雾天车辆目标检测域适应模型
2022-09-03董惠文
董惠文,田 莹
(辽宁科技大学 计算机与软件工程学院,辽宁 鞍山 114051)
常用的车辆目标检测数据集大多是在晴天清晰情况下拍摄,用此数据集训练出来的模型在晴天检测效果良好,但在雾霾天或者雨雪天准确率就会大幅下降。以往研究主要采用两种方式来解决:数据集去雾后检测和一体化的雾霾天目标检测模型。
数据集去雾后检测采用分步实验,先将数据集整体去雾,再将处理好的图像放入目标检测模型进行实验。去雾方法主要分为传统方法和深度学习方法。传统上的去雾模型是将图像退化后的大气散射模型进行恢复,例如,He等[1]提出的暗通道先验,还有颜色衰减先验[2]、色调差异先验[3]。传统方法主要缺点是:恢复的图像中由于手工的严格约束,造成不期望的雾伪影;或是目标场景与大气光类似,如雪地、白色的楼房等,结果较差。近几年深度学习去雾方法中,Li等[4]提出一种基于卷积神经网络的一体化去雾网络(All-in-one dehazing network,AOD-Net),可直接重建无雾图像,但图像往往较暗且不够清晰。Liu等[5]使用对抗性方法CycleGAN,输入不成对的有雾与无雾的图像,通过周期不变性以及对抗性学习增强去雾效果。这些深度学习的方法都是将有雾图片转换成无雾,还需要进行二次训练才能得出适合检测雾天车辆的模型。
一体化的雾霾天目标检测模型通过深度学习,在训练中学得雾霾中车辆的特征,直接用于目标检测。2018年,Chen等[6]提出将域适应算法与双阶段目标检测模型相结合,设计在图像上和实例上的域适应组件,将对抗性训练引入域适应,以减少域漂移导致的性能下降。汪昱东等[7]在Faster R-CNN中添加雾浓度判别模块以及注意力机制,结合扩充后的数据集完成对行人和车辆的检测。Sun等[8]在Faster R-CNN基础上提出一种基于无监督领域分类的多目标检测方法,首先在所有目标域中提取不同风格特征,再使用k均值(kmeans)算法进行无监督聚类,进一步训练出在所有天气情况下都可使用的目标检测模型。以上方法都是基于Faster R-CNN的双阶段目标检测模型进行改进。对于自动驾驶或其他交通检测模型来说,模型的运行速度也是需要考虑的因素。
双阶段目标检测模型速度较单阶段模型慢很多。在雾霾天气下检测车辆和在清晰天气下检测车辆效果不同,主要是由于两种不同的域之间存在着分布差异。因此,本文提出一种单阶段域自适应目标检测模型,在YOLO模型损失上添加联合最大平均差异(Joint maximum mean discrepancy,JMMD)[9]域间损失,称之为JMMD-YOLO模型,对齐跨域的多个域特征层的联合分布参数,并学习传输网络,使无雾到有雾的跨域检测效果得以提升。
