基于改进YOLOv5的幽门螺杆菌免疫印迹图像识别
2022-09-24张鸿鑫刘庆华
王 梦,张鸿鑫,刘庆华,张 东
(1.江苏科技大学计算机学院,江苏 镇江 212003; 2.无锡铂肴医疗仪器有限公司,江苏 无锡 214142)
0 引 言
医学影像识别(Medical Image Recognition, MIR)现已成为现代医学诊断方法中极其重要的一环[1]。近年来,随着深度学习方法被广泛运用到医学影像之中,临床诊断结果的准确性以及诊断效率也因此得到大幅提高,并且有效减少了操作者凭借人工经验所带来的误差和失误[2]。医学影像包括X-射线图像(X-Computed Tomography, X-CT)、核磁共振图像(Magnetic Resonance Imaging, MRI)、超声波成像(Ultrasonic Image, UI)、免疫印迹(蛋白印迹法)图像(Western Blot Image)等[3]。这些图像中包含了病变组织、病灶位置、经染色的阳性区域等十分重要的病理信息,对于医生在临床诊断中起到关键作用[4]。
免疫印迹法是临床上常见的检测蛋白质的检测方法,对于幽门螺杆菌的检测使用免疫印迹法具有很好的效果[5]。检验步骤可简单概括为:先将HP抗原用SDS-聚丙烯胺凝胶电泳,按分子量大小不同分开,再将其转移至硝酸纤维膜上[6]。如果被检血清有相应抗体,应用酶联反应吸附效应,就会在抗原的相应位置出现显色阳性区域。根据阳性区域的分子量不同即可判断HP类型,目前已经是针对幽门螺杆菌的主流检测方法[7]。幽门螺杆菌免疫印迹图像就是在上述硝酸纤维膜显色区域经过染色出现阳性区域之后所采集到的医学图像,通过拍照等手段采集到计算机中,并转换成指定的文件格式而得到的[8]。为了准确分析幽门螺杆菌的感染程度和类型,阳性区域的检测识别是关键一步,其结果影响后续定量、定性检测的精度。
文献[9]对肠道肿瘤图像采用ResNet50模型进行图像特征提取和识别;文献[10]将半监督学习算法和生成对抗网络相结合应用在医学图像分割之中,解决了医学图像中伪影、混叠的问题;文献[11]将深度学习中的迁移学习方法应用在医学图像领域中,改善了在医学图像中因样本少、标注困难等导致深度学习效果不佳的问题。文献[12]将U-Net网络运用于肝脏肿瘤图像的分割之中,并改进了单网络结构和多网络结构进行肝脏肿瘤图像的特征提取。上述文献研究指向性强,多为针对某一类医学图像时提出的方法及模型的改进优化,并不能很好地移植到本文所研究的幽门螺杆菌免疫印迹图像检测识别之中。
