自适应学习中自适应测验长度预测研究
2022-09-15李建伟武佳惠姬艳丽廖德生
李建伟,武佳惠,姬艳丽,廖德生
(1.北京邮电大学 网络教育学院,北京 100088;2.北京邮电大学 网络系统与网络文化北京市重点实验室,北京 100876)
一、引 言
自适应学习是人工智能技术在教育领域的高阶表现形式[1]。培生公司将自适应学习系统定义为自动为学生提供个性化支持、实时响应学生的交互行为的教育技术[2]。自适应学习系统包括自适应内容、自适应评估和自适应序列三种方式。自适应测验是自适应评估过程中常用的一种手段,测验在教育心理学上是指一系列设计来测量人的知识或能力的问题或作业。自适应学习系统通过跟踪每个学生如何回答问题(即自适应测验),收集他们的行为数据,然后,以满足学生的学习需求为目的,系统根据每个学生独特而具体的行为和反馈,提供个性化的学习服务。所以,自适应测验是实现自适应学习的关键所在。
随着现代心理学教育测量理论的不断发展,基于项目反应理论(item response theory,IRT)和认知诊断理论(cognitive diagnostic theory,CDT)的计算机化自适应测验(computerized adaptive testing,CAT)[3]已广泛应用于分析教育与心理测验数据,在自适应学习系统中,自适应测验用于认知能力诊断,评估被试对特定领域知识的掌握情况、加工技能和认知过程[4]。自适应测验主要包括认知诊断模型、选题策略和终止规则[5],其中,终止规则通常有定长和变长两种。定长规则因其固定被试的题目数量这一特点,在开展测验中较为方便,根据被试者测验的作答情况预估被试者的能力,而面向不同被试者将产生不同的测量精度[6]。变长规则即固定每次测验的测量精度或领域知识的掌握目标,每个被试具有相同测量精度或领域知识掌握目标,但对不同的被试会有不同的测验长度[6]130。Kingsbury等[7]分别应用变长规则和定长规则进行CAT后发现:在计算机化自适应测验的效率、能力估计精度、估计值的收敛等方面,变长规则的效果更优。因此,在自适应学习中,自适应测验的终止规则通常采用变长规则。自适应测验长度预测研究是指采用变长CAT进行不同形式的测验时,对不同被试的测验长度进行精准预测的研究。
二、研究内容与现状分析
(一)研究内容
