增强小目标检测性能的通道自注意力机制算法研究
2022-09-20王金东晏天文霍智勇
尹 芹,方 晖,王金东,王 侃,晏天文,霍智勇
(1.中兴通讯股份有限公司多媒体视讯产品部,江苏 南京 210000 2.南京邮电大学通信与信息工程学院,江苏 南京 210003)
由于注意力机制有助于提高小目标检测网络的特征表达,即关注本质特征,抑制不必要的特征,卷积块整合注意力机制可以有效提高图像分类、目标检测和实例分割等计算机视觉任务的性能[1-4]。在基于空间注意力机制的检测算法中,由于小物体边界框面积与图像面积之比(Ratio of Bounding Box Area to Image Area,RBI)在 0.08%~0.58%之间,边缘特征模糊甚至缺失,分辨率和可利用特征信息有限,接连的多层下采样卷积使得小目标特征信息丢失,导致基于空间注意力机制[5-9]目标检测算法性能有限。例如CoupleNet[10]将空间注意力机制用于位置特征信息的提取,许腾等[11]将Darknet-53中的第2个残差块输出的特征图用混合空洞卷积处理后,与下采样特征图相融合成新的注意力特征。R-FCN++网络模型[12]引入了全局上下文空间注意力模块,使用了大且可分离的卷积核提升了网络分类能力。Hu等[13]提出了结构推理网络,建模单个图像中的场景上下文信息和对象的依赖关系,并利用上下文空间注意力机制。这些算法使用空间注意力机制将所有位置上的特征聚集在一起来强化原有特征。
在基于通道注意力机制方面,之前一些研究低秩近似的工作[14]认为卷积层输出的特征在通道维度方面是存在冗余的,通道维度的缩减不会明显影响特征表达能力。例如把每个输出通道对应的卷积核铺成一个ci×k2大小的矩阵,那么矩阵的秩不会超过k2,代表其中存在很多的卷积核是近似线性相关的。 例如在 GCNet[15]和 CBAM[16]等研究中,将空间注意力和通道注意力整合到一个模块中,但对小目标和大中型目标计算均值平均精度(Mean Average Precision,mAP)时,结果存在很大的差距。ShuffleNet虽然使用 channelshuffle[14]算子实现两个分支之间的信息融合,但计算复杂度高。