本文基于YOLOv5模型,为了适用于幽门螺杆菌免疫印迹图像的识别,使用DenseNet作为特征提取器并缩小了下采样倍数,强化了图像中小目标的识别。通过使用Swish激活函数和改进定位损失函数提高检测识别的精度。在合作单位提供的数据集中进行实验分析,识别精度与速度均取得明显提升。
1 基于改进YOLOv5的幽门螺杆菌免疫印记图像检测识别模型
1.1 YOLOv5模型框架概述
YOLO最初于2015年提出,用于检测目标[13]。目标检测是一种计算机视觉技术,它通过在目标周围画一个边界框来定位和标记对象,并确定一个给定的框所属的类标签。与大型NLP transformers不同,YOLO设计得很小,可为设备上的部署提供实时推理速度,之后又相继推出了v1~v5等版本[14]。v5在v4算法的基础上做了进一步的改进,使其速度与精度都得到了一定程度的提升,其大小有v5m、v5x、v5s、v5l等多个版本[15]。YOLOv5网络架构如图1所示,主要由输入端、Backbone、Neck网络、输出端Head组成[16]。输入端表示输入的图片,该网络的输入图像大小为640×640,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic[17]数据增强操作提升模型的训练速度和网络的精度,并提出了一种自适应锚框计算与自适应图片缩放方法。Backbone是一些性能优异的分类器网络。Neck的核心为特征金字塔(Feature Pyramid Networks, FPN)和路径聚合网络(Path Aggregation Networks, PAN)结构。
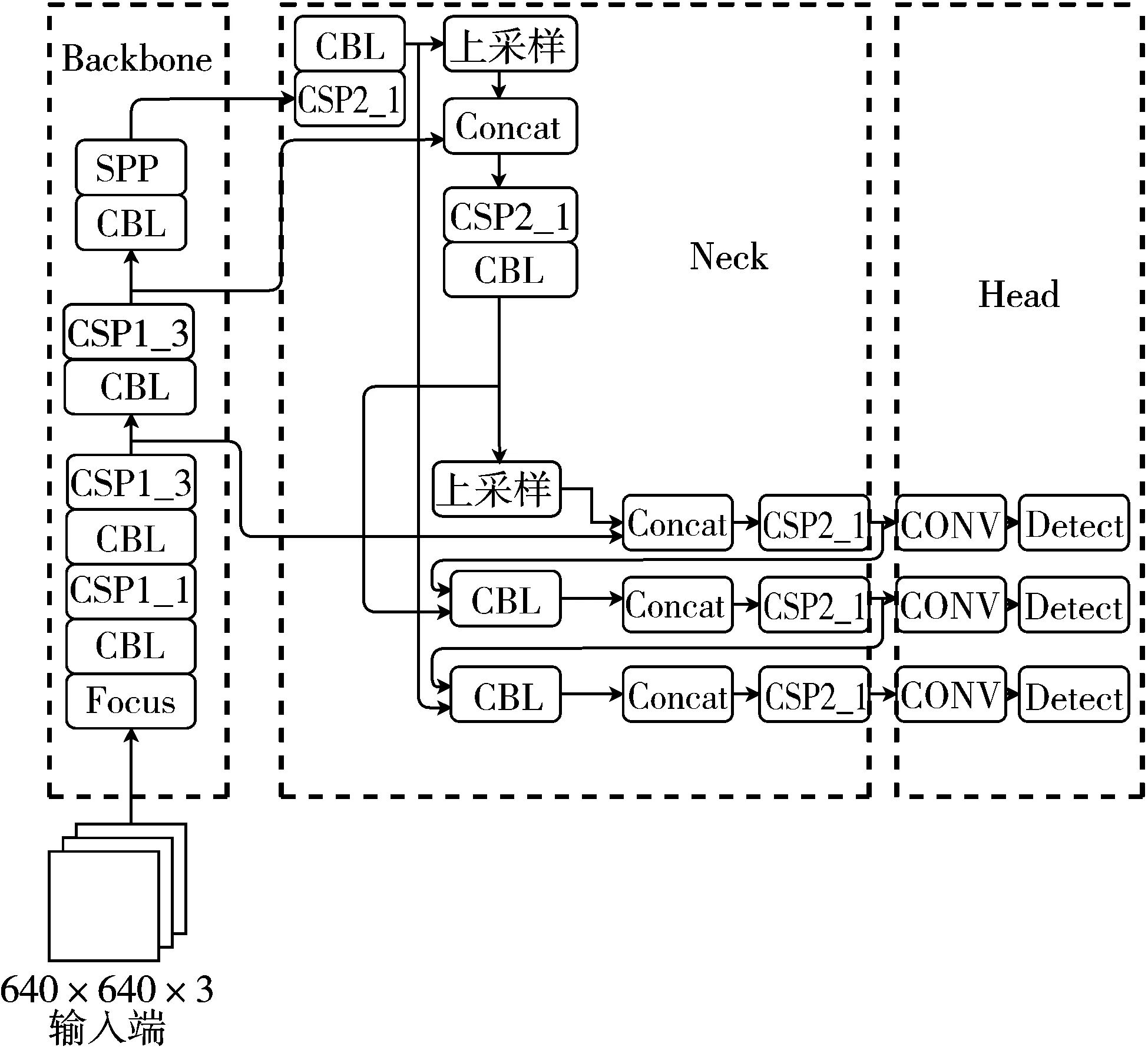
图1 YOLOv5网络架构图
YOLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络[18]。其中CSP1/2_X模块、Focus模块、空间金字塔池化(Spatial Pyramid Pooling, SPP)模块内部结构如图2所示。
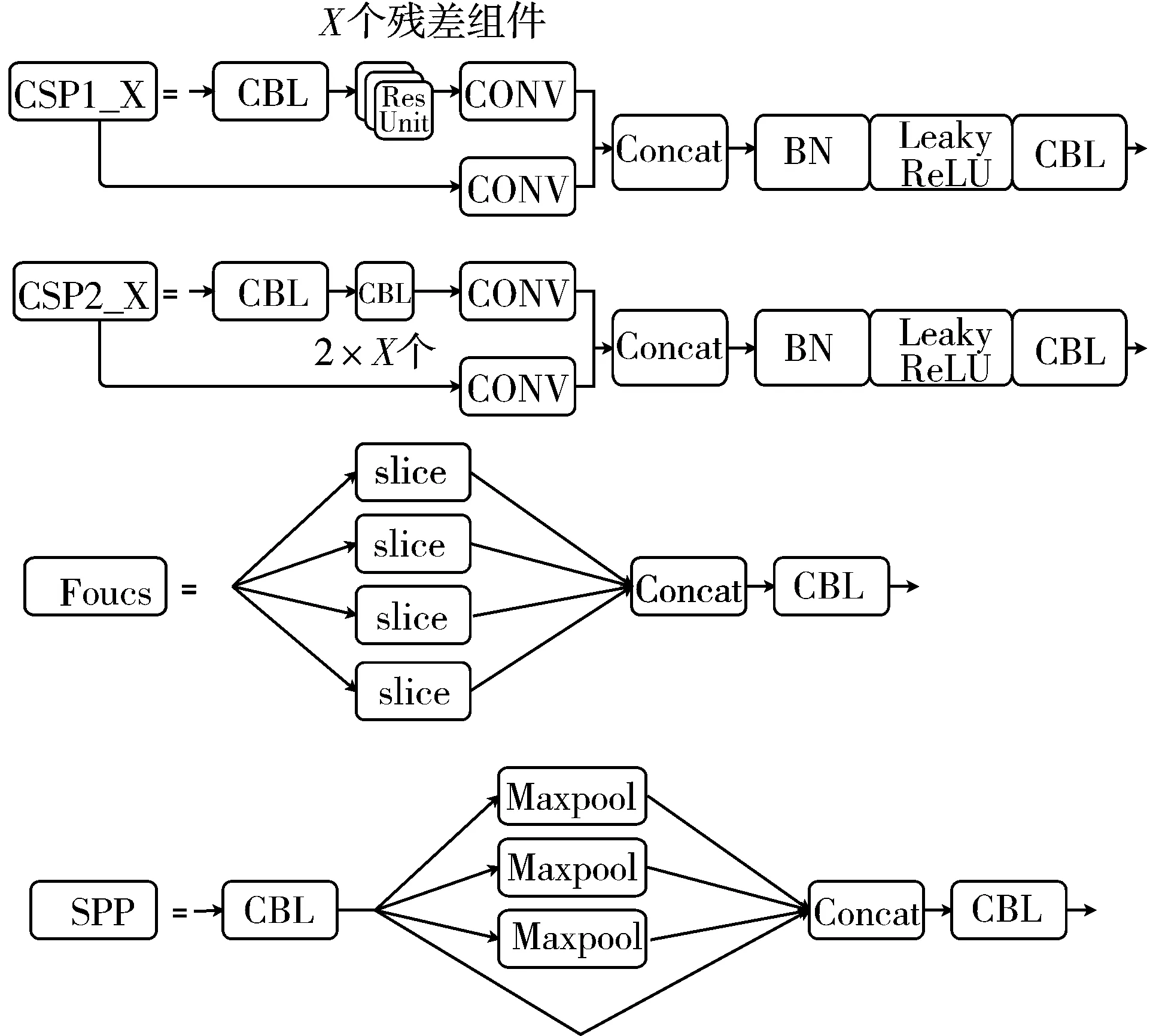
图2 YOLOv5主要模块结构
CSP1/2_X借鉴CSPNet网络结构[19],该模块由CBL模块、Res Unint模块以及卷积层、Concat组成。Focus模块[20]在YOLOv5中图片进入Backbone前,对图片进行切片操作,在一张图片中每隔一个像素拿到一个值,类似于邻近下采样。然后将W、H信息集中到通道空间,输入通道扩充4倍,即拼接起来的图片相对于原先的RGB这3个通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的2倍下采样特征图。SPP为空间金字塔池化层[21],SPP对输入执行3种不同尺寸的最大池化操作,并将输出结果进行Concat拼接,输出深度与输入深度相同[22]。
