2不难看出,当α取值在0.5时性能表现较好,低于0.5时性能出现一定程度下降,这是由于α取值过低会造成实体识别任务损失的权重降低,使模型得不到有效优化;α取值在0.5~0.7时性能较为稳定,而接近1时性能发生下降,原因是α较大使分词损失权重降低,模型性能退化为单任务性能。 由图3不难看出,β取值在0.95时性能最好,且在0.8~1.1之间时性能并未有太大变化。低于0.8时性能逐渐降低,这是由于β取值过低造成L2正则化损失权重降低,因而模型受到了过拟合的影响。 在对比实验的过程中,所有基线模型都使用一块11 GB显存的NVIDIA RTX 2080Ti显卡训练。而本文提出的多任务训练方法需要构建多个表示子空间,因此会占用更多的内存,本文使用2张NVIDIA RTX 2080Ti显卡训练模型。首先将上述基线系统用CCKS2020数据集训练,将多任务实体识别模型用CCKS2020和Medicine这2个数据集并行训练并测试,并对它们的结果按实体类型汇总。然后将基线模型用CCKS2017训练,将多任务实体识别模型用CCKS2017和Medicine这2个数据集并行训练并测试,并对结果按类型汇总。由于多任务实验用到的语料分别来自实体识别和分词任务,所以不必考虑重叠样本问题对模型所带来的影响。 首先使用CCKS2020语料库展开实验,采用命名实体识别常用的深度神经网络模型作为基线系统。包括BiLSTM-CRF[3]、BiLSTM-CNN-CRF[30]、BiLSTM-Att-CRF[31]、Lattice-LSTM[6]、IDDNN[32]、SETL[24]和BERT-CRF[8].BiLSTM-CRF为双向LSTM加上CRF的标注模型;BiLSTM-CNN-CRF加入了卷积神经网络,利用卷积核的局部感知能力对RNN隐藏层作进一步编码,以获得上下文字符的语义特征;BiLSTM-Att-CRF是融入注意力机制的BiLSTM-CRF模型,在各大任务上性能均取得有效提升;IDDNN采用不同策略融入词典特征,提出N-Gram、带有位置的分类特征和不带位置的分类特征3种构建策略,并针对字符和特征设计2种训练框架;SETL即基于笔画Elmo的多任务模型;BERT为BERT_Base版本,采用通用领域语料预训练,并在本实验中使用CCKS2020语料进行微调。由于本次实验是在过采样的语料下展开,为确保实验的有效对照,本文按照IDDNN和SETL在原文中的介绍和设置,在服务器环境下搭建模型,并同BiLSTM等基线模型一同训练并测试。最终实验结果如表6所示。 表6 CCKS2020对比实验结果(F1) 单位:% 通过对上述实验结果的对比和分析,本文提出的模型在6类实体中有5类取得最高的F1值,综合性能达到最好。SETL的Elmo笔画预训练模型在CCKS2020语料库上性能依旧很好,大多数类型的F1值均超过其它基线模型。Lattice-LSTM在“影像检查”和“实验室检验”实体类型中表现较好,但整体性能并未达到最好,原因是其在执行过程中需要进行分词词典构建,而实验数据中可能存在未登录词,引发分词错误的问题。IDDNN在“疾病和诊断”和“解剖部位”表现较好,但整体性能不如Lattice-LSTM。