基于多视图多核学习的弥漫大B细胞淋巴瘤预后分类*
2022-09-14阳桢寰张岩波余红梅郑楚楚赵艳琳李雪玲赵志强罗艳虹
阳桢寰 张岩波 邢 蒙 余红梅 郑楚楚 赵艳琳 李雪玲 李 琼 赵志强 周 洁 罗艳虹△
【提 要】 目的 为更加充分地利用弥漫性大B细胞淋巴瘤患者的电子病历数据,挖掘其内部的区别与联系,以提高疾病预后模型性能,为进一步的临床治疗提供参考。方法 现使用多视图多核的机器学习方法对疾病预后进行建模。对电子病历中患者的病理信息、影像资料以及诊断治疗记录这三个方面分别进行数据收集与整理,将收集到的三类特征经预处理与重采样,用核函数分别映射至三个核空间,最终运用多视图多核学习得到合成核进行预后分类。将目标模型的分类结果与逻辑回归,决策树等经典模型进行对比。结果 通过十折交叉验证,目标模型性能(accuracy=0.977,AUC=0.970,precision=0.981)均高于常见模型,且多视图多核学习的模型性能优于混淆特征的多核或单核学习。结论 通过多视图多核学习的建模方法,更能够挖掘出电子病历数据中的有效信息,模型性能优越,可为临床工作者进一步的诊断与治疗方案选择提供一定参考。
弥漫性大B细胞淋巴瘤(diffuse large B-cell lymphoma,DLBCL)是一种常见的侵袭性B细胞淋巴瘤,约占非霍奇金淋巴瘤的30%~40%。据相关统计表明,DLBCL已成为发病率逐年增长的恶性肿瘤之一[1]。由于DLBCL具有高度异质性,现阶段临床上主要进行化疗,虽然化疗的有效性较高,但化疗敏感性会影响总体效果,远期预后不佳[2]。大部分患者经过治疗可以达到完全缓解,但其中仍有小部分患者在治疗过程中出现缓解后复发,这类患者难以获得长期的无病生存。针对复发难治性DLBCL,自体造血干细胞移植可作为该类患者的挽救治疗手段[3]。故若不进行准确的疾病预后判断,重复对复发难治型患者进行一线治疗,不仅会错过二线挽救治疗的时机,也会给患者带来心理负担和经济压力。而若对早期可治性患者采用R-CHOP联合其他辅助疗法,则可以很大程度提高其生存率[4]。因此,对DLBCL的疾病预后情况进行精确的分类预测有较大的现实意义。
由不同途径或层面获得的数据被称为多视角数据,其表现的是同一对象分布在不同特征空间中的属性。多视图学习是分析多视角数据的机器学习方法,其不仅分析同一视图数据内部的关联,也能发现不同视图数据间的差异性与一致性,从而挖掘出多视角数据中隐藏的有效信息,使得分类结果更加准确。在医学领域内,数据来源各异,之前的研究均不加区分地直接利用,这样不仅会减弱不同类型特征向量之间的区别,并且使得特征向量失去了原有意义[5]。因此,本研究针对DLBCL患者,分别从不同来源(患者病理信息、影像所见、诊断治疗记录)收集数据作为不同的数据视图特征,通过核方法映射至各核空间,再利用多视图多核学习得到合成核进行预后分类,以最终达到提高预后分类模型性能的效果。