1.2 改进的YOLOv5模型
1.2.1 使用DenseNet作为特征提取器
在深度学习网络中,随着网络深度的加深,梯度消失问题会愈加明显,DenseNet[23]在保证网络中层与层之间最大程度的信息传输的前提下,将所有层连接起来,也就意味着每一层的输入来自前面所有层的输出,如式(1):
xl=hl[x0,x1,…,xl-1]
(1)
其中,[x0,x1,…,xl-1] 表示将0~l-1层的输出特征图做concatenation,hl包括卷积层(Conv)、批量归一化(BN)和激活函数。DenseNet网络是由dense block、 transition block和dense layer组成。
对于网络中每个dense block,其宽度和高度保持不变,但是由于特征图的串联,网络的体积在每一层都在扩展。每个dense block中的特征图的最终大小kl计算公式为:
kl=k0+k×lth
(2)
其中,k为growth rate,lth是指特定dense block中dense layer的数量。在此网络中使用了32的growth rate。另外这里每个dense block的3×3卷积前面都包含了1个1×1的卷积操作,即bottleneck layer,目的是减少输入的特征图数量,这样既能降维减少计算量,又能融合各个通道的特征。为了进一步压缩参数,在每2个dense block之间又增加了1×1的卷积操作。
DenseNet的另一大优势是通过特征在通道上的连接来实现特征重用,这有效地加强了特征的传递并提高了特征的利用率,一定程度上减少了参数数量。
1.2.2 FPN与PAN结构改进
本文对幽门螺杆菌免疫印迹图像中质控带以及阳性区域大小进行分析,发现所有质控带和阳性区域均为矩形,采用区域的长度和宽度所占像素的均值以及取整后的结果来衡量区域所占像素大小。统计幽门螺杆菌免疫印迹图像中的目标像素所占大小,结果显示长宽均值取整后介于区间[16,32]的阳性区域个数为2687。
由此可见幽门螺杆菌免疫印迹图像检测识别任务主要以小目标为主。在特征金字塔FPN和PAN结构之中,大目标的特征显著,小目标容易被背景及噪声干扰。原始FPN和PAN结构不能很好适用阳性区域的识别。本文通过缩小最高下采样倍数,将原8、16、32倍下采样削减为4、8、16倍下采样,以此来增强小目标的特征。特征金字塔结构及改进结构如图3所示。
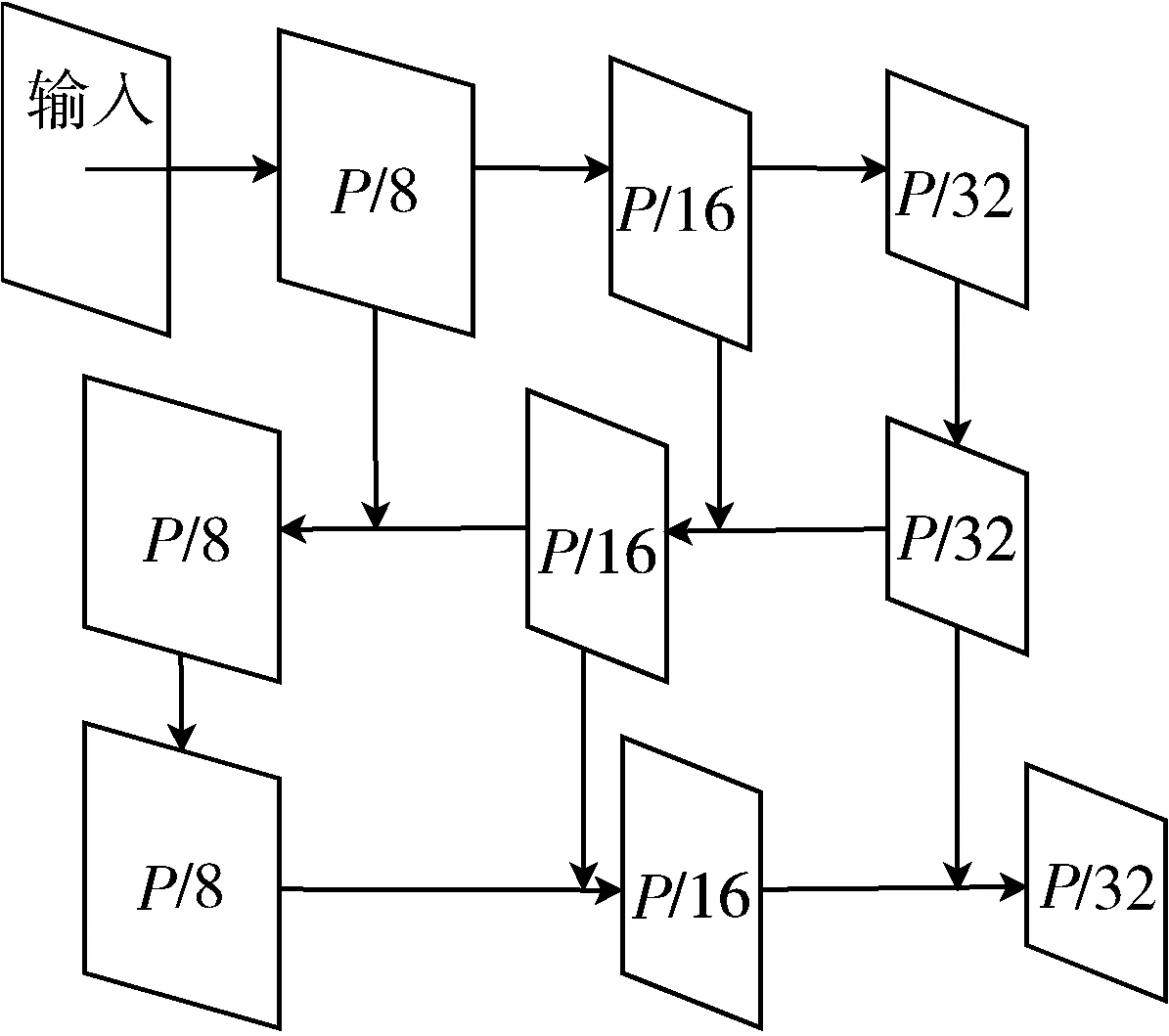