BERT整体并未达到最好,原因是BERT为通用领域预训练模型,虽然具有强大的自注意力机制和残差结构,但并未针对医疗领域知识进行优化,因此在临床文本中表现较差。本文中的多任务结构将类似BERT的注意力机制作为共享层,加入了多个Bi-LSTM私有层并行训练,将较大的模型空间划分为多个子空间,减弱了噪声等因素的影响,因而可以更有效地收敛到最优解,实验性能也得到提升。 接下来用CCKS2017语料库进行实验,其中实验设置、评价指标和基线系统同CCKS2020一致,对BERT基线模型使用CCKS2017进行微调。实验结果如表7所示。通过结果不难发现本文模型在3类实体上F1值高于其它基线模型,综合性能达到最好。SETL在本实验中也取得了较高的结果,且在“症状”上获得最高F1值,其它大部分实体也有较好表现。IDDNN在“身体部位”上效果最好,综合性能也较为突出。Lattice-LSTM在“症状”上表现较好,但整体效果欠佳。BERT通用语言模型的效果依旧略差。由此再次验证本文提出模型的有效性。 表7 CCKS2017对比实验结果(F1) 单位:% 对包括基线系统在内的所有模型测试结果做具体分析,发现本文模型能够有效识别出电子病历中的专业术语、领域名词。部分医学术语由于出现频次低或上下文内容存在误导,使得基线模型无法识别,但本文模型识别的准确率明显提高;一词多义情况下性能相比其它基线系统也表现更好,如“多食用动物肝脏明目”中的“肝脏”可能会被基线系统错误识别为“解剖部位”,在本文模型中此类问题得到了一定程度解决;对无规范、无结构用语的样本也能保持较好的识别效果。 本文也测试了所提出模型在Medicine语料上的分词任务性能。通过在分词子任务中加入通用特征增强机制来提升性能,并保持和NER任务一样的参数设置。基线模型选取BiLSTM-CRF、BiLSTM-CNN-CRF、BiLSTM-Att-CRF和AMT Transfer Learning(AMTTL)[33]来作对比实验,其中AMT Transfer Learning是另一种形式的多任务框架,使用了SIGHAN2005下的数据集作为辅助任务增强Medicine等语料的分词性能,并引入KL散度等距离度量来约束任务之间的隐层表示相关性,从而确保模型保留更多领域不变信息。其余基线模型前文已有介绍,最终实验结果如表8所示。 表8 Medicine分词实验结果(PRF) 单位:% 实验结果表明,本文多任务模型相比基线模型F1值提升了约3个百分点,准确率和召回率也有大幅度的提升,准确率提升约5个百分点。对于未登录词(OOV)的分词能力也有较大的改善。同为多任务框架的AMTTL在结果上也达到较好,对未登录词的切分能力较基线模型大幅提升,这也再次验证了多任务学习具有强大的泛化性,能够防止陷入过拟合情况。 本节对比不同的模型架构,来验证本文模型在私有层设计上相比其它模型的优势,通过修改私有层结构来生成不同模型。首先将模型中所有私有层的Bi-LSTM替换为BERT_Base结构,输入维度调整为512,并使用预训练参数初始化,以得到All-BERT模型;同时通过将Bi-LSTM替换为与全局编码器相同的具有4层网络的4头自注意力结构,以得到All-BERT-mini模型。分别使用CCKS2017和CCKS2020对上述3种结构做对比实验,并比较它们的训练时间、资源占用等情况。