基于SPEI和信息扩散加权一阶局域法的旱涝特征分析
2022-09-08段春青陈晓楠许新勇靳燕国
段春青,陈晓楠,许新勇,靳燕国
(1.北京市水务局 政务服务中心,北京 100071;2.中国南水北调集团中线有限公司,北京 100038;3.华北水利水电大学 水利学院,河南 郑州 450045)
旱涝是全球最常见的经济损失最严重的自然灾害。据统计,每年旱涝灾害导致的经济损失占全球各类自然灾害造成损失的43%[1-2]。我国旱涝频繁发生,且范围广、持续时间长,给生产、生活特别是农业生产造成巨大损失。
旱涝灾害的时空演化特征分析是当前灾害学领域研究热点,国内外学者已取得较丰富的成果,并建立了一些科学实用的旱涝程度的量化评估指标,目前常见的有降水距平指标[3]、降水温度均一化指标[4]、帕尔默干旱指数(palmer drought severity index,PDSI)[5]、标准化降雨指数(standard precipitation index,SPI)[6]、标准化降水蒸散指数(standard precipitation evapotranspiration index,SPEI)[7-8]等。
SPEI是Vicente-Serrano等于2010年提出的。该指数在SPI的基础上,结合了SPI和PDSI的优点,加入潜在蒸散因素,具备计算简单和多时间尺度的特点。SPEI一般只需月平均气温和降水资料即可计算区域蒸散量和水分盈亏量,并以标准化指数呈现,可用于不同时间、不同区域的旱涝变化特征比较。近些年,我国学者基于SPEI指数进行了大量的旱涝评价和规律分析,取得了丰硕成果,同时验证了该指数在国内具有很好的适用性[9-11]。
在旱涝时空分布特征和演变规律研究中,常见的分析方法有Mann-Kendall(M-K)趋势检验[12]、滑动平均模型[13]、logistic函数[14]、多项式回归[15]等。这些方法一般需要较多的样本数据作为支撑,而实际应用中所获得的数据不多,一般只有几十年资料,如何在较少样本条件下得到较好的非线性回归结果是重点研究问题之一。信息扩散技术是近些年兴起的针对不完备样本的一种有效处理手段,是利用适当的扩散函数实现对小样本数据的集值化模糊数学方法,通过把单值样本点扩散到各个控制点上来获取更多的信息[16-17]。此外,随着混沌理论及相关时间序列分析技术的不断发展,许多研究表明水文、气象等系统具有一定的混沌特征,通过对时间序列重构相空间,可挖掘其中丰富的动力学信息[18-19]。传统的各种混沌时间序列预测方法需基于大量数据,对于样本数据量较少情况,鉴于信息扩散技术处理小样本数据的优势,可考虑在回归中采用信息扩散技术进行数据处理,建立新的基于信息扩散近似推理的混沌时间序列分析法。
1 研究方法
1.1 信息扩散技术
1.1.1 信息扩散频率分布
信息扩散频率是在小样本条件下,通过构建离散论域的控制点,利用信息扩散函数将样本点携带的信息分配到控制点上,得到模糊集合,在此基础上分析频率的分布,主要步骤如下[17]。
(1)设样本序列为X=(x1,x2,…,xl),l为样本数量。根据样本序列中的最大值和最小值,构建离散论域U={u1,u2…,uc},c为论域U的离散点数量,对每个样本点xi通过下面的信息扩散函数,将其信息分配到论域中的每个控制点上:

h为信息扩散系数,可根据样本长度l和样本中的a、b来计算。
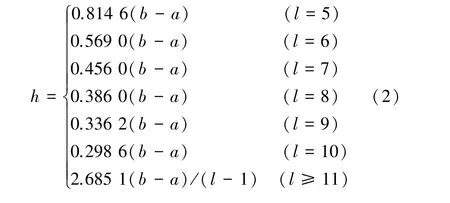
式中:a、b分别为样本中的最小值、最大值。
(2)对样本点xi的信息分配结果进行归一化处理:

(3)针对控制点uj,根据所有样本点在其上的信息分配,计算分配的信息总量:

(4)计算每个控制点的频率值:

(5)计算各控制点的超越频率值:
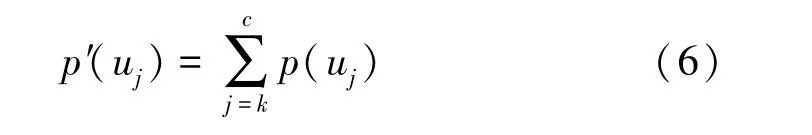
通过计算两个控制点的超越频率的差,即可计算出控制点区间内的频率分布。
1.1.2 信息扩散回归分析
信息扩散回归分析通过信息扩散技术建立变量间的模糊关系,能较好地直观反映出函数的变化趋势,得到光滑的函数曲线,主要步骤如下[18]。
(1)设自变量和因变量组成的样本序列为[(x1,y1),(x2,y2),…,(xl,yl)],分别根据输入和对应输出样本的数据分布情况,确定输入、输出的离散论域U={u1,u2,…,us},V={v1,v2,…,vr},并通过信息扩散将样本(xi,yi)转换为模糊集合:

式中:hx、hy分别为输入样本和输出样本的信息扩散系数,根据式(2)来计算。
(2)对每组样本(xi,yi)得到的模糊集Ai和Bi建立模糊关系Ri:

(3)对给定的输入数据x0,通过信息扩散回归模型估算输出数据y0。首先,将输入数据进行集值化处理:

式中:d=|u1-u2|。
然后,根据得到的模糊集和模糊关系进行模糊推理计算:
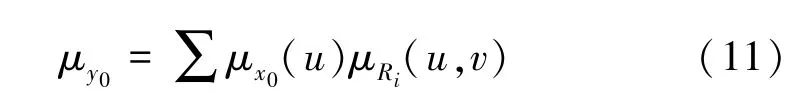
假设v′满足
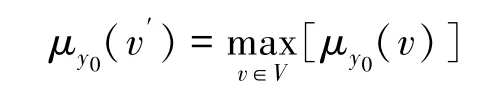
则v′是由第i组样本(xi,yi)推算得出y0的一个估计值,记 作y^i,并将其对应的隶属度看作估计值的权重wi。
(4)按照上述步骤,分别利用每组样本进行计算,将得到l个y0的估计值和相应的权重,加权平均得到最终的估计值:
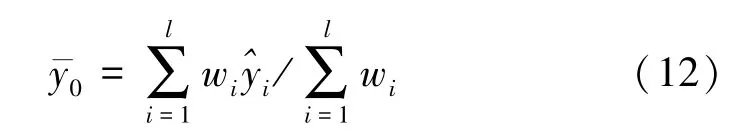
1.2 信息扩散混沌时间序列分析
混沌是确定性系统中出现貌似随机的现象,在自然界中普遍存在。混沌特性是对初始值的敏感性,虽长期不可预测,但短期预测可行。目前,混沌时间序列的分析已经广泛应用于各个领域中,主要预测方法有全域法、局域法、加权零阶局域法、加权一阶局域法等。其中,加权一阶局域法最为常见,在对时间序列数据重构相空间后,采用线性局部拟合相空间中的样本,一般需要较多的数据。当时间序列样本较少时,重构相空间后高维向量样本更少,可考虑采用擅长小样本处理的信息扩散回归技术进行处理,建立信息扩散加权一阶局域法,主要步骤如下[19]。
(1)设时间序列(xn|n=1,2,…,N),对其进行快速傅里叶变换,计算平均轨道周期P。
(2)采用C-C方法[21]计算时间序列嵌入维数m和时间延迟τ,重构相空间得到高维样本序列Yi=(xi,xi+τ,…,xi+(m-1)τ)(i=1,2,…,M,其中M=N-(m-1))。
(3)按照限制短暂分离的原则,要求|i-j|>P。对每个点Yi寻找最邻近点Yj,设最邻近的“点对”初始距离为di(0)。
(4)对相空间中的每个最邻近的“点对”,进行k步演进后,两者之间的距离为di(k)。
(5)对于每个k,计算所有的ln[di(k)]的平均值y(k),由下式计算:

式中:y(k)为计算得到的序列;g为非0的di(k)的数量;T为采样周期,本文取T=1;K为实际中最多演进的步长。
(6)对序列y(k)进行一元线性回归,直线的斜率即为最大李雅普诺夫(Lyapunov)指数λ1。当λ1>0时,认为系统具有混沌特征,λ1越大混沌特征越明显。若时间序列具有混沌特性,采用信息扩散加权一阶局域法进行预测。
(7)寻找邻近点。计算YM的q个最邻近点Yk(k=a1,a2,…,aq)。设Yk到YM的距离为di(i=1,2,…,q),dm是di中的最小值。定义Yk的权重Wk为:

(8)信息扩散加权预测。利用信息扩散回归法根据YM中分量xN估算xN+1,计算过程中将式(14)得到的权重Wk与式(12)权重相乘,并进行归一化处理后作为最终信息扩散回归中权重系数,推算xN+1的估计值。
1.3 标准化降水蒸散指数
根据区域的降水和气温数据量化计算标准化降水蒸散指数(SPEI),计算主要步骤如下[2]。
(1)根据气温数据及研究区位置,应用Thornthwaite法计算月潜在腾发量ETi:

其中:
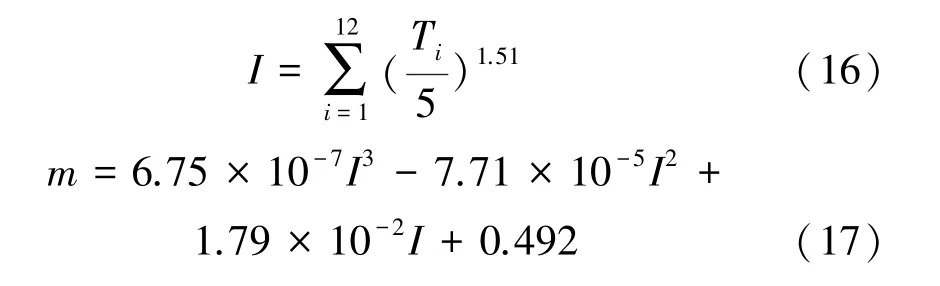
式中:ETi为月潜在腾发量;Ti为月平均气温;K为由区域纬度得出的平均昼长修正系数;I为年热量指数;m为指数,由I计算得出。
(2)根据降水和计算的潜在腾发量分析水分盈亏量:

式中,Di为月水分盈亏量,正值意味着水分盈余,负值则表示水分亏缺,0代表水分恰好平衡;Pi为月降水量。
(3)基于log-logistic概率分布计算SPEI:

式中:Γ()为Gamma函数;N为序列数;s=0,1,2。
设P=1-F(x),当P≤0.5时:

当P>0.5时:

其中,c0=2.5155,c1=0.8029,c2=0.0103;d1=1.4328,d2=0.1893,d3=0.0013。
SPEI的旱涝分级标准为:特旱(-∞,-2],重旱(-2,-1.5],中旱(-1.5,-1],轻旱(-1,-0.5],正常(-0.5,0.5],轻涝(0.5,1],中涝(1,1.5],重涝(1.5,2],特涝(2,∞]。
1.4 信息扩散和混沌理论的旱涝分析
根据研究区域月尺度下的月均降水量和月均气温历史数据,利用SPEI指数计算得出月旱涝程度;利用旱涝时间序列数据,基于信息扩散频率分布模型,得出不同旱涝程度分布规律;对旱涝时间序列进行信息扩散回归分析,得出旱涝变化趋势曲线,研究其随时间交替演变的特征;应用信息扩散加权一阶局域法预测旱涝变化趋势,验证模型的有效性。
2 应用实例
以陕西省西安市为典型研究区,分析旱涝演变规律。西安市是陕西省的政治、经济、文化中心,地处渭河流域中部,位于北纬33°39′—34°44′、东经107°40′—109°49′。西安四季分明,属于温带半干旱、半湿润大陆性季风气候区,多年年均降水量约740 mm,年内分布不均,年际变化大;多年平均气温约13℃;主要农作物为冬小麦、夏玉米等。本研究选择9月份为计算分析时段,该时段为玉米的成熟期,旱涝影响较大。研究区1951—2015年的月均降水量和月均气温数据通过中国气象数据网获得。
2.1 旱涝等级频率分布分析
根据SPEI指数计算西安市1951—2015年每年9月份的旱涝程度序列见图1。
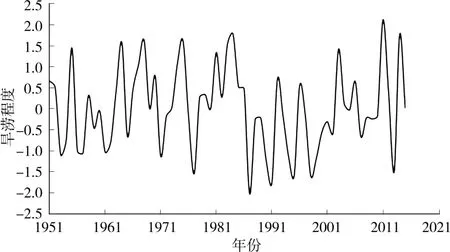
图1 SPEI旱涝程度序列
以图1中SPEI旱涝程度序列为基础,利用信息扩散技术分析不同等级频率分布。本文针对样本数据的实际分布,选取离散论域控制点101个,控制点旱涝程度最小值u1=-2.026、最大值u101=2.122,控制点等距离0.04148;其范围包含全部样本点。计算得出每个控制点上的超越频率,并根据SPEI等级的划分标准计算出不同旱涝等级分布频率(见图2)。