(a) 原特征金字塔结构
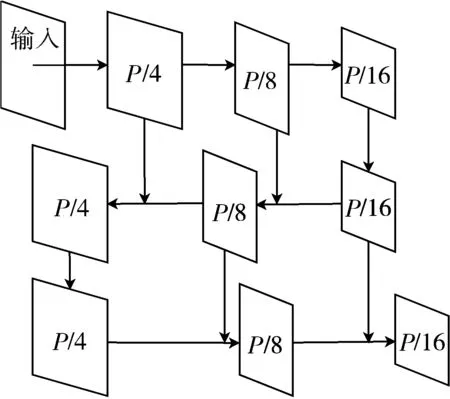
(b) 改进后结构图3 特征金字塔结构及改进
1.2.3 采用Swish激活函数
在YOLOv5原始模型中,激活函数采用的是Leaky ReLU。其公式为:
(3)
虽然Leaky ReLU[24]改进了传统的ReLU激活函数,给所有负值赋予一个非0斜率,但由于在不同区间函数不同,无法为正负输入值提供一致的关系预测,因此本文采用Swish激活函数,其定义为:
f(x)=x·sigmoid(x)
(4)
其中,sigmoid函数定义为:
sigmoid(x)=1/(1+exp-x)
(5)
Swish函数有下界无上届,且具有平滑非单调的特性。Swish的设计受到LSTM(长短期记忆网络)[25]中使用sigmoid函数进行门控的启发[26]。当使用同样的值进行门控来简化门控机制,称为自门控(self-gating)。自门控的优势是它仅需要一个简单的标量输入,而正常的门控需要多个标量输入。该特性令使用Swish能够轻松替换以单个标量作为输入的激活函数(如ReLU),无需改变参数的隐藏容量或数量。实验结果表明Swish激活函数性能要优于原模型中的Leaky ReLU函数。
1.2.4 改进YOLOv5损失函数
原YOLOv5模型包含3种损失函数,分别是分类损失(classification_loss)、定位损失(localization_loss)和置信度损失(cofidence_loss)[27]。分类损失采用BCEcls_loss函数来计算,置信度损失采用BEClogits_loss函数来计算,二者均为二元交叉熵损失函数。总损失函数为以上三者加权相加,通过改变权值可以调整对三者损失的关注度。
YOLOv5原模型中定位损失函数使用的是GIoU_loss,GIoU原理如图4所示。
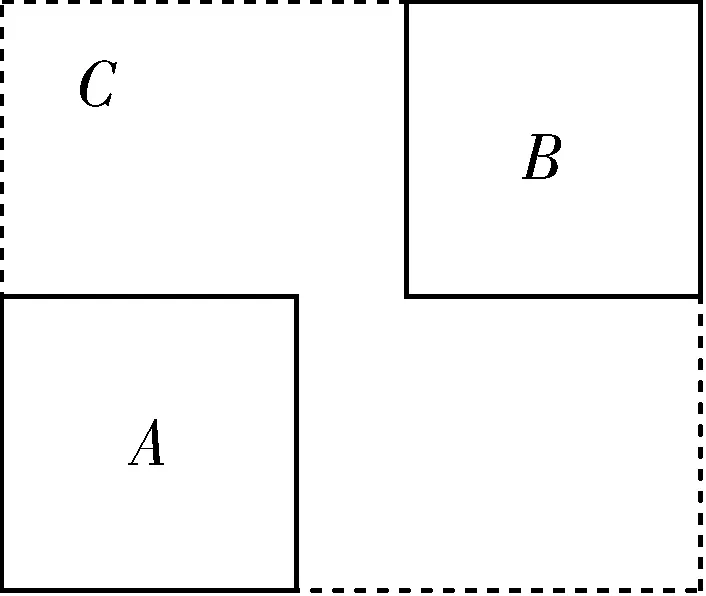
图4 GIoU原理示意图
针对任意的2个A、B框,首先可以寻找到一个能够包含它们的最小方框,其次根据A、B的大小即可以算出C的大小,当有了C的面积,则GIoU的计算公式为:
(6)
其中,IoU(交并比)为:
(7)
GIoU作为loss函数时:
GIoU_loss= 1-GIoU
(8)
当A、B不相交时,A∪B值不变。最大化GIoU就是最小化C。这样就会促使A、B不断靠近。尽管GIoU解决了在IoU作为损失函数时梯度无法计算的问题,且加入了最小外包框作为惩罚项,但是它仍然存在一些问题。首先GIoU需要较多的迭代次数才能收敛,增加了计算量;其次当检测框和真实框之间出现包含现象的时候GIoU就和IoU效果相同。