1 JMMD-YOLO模型
1.1 联合最大平均差异
最大平均差异(Maximum mean discrepancy,MMD)[10]最开始用于衡量两个分布和之间的接近程度。如果两个分布是相同的,那么两个数据差值应该为零式中:是包含所有连续函数的集合,广义再生核希尔伯特空间中的函数类足以区分任意两个分布。数据集满足P分布,数据集满足Q分布。
在实际应用时,采用的是经验核均值嵌入之间的平方距离MMD,计算式
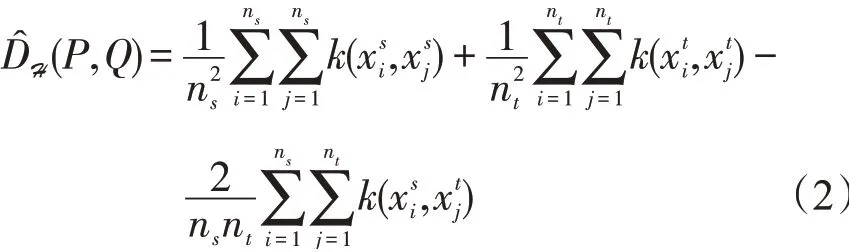
式中:ns是有标签的示例;nt是无标签的示例;k(x,x′)为核函数。
利用张量积特征空间与再生核希尔伯特空间结合[11],推广到多个变量的联合分布,得到
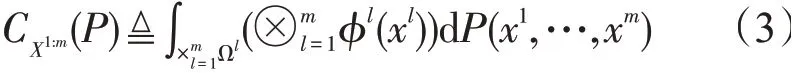
式中:P为联合分布,P中变量X`,…,Xm嵌入到m阶张量积特征空间中。
将式(2)与联合分布式(3)结合,产生的度量即是联合最大平均差异[9],计算式
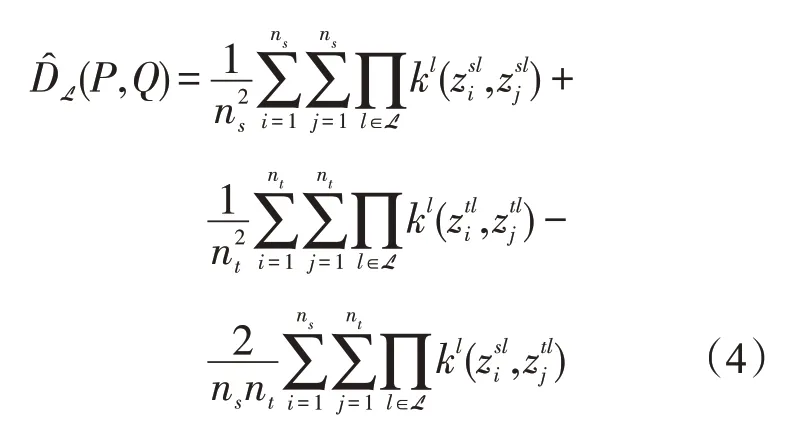
式中:P和Q分别为从源域Ds和Dt目标域中提取的标记点,深层网络分别从L中生成激活,如和
JMMD模块结构如图1所示。Block1为YOLO模型的特征提取层,Block2为后续的卷积层,中间部分为本文所用的JMMD模块。该模块zs1,…,zs|L|特征部分来自源域,zt1,…,zt|L|部分来自目标域,分别把对应层的特征映射到希尔伯特核空间,再进行内积计算,最后计算源域与目标域之间的JMMD。通过优化JMMD达到域自适应。
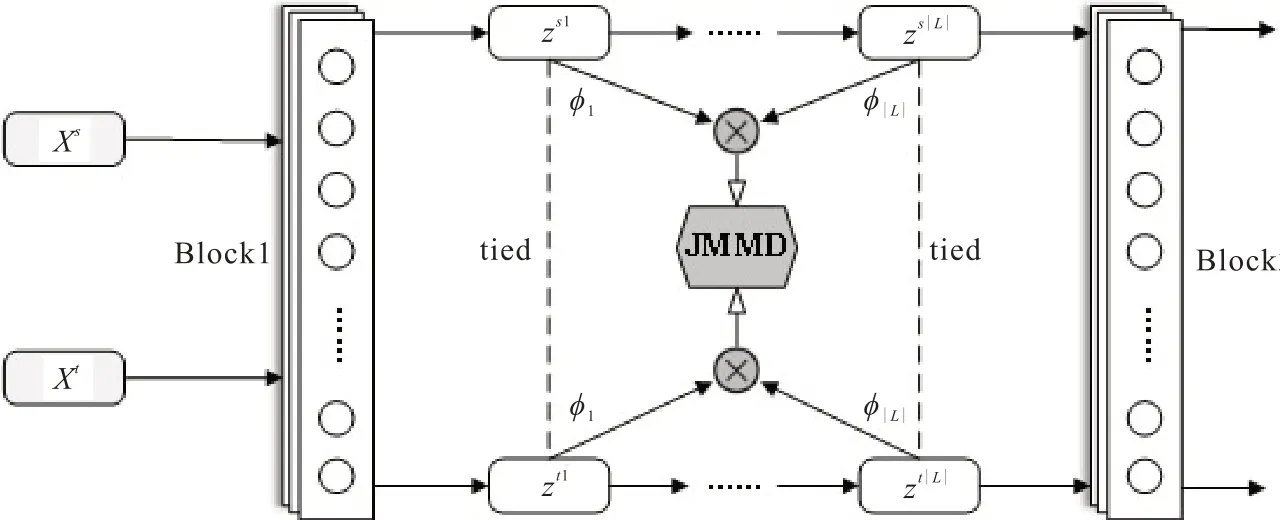
图1 JMMD模块示意图Fig.1 Schematic diagram of JMMD module
1.2 YOLO域自适应网络
YOLO模型[12]最先由Redmon等在2015年提出,将目标检测转成一个回归问题,在一次评估中完成边界框预测与类别预测,运算速度是当时其他实时检测器的两倍,但它的定位误差相对其他双阶段目标检测模型较高,无法从背景中预测假阳性。
2016年,YOLOv2[13]在YOLO的基础上增加多尺度训练方法,引入候选区域框(Anchor boxes),取消随机失活方法,在卷积层全部使用批标准化,增加了细粒度特征,使较小的物体检测准确度提升,召回率也明显提升。YOLOv3[14]在YOLOv2基础上,更新了Darknet-19的结构,变为53层,检测效果进一步提升。