将两种注意力机制对小目标检测的性能和网络参数数量进行对比,如图 1所示。 ECANet[17]与SANet[18]在不增加网络参数的情况下使用通道注意力,对比 ResNet网络 mAP提升 1%~2%。而CMBA[8]和 SKNet[19]使用通道注意力与空间注意力结合的方法,虽然提高了网络的分类性能,但相较于使用通道注意力机制,mAP下降了0.5%~1%。为了公平比较注意力机制对小目标检测的影响,这里都使用 FasterRCNN[20]目标检测框架,并采用ResNet-50[21]作为网络骨干。

图1 注意力机制对小目标检测的性能影响和网络参数量的对比图
因此,为了捕获微小物体的位置和感知其全局空间结构,在不增加计算复杂度的前提下,提出一种针对深度卷积神经网络更高效的通道自注意力机制,通过将网络特征张量压缩,平均空间上所有点的信息,使用自注意力机制有效地捕获了跨通道的相关性,对含有小目标特征信息通道加权,从而实现对小目标检测能力的增强。
1 算法设计
通过对 SENet[22]中的通道注意力模块(即SE块)在小目标检测存在问题的研究,分析降维和跨通道交互作用的影响,提出通道自注意力CSA模块。该模块将输入特征映射压缩,将自注意力机制用于特征通道中,对所有特征进行优化加权。
1.1 SENet通道注意力机制分析
设一个卷积块的输出为X∈RC×H×W,其中C、H、W分别表示通道数、空间高度和宽度。因此,SE块中通道的权值ω可以计算为

式中σ为sigmoid激活函数,嵌入全局信息通过使用全局平均池化g(x)生成,通道注意力参数生成的函数F{w1,w2}可以计算为
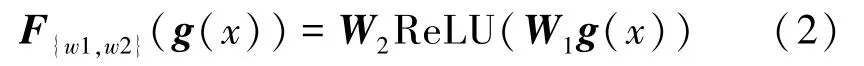

1.2 通道自注意力机制
1.2.1 通道自注意力压缩提取过程
CSA模块的总体架构如图2所示。
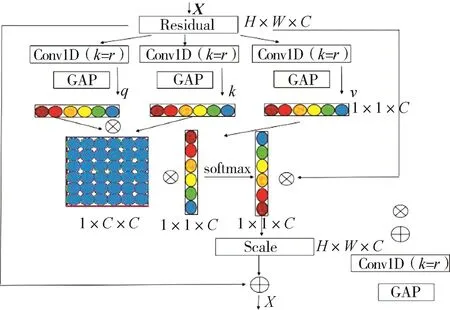
图2 CSA模块的总体架构图
