电网总调调度信息披露不平衡性数据处理模型
2022-09-14侯方迪高卫东
侯方迪,高卫东,张 勇,翟 哲,杨 凡,吴 亮
(中国南方电网有限责任公司,广东广州 610106)
电力供应一直是电力企业的核心业务,随着电力设备的改造和升级,对调度可靠性要求越来越高,通过传统的电话下令模式进行调度已经无法满足要求,通过移动网络及调度数据网实现配网调度成为当下的主流方式[1]。然而,这种新兴的调度模式兴起时间较短,发展并不成熟,普遍存在披露的数据信息内容杂乱,缺乏深层次统计和分析的问题。
披露的数据信息内容杂乱主要是由不平衡性数据造成的,因此必须对不平衡性数据进行处理。关于不平衡性数据处理的研究有很多,如:文献[2]基于KFDA-Boosting 算法的不平衡数据分类模型,提取样本非线性特征并进行集成学习,有效地提高了数据分类处理算法的精度,去除了冗余信息;文献[3]提出基于随机森林算法的不平衡大数据动态分类方法,通过随机森林算法建立大数据动态分类基本框架,利用决策树模型实现不平衡数据分类;文献[4]提出基于SMOTE 的不平衡数据分类算法,通过SMOTE算法根据少数类样本间特征空间的相似性人工合成新样本,解决了数据不平衡的问题,提高了数据处理的精度。
基于前人的研究成果,为提高披露数据信息的完整性、规范性和有效性,该文构建了一种电网总调调度信息披露不平衡性数据处理模型。该模型构建分为3 个步骤,即数据预处理、数据特征提取以及数据分类。最后进行不平衡性数据处理性能测试,证明了该模型的准确性和有效性。
1 基于分类器的不平衡性调度数据处理模型