在多尺度检测方面,采用两次上采样,在原来的5个候选区域框的基础上提升到9个,使小物体检测效果进一步提升。近年来也有基于YOLO模型改进的YOLOv4以及YOLOv5模型,结合SPP(Spatial pyramid pooling)训练的YOLOv3也是工业界常用的版本。本文采用跨域后效果依旧稳定的YOLOv3-SPP模型进行改进。为使原始检测效果更佳,还使用了马赛克数据等增强方法。
YOLO域适应模型所采用的优化目标包括两大部分:一个是目标检测损失,另一个是域适应损失。目标检测损失又包括边界框置信度损失(Lconf)、类别损失(Lclass)以及坐标损失(LCIoU)。计算式
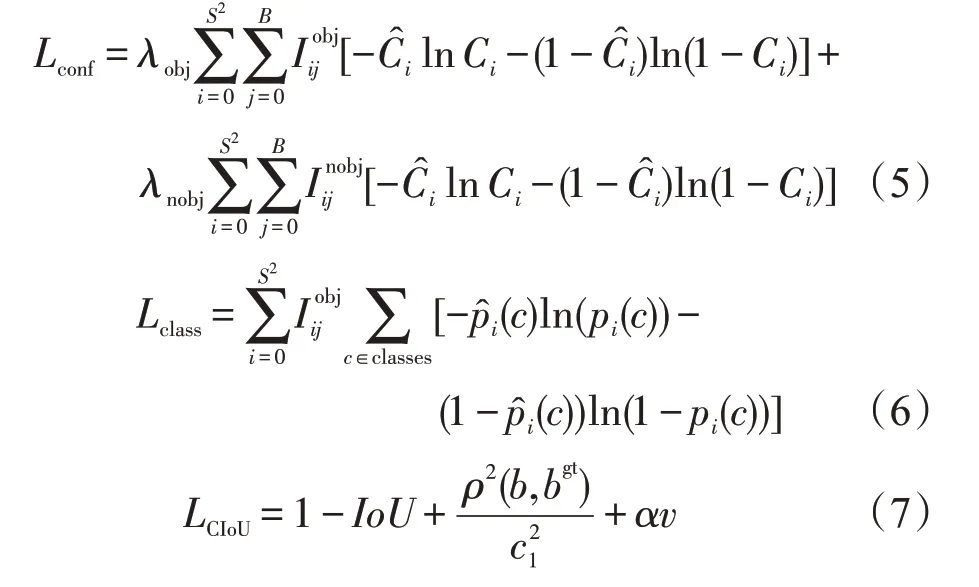
其中
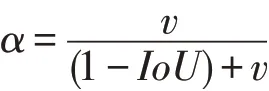
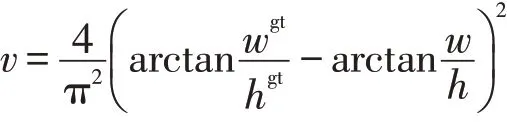
式中:S2为划分的网格数量;B为每个网格预测边界框数量;为判断第i个网格的第j个边界框是否有需要预测的目标;λobj和λnobj为网格有无目标的权重系数;Ci,C^i为预测目标和实际目标的置信度值;c为边界框预测的目标类别;pi(c)为第i个网格检测到目标时,其所属c的预测概率;p^i(c)为第i个网格检测到目标时,其所属c的实际概率;IoU为预测框与真实框之间交并比的差值;c1为预测框与真实框最小包围框的对角线长度;b为预测框中心点坐标;bgt为真实框中心点坐标;ρ(b,bgt)为计算两者间的欧式距离;α为平衡参数,不参与梯度计算;v为惩罚项,判断预测框的宽高是否接近于真实框的宽高;w和h为预测框的宽高;wgt和hgt为真实框的宽高。
将JMMD与YOLO损失函数结合即为本文的损失函数
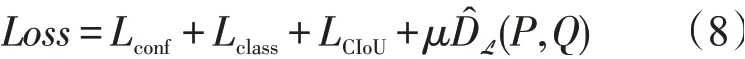
其中μ>0为平衡目标检测和域适应损失的参数,整体目标为最小化目标检测损失和JMMD联合调整。
1.3 模型整体结构
模型整体分为五个模块,分别是输入端、主干网络(Backbone)、颈部、检测头以及域适应模块。模型主要结构如图2所示。
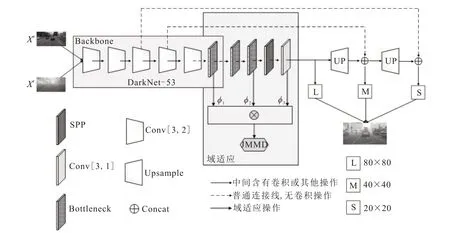
图2 JMMD-YOLO结构图Fig.2 Structure diagram of JMMD-YOLO
输入为源域Cityscape和目标域Foggy Cityscape,在经过马赛克数据增强以及随机图像翻转等数据增强方法后,处理成640×640大小输入到主干网络中。