方法及原理
本研究以DLBCL患者经过住院治疗后是否复发作为分类依据,方法可分为五个部分:数据收集、数据处理、核方法、多视图多核学习、评价指标。
1.数据收集
数据来源于某医院2011-2017年被诊断为DLBCL并通过一线化疗方案治疗后达到完全缓解的病例共518例,随访至2020年12月底,其中三年内复发的人数为96例。根据《NCCN Guidelines Insights:B-Cell Lymphomas,Version 3.2019》[6]及电子病历记录情况,分别收集患者数据,其中病理信息138维,影像资料所见60维,诊断治疗记录12维,共计210维特征。
在特征选择时使用特征递归消除法[7-8],递归特征消除的主要思想是反复地构建模型(本研究使用支持向量机为分类器,故以支持向量机为基础模型筛选特征),得到不同的特征子集,在此基础上使用交叉验证法得到表现最优秀的特征子集。经递归特征消除筛选后,共25维特征进入模型,具体赋值情况如表1。
2.数据处理
(1)数据预处理
由于本研究样本量小,对于数据集中少数的缺失值和异常值,不采用直接丢弃的方法,使用将连续性变量按中位数填补,将分类变量按多数类填补。同时为保证不同的变量值位于相同取值范围内,本研究采用最大最小化[9]的方法进行归一化。
(2)SMOTE采样
在DLBCL患者中,30%患者在达到完全缓解后的三年内复发,造成数据的类别不平衡。其中未复发人群是复发人群人数的2~3倍,同时复发患者的失访率较高,本研究数据的类别不平衡率在4~5倍之间[10]。近年来大量研究表明,数据中类别不平衡问题严重影响着预测模型的分类准确率[11],其中对于少数类样本的准确率更低,而对少数类样本的准确预测往往是研究的目的所在。
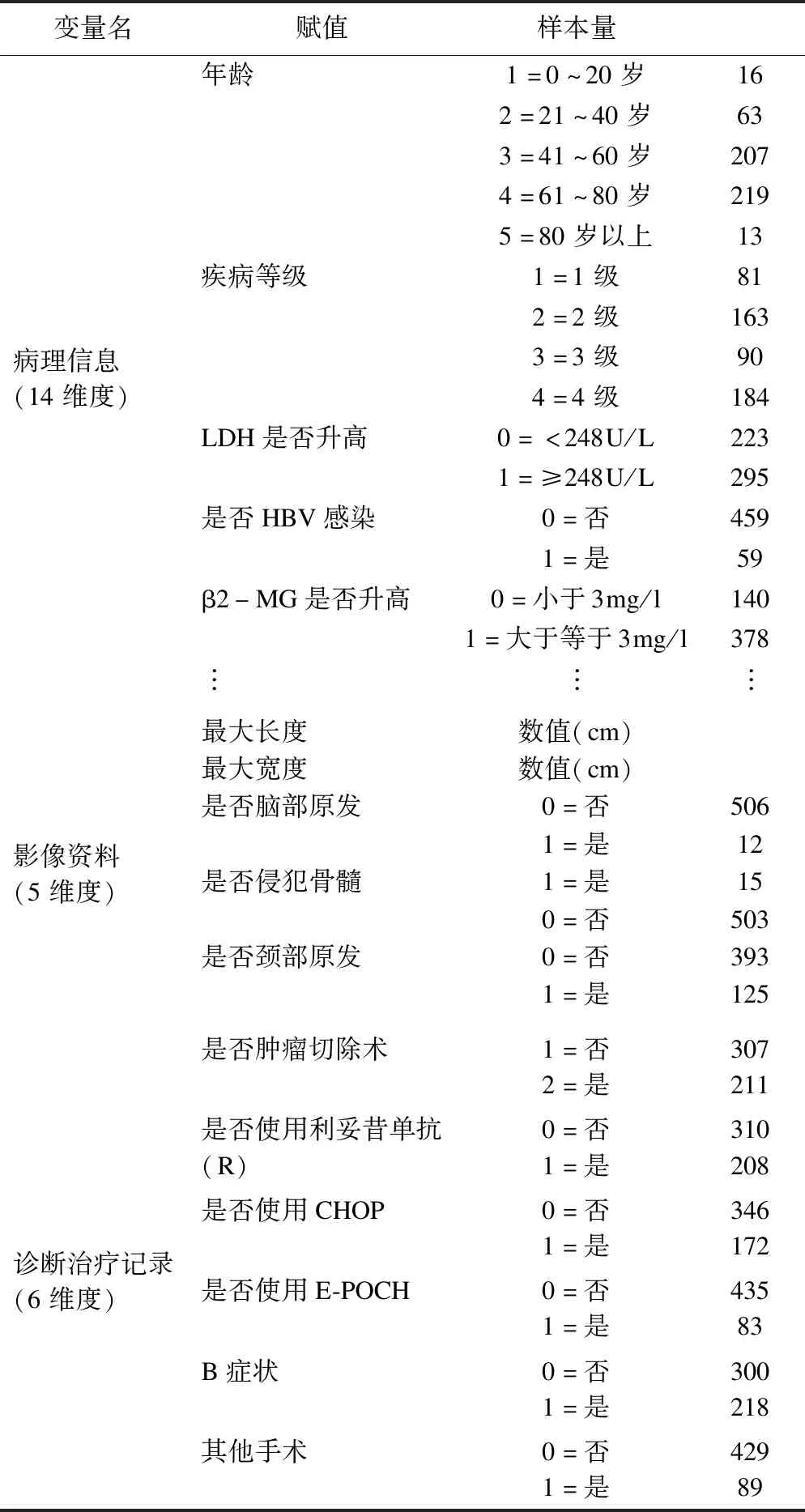
表1 变量赋值情况
SMOTE(synthetic minority oversampling technique)[12]是目前公认的性能较优的解决方法,并已被广泛应用于处理计算机视觉[13]、医学诊断[14]与欺诈识别[15]等多领域数据的类别不平衡问题。如图1所示,SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
xnew=x+rand(0,1)×(xn-x)
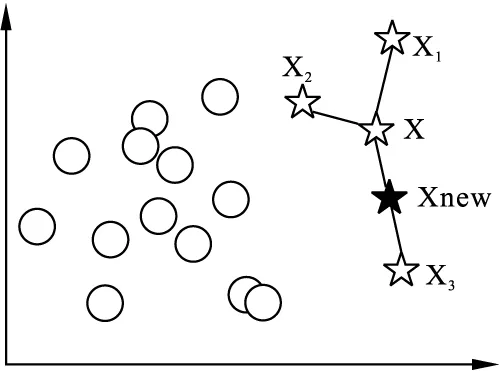