在自适应学习系统中,自适应测验有两种应用场景。其一是作为练习引擎,在这种方式下,自适应测验有一个由不同难度问题组成的题库,这些问题与学习者刚刚学习的内容一致。这些评估通常在课程结束后进行,学习者回答问题以证明其掌握了这些知识。例如,学习者首先学习某个知识的一组内容,然后通过自适应的练习引擎来证明其所学内容的掌握水平。在练习过程中,学习者可以中断练习,学习自适应内容,然后继续在练习引擎中解决问题,直到其正确回答了足够多的问题,一旦学习者达到知识或技能的掌握目标(预先设定的阈值),将继续学习序列中的下一项知识或技能。其二是作为监测学习者进步的基准评估工具,在这种方式下,自适应测验通常是一种更长、更正式的测试,每隔几个月进行一次,以衡量学习者对多个知识或技能的学习程度。这些评估通常是作为独立测试进行的。例如,学习者可能每三四个月进行一次在线自适应评估,以衡量他们学到的内容。笔者将面向自适应学习系统中的练习引擎应用场景,主要研究内容如下:
1.知识点自适应测验长度预测
基于隐语义模型构建单一知识点的自适应测验长度预测模型,预测学习者在知识练习过程中,达到知识或技能的某个掌握水平值时需要作答多少个问题。
2.知识模块自适应测验长度预测
基于隐语义模型构建由多个知识点组成的知识模块的自适应测验长度预测模型,预测学习者在知识模块练习过程中,达到每个知识点的掌握目标时需要作答多少个问题。
(二)研究现状分析
学习预测是学习分析领域的重要任务,通过构建预测模型,可以提前获知学习者未来的学习结果,同时,基于学习预测结果,可以对存在的学习风险及时进行干预(如人为干预或自适应干预),从而实现个性化教学。有关学习预测的已有研究主要围绕学业成绩、学业风险以及学习时长等展开。王希哲等[8]通过从学习云空间提取并量化学习参与度、活跃度、学习态度、总时长、课后作业等预测指标,提出基于改进随机森林算法的学情预测模型,实现了学业成绩预测。Pardo等[9]通过将自我调节学习技能的数据与在线活动的可观察指标相结合,不但提高了学业成绩的预测能力,还可以更好地解释为什么一些学生取得相对较高的学业成绩。舒莹等[10-12]通过采集分析在线学习系统中的行为数据,并基于朴素贝叶斯、多元线性回归、逻辑回归等机器学习算法构建预测模型,实现了精准的学业风险预测。崔炜等[13]通过采集和分析用户知识点的先测能力值、用户已完成知识点的平均用时、其他学习者学习知识点的平均用时等指标,基于线性回归算法构建知识点学习时长预测模型,实现了学习时长预测。
上述研究为开展自适应测验长度预测研究奠定了基础,但是,笔者在查阅国内外相关文献后发现,针对自适应测验长度的预测研究较为匮乏,仅有Knewton公司的Wilson等专门对自适应测验长度进行过相关研究。究其原因,自适应测验长度预测对自适应学习系统的实际应用具有重要的支撑作用,而在理论研究方面不如其他几个研究对象有吸引力。Wilson等[14]通过IRT模型衡量学习者在学习内容时的掌握水平,采用隐语义模型构建单个知识点自适应测验长度预测模型,预测学习者在掌握学习内容之前还需要完成的测验试题数量。该方法中,由于自适应测验长度和其对应的知识掌握水平都是离散型数值,测验长度预测模型中的数据分布不均匀,导致模型的预测准确度不高。