CSA模块为了利用通道依赖性,首先关注网络输出中每个通道的信号特性。网络的卷积核都有一个有效的局部感受野,因此每个特征采集都不能获得这个区域之外的上下文信息。为了解决这个问题,通过使用全局平均池化来获得通道统计信息。对于给定的输入特征X∈ RC×H×W,其中C、H、W分别表示通道数、空间高度和宽度,CSA首先沿着通道维数将X全局平均池化压缩成x∈ R1×C,x=[x1,…,xC],其中特征xi在训练过程中逐渐捕获特定的特征响应。
全局平均池化层的输出可以被解释为局部描述符的集合,这些局部描述符的统计信息可以表达整个图像。虽然SE中的降维可以降低模型的复杂度,但它通过压缩激励两阶段的方式破坏了通道与其权重之间的直接对应关系,因此使用两个卷积核大小为k=r的标准卷积和自注意力机制,CSA模块建立了通道与其权重之间的直接联系。
1.2.2 通道自注意力模型
为了利用压缩操作中聚合的信息,实现完全捕获通道之间的依赖关系,CSA选择采用标准卷积的方式,通过卷积和全局平均池化,使用自注意力的方式学习通道之间的非线性交互关系;同时CSA将通道自适应权重和给定的输入特征X∈RC×H×W相乘,通过对输入特征通道维度的加权增强多个通道,学习非互斥关系。
CSA模块通过自注意力模块为每个特征生成相应的权重系数。如图2所示,在每个注意力单元开始时,X的输入沿着通道维数分为3个分支,即xq,xk,xv∈R1×C。xk和xq产生一个通道自相关的注意力特征图,而另一分支xv与自相关的注意力特征图生成一个通道注意力权重,所以该模块可以专注于图像的语义信息。虽然捕获通道依赖关系的一种方法是利用SE块,但是SE块对权值进行降维和升维操作破坏了权重对通道的直接对应关系,因此采用了一种替代的优化方法。
首先,CSA块中通道的权重计算公式如式(3)所示。
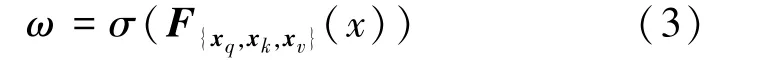
式中:σ为sigmoid激活函数,F为卷积运算。
接着,为了建立更有效的通道相关性,提高小目标检测的性能,如图2所示,CSA模块通过全局平均池化获得全局信息后,使用3个卷积核大小为k=1的标准卷积层xq,xk,xv。 SE注意力机制的降维虽然可以降低模型的复杂度,但破坏了通道与其权值的直接对应关系。因此提取特征是用两个取不同卷积核大小的一维卷积来实现。
