融合多特征和由粗到精排序模型的短文本实体消歧方法
2022-09-05王荣坤宾晟孙更新
王荣坤宾 晟孙更新
(青岛大学计算机科学技术学院,青岛 266071)
随着知识图谱和自然语言处理技术的快速发展,以知识图谱作为知识库的中文问答系统越来越多[1]。实体消歧是中文知识图谱问答系统(Chinese Knowledge Based Question Answering,CKBQA)中的关键技术,目的是构建问句中实体指称的候选实体集合,并将实体指称链接到正确的实体上[2-4]。现有的实体消歧方法主要有三类:基于分类的方法、基于图的方法和基于深度学习的方法。基于分类的方法将实体消歧看作二分类问题,利用分类器对候选实体分类[5-6],然而在分类过程中可能有多个候选实体被标记为真,所以还需要其他的方法对标记为真的候选实体进行消歧。基于图的方法通过实体指称和候选实体构建图模型,使用实体流行度、上下文相似度等信息对图模型中边进行加权,推理目标实体[7-8],能够考虑候选实体之间的关系,但是对于上下文信息利用不足。目前研究最多的是基于深度学习的方法,通过引入双向LSTM 和注意力机制,充分利用实体指称的上下文信息,有效的度量实体指称和候选实体之间的语义匹配,提高实体消歧效果[9-10]。以上实体消歧研究聚焦于以维基百科、描述文档等作为信息来源的长文本语境,利用实体指称和候选实体丰富的上下文信息进行实体消歧,对于短文本实体消歧方法研究较少[11]。而在短文本实体消歧中,中文问句口语化和缩略词[12]容易导致生成候选实体集合无法召回目标实体的问题,并且实体信息来源只有问句和知识图谱,没有描述文档辅助消歧,造成上下文信息缺乏的问题。为此,在生成候选实体集合阶段,通过N-Gram 分词模型对实体分词,构建分词索引;在实体消歧阶段,引入实体在知识图谱中的关系、相邻实体和实体重要性作为实体上下文信息,结合问句中的信息进行特征拟合并通过由粗到精的排序模型预测目标实体,提高实体消歧准确率。
1 融合多特征和由粗到精排序的实体消歧模型
融合多特征和由粗到精排序的实体消歧模型如图1所示,主要包含生成候选实体集合模块和实体消歧模块。以问句中识别出的实体指称作为模型输入,通过生成候选实体集合模块构造实体指称的候选实体集合,然后计算每个候选实体的特征值,构造特征向量,利用粗排模型进行过滤,减少候选实体数量,并选取得分Top10的候选实体构建新的特征向量,最后通过精排模型排序,得分最高的候选实体为目标实体。