因此本文引进CIoU作为定位损失函数,其原理如图5所示。
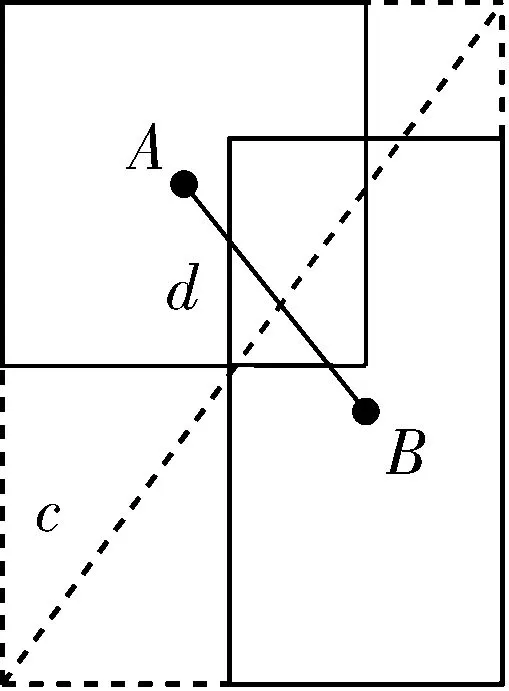
图5 CIoU原理示意图
图5中d=ρ(A,B),即2框中心点坐标的欧氏距离,而c是包含A、B最小方框的对角线距离。
相比于GIoU,CIoU的惩罚项是基于中心点的距离和对角线距离的比值,避免了像GIoU在2框距离较远时,产生较大的外包框,loss值较大难以优化。所以CIoU_loss收敛速度会比GIoU_loss更快。即使在一个框包含另一个框的情况下,c值不变,但d值也可以进行有效度量,其次当考虑2框中心点重合时,c与d的值均不变,此时引入框的宽高比。CIoU_loss计算公式为:
(9)
其中,α是权重函数,v是用来度量宽高比的一致性,即:
(10)
(11)
其中,w,h是检验框宽高,wgt,hgt是真实框的宽高。CIoU增加了检验框尺度的loss,增加了长和宽的loss,这样预测框就会更加的符合真实框,提高了定位精度。
总损失函数计算公式为:
loss=BCEcls_loss+CIoU_loss+BEClogits_loss
(12)
2 实验结果与分析
2.1 实验数据集
2.1.1 实验数据集概述
本文采用的数据集由无锡铂肴医疗仪器有限公司提供。该公司致力于幽门螺杆菌免疫印迹技术的开发,由其提供的幽门螺杆菌免疫印迹图像数量庞大,并且由专门的医疗仪器通过高清摄像头所拍摄。仪器保证了数据集拥有相同的染色条件与拍摄条件。本文数据集部分样本如图6所示。

图6 本文数据集部分样本
幽门螺杆菌免疫印迹图像由以下3个部分组成:阳性区域、质控带以及阴性区域。阳性区域目视为浅蓝至深蓝色,质控带目视为黑色,阴性区域为白色。阳性区域在硝酸纤维膜上的位置决定了幽门螺杆菌的感染类型。将起始线与标准带起始线对齐,观察阳性显色区域与对应的标准带位置即可判断幽门螺杆菌感染类型。
1)质控带未出现:表示本次试验无效。
2)阴性结果:显色区带仅出现质控带,未见任何一条阳性区带,表示被检者血清中无HP抗体。
3)II型HP抗体阳性:仅UreA和UreB区带中任意一种或同时出现,未见CagA、VacA区带。
4)I型HP抗体阳性:CagA、VacA区带中任意1种或2种同时出现。
示意图如图7所示。
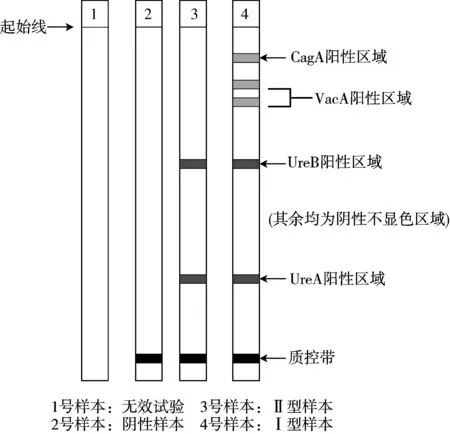
图7 数据集样本类型示意图
2.1.2 实验数据集划分
