基于深度学习的司法判罚研究
2022-09-14高珊何安娜肖清泉
高珊,何安娜,肖清泉
(贵州大学大数据与信息工程学院,贵州贵阳 550025)
随着大数据时代的来临,人民法律意识的加强和法律的普及已不仅仅局限于司法部门。大数据与司法相结合已成为必然趋势[1]。早期文献采用N-gram进行司法智能研究,属于利用浅层的文本特征,准确率较差[2-3]。Daniel 等人采取了人工提取案件显著特征的方式进行美国法院的判决预测[4],准确率提高了,但耗费了时间及精力。Hu 等人提出利用注意力机制模型解决司法判罚任务[5],模型结合罪名问题和相关法条,法条被充分利用,但对法条的监督信息存在一定限制。该文利用CNN+GRU-Attention 技术,充分利用罪名信息并且对监督信息没有限制。
1 司法判罚模型的数据处理
1.1 数据集介绍及分析
数据来源于法研杯大赛,约有20 万条文本数据。单项罪名约有12 万条,占训练集78%。出现次数最多的罪名数量约为次数最少的2 000 倍,因此数据分布不均匀,此外数据中有较多易混淆罪名,易混淆罪名将影响模型性能,因此对易混淆罪名的处理是数据处理的关键。
1.2 数据处理
针对易混淆罪名,该文采用提取要素维度关键特征的方式来区分易混淆罪名,易混淆罪名的处理流程如图1 所示,以易混淆罪名“抢夺”“抢劫”为例,对整个处理流程进行分析。
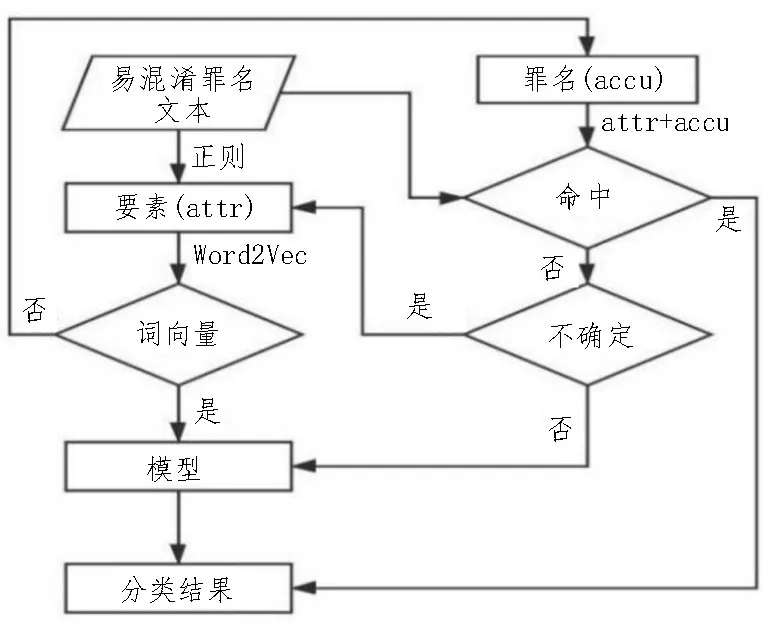
图1 易混淆罪名处理流程