调度机构信息披露对于促进电力调度运行的公开透明以及维护公平、有序的市场秩序发挥着不可替代的作用。然而,当前的电网总调调度信息披露中,数据处理部分由于不平衡性数据的存在,导致处理效率差、准确性低。不平衡性数据的典型特点就是数据中各类别所包含的样本数量差异较大,导致在后期的分类中更容易识别包含样本较多的类别,而包含样本较少的类别的识别准确性较低。面对电网总调调度信息披露不平衡性数据,构建了数据处理模型。
1.1 不平衡性数据预处理
不平衡性数据预处理对于提高数据处理模型的精度具有十分重要的意义,其主要包括数据清洗、数据标准化以及数据平衡化三部分。
1.1.1 数据清洗
电网总调调度披露的数据信息中,经过采集、传输等环节,数据集中难免存在缺失、异常、噪声等问题,数据清洗主要包括缺失填补、异常识别以及噪声处理,其方法如表1 所示。

表1 数据清洗方法
1.1.2 数据标准化
电网总调调度信息披露不平衡性数据来自不同的数据源,因此每种类型数据的量纲都不同,而不同的量纲导致数据彼此之间无法进行比较和分析,因此需要对数据进行标准化处理[5],主要包括Min-Max 标准化、正规化方法及log 函数转换法,分别如下所示:
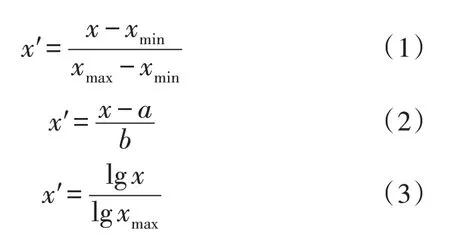
式中,x′为规范化后的大数据;x为原始数据;xmax为大数据集中最大值;xmin为大数据集中最小值;a为对应特征均值;b为标准差。
1.1.3 数据平衡化
数据的不平衡性是导致电网总调调度数据信息处理精度不高的根本原因,因此对数据进行平衡化处理是解决上述问题的关键。数据平衡化的关键在于增加少数类别的样本数据,使其与少数类别的样本数据数量相同,以维持二者平衡[6]。采用SMOTE算法实现数据平衡化,其原理为在一些位置距离较近的少数类样本中线性插入新的样本,以达到数量平衡。