实验结果如表9和表10所示。 表9 不同模型结构在CCKS2020上的实验结果对比 表10 不同模型结构在CCKS2017上的实验结果对比 通过表中实验结果可知,以BERT_Base为私有层的All-BERT模型在2个任务的性能上并未超过本文的模型,原因是子任务层的维度较大、层数较多,导致模型空间过大,过于复杂的模型为收敛带来困难,同时也增加了过拟合的风险。此外All-BERT的时间耗费最长,且执行时需要26.8 GB显存才能容纳全部训练参数;而All-BERT-mini在训练时表现出了速度快、资源占用低的优势,执行时显存占用量约为13.6 GB左右,但性能表现与本文模型有较大差距。原因是子任务层的自注意力机制过于简单,导致模型在当前任务上的局部信息提取能力下降。 多任务模型与单任务模型不同,后者需要建立较为复杂的模型空间以确保构建丰富的向量映射,使模型有效收敛到最优解;而多任务模型同时具有私有层和共享层,需要构建不同的特征子空间,因此每个子空间不宜过大,即网络设计不宜太复杂,否则会导致模型难以收敛或过拟合问题。对于多任务的共享层设计4层网络的4头自注意力机制,而多任务的私有层需要提取子任务的局部特征编码,因此使用LSTM网络为主要结构。 综合上述分析,多任务模型的子任务层结构使用Bi-LSTM时综合性能最佳。Bi-LSTM具有较强的上下文依赖提取能力,能够有效编码电子病历中的领域名词、未登录实体等,帮助模型在实体识别上提升性能。同时Bi-LSTM复杂性较低,能够有效地避免过拟合,提升模型的泛化性。 3.7.1 均衡过采样方法有效性 由于本文中的训练数据存在样本类别分布不平衡的情况,因此提出均衡过采样来缓解这一问题。本节在CCKS2020数据集上展开研究,探讨不同过采样方法对模型性能的影响。首先使用2.7节中的方法制作均衡过采样数据集,即3.4节、3.5节和3.6节实验中所有模型采用的数据。同时制作2个对照版本:普通过采样版和增量过采样版。普通采样版使用随机扩充的方式增加样本,而增量采样版使用连续均衡过采样的方法将所有数量不足5000条的实体类别数据扩充至5000条以上。在这3个版本的数据集和原始数据上展开实验,每个类别上的F1值结果如表11所示。 表11 不同版本数据集结果对比(F1) 单位:% 对比结果发现,均衡采样数据相比未采样数据最高提高约2个百分点,综合性能提升约1个百分点。采样后的数据在“影像检查”等少样本实体上性能增幅较大,这也验证了算法的有效性。普通上采样数据和增量采样数据性能未有太大差异,但整体表现不如均衡采样数据,综合F1值落后均衡采样数据约1.5个百分点。分析可能是由于普通上采样数据使用随机扩充样本的方式,增加样本时没有考虑到新样本对原数据集分布的影响,因此模型性能稍微降低。而增量采样数据中重叠的条目较多,造成了模型过拟合等问题。因此均衡采样数据作为本文模型的实验数据效果最好。 同时本文在CCKS2020上使用原始数据和均衡采样数据分别做对比实验,以验证均衡过采样方法对模型的影响。基线模型和实验设置同实体识别实验一致。不同版本数据对比实验结果如表12所示。从表中数据得知,SETL和本文模型在过采样数据上相比原始数据均有提升。而BERT等部分模型却表现出性能下滑,效果不如原始数据。