ISLM:克服灾难性遗忘的增量深度学习模型
2022-09-20程虎威
程虎威
(北京交通大学计算机与信息技术学院,北京 100044)
0 引言
深度神经网络(deep neural networks,DNNs)在多个领域取得了显著的成功,包括计算机视觉,自然语言处理和强化学习等。然而,传统的DNNs方法在训练时需要所有训练样本,这在现实世界中很难实现,因为现实中的数据往往会随着时间、地点的变化以及其他条件而逐渐被收集。针对这种情况,研究人员提出令DNNs按照人类的学习方式进行增量学习。但是,研究人员发现如果DNNs按照人类学习的方式顺序学习一系列任务,DNNs会遭受灾难性遗忘而忘记先前学习的知识。因此,如何解决增量学习中出现的灾难性遗忘问题是研究人员关注的重点。
当前解决灾难性遗忘的增量学习研究工作大致可以分为三类。第一类方法通过重放先前的任务样本来解决灾难性遗忘问题,不过这些基于重放的方法需要额外的存储空间来存储旧任务的样本和旧模型的权重;第二类方法在学习新任务时引入了控制参数变化的约束,从而缓解旧任务权重丢失,然而在这类方法中遗忘仍然会发生,尤其是当任务数量增加时;第三类方法在冻结旧任务参数的同时,通过添加少量参数来完全避免遗忘。以上这些增量学习方法虽然可以缓解灾难性遗忘问题,但是通常存在三个缺点:性能较差,开销较大,以及设计复杂。为了解决上述问题,本文提出了一个有效的并且能够克服灾难性遗忘的增量深度学习方法(incremental structure learning model,ISLM)。
1 增量深度学习算法
图1显示了本文实现增量式深度学习模型的方法概述。该方法进行增量学习时主要有两个流程,首先,根据新任务样本借助注意力机制对模型通道进行区分,然后根据区分的结果进行增量训练。模型通道的区分过程如图1(①③④)所示,首先,在空神经网络结构中插入注意力模块;其次,训练插入注意力模块的空网络,得到可以度量通道重要性的统计量;再次,挑选一定比例的重要通道作为新任务下的共享通道,未挑选的通道作为新任务的辅助通道;最后,挑选的新共享通道与旧模型的共享通道进行交操作,相同的通道作为当前模型下的共享通道,其余通道作为当前模型下的辅助通道。区分结束后,模型根据区分结果进行增量学习,增量训练过程如图1(②⑤)所示。本文在共享通道上对所有任务使用一组参数,每次训练新任务时以微调的方式更新参数,并且在辅助通道上保持旧任务参数。此外,ISLM还会为特定任务在辅助通道上并行添加滤波器来提高识别精度。
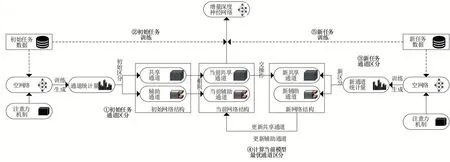
图1 ISLM方法概述
2 算法实现
2.1 模型通道区分
注意力机制最初被应用在机器翻译领域,它能够在大量信息中迅速找到所关注的重点区域并忽略不相关的部分。由于其出色的性能,注意力机制被越来越多的研究人员应用在计算机视觉领域。在计算机视觉领域中,其通过输入特征图来生成通道权重,从而在对重要特征信息进行增强的同时抑制非重要信息表达。
目前根据区分标准的不同,注意力可以分为以下三类:空间注意力,通道注意力以及混合注意力。其中,与空间注意力考虑使用空间域信息来生成权重参数不同的是,通道注意力主要关注通道域信息。然而,无论是根据空间域还是通道域信息产生权重的方式,均会忽略部分信息。因此,研究人员提出混合注意力,其通过综合考虑空间和通道域信息,更为准确地分辨特征图中重要与非重要通道。与此同时,ISLM方法需要极其精确地分辨出模型的共享通道、辅助通道,以达成在共享通道上训练新任务,辅助通道上保持旧任务的设计目标,因此本文将混合注意力机制引入ISLM作用于通道选择,保障模型性能。

通道区分算法


为空模型插入注意力模块


2.2 模型增量训练




其中,R是参数的正则化因子,本文在优化参数模型时,采用范数对W进行正则化,其中ε≥0。通过这种方式,使得参数总数存在上界,从而避免退化的情况,并且本文在共享通道上以微调的方式训练新任务,在辅助通道上保持旧任务参数不变,来最大程度避免改变损失函数。
在此基础上,本文在辅助通道上采用固定任务参数并且为特定任务添加滤波器的方式,进一步提高模型缓解灾难性遗忘的能力以及模型性能。假设模型( )·;W中每个卷积层为φ,设F∈R是该层的一组滤波器,其中C是输出特征的数量,C是输入的数量,×是卷积核大小,那么F中滤波器的值为:

此外,如果任务精度较差,本文把f∈R滤波器并行添加到对应任务的滤波器上。在进行增量训练时,权重保持不变,同时学习f参数。那么,每个卷积层的输出()将变为(;)。

2.3 通道剪枝
由于ISLM是通过添加滤波器的方式来提高缓解灾难性遗忘的能力,会增加额外的参数。因此,为了验证ISLM方法的有效性,本文对模型进行了基于范数的通道剪枝,使得ISLM精度近似达到3.3节中Baseline精度,进而比较模型大小以体现ISLM方法的优势。相比于其他压缩方法,基于范数的通道剪枝会避免模型权重稀疏,并且范数具备计算简单,操作性强的优势,所以本文采用基于范数的通道剪枝对增量深度模型进行网络压缩。它可以表示为:

其中,二进制掩码中的每一项表示对应的输出通道是否需要修剪,并且是保存下来的输出通道的数量。参数用来控制中非零值的数量,越大,中的非零值就越少。
3 实验
3.1 实验设置
本实验中,采用的是PyTorch 1.1.0深度学习框架,开发语言为Python 3.6.9,训练和推理平台均为GeForce RTX 2080Ti。采用的数据集包含ImageNet、Omniglot、CIFAR-10和CIFAR-100数据集,它们是图像分类任务中常用的经典数据集。特别的是,我们在3.3节的实验中将CIFAR-100数据集拆分为20个任务,每个任务分为5个类,用来模拟增量学习环境。网络模型选用的是VGG16、ResNet50两种典型的网络结构。
3.2 注意力模块评估
在本节中,我们先后通过实验探索了注意力机制对ISLM模型结构的影响。然后,通过对比实验寻找最优ISLM模型最佳注意力模块。接下来,将详细介绍实验结果并进行分析。
本文对引用注意力机制和未引用注意力机制的ISLM模型进行对比实验,分别以10%、30%、50%、70%、90%共享通道比例来比较注意力模块的影响。值得注意的是,我们引入目前流行的注意力模块SCA作为实验比较对象。实验结果如表1所示。其中,Baseline表示网络模型训练CIFAR-10识别精度。实验结果表明,不论是基于VGG16的ISLM增量模型,还是基于ResNet50的ISLM增量模型,在引入注意力模块后,ISLM增量模型对CIFAR-10的识别精度都有所提升,并且基于ResNet50的ISLM增量模型以70%共享通道比例区分通道时精度提升最大,提高了0.94%,而基于VGG16的ISLM增量模型以50%共享通道比例区分通道时精度提升最大,提高了0.62%。

表1 基于CIFAR-10数据集的ISLM模型对比
此外,为了验证注意力机制对ISLM模型结构通道区分有效,我们使用基于VGG16的ISLM模型分别顺序训练ImageNet、CIFAR-100数据集和ImageNet、Omniglot数据集。图2(a)和图2(b)分别显示了不同任务上ISLM模型上的注意力权重。如图2(a)所示,当这两个任务相似时(ImageNet和CIFAR-100都由自然图像组成),这两个任务的重要通道大部分相同;当使用两个截然不同的任务时(ImageNet和Omniglot),如图2(b)所示,这两个任务的重要通道相差很大,导致大部分通道区分为辅助通道。上述实验结果表明,注意力机制能够区分出有效的通道。

图2 不同数据集生成的注意力权重
最后,本文对比了几种目前流行的注意力模块在ISLM增量模型上的性能,它们分别是SCA、CBAM、SGE、DMSA和EPSA注意力模块。在本次实验中,本文挑选75%重要通道作为共享通道,剩余通道为辅助通道。其中,Baseline表示网络模型顺序训练CIFAR-10识别精度,实验结果如表2所示。通过分析实验结果,我们可以得到以下结论:首先,引入注意力模块后的ISLM模型在精度上都有提升;其次,SCA模块和DMSA模块不论是对基于VGG16的ISLM增量模型,还是对基于ResNet50的ISLM增量模型,都有优秀的性能。其中SCA模块在VGG16上精度提高1.39%,在ResNet50上精度提高了0.84%;DMSA模块在VGG16上精度提高1.45%,在ResNet50上精度提高了1.03%。但是相比较SCA,DMSA参数量更多,并且设计方法也比SCA更加复杂。所以,本文选择SCA模块作为区分ISLM模型共享通道的注意力模块。