综上所述,国内外学者在学习预测分析方面已开展了大量研究工作,积累了很多研究成果和经验,但仍有亟待改进的地方:首先,多数研究集中在对学业成绩、学业风险和学习时长三个研究对象的预测,针对自适应测验长度的预测研究较少;其次,目前已有的自适应测验长度预测模型,由于数据分布不均匀,导致模型预测准确度不高;最后,多数研究从理论视角研究预测分析,缺少大规模应用场景,用于实验研究的数据量也较少,例如田浩等[15]通过调查25篇预测分析论文的实证研究,发现近一半论文涉及的学习者数量不足200人,超过1 000名学习者的仅有8篇,研究结论缺少说服力。
因此,有必要对自适应测验长度预测开展深入研究。笔者拟基于隐语义模型构建自适应测验长度预测模型,并依托自主研发的大学英语自适应学习平台采集大规模数据进行实验研究,实现对自适应测验长度的精准预测,为自适应学习的实现奠定坚实基础。
三、自适应测验长度预测模型构建
(一)相关技术介绍
1.隐语义模型
隐语义模型(latent factor model, LFM)属于机器学习算法,常被用在推荐系统和文本分类中,在自适应测验长度预测中的应用原理[16]如下:
假设学习者为u,pu=(pu1,pu2,…,puF),即学习者u与隐含特征F之间的关联程度,矩阵PU表示全部学习者与特征因子间的关系。qi=(qi1,qi2,…,qiF)表示知识掌握区间与特征因子之间的关联度,矩阵QI表示全部知识点掌握区间i与特征因子间的关联程度。
自适应测验长度预测矩阵R(m,n)表达式为:
(1)
其次,PU和QI矩阵应用最小化损失函数可得:
(2)
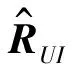
最后,模型通过数据集迭代训练得到矩阵PU和QI后,对于自适应测验长度预测矩阵R(m,n)中的任意一个残缺值位置就可以通过式(1)计算得出预测值。
2.认知诊断模型
认知诊断模型是一种认知评估手段[18],在自适应测验领域通常用来描述学习者在作答某一知识点的题目时,答题情况与题目结果的联系[19]。将知识点的个数作为划分依据,认知诊断模型可分为以IRT模型为代表的单维模型和常见的MIRT,DINA,NIDA等多维模型[19]4;依据时间维度可以分为静态模型(如PMF,FuzzyCDM,NeuralCD等)和动态模型(如BKT,PFA,DKT等)。在自适应测验长度预测中,使用基于项目反映理论的知识点掌握度计算模型[20],其属于单维、动态模型,具体如式(3)所示:
(3)
其中,M表示学习者对某个知识点的掌握度,取值范围在[0,1]之间。N代表学习者所作答题目的数量,取值为常数8,e表示学习者的努力值,预设为常数(如e=0.3),A为理想状态(学生在某一知识点下作答的题目全部正确)下计算出的学习者在这一知识点可达到的最大能力值[20]62,θ为采用项目反应理论的三参数Logistic模型计算得到的学习者能力值[16]2。
(二)知识点自适应测验长度预测模型构建


表1 知识点自适应测验长度预测矩阵
在构造自适应测验长度预测矩阵时,矩阵的列数不宜过大,否则矩阵会比较稀疏。学习者在练习过程中的知识掌握水平通过知识点掌握度计算模型[20]62获得。
由于学习者完成的测验长度和其对应获得的知识掌握水平都是离散型数值,平均切分知识点掌握度区间会导致测验长度预测矩阵中的值分布不均匀,这对模型的预测准确度影响很大,本文的实验环节也证明了预测准确度不高。为了解决这一问题,通过对知识点掌握度区间窗口进行均值池化来优化预测矩阵,解决预测矩阵中值分布不均匀的问题,提高模型的预测准确度。模型的优化过程如下:首先,将某个知识点下所有学习者的所有自适应测验对应的知识点掌握度进行排序;然后,按照每个掌握度区间窗口内的知识点掌握度值的数量相等的原则,将取值范围为[0,1]的知识点掌握度划分为n份,每个掌握度区间的大小不相等;接着,计算每个学习者在每个掌握度区间的自适应测验长度;最后,构造出新的自适应测验长度预测矩阵,矩阵R(m,n)如下所示:
(4)
式中,矩阵行m表示学习者,列n表示新的知识点掌握度区间,ruj表示学习者u达到知识点掌握度区间j时完成的自适应测验长度。
然后,构造训练数据集,对优化后的知识点自适应测验矩阵进行模型训练,得到矩阵PU和QI。
最后,通过式(1)对R(m,n)中的任意一个残缺值进行精准预测。
(三)知识模块自适应测验长度预测模型构建
知识模块是由多个知识点组成的学习单元,知识模块自适应测验长度预测矩阵R(m,n)的构建见表2,矩阵的行U表示学习者,列K表示知识点,矩阵中的数值表示学习者达到某个知识点的掌握目标时完成的测验长度,矩阵中值空缺位置表示学习者没有达到该知识点的掌握目标。因此,得到一个高度残缺的知识模块自适应测验长度预测矩阵。接着,构造训练数据集,对知识模块自适应测验长度预测模型进行训练,得到矩阵PU和QI,最后,通过式(1)对R(m,n)中的任意一个残缺值进行精准预测。