第一步:分析易混淆罪名法条:抢劫罪指暴力对人实施或者对人加物实施,抢夺罪指的是暴力对物实施。第二步:提取易混淆罪名要素。抢劫罪要素:暴力+人/暴力+人+物;抢夺罪要素:暴力+物。通过正则表达式对文书提取“暴力”的词汇,“受害人”词汇以及“物品”词汇,将提取的“暴力+人+物”设置为抢劫罪要素attr1,将提取的“暴力+物”设置为抢夺罪要素attr2。第三步:处理易混淆罪名要素。方式一:直接由Word2Vec 转化为词向量,在输入模型的全连接层中参与模型训练,提高模型对易混淆罪名的分类准确性。方式二;将要素与罪名进行强绑定,每个要素设定三个值,分别为命中、不命中、不确定。将输入样本在要素上作三分类预测。
2 建立司法判罚模型
2.1 司法判罚模型实验步骤
该文提出CNN+GRU-Attention 网络的判罚模型,具有卷积神经网络和GRU 网络的共同特点[6-7]。模型结构如图2 所示。
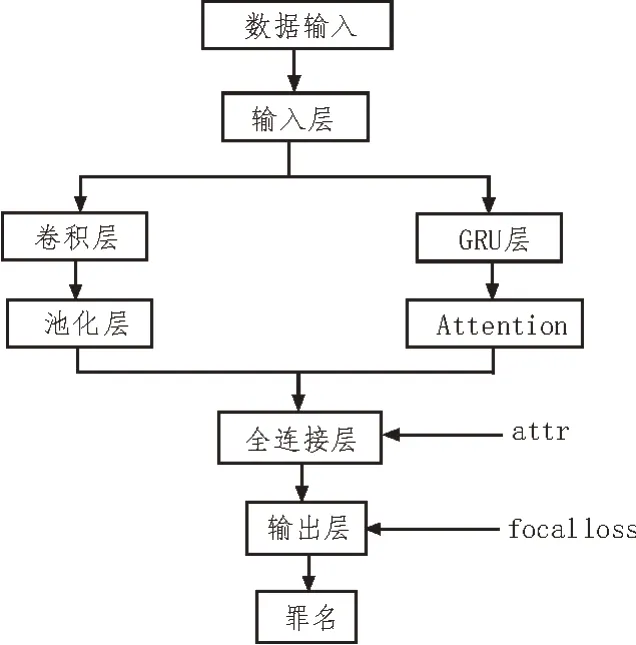
图2 CNN+GRU-Attention模型结构图
输入层:司法事实描述X={A1,A2,…,An},向量化后X={x1,x2,…,xn}。卷积层采用多尺寸卷积核,一个卷积核的特征输出如式(1)所示,高度为h,宽度为k,对h个词进行卷积操作。
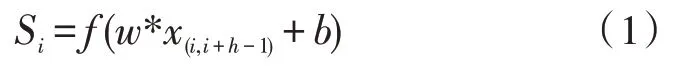
其中,w是值矩阵参数,b是偏置项,x是输入的特征值,表示第i行到第i+h-1 行的局部特征,Si为输出的特征值,多个卷积核可得到多个特征。
池化层:池化层采取了最大池化操作,池化后的特征如式(2)所示:
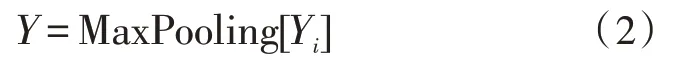