SMOTE 算法数据平衡化原理如下:首先从少数类样本点中随机选取一个样本点,记为x1,然后寻找该样本点的同类近邻,记为{x1,x2,…,xn},一般情况下n取值为5~10,接着从{x1,x2,…,xn} 中随机选择一个样本,记为x2,再然后计算x1和x2在对应属性j上的差值,记为:

然后与[0,1]范围内的一个随机数相乘,再与x1j相加,即可生成一个新的的属性值f1j,即:
利用SSR分子标记技术进行纯度鉴定时,有些与杂交种带型有明显差异的单株在种植鉴定时并不一定表现出表型性状的差异,因此SSR分子标记技术用于纯度鉴定时,可以有效鉴别出大田无法确定的表型以及难以鉴别的植株,因而分子鉴定和种植鉴定结果必然存在一定的差异,而种植鉴定是最符合生产实践的纯度鉴定方法,如何使分子鉴定结果更接近种植鉴定、更好地辅助种植鉴定结果还需进一步研究。
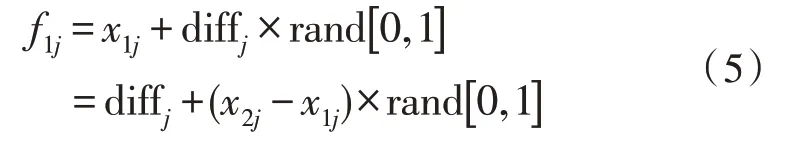
不断重复上述过程,最后得到m个属性值,将其组合在一起,产生一个新的少数类样本,将这一新的少数类样本加入到原始少数类样本数据集中,即可完成数据平衡化处理[7-9]。
1.2 数据特征提取
不同类别的数据拥有不同的特征,如电网总调调度信息中的缺失数据、趋势突变数据等。该文选用的特征提取方法为人工蜂群算法[10-12]。
人工蜂群算法基本流程如下:
步骤1:初始化种群,随机生成S个可行解,记为xi,i=1,2,…,S;