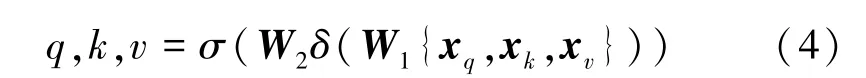
式中:q,k,v分别表示xq,xk,xv的归一化权重;σ为激活函数sigmoid;δ为激活函数ReLU;W1和W2为两个一维卷积层。CSA模块首先将xq,xk通过点积的方式获得通道自相关权重矩阵XT,如式(5)所示。

为了防止点积出现尺度爆炸,使用dk进行尺度缩放,接着使用softmax激活函数归一化权重,然后按照式(6)将获得通道自相关权重矩阵XT和xv点积获得通道自适应权重Xs。

最后为了捕获通道的远距离依赖关系,获得有效的小目标语义特征表示,将通道自适应权重Xs和给定的输入特征X∈RC×H×W相乘。

式中Xc为最终建立通道相关性的特征表达。
2 实验结果
2.1 实验设置
实验方法使用PyTorch和Keras来实现所有的实验。在训练过程中,使用标准的衰减和动量为0.9的随机最速下降(Stochastic Gradient Descent,SGD)优化器来训练所有的模型,权重衰减值设置为4×105,初始学习率为0.05。实验使用1个NVIDIA GPU进行训练,批处理大小设置为2。不作额外声明,取ResNet类网络作为实验基线和训练模型。实验使用包含有20个类别的PASCAL VOC数据集训练模型,将批次大小设置为2,并使用同步批归一化。使用余弦学习计划,初始学习率为0.01。由于PASCAL VOC2007本身不是小目标数据集,为了验证CSA小目标检测性能,实验从PASCAL VOC2007测试集和验证集中筛选出物体边界框面积与图像面积之比RBI在0.08%~0.58%之间,面积小于 32×32(像素)的物体作为小目标数据集作为测试集,进行随机测试。
2.2 通道自注意力机制用于小目标检测网络性能对比
本文在不同的目标检测网络上应用通道自注意力机制,在PASCAL VOC2007的验证集下进行了性能对比,结果如表1所示,从mAP值可以明显看出,在ResNet、mobileNet和 EfficientNet中加入 CSA注意力模块显著提高了小目标检测精度。