表2 基于CIFAR-10数据集的不同注意力模块性能比较
3.3 增量训练评估实验
为了评估插入ISLM模型的最优区分通道比例,本文以基于VGG16的ISLM模型为例,在拆分的CIFAR-100数据集上进行实验,比较了19组不同比例的ISLM模型。得到顺序训练20个任务的平均精度如图3所示。
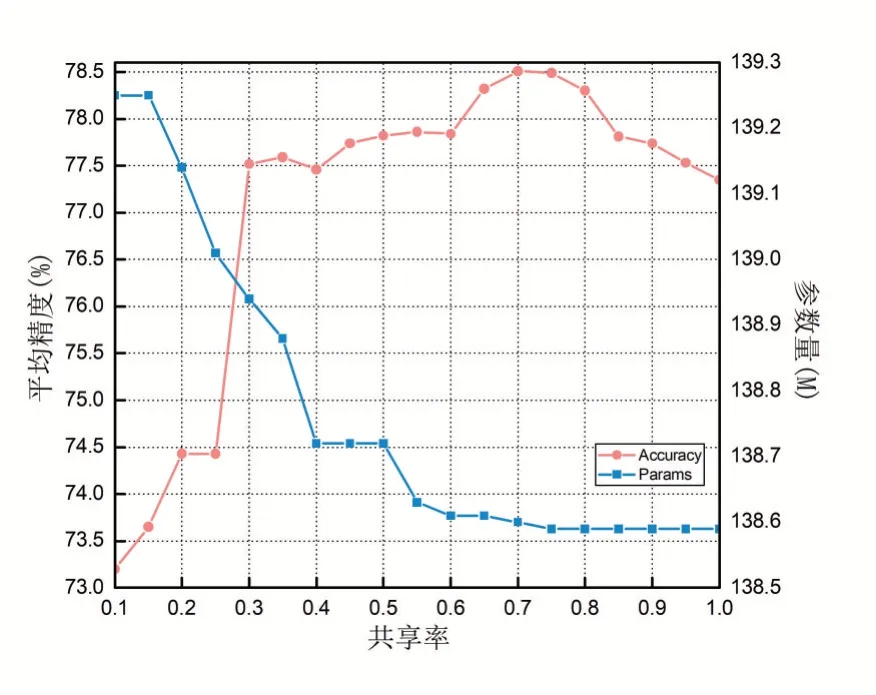
图3 不同通道划分对ISLM模型性能影响
从实验结果可以得出以下结论:共享率会影响ISLM增量模型的性能。例如,当共享率为70%时,增量模型精度达到最高值,为78.51%,并且此时的模型结构所带来的参数量也较少;如果共享率太低,ISLM增量模型会为每个未达到目标精度的任务增添滤波器,这样会导致模型过拟合并且参数量也会增多;如果共享率太高,ISLM增量模型就会退化成普通的微调增量模型,缓解灾难性遗忘不显著。以上实验结果全都表明了合适的共享率会提高ISLM增量模型性能,并且ISLM增量模型以70%通道区分比例在CIFAR-100数据集上有着最优的性能。因此,本文在接下来的实验中都挑选70%重要通道来区分共享通道与辅助通道。
最后,本文分别将基于VGG16和基于ResNet50的ISLM模型与目前最为流行的增量深度模型,包括EWC,CPG,HAT进行比较,它们都是增量深度模型领域具有代表性的工作。为了减少训练时间,本文只对前十个任务的实验结果进行对比。需要注意的是,在本次实验中,我们把单独训练每个任务生成的模型作为Baseline。实验结果如图4和表3所示。

表3 不同深度增量模型平均精度及参数量

图4 基于CIFAR-100数据集的不同深度增量模型性能对比
对实验结果进行分析得到以下结论:首先,本文提出的方法和目前流行的增量学习方法都有不错的缓解灾难性遗忘的能力;其次,ISLM模型在CIFAR-100数据集识别的平均精度分别达到了76.20%和76.14%,提高了1.87%和0.27%。此外,为了验证剪枝后的ISLM模型仍然具有较好性能,本文进一步对训练后的ISLM模型进行通道剪枝,实验结果如表4所示。当基于VGG16的ISLM模型剪枝率为0.6时,ISLM精度达到Baseline精度,并且与Baseline模型相比其模型大小减少了47%;当基于ResNet50的ISLM模型剪枝率为0.4时,模型精度达到Baseline精度,模型大小比Baseline模型减少21%。以上实验结果说明,基于VGG16的ISLM模型要优于其他流行的增量学习方法。

表4 不同剪枝率下ISML模型平均精度及参数量
4 结语
在这项工作中,本文提出了一种新的增量学习方法ISLM,用于克服DNN连续学习中的灾难性遗忘问题。ISLM方法的核心思想是根据注意力模块提供的注意力统计信息把模型通道区分为共享通道和辅助通道,本文使用共享通道以微调的方式训练增量任务,而当无法满足任务精度需求时在辅助通道上为其添加特定滤波器以提升性能,与此同时,旧任务的辅助通道参数保持不变。本文在拆分的CIFAR-100数据集上进行DNN的持续学习,ISLM不仅能够正确区分模型通道,而且利用通道共享和为特定任务添加滤波器的方法可以有效避免灾难性遗忘,优于其他主流增量学习方法。在未来工作中,我们计划将ISLM与其他模型优化方法(如模型量化等)相结合,以进一步提升其性能。