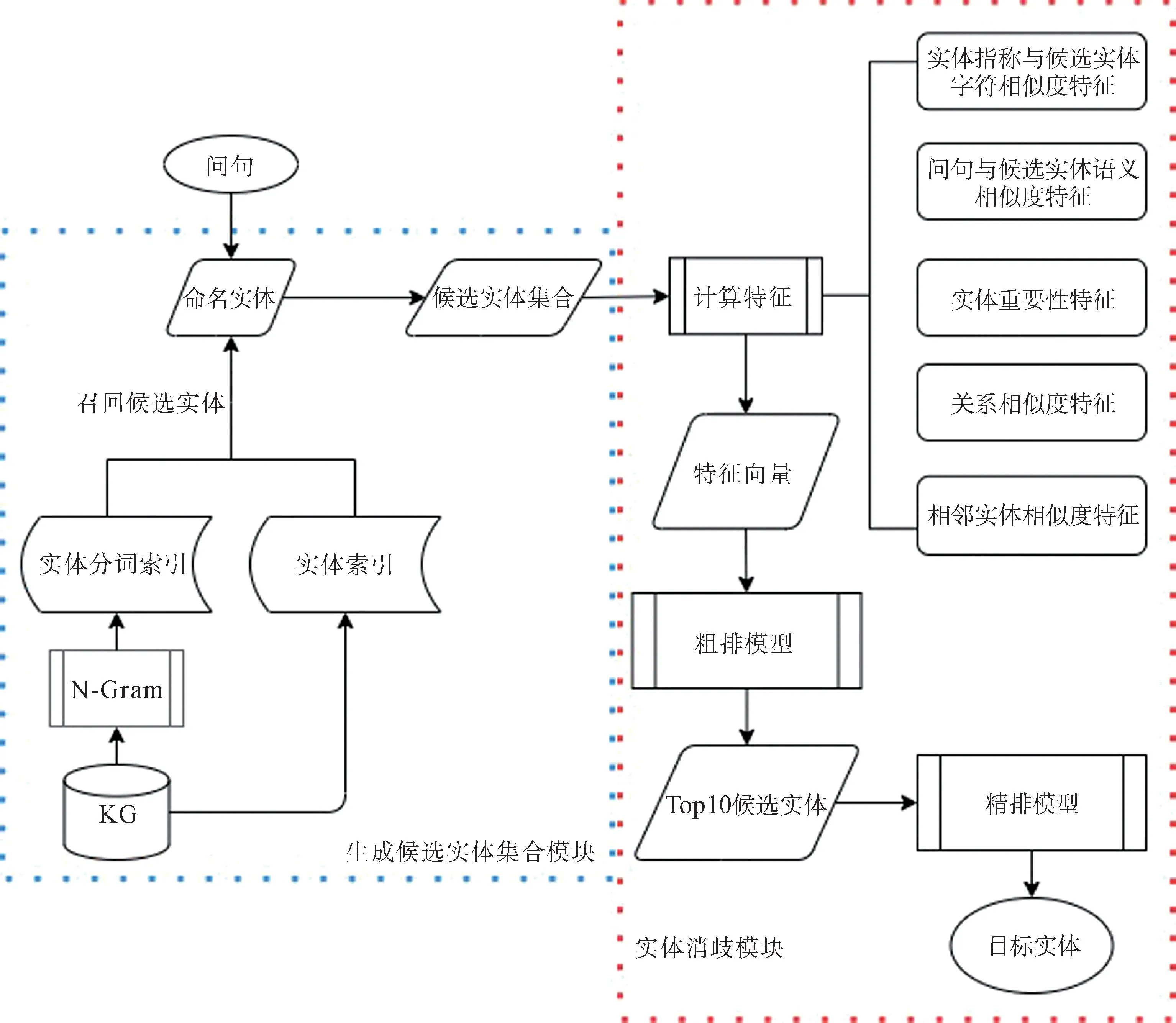
图1 实体消歧模型框架图
1.1 候选实体集合生成模块
给定一个问句和实体指称,候选实体集合生成模块根据实体指称到知识图谱中选取相似的实体作为候选实体。候选实体集合是实体消歧的基础,如果不包含目标实体,实体消歧部分就毫无意义。
(1)预处理。对知识图谱中的实体使用Bi-Gram 和Tri-Gram 分词的方法进行分词,针对每个分词和原词构建倒排索引。N-Gram 是一个基于概率的判别模型[13],N是指由N个单词组成的集合,本文使用的Bi-Gram 中N=2,Tri-Gram 中N=3。假设一个句子有m个字符,S=(w1,w2,…,w n),n≤m表示句子中的一个分词,Bi-Gram 中假设一个字出现的概率仅仅依赖它前面出现的字,Tri-Gram 假设一个字出现的概率依赖它前面的两个字。在Bi-Gram 和Tri-Gram 中S是词语的概率计算方法分别为
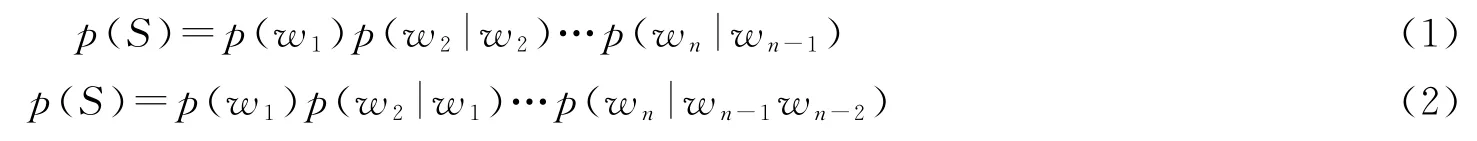
其中,w i表示第i个字符,i≤n,p(S)表示分词S是词语的概率,p(w n|w n-1)表示第n-1个字符是S组成的情况下,第n个字符也是S组成的概率。以“崂山风景区”为例,使用Bi-Gram 分词后的结果Y1={崂山,风景区},Y2={崂,山风景区},Y3={崂山风,景区}。其中,p(Y1)=p(崂山)p(风景区|崂山),p(Y2)=p(崂)p(山风景区|崂),p(Y3)=p(崂山风)p(景区|崂山风),三个概率中,“崂山”在语料库中比较常见,所以p(Y1)的概率比较大,“崂山风景区”会被分词为“崂山”和“风景区”。
(2)生成候选实体集合。对于每个实体指称,构造一个候选实体集合。候选实体集合的来源有两部分,一部分是使用实体指称到知识图谱实体的实体索引库中通过相似度进行召回;另一部分是使用实体指称到知识图谱实体的实体分词索引库中通过相似度进行召回,主要缓解问句中因为使用简称和缩略词导致无法召回目标实体的问题。
1.2 实体消歧模块