主干网络采用DarkNet-53网络结构,由残差模块和卷积层堆叠构成,图中仅简要画出五个步长为2的卷积以及最后一层卷积。为得到更好的泛化效果,其中激活函数采用平滑的非单调函数Swish。
颈部为DarkNet-53和检测头之间的部分,使用特征金字塔网络(Feature pyramid networks,FPN),同时应用高层语义信息与低层位置信息,融合不同层特征,达到较好的预测效果。
检测头部分为三种尺寸,分别是80×80、40×40、20×20,在不同的感受野下检测对应尺度的目标。
域适应部分在三个特征层中分别获取源域和目标域的特征,求出JMMD,并加入总体损失进行计算。
2 仿真实验
2.1 配置及设置
服务器配置采用CentOs7,计算统一设备架构(Computer unified device architecture,CUDA)采用10.1.105版本,CUDA深度神经网络库(CUDA deep neural network library,cuDNN)采用7.65版本,深度学习框架采用PyTorch1.7.1。硬件使用两张NVIDIAGTX1080Ti显卡。
模型的图像增强采用的是马赛克数据增强、随机翻转、剪切、水平以及垂直平移。此种混合的图像增强可明显提升小目标的检测效果。代码采用Ultralytics的YOLOv3-SPP。实验中图像输入大小均为640×640,域适应实验中,每批次为两张源域和两张目标域图像。文中平衡目标检测和域适应损失参数μ选用0.01。
2.2 数据集
Cityscapes[15]数据集包括来自50个不同城市的街道场景,共有5 000张具有高质量像素级注释,2万张图像具有粗糙注释。其中公开带标签的高质量数据包括训练集2 975张,验证集500张。数据集场景较为复杂多变,专为城市环境中的自动驾驶设计,共有8个类别。本文仅比较轿车、自行车、摩托车、公共汽车、卡车以及火车这6个类别。
Foggy Cityscapes[16]数据集是在Cityscapes真实晴天图像的基础上合成的高质量雾天数据集,可用于目标检测与分割。根据衰减系数分为三种,分别是0.005、0.01、0.02的三个版本,分别对应600 m、300 m、150 m的能见度范围。
两个数据集的类别按照标签数目从多到少排列分别为:轿车、自行车、摩托车、公共汽车、卡车、火车。数据集示例如图3所示。

图3 Cityscapes和Foggy Cityscape数据集示例图Fig.3 Example graphs of Cityscapes and Foggy Cityscape datasets