GRU 层:采用双向GRU 网络在编码层对数据进行双向编码,如式(3)所示,编码后生成隐层向量,将隐层向量进行拼接,如式(5)所示,拼接后向量hi融合了司法文书的上下文语义信息。
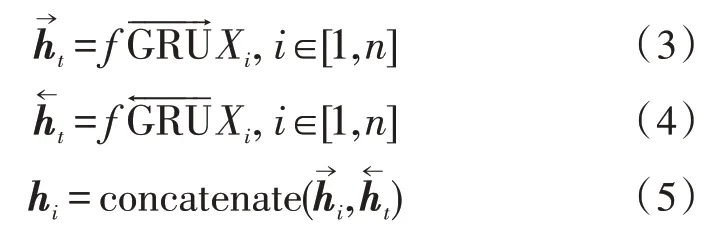
Attention 机制:将GRU 层编码后生成的特征向量与注意力层的权值相乘,将每条文本对应罪名的词级特征整合为句级特征。将hi输入到Attention中,Attention 处理后输出中间向量mi,如式(6)所示:
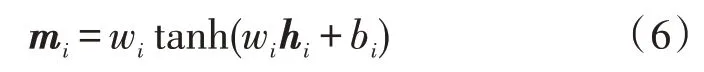
mc是实际向量,输出向量mi与实际向量余弦相似度,求取各个词语的注意力权重为αi,αi的计算公式如式(7)所示:
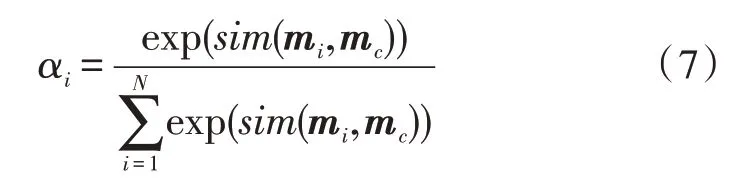
根据权重系数对输出的拼接向量hi进行加权求和得到Hi,将求和得到的多个向量进行拼接,拼接后的矩阵为H,H如式(8)所示:
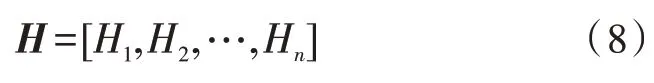
全连接层:全连接层采用ReLu、Dropout,并且加入了易混淆罪名要素,增加了模型对易混淆罪名区分的准确率。
输出层:经过softmax 函数运算后得到判罚结果。在输出层加入损失函数来解决罪名分布不均匀问题。focal loss 主要通过降低常见罪名权重,使模型关注于罕见罪名,进而解决罪名分布不均匀的情况。focal loss 是在交叉熵loss 基础上进行了改进[8-9],该文的判罚模型本质是多标签文本分类,因此将二分类focal loss展开为多标签分类focal loss公式如(9)所示:
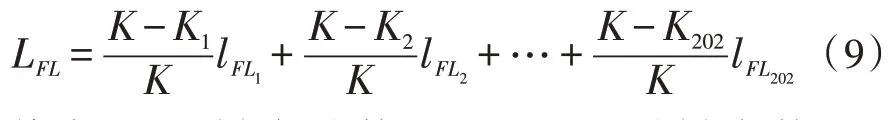