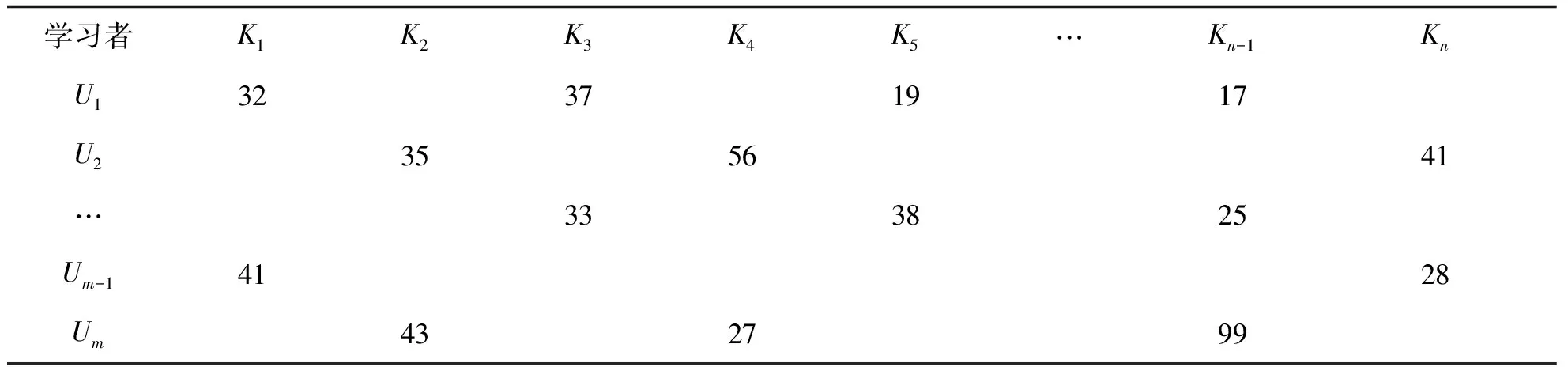
表2 知识模块自适应测验长度预测矩阵
四、实验过程与结果分析
(一)数据集
为了使实验结果准确和可信,实验选择在自主研发的大学英语自适应学习平台采集大规模数据,实验的数据来自平台中的北京成人本科学士学位英语课程。
1.知识模块自适应测验长度预测数据集
数据来自2 454个北京成人本科学士学位英语课程的学习者对23个语法知识模块进行学习所产生的学习记录。数据集按照8∶1∶1的比例切分,分别用于模型的训练、验证和测试。规定user_id表示学习者编号,knowlege_id表示知识点编号,knowlege_name表示知识点名称, praxis_number表示达到该知识点学习目标需要完成的问题数量。
2.知识点自适应测验长度预测数据集
数据来自北京成人本科学士学位英语课程的四个语法知识点的学习记录。其中,主谓一致数据集包含了3 758个学习者对24个问题的学习记录,代词数据集包含了3 321个学习者对27个问题的学习记录,连词数据集包含了6 505个学习者对21个问题的学习记录,名词性从句数据集包含了2 627个学习者对19个问题的学习记录。每个数据集都按照8∶1∶1的比例切分,分别用于模型的训练、验证和测试。数据集中,user_id表示学习者编号,knowlege_id表示知识点编号,knowlege_name表示知识点名称,knowlege_proficiency表示学习者对知识点的掌握度,praxis_number表示达到该知识点掌握度需要完成的问题数量。
(二)实验评价指标
由于自适应测验长度预测模型属于回归模型,实验使用均方根误差(root mean square error, RMSE)、平均绝对误差(mean absolute error, MAE)和平均绝对百分误差(mean absolute percentage error, MAPE)三种常用误差评价指标来衡量模型的预测准确度。预测准确度是指预测值和实际值之间的相近程度,偏差值越低,说明模型的预测准确度越高。RMSE取值范围[0,+∞),0表示最优模型,即预测值与真实值完全一致,误差越大,RMSE的取值越大[21]。MAE取值范围[0,+∞),0表示最优模型,即预测值与真实值完全一致,误差越大,MAE的值越大[21]120。MAPE取值范围[0,+∞),0表示最优模型,大于1表示劣质模型,通常认为MAPE小于0.1时,模型较优且预测准确度也较高。