由于在CKBQA 中,信息来源有限,只能通过问句和知识图谱本身的信息进行实体消歧。而大部分短文本实体消歧方法对知识图谱本身信息利用不足,所以在实体指称与候选实体字符相似度特征、问句与候选实体语义相似度特征两个常用特征[14-16]的基础上,引入了关系相似度特征、相邻实体相似度特征、实体重要性特征,以充分利用候选实体在知识图谱中的信息。在最终的排序环节,通过粗排模型过滤无关候选实体,缩小候选实体集合数量,然后使用精排模型预测目标实体,提高实体消歧准确率。
(1)相似度计算模型。实体指称与候选实体的字符相似度特征计算使用编辑距离方法[17],问句与候选实体语义相似度、关系相似度和相邻实体相似度计算使用图2所示的语义相似度计算模型。
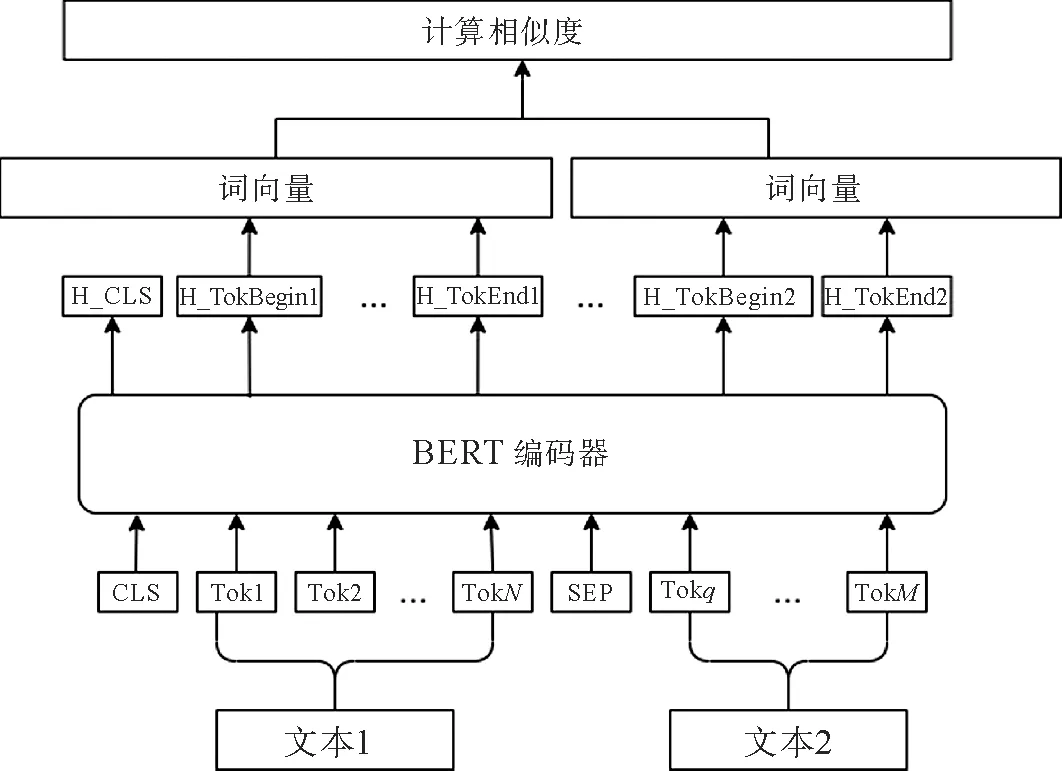
图2 语义相似度计算模型图
首先拼接文本1 和文本2,两个文本之间使用[SEP]标记分隔,拼接后的文本头部加入[CLS]标记,然后计算拼接文本中每个字符的词向量、段向量和位置向量。将这三个向量相加后输入BERT[18-19]预训练模型对文本编码,得到两个文本向量a和b,最后计算向量的相似度similarity(a,b)

(2)关系相似度特征。关系相似度特征指的是问句与候选实体关系的相似度,知识图谱KG=(H,R,E),其中H表示头实体的集合,R表示关系集合,E表示尾实体集合。候选实体集合C={c1,c2…,c m},c i∈(H∪E),c i的关系集合R e={r1,r2,…,r n},r j∈R,关系相似度计算公式为
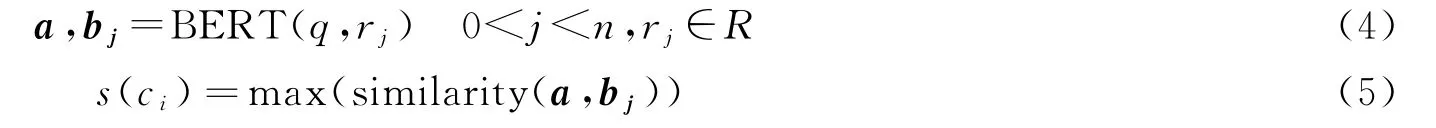
其中,a表示问句q经过BERT 模型编码后的向量,b j是关系r j编码后的向量,s(c i)表示问句q与候选实体c i关系的相似度特征,下面举例说明。
例如问句“《西厢记》又名什么?”,对应的候选实体集合中有“<西厢记_(元代王实甫著古典戏剧)>”、“<越剧西厢记>”、“<浅析西厢记>”等多个候选实体,其中“<西厢记_(元代王实甫著古典戏剧)>”存在“类型”和“别名”两个关系,分别计算问句作为文本1、“类型”作为文本2的相似度和问句作为文本1、“别名”作为文本2的相似度,选取最大的相似度作为问句与候选实体“<西厢记_(元代王实甫著古典戏剧)>”的关系相似度特征。存在“又名”或者“别名”这种关系的候选实体是目标实体的几率比不存在该关系的候选实体几率大,使用这个特征可以补充候选实体的信息,筛选掉候选实体集合中不存在目标关系的候选实体。