图2 旱涝等级分布频率
西安市9月份旱涝程度分布规律为:正常情况的频率最大,为39.6%;特旱和特涝的频率相对最小,分别为0.9%和1.0%;轻旱至轻涝的频率达到63.0%;中旱及以上程度的干旱频率为19.5%;中涝及以上程度的渍涝频率为17.5%。
与传统频率计算方法进行对比。利用传统频率计算方法计算得出不同旱涝等级分布频率为:特旱1.5%、重旱6.2%、中旱13.8%、轻旱9.2%、正常40.0%、轻涝10.8%、中涝7.7%、重涝9.2%、特涝1.5%。信息扩散计算结果与传统方法整体上相差不大。但是,假设增加1个旱涝程度为-2(特旱等级)的年份,数据样本增加66组,则用传统方法计算得出特旱等级的频率为3.0%,相比原65组样本计算结果增大了1倍。而利用信息扩散方法计算结果为1.7%,是因为样本数量较少,当发生个别变化时,传统方法计算结果很不稳定,但信息扩散技术可充分利用每个样本位置信息,得出较稳定的结果,体现出小样本条件下信息扩散技术分析频率的优越性。
2.2 旱涝演化趋势分析
利用信息扩散回归分析方法对旱涝程度数据进行处理。将年份序号作为自变量,相应的计算时段旱涝程度作为因变量,进行关系拟合。在计算中,两个变量所在论域的控制点个数均选取101个,且等间隔分布,最大控制点和最小控制点均分别选取样本的最大值、最小值外延0.001。信息扩散近似推理完成拟合后,处理前后对比情况如图3所示。图3中原旱涝程度序列呈现锯齿状,逐年变化波动大,不易直接看出演变规律。经过信息处理后得到光滑曲线,能够较为清晰地反映出演变的趋势和波动起伏的特征。

图3 信息扩散旱涝趋势
由图3可以看出,旱涝呈现交替变化规律:1951—1962年呈偏旱趋势,1963—1986年呈现偏涝趋势,1987—2002年又呈现偏旱趋势,2003年后再次呈现偏涝趋势。1951—2015年的整体趋势线基本处于水平状态,旱涝围绕正常状态上下波动,趋势线未有明显的上升或下降趋势。
2.3 旱涝趋势信息扩散混沌预测
利用上述信息扩散回归得到的旱涝程度趋势序列数据,计算时间序列的Lyapunov指数最大值为0.1492、大于0,表明序列具有一定的混沌特性。利用本文提出的信息扩散加权一阶局域法对旱涝趋势进行预测分析,结果如图4所示。

图4 旱涝趋势混沌预测
以1951—1984年实际趋势数据为基础预测1985年旱涝程度,之后再以1951—1985年实际趋势数据为基础预测1986年旱涝程度,以此递推。对比1985—2015年实际趋势数据和逐年预测的情况,可以看到利用信息扩散混沌预测的结果与实际的旱涝变化过程吻合较好,预测曲线与实训曲线比较接近,曲线转折点也较好地吻合,表明利用信息扩散混沌分析方法对旱涝的趋势预测可获得较好效果,在实际防灾、减灾中能提供一定的参考。
利用信息扩散一阶加权法预测平均误差为0.0863,而传统线性回归一阶加权局域法预测平均误差为0.1063,改进后的方法预测的精度更高。
3 结论
根据西安市历年9月份的气象资料,采用SPEI指数对旱涝程度进行量化计算。在此基础上,利用小样本数据分析的信息扩散技术对旱涝等级的分布频率进行计算,得出不同旱涝等级对应的发生频率。利用信息扩散回归方法对旱涝程度序列进行拟合,得到光滑的趋势曲线,较清晰地反映出旱涝交替变化规律及整体变化趋势。结合信息扩散和传统局域混沌时间序列分析方法,建立了信息扩散加权一阶局域法预测新模型,利用信息扩散近似推理实现相空间里的高维向量拟合,并对旱涝趋势进行预测,取得了较好的效果。研究表明,借助SPEI指数对旱涝量化评估,以及信息扩散技术和混沌分析技术能够较好地实现区域旱涝演变规律的分析,为当地防涝抗旱提供技术支撑。