本文将合作单位提供的1475份样本,剔除无效样本后按照6∶2∶2划分为训练集、验证集、测试集。为测试模型在面对不同幽门螺杆菌感染类型时的性能,对测试集进一步划分:I型感染测试集、Ⅱ型感染测试集、Ⅰ型和Ⅱ型混合测试集。此外单独区分测试集1和测试集2是根据临床需要,测试本文改进模型对不同幽门螺杆菌感染类型的识别效果。具体分组如下:
1)训练集:880份阴性、Ⅰ型、Ⅱ型样本混合。
2)验证集:295份Ⅰ、Ⅱ型混合样本。
3)测试集1:100份I型感染样本。
4)测试集2:100份Ⅱ型感染样本。
5)测试集3:100份Ⅰ、Ⅱ型混合样本。
2.2 实验结果
2.2.1 检测识别精度衡量指标
在YOLO系列模型中,精度衡量指标主要包含F1-score、mAP@0.5、mAP@0.5:0.95这3种指标[28],本文也采用此3种指标来衡量模型效果。上述3种指标的计算是基于混淆矩阵[29](Confusion Matrix)、准确率、召回率的计算。其定义见表1。
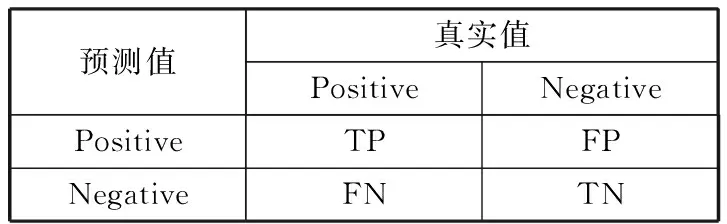
表1 混淆矩阵
其中,True Positive(TP):真正类,样本的真实类别是正类,并且模型识别的结果也是正类。False Negative(FN):假负类,样本的真实类别是正类,但是模型将其识别为负类。False Positive(FP):假正类,样本的真实类别是负类,但是模型将其识别为正类。True Negative(TN):真负类,样本的真实类别是负类,并且模型将其识别为负类。
准确率(Precision, P)又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。一般情况下,查准率越高,说明模型的效果越好。计算公式为:
(13)
召回率(Recall, R)表示的是模型正确识别出为正类的样本的数量占总的正类样本数量的比值。一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。计算公式为:
(14)
F1-score(F)定义为准确率和召回率的调和平均数,该指标综合了Precision与Recall的产出的结果。计算公式为:
(15)
mAP是每个类别AP的平均值,AP是PR曲线下的面积。单纯地用Precision和Recall来评价整个检测器并不合理,因为有的检测任务要求更高的Recall,错检几个影响不大;有的检测任务则要求更高Precision,漏检几个影响不大。因此需要对Precision和Recall做一个整体的评估,而这个评估就是AP(Average Precision)。AP@0.5定义为当混淆矩阵IoU阈值取0.5时对排序好的检测结果进行“截取”,依次观察检测结果的前1个、前2个、...、前n个,每次观察都能够得到一个对应的Precision(Pi)和Recall。mAP@0.5定义为所有类的AP@0.5求均值,其计算公式为:
(16)
mAP@0.5:0.95表示在不同IOU阈值(从0.5~0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP,该值越高意味着模型高精度边界回归能力越强,检测框与标定框拟合越精准。计算公式为:
(17)
2.2.2 检测识别速度衡量指标
本文选用FPS(Frames Per Second)作为模型的检测速率衡量指标,FPS是图像领域中的定义[30],是指画面每秒传输帧数。人眼舒适放松时可视帧数是每秒24帧,集中精神时不超过30帧,即意味着大于30帧时即为检测流畅。
2.2.3 改进YOLOv5模型测试实验
本文主要对比的模型为YOLOv5s和YOLOv5m。s是YOLOv5系列中深度最小,特征图的宽度最小的网络。m在此基础上不断地加深,不断地加宽。
为测试改进YOLOv5模型的检测性能,本文将所有待参照对比模型都训练至理想状态,在测试集1(全Ⅰ型样本)、测试集2(全Ⅱ型样本)、测试集3(Ⅰ型和Ⅱ型混合样本)中评估检测,识别效果见图8与图9。

(a) I型样本原图

(b) YOLOv5s检测结果

(c) YOLOv5m检测结果

(d) 本文模型检测结果图8 I型样本在不同模型中的检测结果

(a) Ⅱ型样本原图

(b) YOLOv5s检测结果

(c) YOLOv5m检测结果

(d) 本文模型检测结果

(e) Ⅰ、Ⅱ混合型样本原图

(f) YOLOv5s检测结果

(g) YOLOv5m检测结果

(h) 本文模型检测结果图9 测试集2和测试集3在不同模型中的检测结果(图中Q为质控带,C为显色带)
图8(a)是I型幽门样本原图,图8(b)是测试集1在YOLOv5s模型中检测结果,对比原图可知该模型漏检了VacA阳性区域,而图8(c)是测试集1在YOLOv5m模型中的检测结果,可明显看到有误检区域,效果并不理想,图8(d)是使用本文改进YOLOv5模型之后的检测结果,可见所有的阳性区域均检测出,无漏检、误检情况,检测效果相比其他模型要出色。
图9(a)是Ⅱ型幽门样本原图,图9(b)和图9(c)是该样本在YOLOv5s和YOLOv5m模型中的检测结果,发现在这2个模型均存在漏检情况,漏检区域由白框标出。
图9(e)为Ⅰ型和Ⅱ型混合型样本原图,图9(f)为该样本在5s模型中的检测结果,漏检的阳性区域位置由白框标出。图9(g)为该样本在5m模型中的检测结果,有2处误检区域由白框标出。而图9(d)、图9(h)在使用本文改进模型的情况下,无漏检、误检情况,具有优秀的检测效果。