(3)相邻实体相似度特征。本特征指的是问句与候选实体一阶相邻实体的相似度,计算方法与关系相似度特征计算方法相同,计算问句与候选实体每个一阶相邻实体的相似度,选取最大相似度作为问句与候选实体的相邻实体相似度特征。例如问句“导演诺兰2017年的哪部作品出品了?”中实体指称“诺兰”对应的候选实体集合中存在“<诺兰·诺斯>”、“<诺兰>”等多个候选实体,候选实体“<诺兰>”存在三元组<诺兰,职业,导演>和<诺兰,类型,娱乐人物>,分别计算问句作为文本1、“<导演>”作为文本2的相似度和问句作为文本1、“<娱乐人物>”作为文本2的相似度,最大的相似度作为问句与候选实体“<诺兰>”的特征值。一阶相邻实体可以作为候选实体描述信息辅助实体消歧,问句中形容词“导演”与“<诺兰>”的相邻实体“<导演>”相似度较高,所以“<诺兰>”是目标实体的概率比不存在该相邻实体的候选实体高。
(4)实体重要性特征。候选实体的重要性特征能够表示候选实体在知识图谱中的重要程度,在开放领域知识问答中,重要性高的候选实体更容易成为目标实体。与常见的使用实体在图中入度、出度计算实体重要性的方法不同,本文的重要性计算方法使用的是PageRank[20]算法。在PageRank中,一个PageRank值很高的实体链接到另一个实体上,被链接的实体PageRank值也会相应的提高,而常规方法中实体的重要性只与相邻实体的数量有关,与相邻实体的重要性无关,因此PageRank计算的重要性特征更加符合真实情况

其中,PR(p j)表示实体p i的PageRank值,即实体的重要性,M p i是所有对p i实体有出链的实体集合,L(p j)是实体p j的出链数目,N是知识图谱中的实体总数,α一般取0.85。
(5)由粗到精排序模型。在生成候选实体集合阶段,为了保证目标实体在候选实体集合中,召回的候选实体数量比较多,直接对候选实体集合中的实体排序会导致排序结果比较差。因此,本文利用多排序模型,先将候选实体集合的特征向量通过LR 模型进行粗排,选取分数Top10的候选实体构造新的候选实体集合,并且将粗排打分作为新的特征加入特征向量。然后通过XGBOOST 模型精确排序,预测每个候选实体是目标实体的概率,得到最终的目标实体。