(三)实验参数设置
在实验过程中,知识点掌握度区间窗口n设置为10个,使用随机梯度下降法训练,模型有四个主要参数需要反复调优,以获得最佳实验结果。参数F表示隐含特征数量,参数a表示学习率,参数λ表示正则化参数,参数ITER_N表示迭代次数。通过多轮实验发现不同参数设置对RMSE,MAE和MAPE指标的影响规律,具体如下:
1.参数F对预测准确度的影响
预测模型在其他参数不变的情况下,F取值越大,RMSE,MAE和MAPE指标的值越小,预测准确度越高。但是,模型的收敛速度越慢。如图1(a)所示,在主谓一致自适应测验长度预测原模型中,当a取值0.000 1,λ取值0.002,ITER_N取值300时,F取值从5到30,当取值为30时,预测准确度达到最高。
2.参数ITER_N对预测准确度的影响
预测模型在其他参数不变的情况下,ITER_N取值越大,而RMSE,MAE和MAPE指标的值不一定越小,当ITER_N取值为某一中间值时才会获得最好的预测准确度。如图1(b)所示,在连词自适应测验长度预测优化模型中,当a取值0.000 1,λ取值0.002,F取值8时,ITER_N取值从100到400,当取值为350时,预测准确度达到最高。
3.参数λ对预测准确度的影响
预测模型在其他参数不变的情况下,λ取值越大,而RMSE、MAE和MAPE指标的值不一定越小,当λ取值为某一中间值时才会获得最好的预测准确度。如图1(c)所示,在知识模块自适应测验长度预测模型中,当ITER_N取值100,a取值0.000 1,F取值10时,λ取值从0.001到0.005,当取值为0.004时,预测准确度达到最高。
4.参数a对预测准确度的影响
预测模型在其他参数不变的情况下,a值越大,而RMSE,MAE和MAPE指标的值不一定越小,当a取值为某一中间值时才会获得最好的预测准确度。如图1(d)所示,在知识模块自适应测验长度预测模型中,当ITER_N取值200,λ取值0.003,F取值20时,a取值从0.000 03到0.000 1,当取值为0.000 08时,预测准确度达到最高。
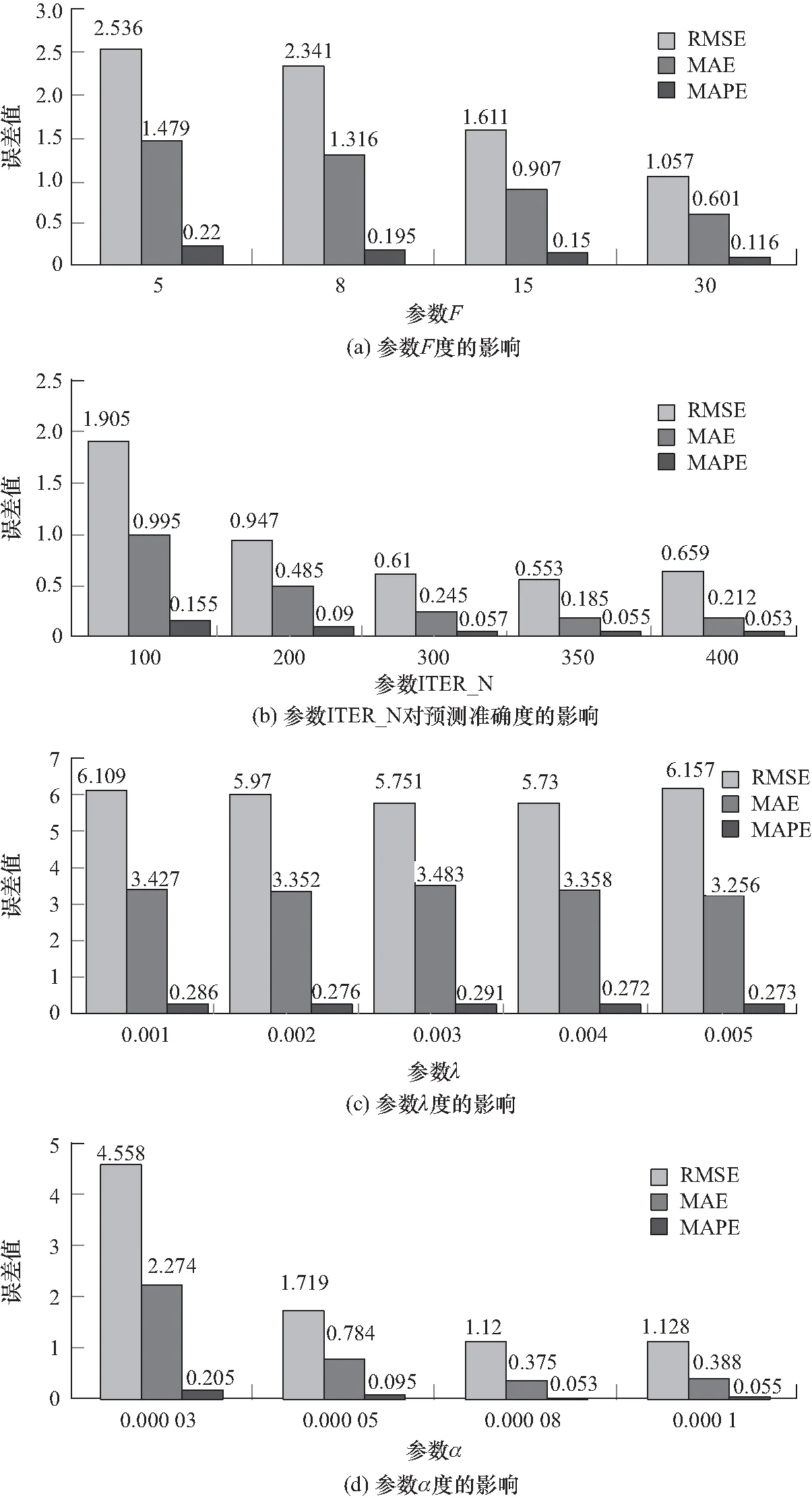
图1 各个参数对预测准确度的影响
此外,实验表明,四个参数相互之间也有影响,F值越大,a越小,要获得较高预测准确度就需要更大的ITER_N值和更多的模型训练时间。所以,需要通过多轮实验,调整参数设置,才可以获得兼顾模型预测精确度和训练时间的最佳模型。
(四)实验结果分析
模型训练完成后,模型的预测准确度通过RMSE,MAE和MAPE三个评价指标进行评价。