为进一步评估YOLOv5系列不同模型的检测识别精度、检测速率以及YOLOv5各模块改进的有效性,在测试集3(Ⅰ型和Ⅱ型型混合样本)中评估识别精度、检测速率,结果见表2。
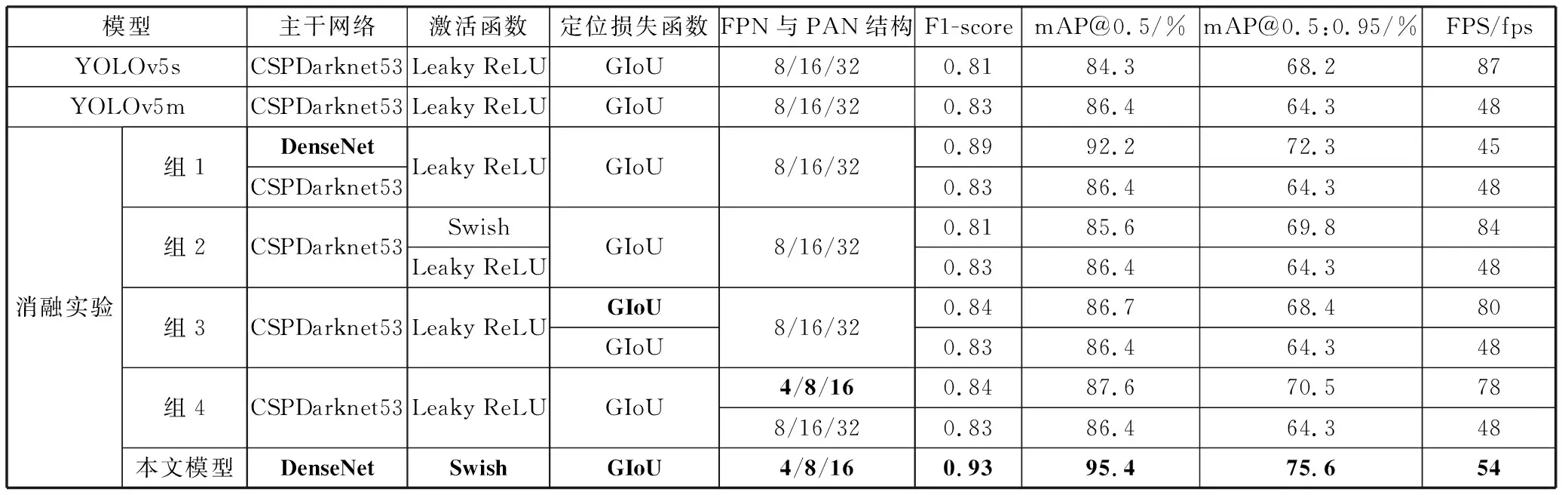
表2 不同模型性能比较
由表2数据可知,改进后YOLOv5模型在各指标上均取得了显著提升。相较于YOLOv5s,F1-score提升0.12;mAP@0.5提升11.1个百分点,检测准确率显著提升;mAP@0.5:0.95提升7.4个百分点,模型高精度边界拟合能力增强;检测速率达到54 fps,满足临床实时性需求。
其次针对本文提出的各改进点进行消融实验,实验共分5组,组1实验结果发现,对本文模型起到关键提升作用的是主干网络DenseNet,但其同时也限制了模型的检测速度。组2实验数据表明Leaky ReLU激活函数虽然在F1-score和mAP@0.5这2个指标上相较Swish激活函数分别高出0.02个百分点、0.8个百分点,但是在mAP@0.5:0.95和FPS上Swish激活函数却有较大的提升,从而弥补了使用DenseNet作为主干网络带来的检测速度的劣势,融合这4种改进可以实现识别精度的提升同时也保证了检测速率符合临床要求。
2.2.4 改进模型与其他算法对比实验
本文将改进的算法与SSD、Faster R-CNN、CenterNet、YOLOv3进行比较,在控制相同实验参数的情况下比较mAP@0.5的值,结果如表3所示。
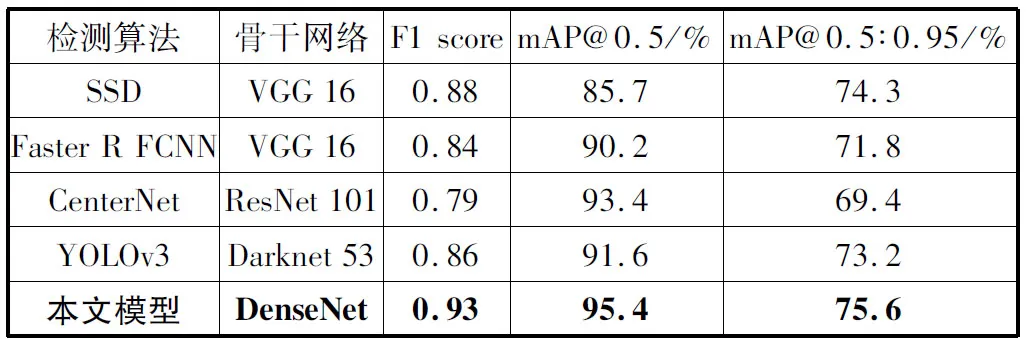
表3 不同检测方法效果的比较
从表3可发现本文方法的mAP@0.5值高于其他算法,并且对比于同样是one-stage算法的SSD,本文提出的改进算法对小目标检测效果更好。
3 结束语
本文针对临床需要,提出了一种改进YOLOv5模型,用于幽门螺杆菌免疫印迹图像的自动识别检测,有效地解决了临床上重度依赖医生目视识别导致费时费力的现状。通过引入DenseNet解决了梯度消失的问题;改善FPN和PAN结构削减下采样倍数提高了小目标识别能力;通过引入Swish激活函数提高了模型检测速度性能;最后优化IoU提高了定位精度。实验结果表明,改进后的模型针对幽门印迹图像对比YOLOv5其他版本,具有更好的识别精度和稳定性。同时本文优化模型也存在一定的局限性,由于实际临床医疗设备硬件设备算力有限,如何将模型移植到有限算力的医疗设备之中,这也是下一阶段需重点研究的方向。