步骤2:计算种群中各蜜蜂的适应值[13];
步骤3:重复计算各蜜蜂的适应值,得到蜂群新的解,记为vi,并计算适应值;
步骤4:雇佣蜂根据贪心策略选择蜜源;
步骤5:计算引领蜂找到蜜源xi的概率pi;判断蜜源xi是否满足被放弃的条件,若满足,对应的引领蜂角色变为侦察蜂,并随机产生一个新的蜜源代替旧的蜜源,否则继续进行下一步骤;
步骤6:判断算法是否满足终止条件,若满足,则终止,记录最优解,否则转到步骤2[10-12]。
1.3 不平衡性数据分类处理
基于上述研究,构建分类器并进行训练,利用训练好的分类器进行不平衡性数据分类处理[14]。决策树是一种分类算法器,其构建基本原理是通过递归的方式进行属性归类,生成不同的决策树,基本流程如图1 所示。
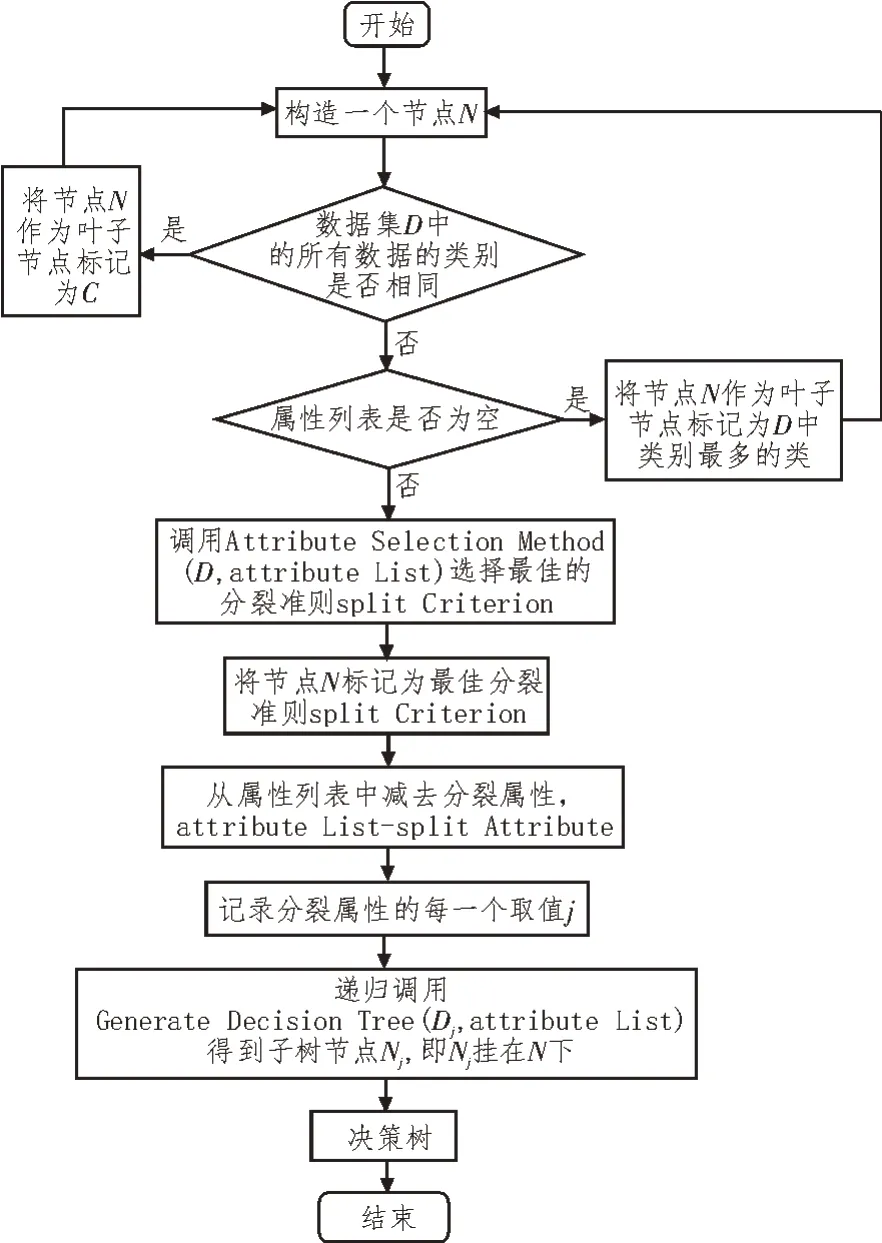
图1 决策树构建基本流程
将构建的决策树作为基分类器,构成随机森林,实现分类[15]。具体过程如下:首先利用Bagging 方法进行放回抽样,为每棵决策树产生训练集,然后利用训练集训练决策树[16]。训练完成后,将决策树组合构成随机森林,最后将测试数据集输入到随机森林中,通过投票方式完成分类预测。
2 仿真实验分析
为了验证该文提出的电网总调调度信息披露不平衡性数据处理模型的有效性,在Eclipse 环境下的Weka 平台进行仿真实验,并用文献[2]、[3]、[4]提到的3 种算法作为对比项,进行对比分析。
2.1 实验样本
以红水河水库日来水数据为例,选取2020.01.01-2020.03.31 的日来水数据作为不平衡性数据示例,仿真实验参数设置如表2 所示。

表2 仿真实验参数设置