2 实验结果分析
2.1 实验数据
本文在公开数据集CCKS2019-CKBQA(https://www.biendata.xyz/competition/ccks_2019_6/data/)上测试。数据集包括2 298 条训练集,766条验证集和766条测试集以及一份北京大学构建的知识图谱PKUBASE。知识图谱中包括255 744个实体和66 499 738条关系。CCKS2019-CKBQA 的数据集是用来评测整个问答流程的,本文在数据集的基础上做了二次标注,仅用在实体消歧部分的实验。
2.2 实验设置
实验在Windows10环境下使用Py Charm 验证,计算词向量的Bert预训练模型使用的Pytorch版本的“Bert-Base-Chinese”模型,编码器有12层,词向量维度768维,最大句子长度设置为256。实验分为两部分,一部分为实体消歧实验,分别使用不同数量的特征和不同的排序模型进行对比实验,数据集内容是问句、问句中的实体指称和实体指称对应的目标实体。另一部分是N-Gram 分词方法对实体消歧模型的影响实验,采用相同的数据集,候选实体生成方法分别采用只使用相似度召回的方法和使用相似度召回加上N-Gram分词召回的方法。假设有n个实体指称E N={e1,e2,…,e n},实体指称的预测结果E p={e1,e2,…,e n},实体指称对应的目标实体为E t={e1,e2,…,e t},则实体消歧的准确率P、召回率R和F值分别为:P=实验使用的数据集中实体指称已被二次标注,所以|E p|=|E t|,P=R=F,将准确率P作为实验结果的主要评价指标。
2.3 实验结果
2.3.1 实体消歧模型实验 实体消歧实验选取了5个特征:问句与候选实体语义相似度特征(f0)、实体重要性特征(f1)、实体指称与候选实体字符相似度特征(f2)、关系相似度特征(f3)、相邻实体相似度特征(f4)。基于上述特征分别构建了不同数量特征的实体消歧模型,分别是使用f0和f1特征的模型1,使用f0、f1和f2特征的模型2,使用f0、f1、f2和f3特征的模型3,使用全部特征和单排序模型的模型4以及使用全部特征和多排序模型的模型5,模型6 是CCKS-CKBQA 评测比赛第一名(https://conference.bj.bcebos.com/ccks2019/eval/webpage/pdfs/eval_paper_6_1.pdf)实体消歧部分的准确率,模型7是其他多特征模型[14]的准确率。这7个模型实体消歧的准确率结果如图3所示。