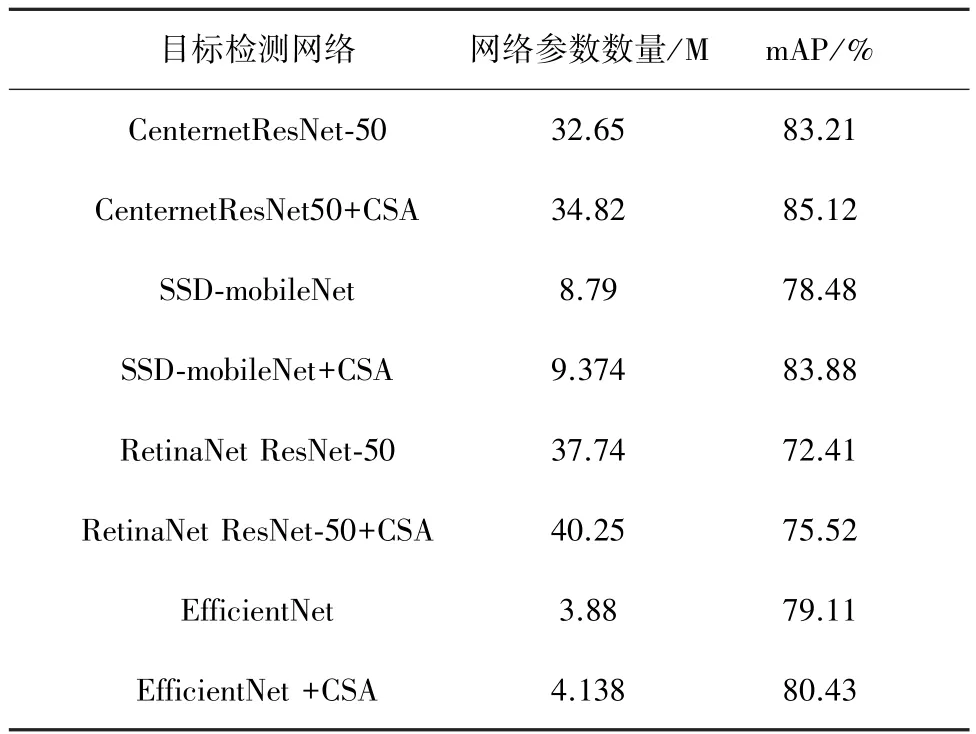
表1 基于目标检测算法CSA性能对比
2.3 Retinanet网络下注意力机制性能对比实验
本文提出的通道自注意力机制和其他注意力机制性能对比结果如表2所示。采用CSA注意力机制的RetinaNet的 mAP值比原始RetinaNet的mAP值高3.11个百分点。与SE注意力机制和CBAM等其他注意力机制相比,CSA注意力机制将目标检测算法性能提升0.1~0.2个百分点。可以明显看出,在ResNet中加入CSA注意力显著提高了检测结果。PASCAL VOC2007数据集上的检测实验表明,在RetinaNet目标检测算法中,CSA注意力的网络模型具有更好的提升检测小目标的能力。

表2 CSA与其他注意力性能对比(PASCAL VOC2007数据集)
表3为卷积核k对网络性能的影响结果。实验中k分别为 1,3,5,7,9。 使用 CSA 注意力机制的MobileNetv2比原始的MobileNetv2 mAP值提高3.05个百分点。当k取相对较小值时,网络的性能逐渐提升;当超过5时性能反而下降。这是因为当卷积核取较小值时,网络卷积过程提取了完整的特征信息,而当卷积核过大时,网络卷积过程会丢失有效的特征信息。
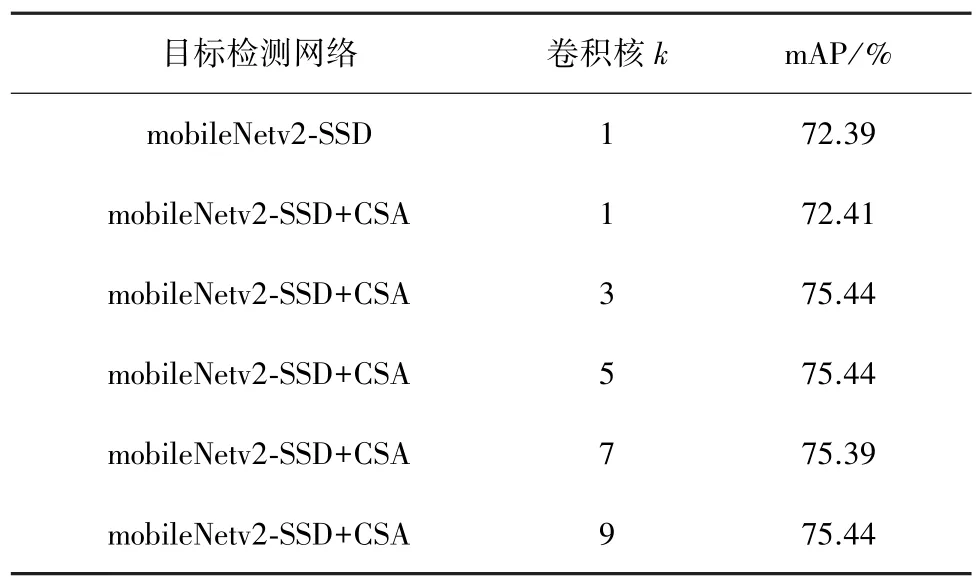
表3 卷积核k对网络性能的影响
2.4 基于YOLOv4算法训练损失对比
在YOLOv4算法中添加了CSA模块前后的损失对比,如图3所示。纵坐标为损失值,横坐标为网络训练迭代次数。蓝色和绿色的曲线为本文模型和原始YOLOv4的训练损失,黄色和红色的曲线分别为本文模型和原始YOLOv4模型的验证损失。蓝色曲线和黄色曲线在迭代次数65次后几乎重合,说明CSA模块使网络训练更加容易拟合。
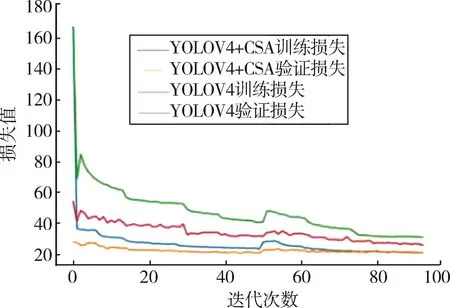
图3 YOLOv4算法中添加CSA前后损失曲线下降对比
然而,随着训练的进行,蓝色曲线比绿色曲线下降得更快。因此,CSA权重趋向于信息更丰富的权重,这也是使用CSA机制的YOLOv4获得更好性能的原因。