2.2 实验结果
分别采用文献[2]、[3]算法及所提方法对实验数据中的不平衡性数据进行分类处理,得到2020.01.01-2020.03.31的红水河水库日来水数据趋势如图2所示。
分析图2,该文模型对不平衡性数据的处理性能较好,按照日来水数据整体趋势对不平衡性数据进行处理,得到红水河水库日来水数据趋势整体在2 200~2 800 m3/s 之间波动,而两种文献对比模型对数据的处理性能较差,不能很好地得到红水河水库日来水数据趋势。
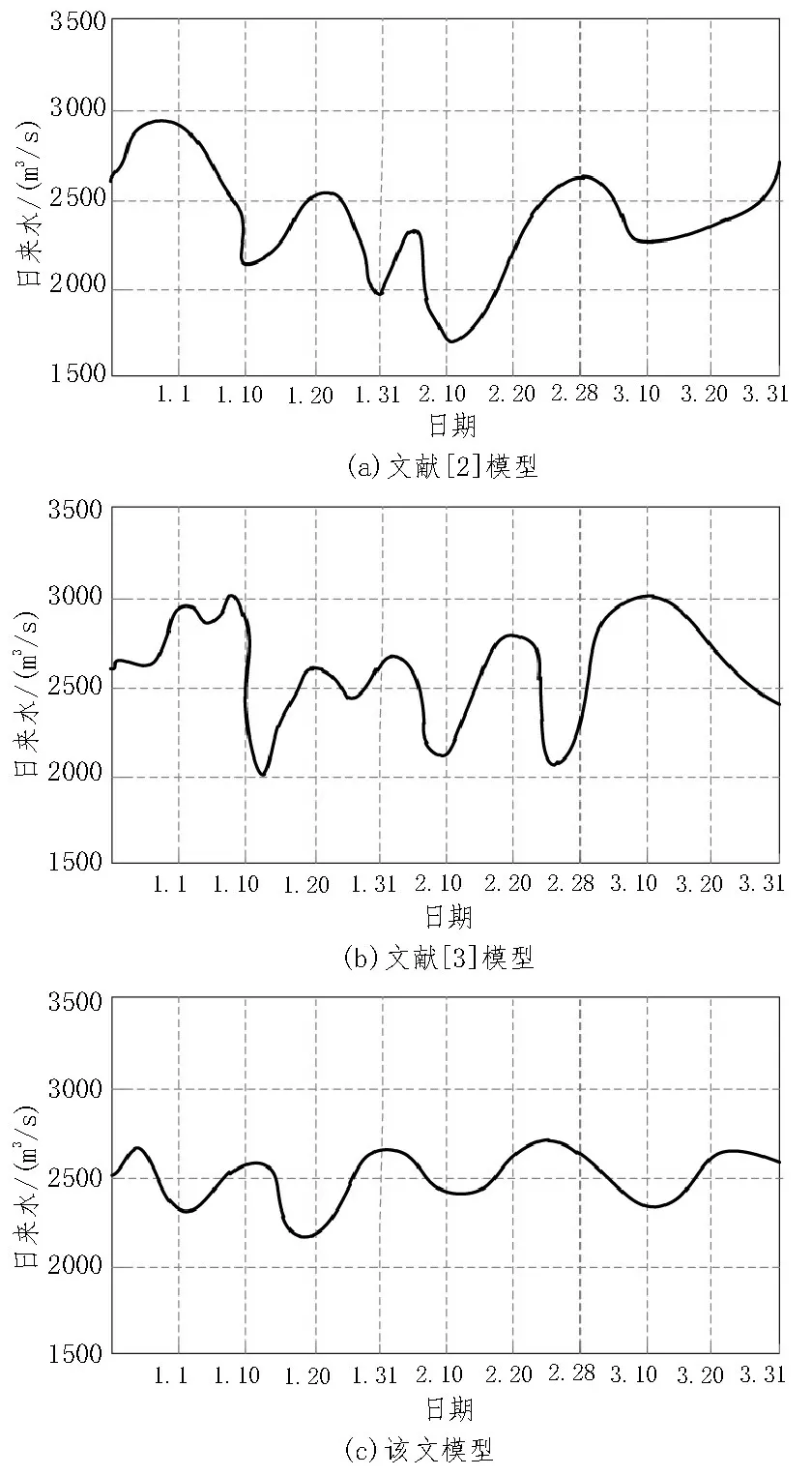
图2 不平衡数据处理后的红水河水库日来水数据趋势
经不同方法对数据处理后,根据所得数据趋势对2020.04.01-2020.04.31 的数据进行预测,得到红水河水库日来水数据预测结果如图3 所示。
分析图3,该文模型预测值与实测值较为接近,说明该文模型能够准确处理不平衡性数据,实现水库日来水情况的预测。
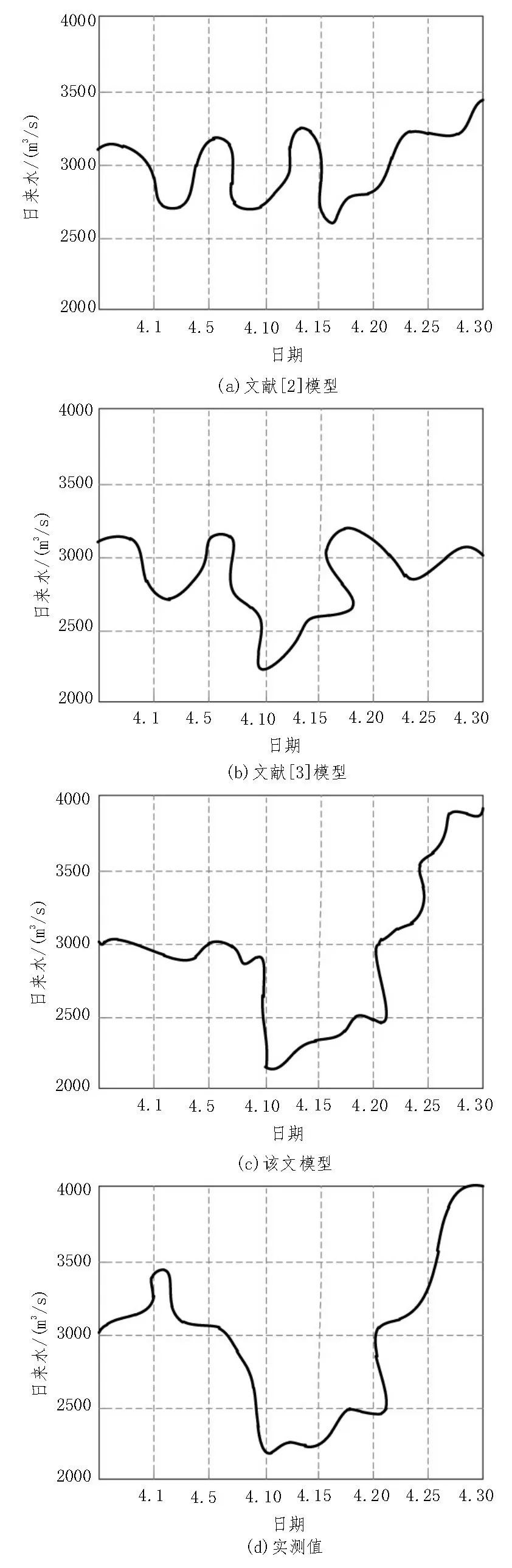
图3 红水河水库日来水数据预测情况
3 结束语
综上所述,随着电力的需求范围越来越广泛,对电力调度的可靠性和效率性要求越来越高,因此,电网总调调度信息披露系统逐渐取代传统的调度信息传递方式,提高了数据信息传递效率,然而披露系统的应用,同时也使数据信息量剧增,导致数据信息内容杂乱,缺乏深层次的统计和分析。基于此,构建一种电网总调调度信息披露不平衡性数据处理模型,该模型经仿真实验测试,证明了其在不平衡性数据处理中的性能,提高了不平衡性数据处理的精度,规范了电网总调调度数据信息。