将数据集无关类别删除后,域适应训练过程中源域选用带标注的Cityscapes数据集,目标域采用无标注的Foggy Cityscapes数据集,验证集采用Cityscapes的验证部分,测试集采用Foggy Cityscapes的验证集。
2.3 模型评估
评价指标采用平均精度mAP(mean average precision)、PR(Precision-Recall)曲线以及每秒传输帧数(Frames per second,FPS),计算式

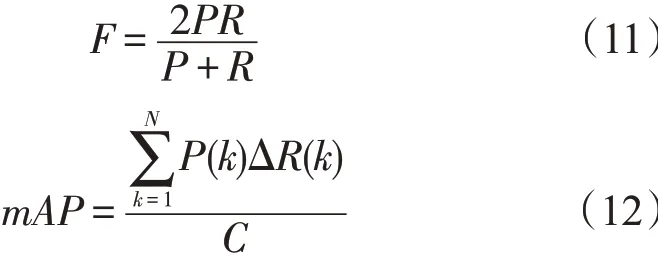
式中:TP为目标正确检测的数量;FP为目标未检测数量;FN为目标错误检测的数量;P为精确率;R为召回率(Recall);N为测试输入图片数;C为分类类别数;k为输入的第k张图片;ΔR(k)为召回率k-1到k时的变化情况。
各类的平均精度(AP)以及整体平均精度(mAP)阈值均采用0.5。
2.4 结果与讨论
为选用更适合的模型进行域适应,本节采用多种模型进行比较。选用YOLOv3-SPP以及YOLOv5的两种版本YOLOv5l、YOLOv5x进行对比,测试结果如表1所示。YOLOv3-SPP的检测效果与YOLOv5x接近,在速度上YOLOv3-SPP介于YOLOv5l与YOLOv5x之间。

表1 各模型在Cityscapes下测试效果Tab.1 Test results of each model under Cityscapes
表2为使用Cityscapes数据集进行训练后的模型在Foggy Cityscapes进行测试的结果,其中测试数据均采用150 m可见度下的雾霾图像,为跨域实验。在跨域后,所有模型的效果均大幅下降,说明雾霾对车辆检测效果影响较大。其中YOLOv3-SPP在跨域后实验效果最佳。

表2 各模型在150 m可见度下Foggy Cityscapes的测试效果Tab.2 Test results of each model at 150 m visibility under Foggy Cityscapes
显然,在同域下的实验效果佳并不能代表跨域后依旧有很好的适应性,在一个数据集中学习好的特征在跨域后由于域之间的差异并不能适应新的数据集。因此,采用跨域后效果最好的YOLOv3-SPP结合JMMD,进一步缩小两个数据集之间的域差异。
域适应测试结果详见表3。能见度列中的“混合”是使用Foggy Cityscape数据集中的3种能见度混合验证集进行测试,“无雾”是使用Cityscape验证集进行测试。在源域与目标域雾霾区别程度较大的情况下,JMMD-YOLO可有效提升车辆的检测效果。在标签数比较少的类别上提升效果更为突出,在150 m可见度范围下,公共汽车类别提升6.4%,卡车类别提升2.46%,火车类别提升2.29%,整体平均精度提升2.2%。在三种可见度混合的数据集中,火车类别提升5.4%。从速度上看,改进后的模型速度略有下降,但依旧能达到57.8帧/s,具有实时性。