在本实验中,模型在COCO数据集上进行预训练,在PASCAL VOC数据集上进行微调,只需要几十个迭代就可以使训练收敛。训练分为两个阶段。在第一阶段,骨干网络被冻结,权重网络只有在conv 52层之后才会更新;在第二阶段,整个网络进行更新。
实验将输入图像的大小缩放成不同大小比例,比如320×320和352×352。在评估阶段,将输入图像的大小缩放为544×544。如表 4所示,与带有CSA的模型比YOLOV4性能提升近2个百分点,从帧率看推理时间增加很少。
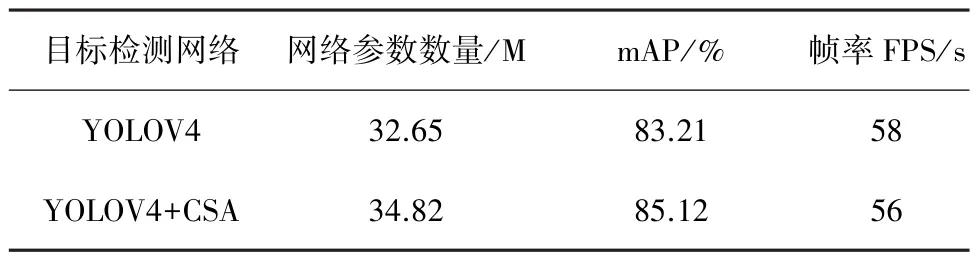
表4 基于目标检测算法YOLOV4性能对比
2.5 注意力特征可视化
为了验证CSA模块提高小目标语义特征表示的有效性,使用PASCAL VOC2007作为测试集,对ResNet-50网络添加CSA模块前后注意力特征图进行对比。选取了4张图像作为样本,使用GradCAM进行特征注意力热力图可视化。如图4所示,图4(a)为ResNet-50在分类性能最佳的“layer4.2”处的热力图,图 4(b)为添加 CSA模块后在“layer4.2”处的热力图。由图中可以看出,添加了CSA模块允许分类模型关注更多相关区域和更多的对象细节,建立通道间相关性,自适应地重新优化特征通道的响应,提升了小物体远距离上下文信息的捕获能力。这意味着CSA模块可以有效提高分类精度,增强了网络的小目标检测能力。
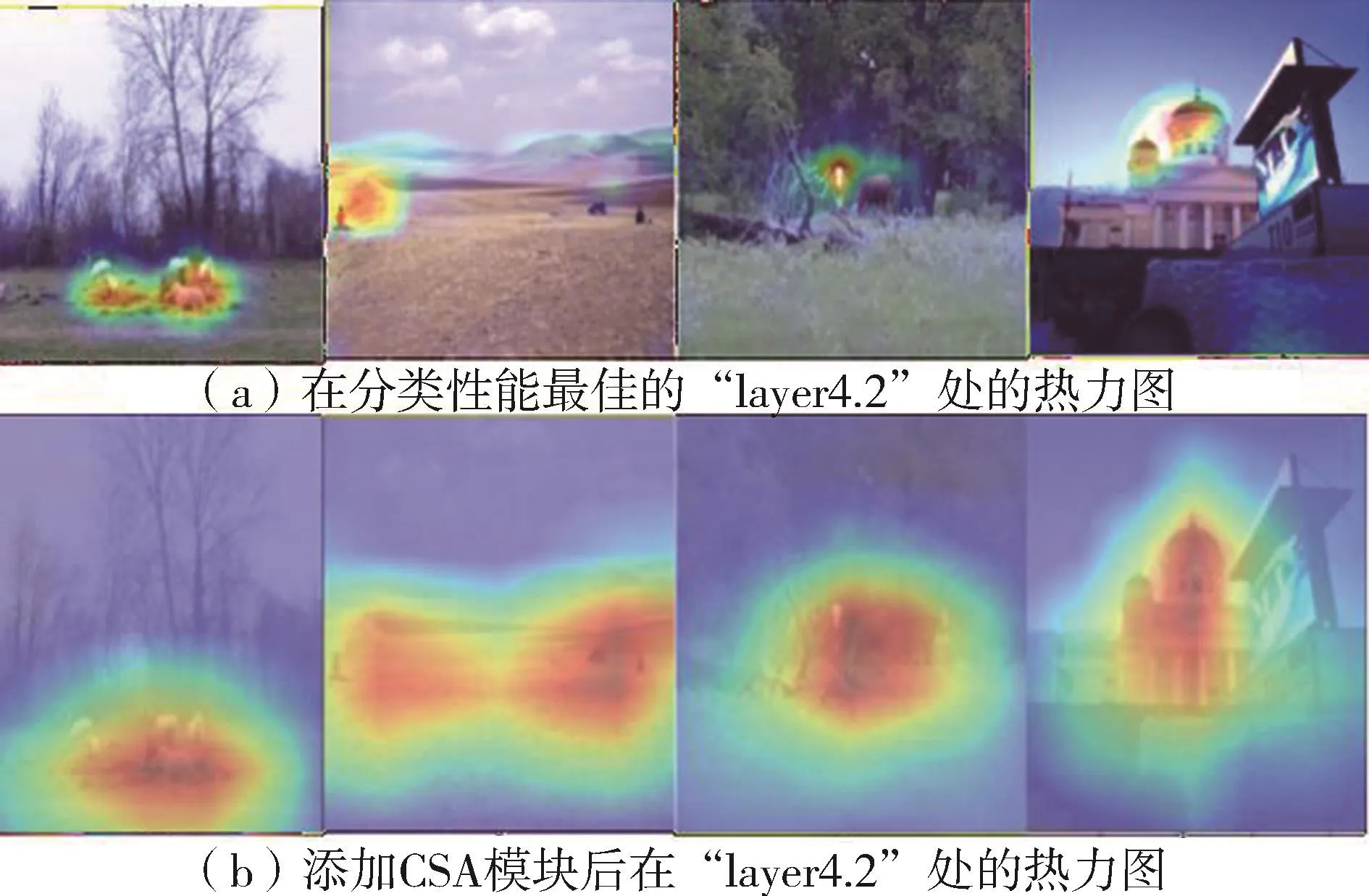
图4 ResNet-50网络添加CSA热力图可视化
3 结束语
本文提出了一个高效的通道自注意力模块。该模块对通道域采用自注意力机制来有效地建立通道相关性,自适应地重新优化通道方面的特征响应。实验结果表明,CSA块是一个即插即用模块,可以改善小目标检测网络的性能,包括广泛使用的ResNet类网络和轻量级的mobileNetV2网络。在未来,将把CSA模块应用到更多的多层预测网络架构中,并进一步研究CSA与空间注意模块的结合。