其中,K是样本总数目,K1是lFL1时样本数目。focal loss 的最终损失为202 种罪名损失加权值总和。模型参数较多增加了负担[10-12],因此需分组来设置参数,具体参数如表1 所示。

表1 focal loss参数设置
2.2 模型参数设置
优化模型具体参数设置如表2 所示。
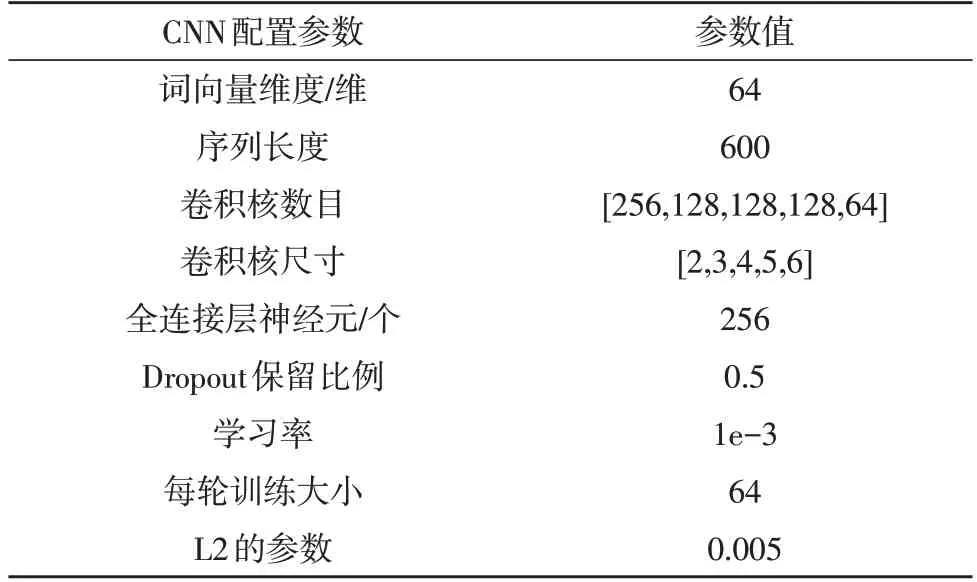
表2 优化模型参数配置
2.3 实验结果及分析
将加入交叉熵loss 与focal loss 的模型进行性能对比,如表3 所示。

表3 模型性能对比实验
采用focal loss 各项评估指标均高于交叉熵loss,Accu 提升了1.82%,Pre 提升了0.45%,Rec 提升了1.62%,F1 提升了1.62%,因此focal loss 能够使模型性能得到提升[13-14]。因为focal loss 函数增加了罕见罪名权重,减少了常见罪名权重,令模型对难以训练的标签进行学习,从而提升模型性能[15-16]。加入其他司法判罚模型进行对比分析,各F1 值模型对比结果如表4 所示。
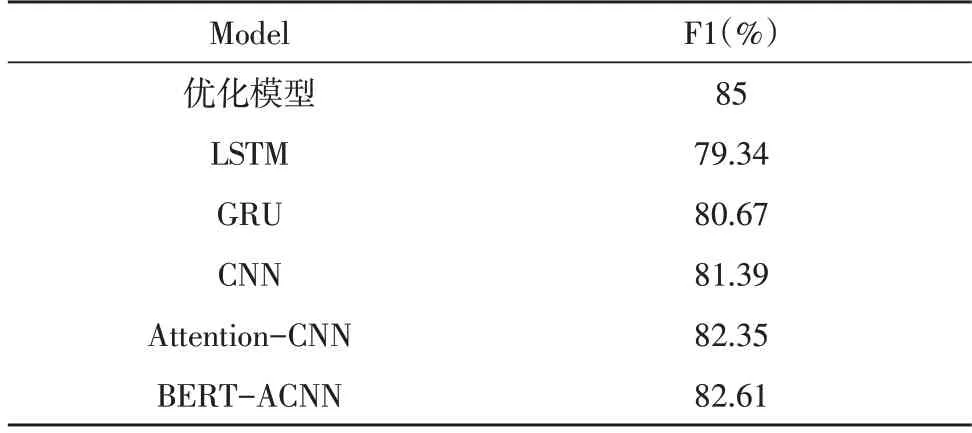
表4 各模型F1值对比
表4 加入了文献[16]中的模型,通过对比分析得出如下结论:Attention-CNN 模型F1 值大 于CNN 模型,则加入了注意力机制模型能够获得更多语义信息。该文的模型F1 值最大,其次为CNN 类模型,最后是RNN 类模型,所以罪名预测时更多依据文书中的关键词,而不是上下文语境信息。
3 基于深度学习司法判罚系统