图1 SMOTE采样示意图
本研究中SMOTE采样通过使用Python(version=3.7)的imblearn(version=0.0)库中的SMOTE类实现,参数K_neighbors=5。
3.核方法
(1)核方法
核方法是一类把低维空间的线性不可分问题转化为高维空间的线性可分问题的方法[16-17]。给定有监督机器学习问题(x1,y1),(x2,y2),…,(xi,yi)∈X×Y,其中输入空间X⊆RN,输出空间Y⊆RN(回归问题)或Y={-1,+1}(二分类问题)。可以通过一个非线性映射:
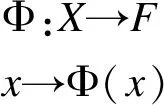
把低维度输入数据映射到一个新的高维特征空间F={Φ(x)|x∈X},其中F⊆RN。然后利用新的高维线性可分数据表示原来的低维线性不可分问题[18]。
(Φ(x1),y1),(Φ(x2),y2),…,(Φ(xi),yi)∈F×Y
(2)核函数
若∀x,z∈X,函数K(x,z)=<Φ(x),Φ(z)>,则称K为核函数,即核函数输入两个向量,它返回的值跟两个向量分别作映射然后点积的结果相同。
核方法的采用使支持向量机(support vector machine,SVM)由线性推广到非线性,其核心在于利用核函数可以快捷地得到该数据集的相关核矩阵,后者用于替代模型分类决策函数中的内积运算。
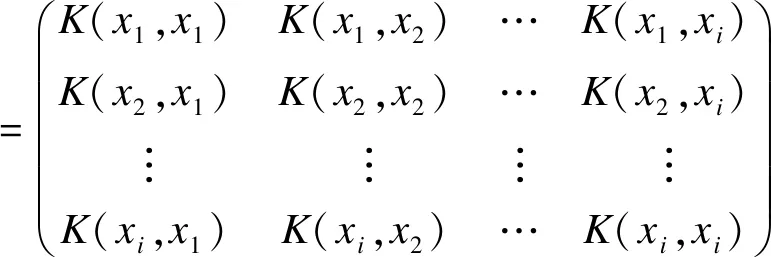
常用核函数如表2所示。

表2 常用核函数
4.多视图多核学习
多核学习[19]是在模型构建时通过组合多个核函数进行映射的一种方法,用以实现更好的泛化性,弥补基于单核学习方法的不足。由于多核学习中的内核自然对应于不同视图,因此多核学习被广泛应用于处理多视角数据[20]。
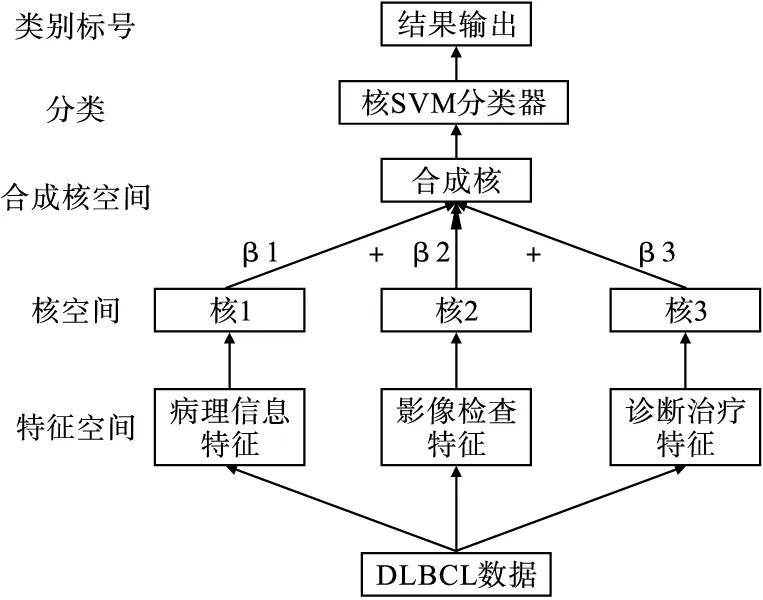
图2 多核学习模型的构成示意图
研究分别使用Python(version=3.7)MLKpy库中(version=0.6)的Multiview_generator类与EasyMKL类实现核映射与多核学习。其中,核总数为3,基础核经超参数搜索确定均为RBF(σ=1,0.1,0.01),多核学习分类器选择SVM(C=10)。
5.评价指标
本研究使用10折交叉验证的方法来评价模型的性能,分别采用准确率(accuracy)、ROC曲线下区域面积(AUC)、灵敏度(sensitivity)以及精度(precision)四个二分类指标。其中每个分类器的结果可以分为真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)四类,由此可得以下的指标计算公式:
除了统一评价标准外,在实验评价的所有模型中的超参数均经过循环网格搜索为最佳参数。
结 果
为验证本文中的采样效果,该模型分别使用SMOTE平衡采样数据与原始数据训练后的10折交叉验证结果均值如表3所示。
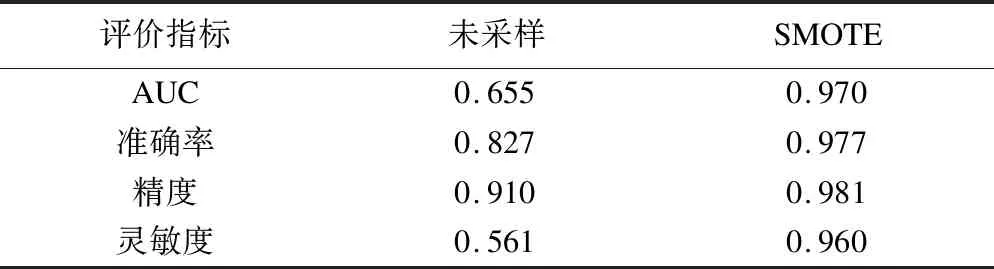
表3 采样前后模型性能比较
从表3可以看出,通过重采样,模型的各个性能指标均有提升,其中灵敏度与AUC分别提升了39.9%与31.5%。正是由于原始数据中多数类样本远多于少数类样本,少数类样本信息量较少,使得模型在训练过程中会在很大程度上偏向于多数类的样本进行分类以获得更高的准确率,故模型对于少数类样本的敏感性不足,导致灵敏度低。通过SMOTE重采样均衡训练数据后,模型对于少数类样本的分类性能得到了很大增强,提升了灵敏度从而提升了AUC。
目标模型与常见的机器学习算法模型的10折交叉验证结果均值如表4所示。
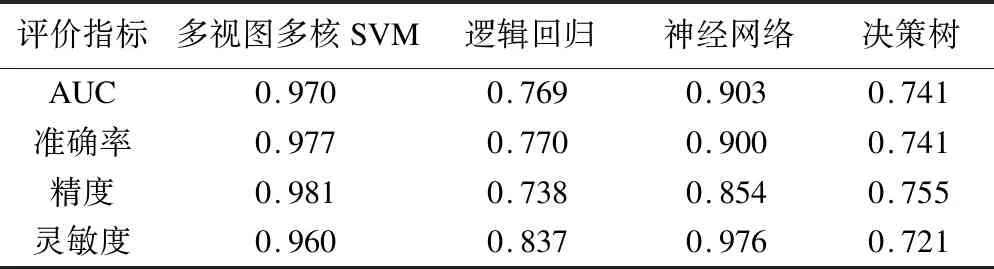
表4 各模型性能指标对比
由表4可知,除目标模型的灵敏度略低于神经网络,其余AUC、准确率、精度等指标均为最优。不难看出逻辑回归为常用的线性分类器,在非线性问题上的表现不佳,而其他三种模型均可处理非线性问题。
为了验证多视图多核学习的效果,分别使用多核SVM与单核SVM的模型对数据集串联变量进行学习,其十折交叉验证结果如表5所示。
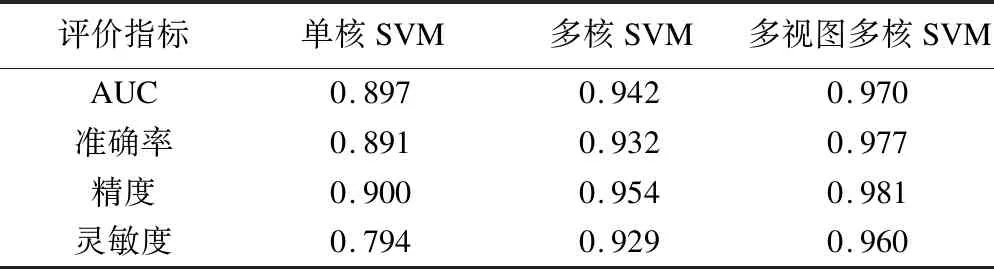
表5 多视图多核学习效果
综合表5二分类评价指标来看,多视图多核SVM的表现均为最优。通过AUC比较,多核SVM比单核SVM提升了4.5%,多视图多核SVM比多核SVM提升了3.2%。
讨 论
神经网络与决策树都是通过增加中间层的方法实现线性到非线性的转换,但由于决策树过拟合与鲁棒性不强问题,单棵决策树在实际应用往往不如人意。核支持向量机不仅巧妙运用核方法进行非线性转换,而且计算复杂度也小于多层的神经网络(如深度学习与集成的决策树等),是处理小型数据集非线性问题的良好选择。现有的模态特征融合方法中,一类方法是独立地从每种模态中提取特征,然后简单地将它们连接到一个长向量中,即对各个模态的特征进行串联,缺点是把所有模态特征信息赋予同等权重,没有考虑从不同模态提取出的特征的不同特性[21-22]。另一类方法是既可以利用在单个模态中训练的分类结果,也可以利用特殊的组合规则得到的总和特征。其中多视图多核学习针对不同的特征类型,采用不同的核函数建立核矩阵以表现局部特性,并将多个核矩阵进行评估与融合以体现全局性,最后对融合的核矩阵进行分类。多核学习通过提高核函数的搜索空间容量,实现不同核矩阵的组合,可以实现比单核学习更良好的泛化性,而由于不同的特征集对应不同的特征空间,若单纯串联各个不同特征集会减少模型在数据中学习到的信息量,使得模型最终的性能降低。因此,采用多视图多核学习可以合理且充分利用不同的特征集,以达到更好地进行数据挖掘的效果。