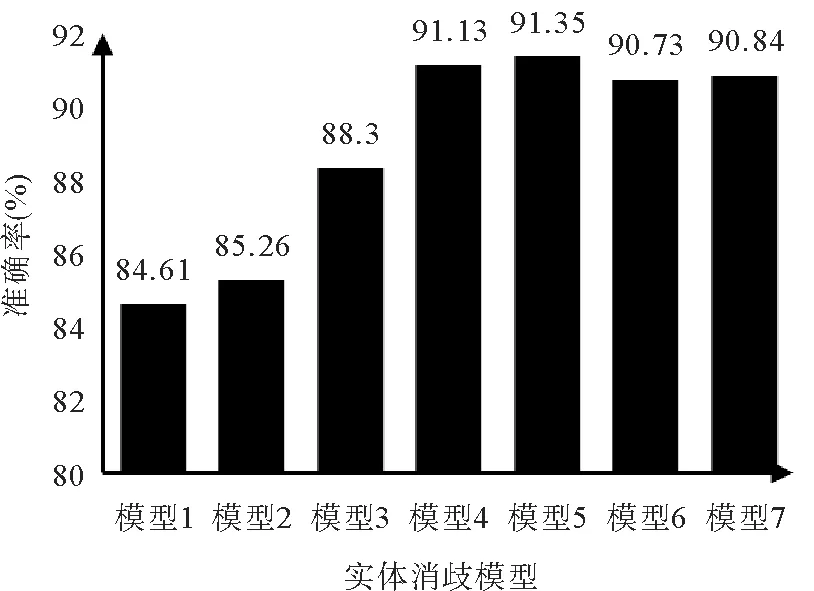
图3 实体消歧模型准确率对比图
随着使用特征的增多,实体消歧准确率会上升,模型4 相比模型6 提高了0.4%,比模型7 提高了0.29%,模型5比模型4提高了0.22%,比模型7提高了0.51%。模型5使用由粗到精多排序模型的方法,经过粗排模型减小了候选实体集合中候选实体的数量,所以实体消歧准确率高于未使用粗排的模型4。
图4展示了排序模型中不同特征的重要性,在精排模型预测分数最重要的三个特征中,f1和f4分别为第一名和第三名。实验结果表明,本文引入的特征在实体消歧过程中起到了重要作用。
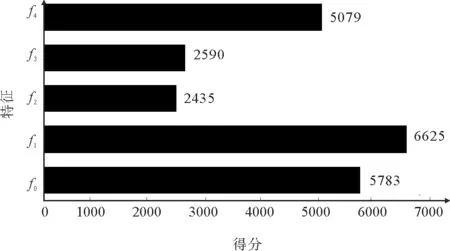
图4 特征重要性得分图
2.3.2 候选实体与实体消歧实验 表1展示了N-Gram 分词方法对实体消歧结果的影响(实体消歧模型使用模型5),使用N-Gram 分词召回方法后实体消歧的准确率提升了0.09%。分析实验发现,N-Gram 分词结果中只包含相邻的字组成的词,对于不相邻的字组成的词则不会分词,而中文缩略词多是原词中不相邻字组成的缩略词,导致对于缩略词的召回效果比预期效果较差。

表1 N-Gram 分词召回对实体消歧的影响
3 结论
本文通过N-Gram 分词召回和相似度召回相结合,引入候选实体在知识图谱中的关系、相邻实体和实体重要性信息,设计粗排和精排相结合的排序模型,得到融合多特征和由粗到精排序模型的实体消歧方法。在CCKS2019-CKBQA 的数据集上实验表明,本文方法对短文本问句实体消歧效果有明显提升,实体重要性信息和问句与候选实体的相邻实体信息在排序时起到了重要作用。经过实验分析,N-Gram 分词结果都是实体中相邻字组成的词,而中文问句中的缩略词还包含了大量不相邻字组成的词,导致N-Gram 分词召回的方法对实体消歧准确率提升不大。所以下一步需要优化分词模型,考虑不相邻字组成的缩略词,提高缩略词的召回率,减少缩略词对实体消歧的影响。