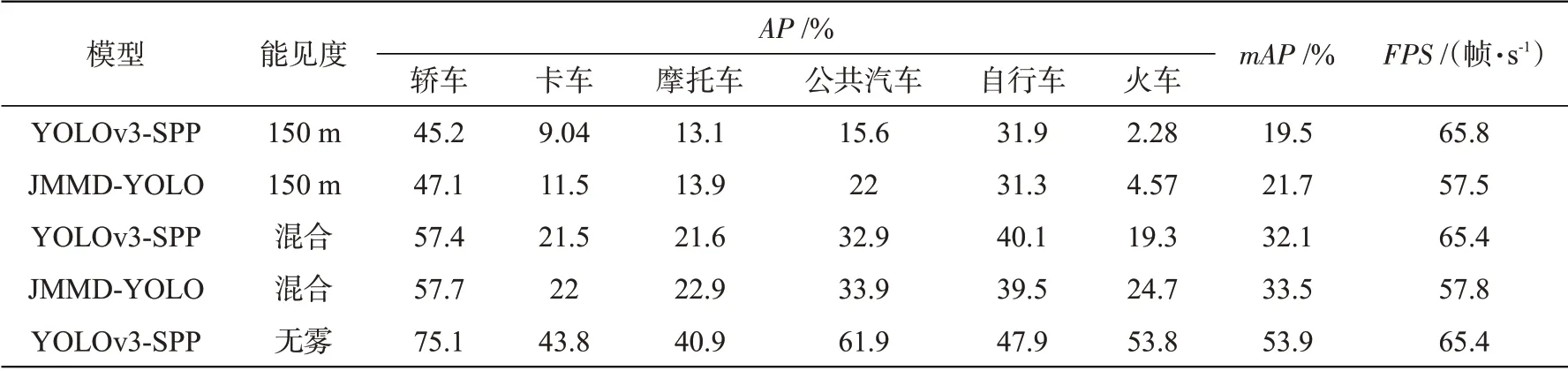
表3 域适应测试结果Tab.3 Test results of domain adaptation
实验结果证明,多个特定特征层的联合激活,可有效纠正跨域联合分布的偏移。同时,将JMMD嵌入到目标检测模型中,无需额外训练网络就可以达到域适应效果,避免了分步训练的麻烦。
图4为150 m可见度下域适应前后对比图。图4a中,由于雾霾漏掉了一些车辆,而在图4b中,域适应后的模型可以检测出这些车辆。图4c将卡车误检成火车,自行车误检成公共汽车,图4e将摩托车误检成自行车,域适应后也能识别出正确的类别,使各类的识别准确率也有所提升。

图4 150 m可见度下域适应前后对比图Fig.4 Comparison before and after domain adaptation at 150 m visibility
将JMMD-YOLO模型与其他目标检测域适应模型从无雾到有雾的检测效果进行对比,结果详见表4。其中DA-YOLO为单阶段域适应,其他三种均为Faster R-CNN下的域适应。与DA-YOLO单阶段域适应模型相比,JMMD-YOLO对6种车辆的检测效果都更好一些。与其余几种双阶段域适应模型相比,JMMD-YOLO模型对个别类别车辆检测准确率稍低,但均值准确率mAP效果最佳。
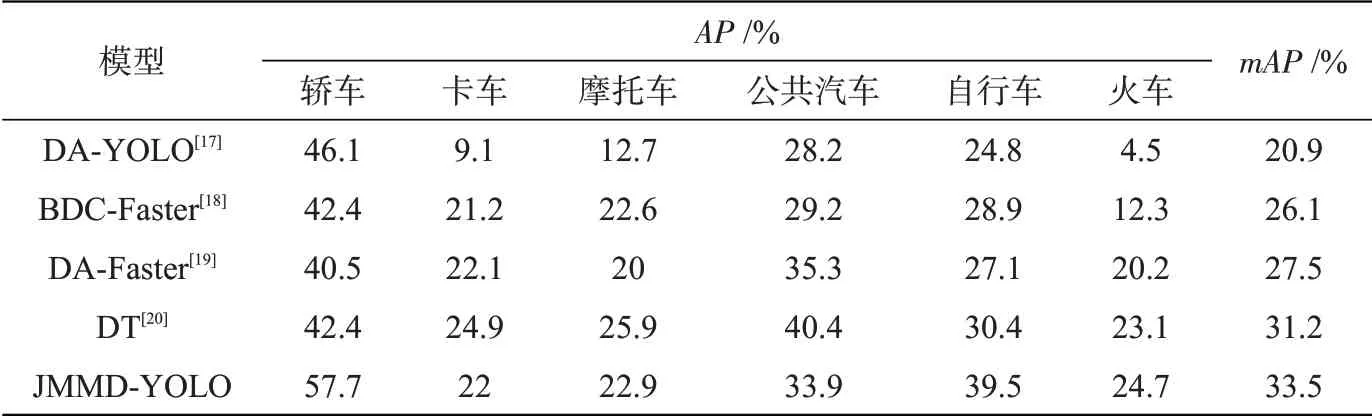
表4 不同域适应模型对比结果Tab.4 Comparison between results of different domain adaptation models
3 结论
雾霾天气情况下数据集较少,在晴天拍摄标注的数据集难以满足雾霾天气车辆检测。基于此问题,本文采用域适应的方法对模型进行改进。在对多种单阶段模型进行实验后,本文选用其中跨域检测效果最好的YOLOv3-SPP进行改进,调整原有YOLO输入结构,将跨域多个特定层的联合分布对齐,提出域适应目标检测JMMD-YOLO模型。与传统的目标检测网络相比,JMMD-YOLO在训练时目标域的输入无需注释,可便捷地用于雾霾下的车辆检测。实验结果显示,JMMDYOLO模型可以更好地检测出雾霾天中的车辆,在150 m可见度下,单类识别准确率最高提升6.4%,整体平均精度提升2.2%,并且速度达到57.8帧/s,具有实时性。