在当前大数据时代,数据都有不同的来源或者是从不同的视角获得,医疗数据同样如此,如何充分利用以及挖掘出数据中尽可能多的有效信息是卫生医疗统计行业的重要工作。多视角学习是一种新的机器学习方法,其既利用数据中联系,又关注数据间差别的思想,近年来受到了越来越多学者的关注和研究,其有效性也在众多的实践中得到了证明[23-24]。如Wang等对心率衰竭死亡率的预测AUC达到89.64%[5],唐楠等在医学文献蛋白质关系提取的实验AUC达到87.83%[25]。在卫生医疗领域,数据挖掘工作格外重要,不仅可以通过数据统计描述的方法,了解医疗工作的整体趋势,还可以通过机器学习等方法对临床数据进行数据分析、结果预测等,将得到的分析结果反馈给临床医疗工作者作为重要参考。
多视角学习一般遵循两个原则[26],即一致性与互补性。一致性原则是指同一对象不同视角的特征是存在内在联系的,旨在最大化多个视角间的一致性,即利用同一对象不同视角间的一致性和错误率获得更好泛化能力的模型。互补性是指不同视角数据间的差异性使得每个视角都包含对象某一方面独特的信息,通过利用此类相互补充的信息,全面而准确地描述数据,产生更好的算法新能[27]。本研究主要使用了多视图多核学习的建模方法。首先对肿瘤医院患者的病理信息、影像检查、诊疗记录三个不同来源的数据进行收集与多视图处理,同时针对患者类别不平衡的问题进行了重采样后,再使用多视图多核SVM模型对患者的预后(复发难治型与可治疗型)进行分类学习。结果显示了多视图多核学习在临床数据分析与数据挖掘中的作用,对比单核、多核与其他经典模型,本文基于肿瘤患者不同来源数据的多视图多核学习有明显优势,AUC与准确率分别达到97.0%与97.7%。从患者病理信息、影像资料、诊疗记录三个不同且互补的数据层面,分别通过核方法把三个特征集映射到三个相应的特征空间中,实现非线性转换的同时体现了不同视角之间的差异性,之后又利用三个核特征空间的非线性组合得到合成核,体现了不同视角间的互补性与一致性,最终在合成核空间中进行分类,达到了预期的效果。
本研究的不足在于影像资料来源的特征尚不够全面,仅使用了患者DLBCL的PET-CT中肿瘤形状特征,目前尚未对PET-CT的高阶特征[28]进行提取。故在今后的研究中,本研究团队重点会在PET-CT影像资料的收集整理与特征提取以及相关的多视图机器学习方法。