3.1 系统设计
系统总体设计流程图如图3 所示。
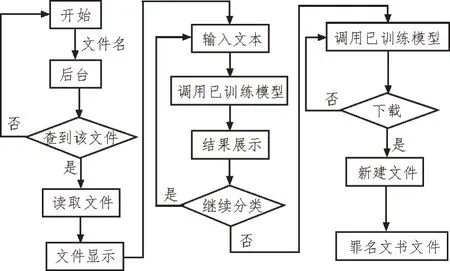
图3 系统总体设计流程图
1)文本显示。点击页面文档,文件名将被传回后台,在后台存储路径中找到该文件并进行读取,将读取后内容显示到前端页面。2)文本分类。读取数据并且调用司法判罚模型进行分类,分类结果显示到前端页面。3)文本生成。点击下载后,在本地新建文件,将已分类的文本写入到新建文件中,则在本地存储了罪名文书文件。
3.2 系统测试
用户选中目标件,右侧显示出文件名以及文件内容。点击“分类”按钮,分类结果被展示出来,如图4 所示。用户点击“设置”选项,进入个人信息页面,点击“信息修改”按钮即可完成修改,如图5所示。罪名分类文书生成如图6 所示,将分类后的文书以及分类结果生成文档,点击下载按钮下载到本地。
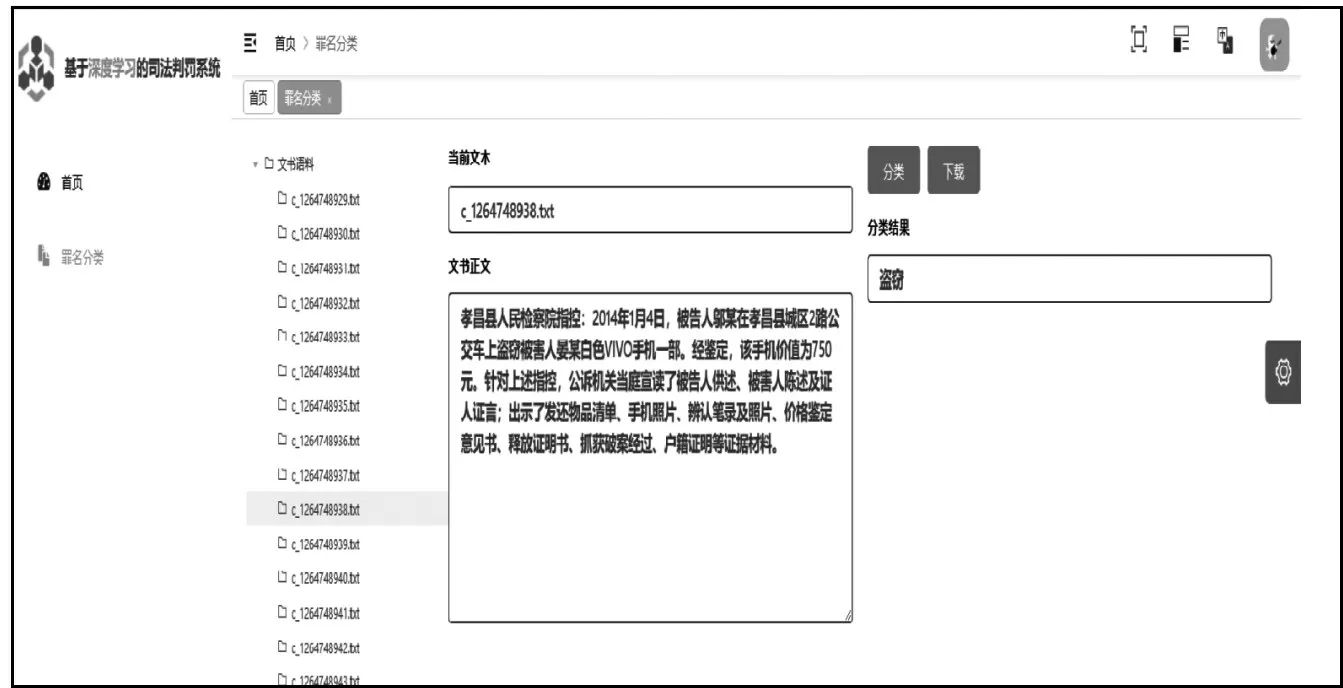
图4 罪名分类页面
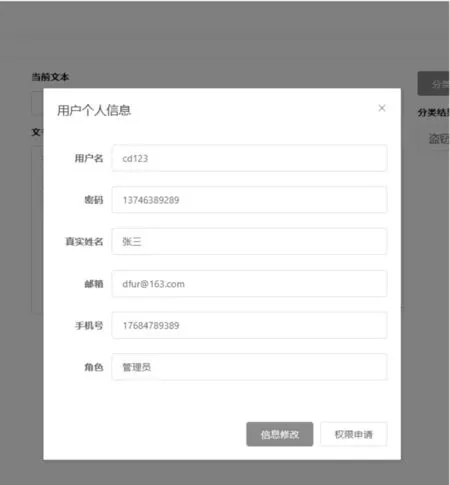
图5 用户个人信息页面
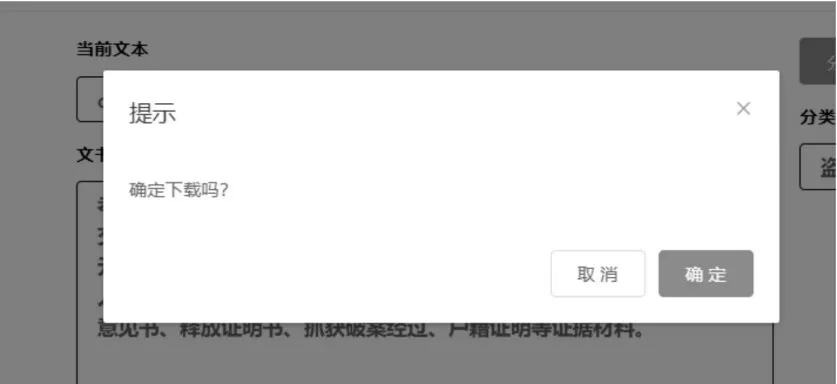
图6 罪名分类文书下载页面
4 结论
该文采用提取要素维度关键特征方式区分易混淆罪名,模型输出层加入focal loss 函数,解决了数据不均衡问题,通过实验对比得出:文中模型加入focal loss,相比于交叉熵函数Accu、Pre、Rec、F1 性能提升了1.82%、0.45%、1.62%、1.62%。最后建立了司法判罚系统,实现了罪名分类以及罪名分类文书生成功能,通过测试验证了系统的有效性。