1.知识模块自适应测验长度预测模型的预测准确度较高
实验结果表明,经过多轮参数优化调整,知识模块自适应测验长度预测模型的预测精确度较高,且模型训练时间较短。如图2和表3所示,当参数组合为P11时,即参数F取值20,a取值0.000 08,λ取值0.003时,ITER_N取值200,评价指标RMSE值为1.12,MAE值为0.375,MAPE值为5.3%,这三个指标的值都非常小,说明预测值与真实值非常接近。其中,指标MAPE值远小于10%,这说明模型的预测准确度较高,属于优质模型。同时,由于参数F和ITER_N的取值不高,所以,模型的训练时间也比较短。
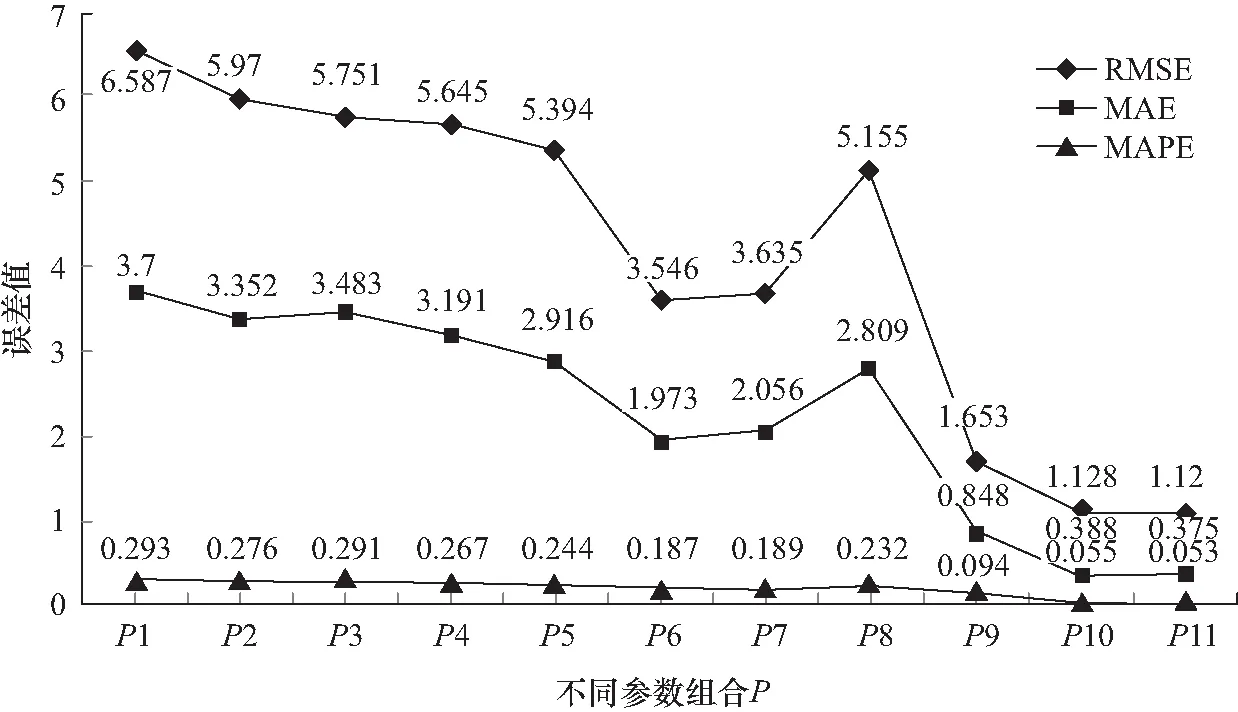
图2 不同参数组合下知识模块自适应测验长度预测准确度比较
不同参数组合下RMSE,MAE和MAPE指标比较见表3。
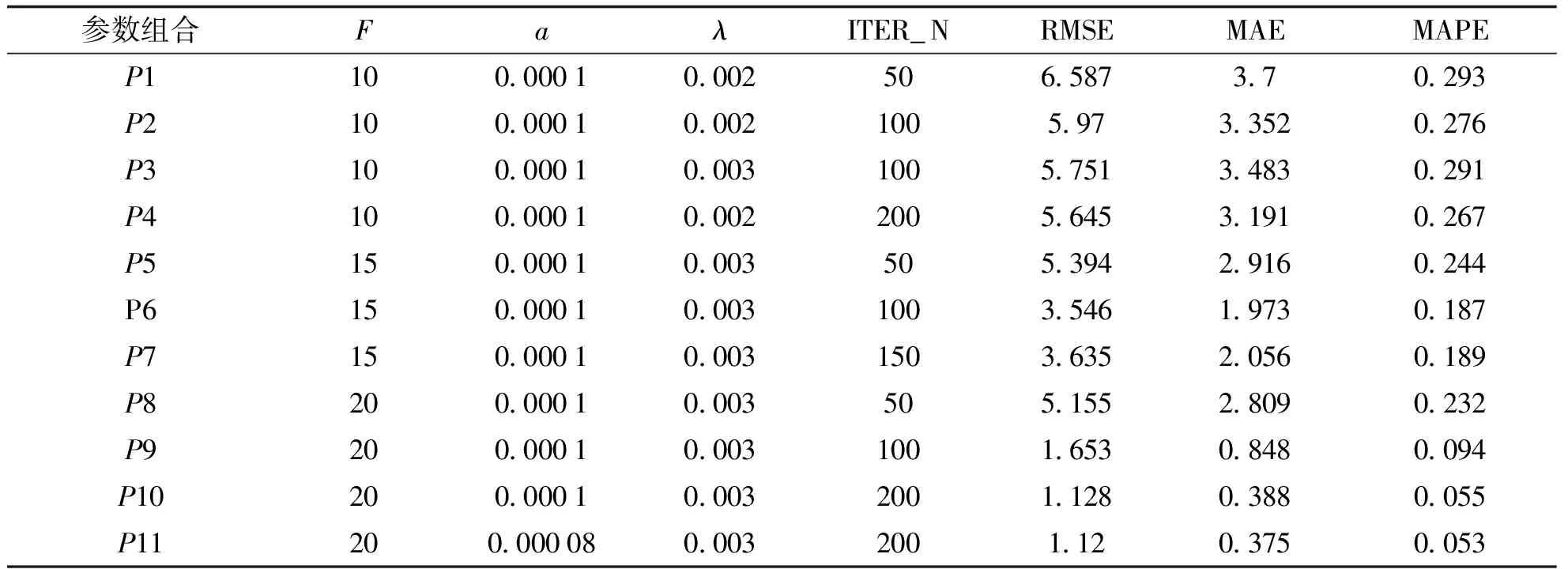
表3 不同参数组合下RMSE、MAE和MAPE指标比较
2.优化后的知识点自适应测验长度预测模型与原模型相比,预测准确度大幅提高
实验结果表明,优化后的知识点自适应测验长度预测模型比原模型的预测准确度有大幅度提高。如图3(a)所示,优化后的主谓一致自适应测验长度预测模型与原模型相比,RMSE值降低了59.18%,MAE值降低了60.78%,MAPE值降低了33.33%;如图3(b)所示,优化后的代词自适应测验长度预测模型与原模型相比,RMSE值降低了36.06%,MAE值降低了47.09%,MAPE值降低了34.69%;如图3(c)所示,优化后的连词自适应测验长度预测模型与原模型相比,RMSE值降低了77.13%,MAE值降低了82.77%,MAPE值降低了35.19%;如图3(d)所示,优化后的名词性从句自适应测验长度预测模型与原模型相比,RMSE值降低了43.9%,MAE值降低了53.11%,MAPE值降低了16.67%。

图3 四个语法知识点预测模型优化前后预测准确度比较
3.优化后的知识点自适应测验长度预测模型与原模型相比,模型训练时间大幅减少
实验结果表明,优化后的知识点自适应测验长度预测模型比原模型的训练时间大幅度较少。如表4所示,优化后的主谓一致自适应测验长度预测模型与原模型相比,参数F值减少了66.67%,参数ITER_N值减少了12.5%;优化后的代词自适应测验长度预测模型与原模型相比,参数F值减少了66.67%,参数ITER_N值减少了14.29%;优化后的连词自适应测验长度预测模型与原模型相比,参数F值减少了66.67%,参数ITER_N值减少了33.33%;优化后的名词性从句自适应测验长度预测模型与原模型相比,参数F值减少了66.67%,参数ITER_N值减少了25%。由于隐含特征数量F和迭代次数ITER_N决定了模型的训练时间,所以,优化后的模型训练速度比原模型要快很多。