分析原因可能是GloVe向量表示会将噪音或其它不相关信息当作低频样本编码到稀疏向量空间,从而过采样导致噪声变大。而SETL和本文模型都为多任务结构,通过拟合不同任务样本空间产生较强的噪声对抗能力,因此受影响较小,模型性能得到有效提升。其余单任务模型在本算法中均受到不同程度影响。由此得出结论,均衡过采样方法在多任务场景下更有效。这也再次验证本文提出的模型在电子病历实体识别上性能高于其它基线模型。 表12 原始/过采样数据NER实验结果对比(F1) 单位:% 3.7.2 通用特征增强的性能 如何更有效地控制不同任务之间的信息流一直是多任务学习的研究重点,目前主要方法是在共享层增加判别器机制[19,22],过滤其中的私有特征信息,保留对任务有帮助的通用特征信息。因此本节通过对比实验来讨论融入判别器和通用特征增强机制2种不同方法的性能差异。首先使用CCKS2020和Medicine语料训练判别器,其中CCKS2020为原始语料集。利用2个语料集训练一个具有3层前馈神经网络的判别器,经过10轮训练后使其具备判断样本归属的能力。随后使用判别器在多任务模型上按照3.3节中的超参设置展开训练,训练过程中不更新判别器的参数,将判别器输出加入目标函数中作为惩罚项,以约束全局编码器产生不依赖任务的特征。实验过程中每2个epoch做1次测试来对比F1值,模型性能对比趋势如图4所示。 图4 本文模型和判别器版本不同训练阶段的F1值对比 对比使用判别器作为共享网络层约束的方法,本文提出的通用特征增强机制表现更好。模型训练的整个过程中,本文方法在综合F1值上始终高于判别器方法。在最终轮训练结束后,本文方法的F1值为90.74%,而判别器方法的F1值为89.34%。通过分析得出,注意力机制可以通过调整加权来捕捉有用的通用信息,因而可以针对当前任务进行优化,模型也能更有效地收敛;此外多任务共享层完全采用自注意力机制来实现,因此该情况下同为注意力机制的通用特征增强机制可能更适用,原因是相同或相似的网络结构可以确保特征空间更近似,模型表示能力也就越好。 本文提出了使用多任务学习的方法来实现医疗领域实体识别任务,设计基于Bi-LSTM的子任务编码层来构建任务内的局部知识表示,引入基于自注意力机制的全局编码器来建模不同任务的全局特征,并加入了通用特征增强机制来帮助模型增强有用信息,以更有效地收敛到最优解。同时针对电子病历语料提出均衡过采样方法来解决样本不平衡问题。同基线模型对比,本文所提方法在CCKS2017和CCKS2020电子病历数据集中取得显著效果,同时在Medicine分词数据上的性能也得到提升。多任务学习是迁移学习的重要方法,未来将继续探索多任务学习在其它领域的应用。3 实验部分
3.1 实验数据和预处理
3.2 评价指标
3.3 实验设置
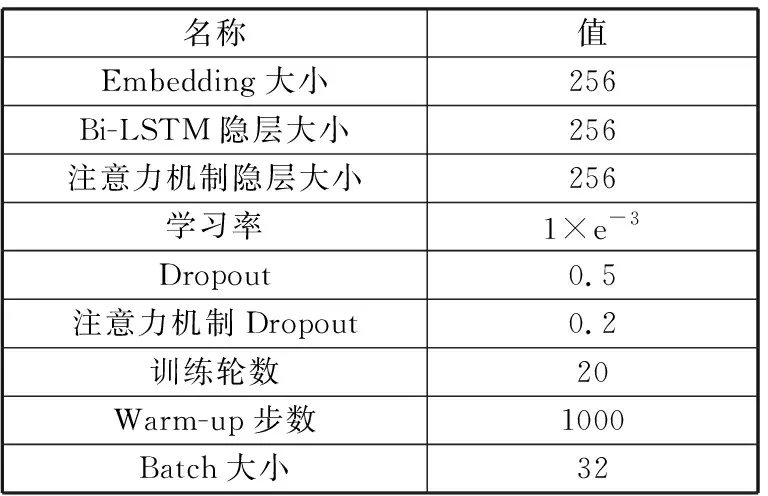
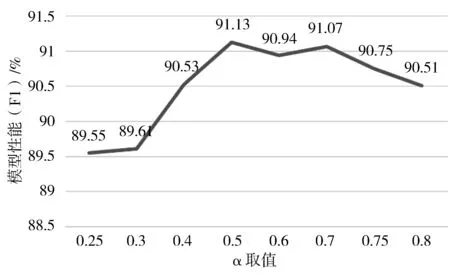
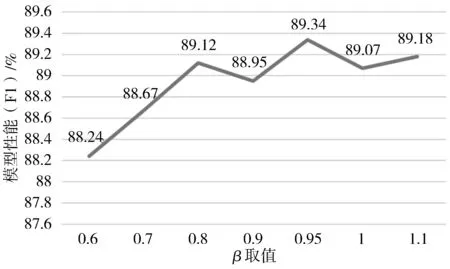
3.4 实验结果
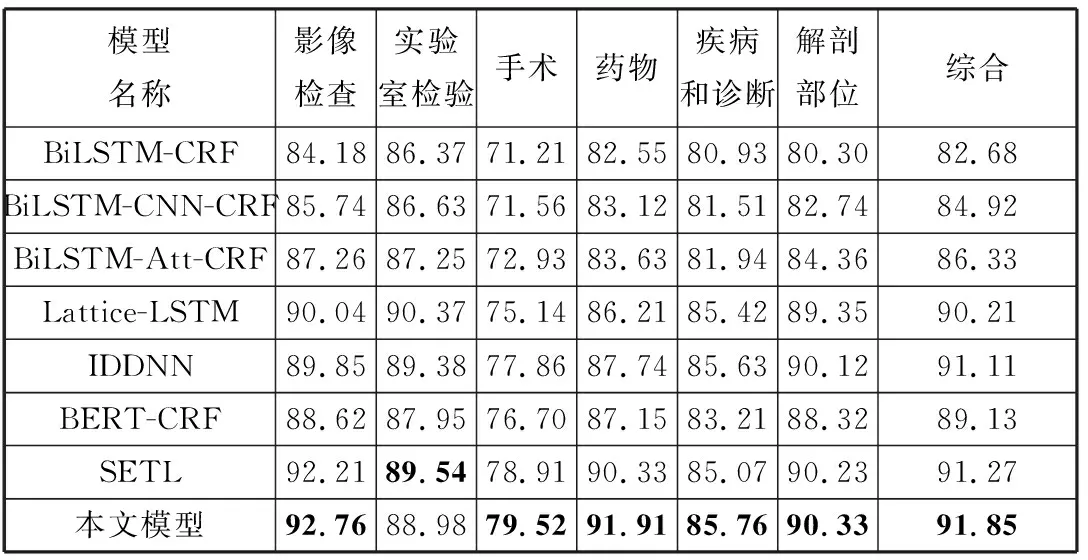
3.5 分词性能测试
3.6 模型性能分析
3.7 消融实验与分析
4 结束语