表4 模型优化前后的参数和评价指标比较
五、结论与建议
本文基于隐语义模型提出了知识模块自适应测验长度预测模型,并对已有的知识点自适应测验长度预测模型进行了优化。结果表明,知识模块自适应测验长度预测模型的预测准确度较高,完全能满足实际应用需要;优化后的知识点自适应测验长度预测模型与原模型相比,预测准确度大幅提高;优化后的知识点自适应测验长度预测模型与原模型相比,模型训练时间大幅减少。模型能够以优异性能准确预测自适应测验长度,研究成果对自适应学习系统的实现有重要意义。
基于上述研究结论,提出三个自适应测验长度预测在自适应学习中的应用建议。首先,在针对某一知识点的学习中,学习者可以借助自适应长度预测直观感受自身的学习进程的快慢,从而减少学习者的心理抗拒,当自适应学习系统通过测验长度预测感知到学习停滞不前时,会及时为学习者提供必要的推荐干预;其次,在知识模块学习过程中,通过知识模块自适应测验长度预测,使学习者在开始学习之前就能知道掌握这些知识需要完成多少问题或作业,若将预测结果与知识图谱的学习路径相结合,可以帮助学习者在正式学习开启前有计划地对自身学习进行规划,进而提升学习效率;最后,在自适应学习中,基于自适应测验长度预测,自适应学习系统会生成最优的个性化推荐策略,例如,当考试临近时,通过自适应测验长度预测,自适应学习系统可能战略放弃推荐难度较大且测验较长的知识点,保证学习者能够在有限的时间内掌握最多的知识点,在考试中获得最好的成绩。
此外,本文存在一定局限性,基于隐语义模型的自适应测验长度预测模型也存在一些缺点。首先,由于模型的训练时间将随训练数据量的增加而增加,故模型不适合做实时预测,所以,只能隔一段时间训练一次模型,无法实现真正的实时预测;其次,由于模型中使用的隐含因子与结果间无明显联系,故模型不具备较好的解释性;最后,模型的“冷启动”问题,如有新知识点或者新知识模块加入,由于没有历史测验数据,所以,模型无法训练和预测。
未来,将重点在两个方面展开进一步的研究。一是面向自适应学习系统中的基准评估应用场景,研究基于隐语义模型和多维动态认知诊断模型的多维知识点自适应测验长度预测;二是研究基于知识的自适应测验长度预测模型,根据学习者和领域知识的属性相似性来预测自适应测验长度,解决现有模型的“冷启动”问题。
